TiDB ダッシュボード診断レポート
本書では、診断レポートの内容や閲覧のヒントを紹介します。クラスター診断ページにアクセスしてレポートを生成するには、 TiDB ダッシュボードのクラスタ診断ページを参照してください。
レポートをビュー
診断レポートは次の部分で構成されます。
- 基本情報: 診断レポートの時間範囲、クラスターのハードウェア情報、クラスター トポロジのバージョン情報が含まれます。
- 診断情報: 自動診断の結果が表示されます。
- 負荷情報:サーバー、TiDB、PD、または TiKV の CPU、メモリ、およびその他の負荷情報が含まれます。
- 概要情報: 各 TiDB、PD、または TiKV モジュールの消費時間とエラー情報が含まれます。
- TiDB/PD/TiKV監視情報:各コンポーネントの監視情報が含まれます。
- コンフィグレーション情報: 各コンポーネントの構成情報が含まれます。
診断レポートの例は次のとおりです。

上の画像では、上部の青いボックスにある合計時間消費がレポート名です。以下の赤いボックス内の情報は、このレポートの内容とレポートの各フィールドの意味を説明しています。
このレポートでは、いくつかの小さなボタンについて次のように説明します。
- iアイコン: マウスをiアイコンに移動すると、その行の説明が表示されます。
- Expand : [Expand]をクリックすると、この監視メトリクスの詳細が表示されます。たとえば、上図の
tidb_get_tokenの詳細情報には、各 TiDB インスタンスのレイテンシーの監視情報が含まれています。 - Collapse : Expandとは逆に、このボタンは詳細な監視情報を折りたたむために使用されます。
すべてのモニタリング メトリクスは、基本的に TiDB Grafana モニタリング ダッシュボード上のメトリクスに対応します。モジュールに異常が見つかった後は、TiDB Grafana で詳細な監視情報を表示できます。
さらに、このレポートのTOTAL_TIMEおよびTOTAL_COUNTメトリクスは、Prometheus から読み取られたモニタリング データであるため、統計に計算の不正確さが存在する可能性があります。
本レポートの各部を以下に紹介します。
基本情報
診断時間範囲
診断レポートを生成する時間範囲には、開始時刻と終了時刻が含まれます。

クラスタのハードウェア情報
クラスタのハードウェア情報には、クラスター内の各サーバーの CPU、メモリ、ディスクなどの情報が含まれます。

上の表のフィールドは次のように説明されています。
HOST:サーバーの IP アドレス。INSTANCE:サーバーにデプロイされたインスタンスの数。たとえば、pd * 1、このサーバーに1 つの PD インスタンスがデプロイされていることを意味します。tidb * 2 pd * 1このサーバーに2 つの TiDB インスタンスと 1 つの PD インスタンスがデプロイされていることを意味します。CPU_CORES:サーバーの CPU コア (物理コアまたは論理コア) の数を示します。MEMORY:サーバーのメモリサイズを示します。単位はGBです。DISK:サーバーのディスクサイズを示します。単位はGBです。UPTIME:サーバーの稼働時間。単位は日です。
クラスタトポロジ情報
表Cluster Infoは、クラスター トポロジー情報を示します。この表の情報は、TiDB information_schema.cluster_infoシステム テーブルからのものです。

上の表のフィールドは次のように説明されています。
TYPE: ノードのタイプ。INSTANCE: インスタンス アドレスIP:PORT形式の文字列です。STATUS_ADDRESS: HTTP API サービスのアドレス。VERSION: 対応するノードのセマンティック バージョン番号。GIT_HASH: ノードのバージョンをコンパイルするときの Git コミット ハッシュ。2 つのノードが完全に一貫したバージョンであるかどうかを識別するために使用されます。START_TIME: 該当ノードの開始時刻。UPTIME: 対応するノードの稼働時間。
診断情報
TiDB には自動診断結果が組み込まれています。各フィールドの説明については、 情報スキーマ.検査結果システム テーブルを参照してください。
ロード情報
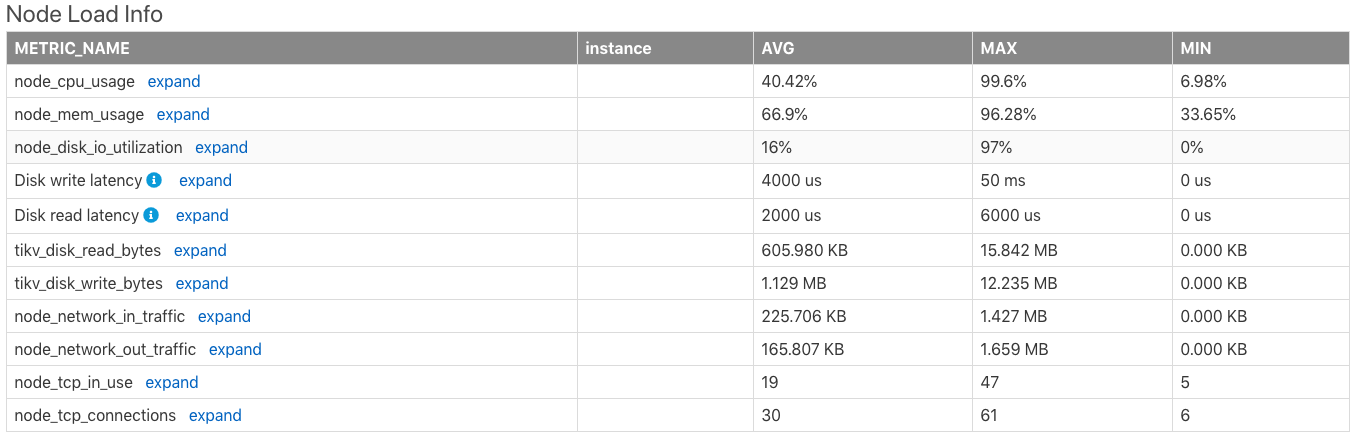
ノード負荷情報
Node Load Info表には、時間範囲内のサーバーの次のメトリックの平均値 (AVG)、最大値 (MAX)、最小値 (MIN) を含む、サーバーサーバーの負荷情報が表示されます。
- CPU 使用率 (最大値は
100%) - メモリ使用量
- ディスク I/O の使用量
- ディスク書き込みレイテンシー
- ディスク読み取りレイテンシー
- 1 秒あたりのディスク読み取りバイト数
- 1 秒あたりのディスク書き込みバイト数
- ノード ネットワークが 1 分あたりに受信したバイト数
- 1 分あたりにノード ネットワークから送信されるバイト数
- ノードによって使用されている TCP 接続の数
- ノードのすべての TCP 接続の数
インスタンスの CPU 使用率
表Instance CPU Usageは、TiDB/PD/TiKVの各プロセスのCPU使用率の平均値(AVG)、最大値(MAX)、最小値(MIN)を示しています。プロセスの最大 CPU 使用率は100% * the number of CPU logical coresです。

インスタンスのメモリ使用量
表Instance Memory Usageは、各 TiDB/PD/TiKV プロセスが占有するメモリバイトの平均値 (AVG)、最大値 (MAX)、および最小値 (MIN) を示しています。

TiKV スレッドの CPU 使用率
表TiKV Thread CPU Usageは、TiKVにおける各モジュールスレッドのCPU使用率の平均値(AVG)、最大値(MAX)、最小値(MIN)を示しています。プロセスの最大 CPU 使用率は100% * the thread count of the corresponding configurationです。
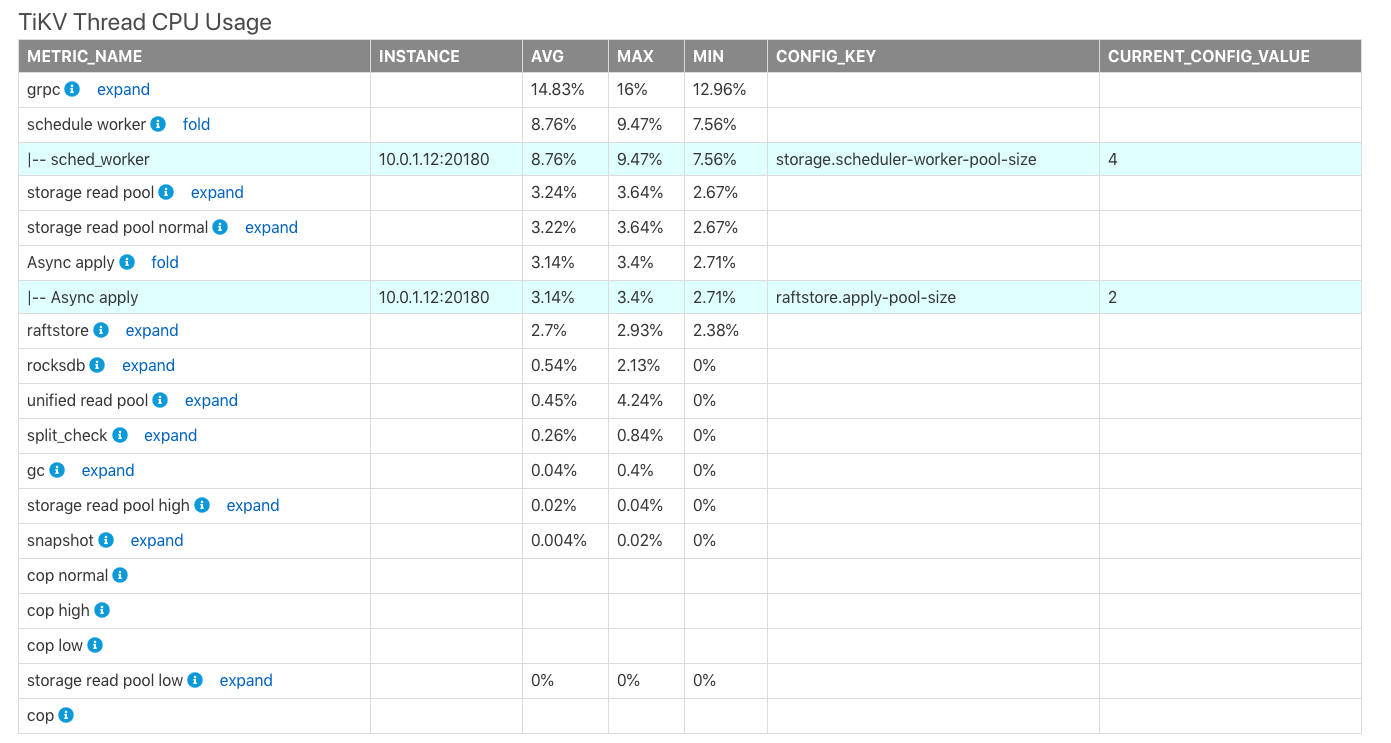
上の表では、
CONFIG_KEY: 対応するモジュールの関連スレッド構成。CURRENT_CONFIG_VALUE: レポートが生成されたときの構成の現在の値。
注記:
CURRENT_CONFIG_VALUEはレポート生成時の値であり、このレポートの時間範囲内の値ではありません。現在、過去の時刻の一部の設定値が取得できません。
TiDB/PD Goroutines Count
表TiDB/PD Goroutines Countは、TiDBまたはPDゴルーチン数の平均値(AVG)、最大値(MAX)、最小値(MIN)を示しています。ゴルーチンの数が 2,000 を超えると、プロセスの同時実行性が高くなりすぎ、全体的なリクエストのレイテンシーに影響します。

概要情報
各コンポーネントの所要時間
表Time Consumed by Each Componentは、クラスター内の TiDB、PD、TiKV モジュールの監視された消費時間と時間比率を示しています。デフォルトの時間単位は秒です。このテーブルを使用すると、どのモジュールがより多くの時間を消費しているかをすばやく特定できます。
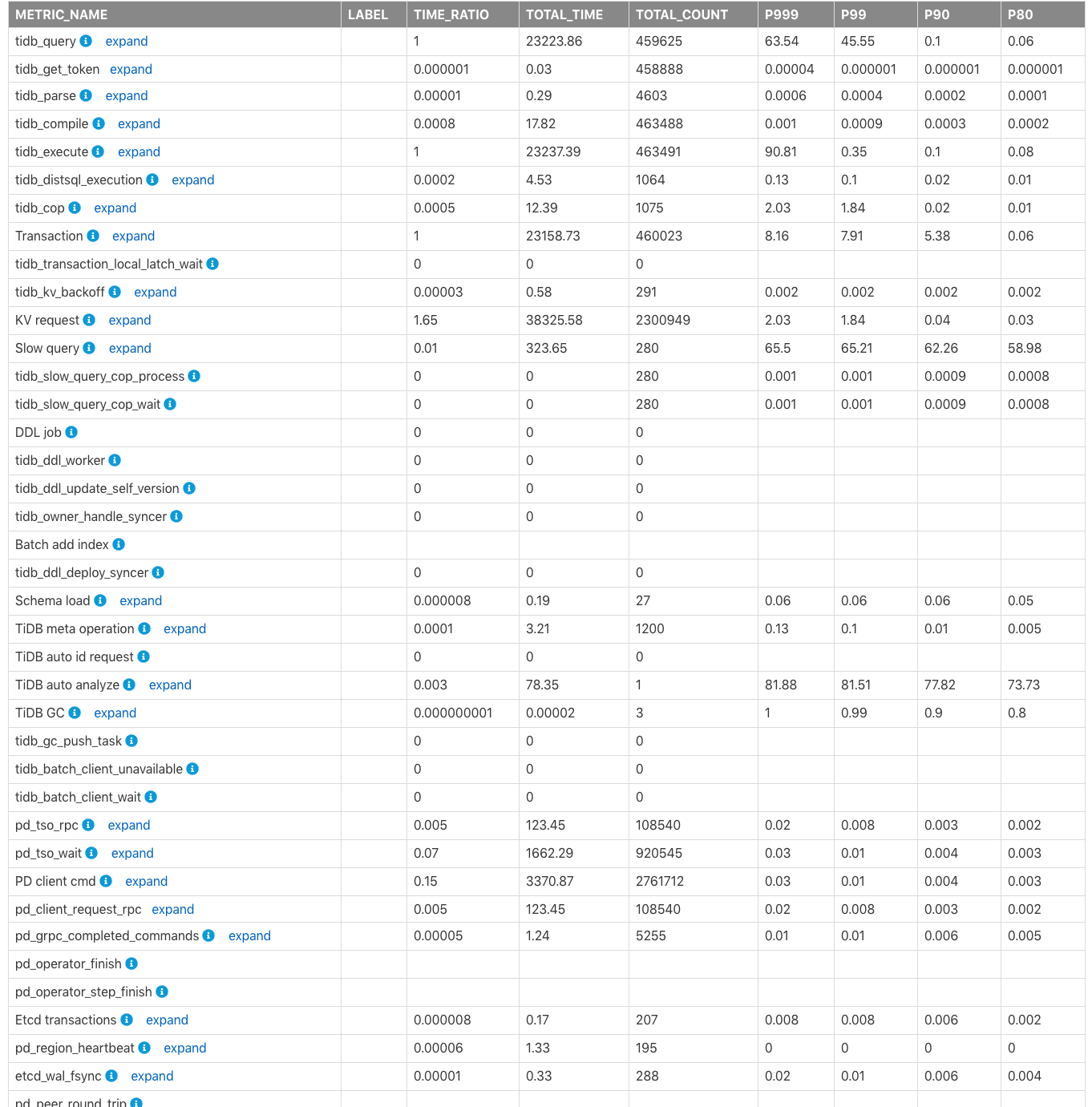
上の表の列のフィールドは次のように説明されています。
METRIC_NAME: 監視メトリックの名前。Label: 監視メトリックのラベル情報。 「展開」をクリックすると、メトリクスの各ラベルの詳細な監視情報が表示されます。TIME_RATIO: 監視行の合計時間に対するこの監視メトリックによって消費された合計時間の比率 (TIME_RATIOが1の場合)。たとえば、kv_requestによる合計消費時間はtidb_queryの合計時間の1.65(つまり38325.58/23223.86) 倍になります。 KV リクエストは同時に実行されるため、すべての KV リクエストの合計時間がクエリ (tidb_query) の合計実行時間を超える可能性があります。TOTAL_TIME: この監視メトリックによって消費された合計時間。TOTAL_COUNT: この監視メトリックが実行される合計回数。P999: この監視メトリックの最大 P999 時間。P99: この監視メトリックの最大 P99 時間。P90: この監視メトリックの最大 P90 時間。P80: この監視メトリックの最大 P80 時間。
次の図は、上記の監視メトリクスにおける関連モジュールの時間消費の関係を示しています。
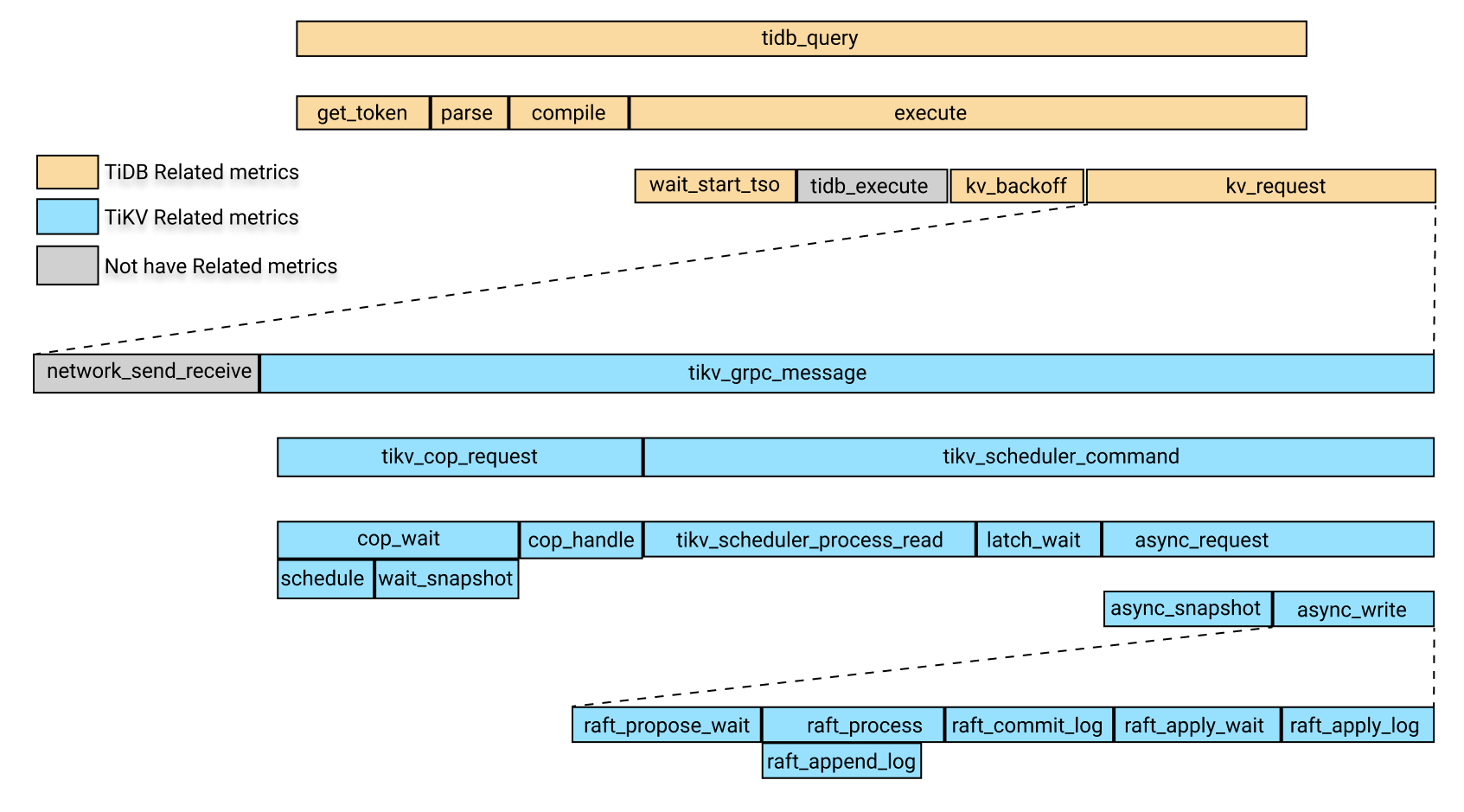
上の画像では、黄色のボックスは TiDB 関連のモニタリング メトリックです。青色のボックスは TiKV 関連のモニタリング メトリックで、灰色のボックスは一時的に特定のモニタリング メトリックに対応していません。
上の画像では、 tidb_queryの時間消費には次の 4 つの部分が含まれます。
get_tokenparsecompileexecute
execute回には次の部分が含まれます。
wait_start_tso- TiDBレイヤーでの実行時間 (現在監視されていません)
- KVリクエスト時間
KV_backoff時間。KV リクエストが失敗した後のバックオフの時間です。
上記の部分のうち、KV 要求時間には次の部分が含まれます。
- ネットワークによるリクエストの送受信にかかる時間。現在、この項目に関する監視指標はありません。 KV リクエスト時間から
tikv_grpc_messageの時間を減算すると、この項目を大まかに見積もることができます。 - 消費時間
tikv_grpc_message。
上記パーツのうち、 tikv_grpc_message回の消費には以下のパーツが含まれます。
コプロセッサー要求の消費時間。COP タイプの要求の処理を指します。この時間の消費には次の部分が含まれます。
tikv_cop_wait: リクエストキューの消費時間。Coprocessor handle:コプロセッサー要求の処理にかかる時間。
消費時間は
tikv_scheduler_command。これには次の部分が含まれます。tikv_scheduler_processing_read: 読み取りリクエストの処理にかかる時間。tikv_storage_async_requestでスナップショットを取得するのに費やした時間 (スナップショットはこの監視メトリックのラベルです)。- 書き込みリクエストの処理にかかる時間。この時間の消費には次の部分が含まれます。
tikv_scheduler_latch_wait: ラッチを待つのにかかる時間。- 書き込みの消費時間
tikv_storage_async_request(書き込みはこの監視メトリックのラベルです)。
上記の指標のうち、 tikv_storage_async_requestの書き込み時間は、以下の部分を含むRaft KV の書き込みにかかる時間を指します。
tikv_raft_propose_waittikv_raft_process、主にtikv_raft_append_log含まれますtikv_raft_commit_logtikv_raft_apply_waittikv_raft_apply_log
TOTAL_TIME 、P999 時間、および P99 時間を使用して、上記の時間消費間の関係に従ってどのモジュールがより長い時間を消費しているかを判断し、関連する監視メトリックを確認できます。
注記:
Raft KV の書き込みは 1 つのバッチで処理される可能性があるため、各モジュールによって消費される時間を測定するために
TOTAL_TIMEを使用することは、 Raft KV の書き込みに関連するメトリック (具体的にはtikv_raft_process、tikv_raft_append_log、tikv_raft_commit_log、tikv_raft_apply_wait、およびtikv_raft_apply_logのモニタリングには適用できません。この状況では、各モジュールの消費時間を P999 および P99 の時間と比較する方が合理的です。その理由は、10 個の非同期書き込みリクエストがある場合、 Raft KV は内部的に 10 個のリクエストをバッチ実行にパックし、実行時間は 1 秒であるためです。したがって、各リクエストの実行時間は 1 秒、10 個のリクエストの合計時間は 10 秒ですが、 Raft KV の処理時間の合計は 1 秒になります。消費時間を測定するために
TOTAL_TIME使用すると、残りの 9 秒がどこに費やされているかが分からなくなる可能性があります。また、リクエストの合計数から、 Raft KV のモニタリング メトリックと他の以前のモニタリング メトリックとの違いを確認することもできます (TOTAL_COUNT)。
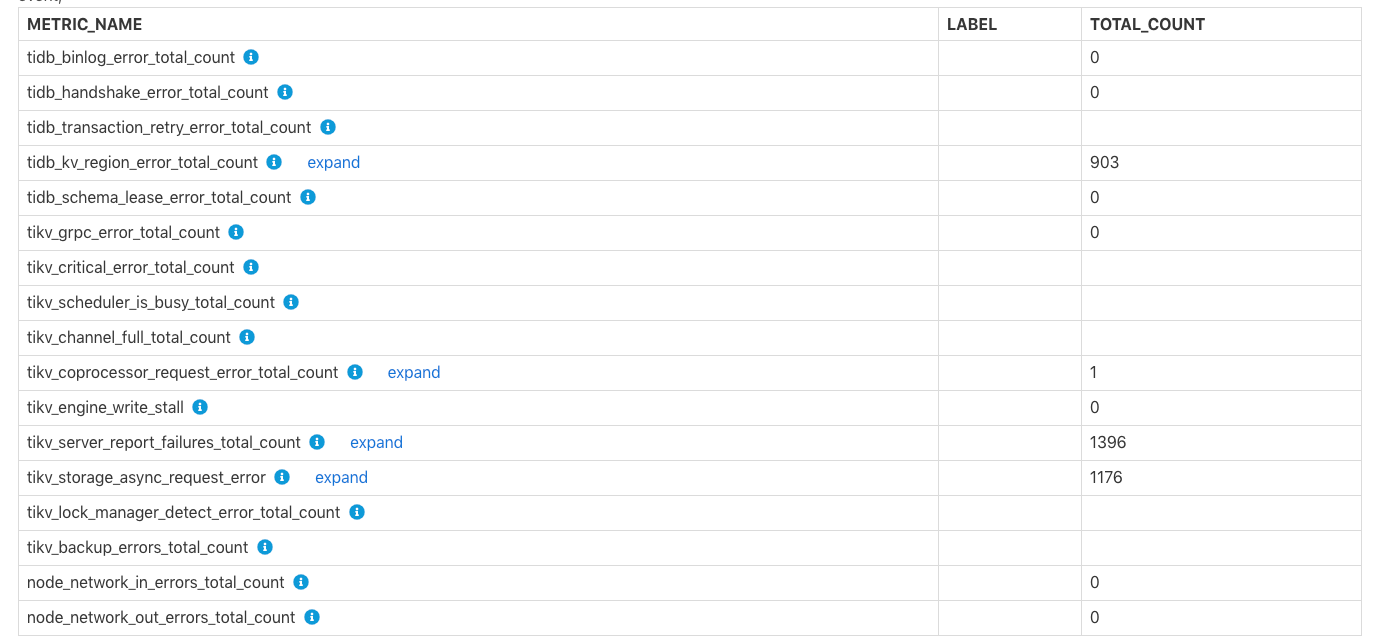
各コンポーネントで発生したエラー
Errors Occurred in Each Component表は、 binlog、 tikv server is busy 、 TiKV channel full 、 tikv write stallへの書き込み失敗など、TiDB と TiKV のエラーの合計数を示しています。各エラーの具体的な意味については、行のコメントを確認できます。
特定の TiDB/PD/TiKV モニタリング情報
この部分には、TiDB、PD、または TiKV のより具体的な監視情報が含まれます。
TiDB関連のモニタリング情報
TiDB コンポーネントにかかる時間
この表は、各 TiDB モジュールの消費時間と各時間の割合を示しています。概要のtime consume表と似ていますが、この表のラベル情報はより詳細です。
TiDB サーバー接続
この表は、各 TiDB インスタンスのクライアント接続数を示しています。
TiDBトランザクション
この表は、トランザクション関連の監視メトリックを示しています。
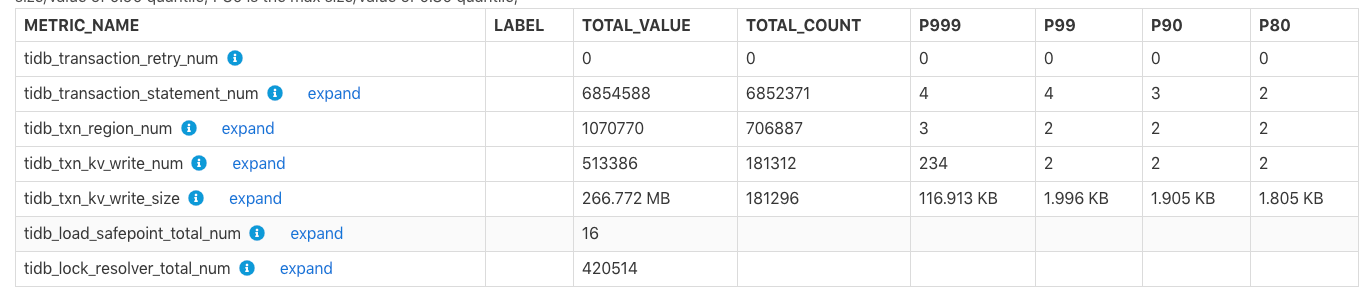
TOTAL_VALUE: レポート時間範囲内のすべての値の合計(SUM)。TOTAL_COUNT: この監視メトリックの合計発生数。P999: この監視メトリックの最大 P999 値。P99: この監視メトリックの最大 P99 値。P90: この監視メトリックの最大 P90 値。P80: この監視メトリックの最大 P80 値。
例:
上の表では、レポート時間範囲内で、 tidb_txn_kv_write_size : KV 書き込みの合計約 181,296 トランザクション、および KV 書き込みの合計サイズは 266.772 MB で、そのうち 1 つのトランザクションの最大 P999、P99、P90、P80 値はKV書き込みは116.913KB、1.996KB、1.905KB、1.805KBです。
DDL 所有者

上の表は、 2020-05-21 14:40:00から、クラスターのDDL OWNER 10.0.1.13:10080ノードにあることを示しています。所有者が変更されると、上の表には複数のデータ行が存在しますMin_Time列は、対応する既知の所有者の最小時間を示します。
注記:
所有者情報が空であっても、この期間に所有者が存在しないことを意味するわけではありません。この状況では、DDL 所有者は
ddl_workerの監視情報に基づいて決定されるため、ddl_workerがこの期間内に DDL ジョブを実行していないため、所有者情報が空になっている可能性があります。
TiDB のその他の監視テーブルは次のとおりです。
- 統計情報: TiDB 統計情報の関連監視メトリックを表示します。
- トップ 10 の遅いクエリ: レポート時間範囲内のトップ 10 の遅いクエリ情報を表示します。
- ダイジェスト別の上位 10 の低速クエリ グループ: SQL フィンガープリントに従って集計された、レポート時間範囲内の上位 10 の低速クエリ情報を表示します。
- 差分プランのある低速クエリ: レポート時間範囲内で実行プランが変更される SQL ステートメント。
PD関連監視情報
PDモジュールの監視情報に関するテーブルは以下のとおりです。
Time Consumed by PD Component: PD 内の関連モジュールのメトリクスの監視に費やされる時間。Blance Leader/Region:balance-regionとbalance leaderの監視情報がレポート時間範囲内のクラスターで発生しました (tikv_note_1からスケジュールされたリーダーの数、またはスケジュールされたリーダーの数など)。Cluster Status: TiKV ノードの総数、クラスターの総storage容量、リージョンの数、オフライン TiKV ノードの数を含むクラスターのステータス情報。Store Status:リージョンスコア、リーダー スコア、リージョン/リーダーの数など、各 TiKV ノードのステータス情報を記録します。Etcd Status: PD 内の etcd 関連情報。
TiKV関連監視情報
TiKV モジュールの監視情報に関連するテーブルは次のとおりです。
Time Consumed by TiKV Component: TiKV 内の関連モジュールによって消費される時間。Time Consumed by RocksDB: TiKV で RocksDB が消費した時間。TiKV Error: TiKVの各モジュールに関するエラー情報。TiKV Engine Size: TiKV の各ノードに格納される列ファミリーのデータのサイズ。Coprocessor Info: TiKV のコプロセッサーモジュールに関連する情報を監視します。Raft Info: TiKV のRaftモジュールのモニタリング情報。Snapshot Info: TiKV 内のスナップショット関連の監視情報。GC Info: TiKV のガベージ コレクション (GC) 関連の監視情報。Cache Hit: TiKVにおけるRocksDBの各キャッシュのヒット率情報。
コンフィグレーション情報
構成情報には、レポート時間範囲内の一部のモジュールの構成値が表示されます。ただし、これらのモジュールの他の一部の構成の履歴値は取得できないため、これらの構成の表示値は、現在の (レポート生成時の) 値です。
レポート時間範囲内で、次の表には、レポート時間範囲の開始時に値が設定される項目が含まれています。
Scheduler Initial Config: レポート開始時のPDスケジューリング関連設定の初期値。TiDB GC Initial Config: レポート開始時の TiDB GC 関連設定の初期値TiKV RocksDB Initial Config: レポート開始時の TiKV RocksDB 関連設定の初期値TiKV RaftStore Initial Config: レポート開始時の TiKV RaftStore 関連設定の初期値
レポート時間範囲内で、一部の構成が変更された場合、次の表には、変更された一部の構成のレコードが含まれます。
Scheduler Config Change HistoryTiDB GC Config Change HistoryTiKV RocksDB Config Change HistoryTiKV RaftStore Config Change History
例:

上の表は、 leader-schedule-limit構成パラメータがレポート時間範囲内で変更されたことを示しています。
2020-05-22T20:00:00+08:00: レポートの開始時点で、leader-schedule-limitの構成値は4です。これは、構成が変更されたことを意味するのではなく、レポート時間範囲の開始時点での構成値が4であることを意味します。2020-05-22T20:07:00+08:00:leader-schedule-limit構成値は8であり、この構成の値が2020-05-22T20:07:00+08:00付近に変更されたことを示します。
次の表は、レポート生成時の TiDB、PD、および TiKV の現在の構成を示しています。
TiDB's Current ConfigPD's Current ConfigTiKV's Current Config
比較レポート
2 つの時間範囲の比較レポートを生成できます。レポートの内容は、2 つの時間範囲間の差異を示す比較列が追加されていることを除き、単一の時間範囲のレポートと同じです。次のセクションでは、比較レポート内のいくつかのユニークなテーブルと比較レポートの表示方法を紹介します。
まず、基本情報のCompare Report Time Rangeレポートには、比較のために 2 つの時間範囲が表示されます。

上の表において、 t1は通常の時間範囲、または基準時間範囲を示します。 t2は異常な時間範囲です。
遅いクエリに関連するテーブルは次のとおりです。
Slow Queries In Time Range t2:t2でのみ表示され、t1では表示されない遅いクエリを表示します。Top 10 slow query in time range t1:t1中のトップ 10 の遅いクエリ。Top 10 slow query in time range t2:t2中のトップ 10 の遅いクエリ。
DIFF_RATIO の概要
ここでは、 Instance CPU Usage表を例にDIFF_RATIOを紹介します。

t1.AVG、t1.MAX、t1.Minはt1における CPU 使用率の平均値、最大値、最小値です。t2.AVGt2.Mint2.MAX中t2CPU使用率の平均値、最大値、最小値です。AVG_DIFF_RATIOt1とt2の平均値のDIFF_RATIOです。MAX_DIFF_RATIOはt1とt2の間の最大値のDIFF_RATIOです。MIN_DIFF_RATIOはt1とt2の間の最小値のDIFF_RATIOです。
DIFF_RATIO : 2 つの時間範囲の差分値を示します。次の値があります。
- 監視メトリックが
t2以内の値のみを持ち、t1以内の値を持たない場合、DIFF_RATIOの値は1になります。 - 監視メトリックが
t1以内の値のみを持ち、t2時間範囲内に値がない場合、DIFF_RATIOの値は-1になります。 t2の値がt1の値より大きい場合、DIFF_RATIO=(t2.value / t1.value)-1t2の値がt1の値より小さい場合、DIFF_RATIO=1-(t1.value / t2.value)
たとえば、上の表では、 t2のtidbノードの平均 CPU 使用率はt1の 2.02 倍、つまり2.02 = 1240/410-1です。
最大別アイテム表
Maximum Different Item表は、2 つの時間範囲の監視メトリックを比較し、監視メトリックの違いに従って並べ替えています。このテーブルを使用すると、2 つの時間範囲でどの監視メトリクスに最も大きな違いがあるかをすぐに見つけることができます。次の例を参照してください。
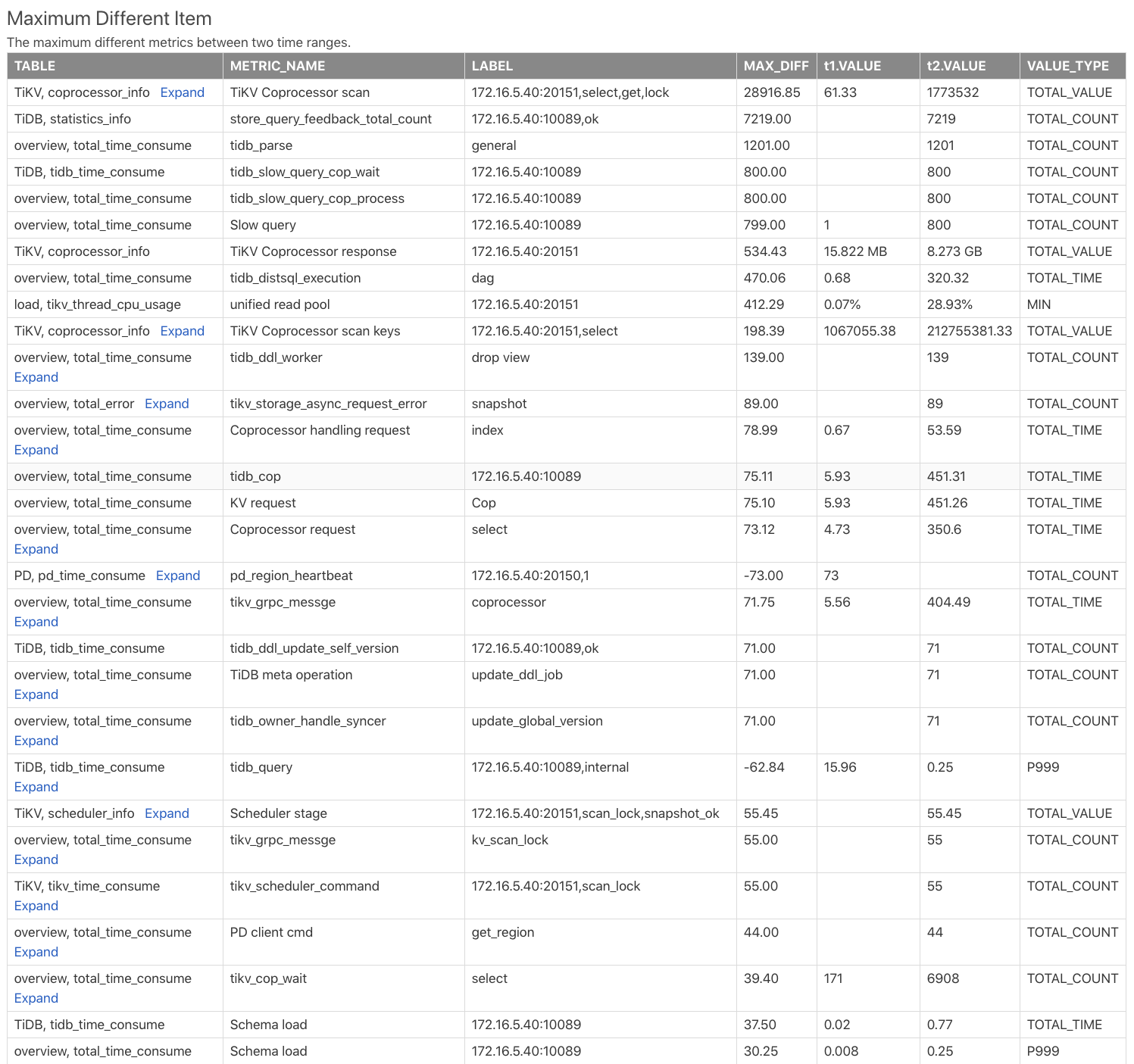
Table: この監視メトリックが比較レポートのどのテーブルから取得されたかを示します。たとえば、TiKV, coprocessor_infoTiKVコンポーネントのcoprocessor_infoテーブルを示します。METRIC_NAME: 監視メトリック名。expandをクリックすると、メトリックのさまざまなラベルの比較が表示されます。LABEL: 監視メトリックに対応するラベル。たとえば、モニタリング メトリックTiKV Coprocessor scanには 2 つのラベル、つまりinstance、req、tag、sql_typeがあり、これらは TiKV アドレス、リクエスト タイプ、操作タイプ、および操作カラムファミリーです。MAX_DIFF:t1.VALUEとt2.VALUEのDIFF_RATIO番目の差分値。
上の表から、 t2時間範囲にはt1時間範囲よりもはるかに多くのコプロセッサーリクエストがあり、 t2範囲の TiDB の SQL 解析時間がはるかに長いことがわかります。