TiDB ストレージ
このドキュメントでは、 TiKVのいくつかの設計アイデアと主要な概念を紹介します。
キーと値のペア
データstorageシステムを決定する最初のことは、データstorageモデル、つまり、データを保存する形式です。 TiKV が選択したのは Key-Value モデルであり、順序付けされたトラバーサル メソッドを提供します。 TiKV データstorageモデルには 2 つの重要なポイントがあります。
- これは、キーと値のペアを格納する巨大な Map (C++ の
std::Mapに似ています) です。 - Map 内のキーと値のペアは、キーのバイナリ順に従って並べられます。つまり、特定のキーの位置をシークし、Next メソッドを呼び出して、このキーよりも大きいキーと値のペアを増分順に取得できます。
このドキュメントで説明されている TiKV の KVstorageモデルは、SQL のテーブルとは関係がないことに注意してください。このドキュメントでは、SQL に関連する概念については説明せず、TiKV などの高性能で信頼性の高い分散 Key-Valuestorageを実装する方法のみに焦点を当てています。
ローカルstorage(RocksDB)
どの永続storageエンジンでも、データは最終的にディスクに保存されます。TiKV も例外ではありません。 TiKV はディスクに直接データを書き込むのではなく、データstorageを担当する RocksDB にデータを格納します。その理由は、スタンドアロンstorageエンジン、特に慎重な最適化が必要な高性能スタンドアロン エンジンの開発には多くの費用がかかるためです。
RocksDB は、Facebook によってオープンソース化された優れたスタンドアロンstorageエンジンです。このエンジンは、TiKVのさまざまな要件を1つのエンジンで満たすことができます。ここでは、RocksDB を単一の永続的な Key-Value マップと単純に考えることができます。
Raftプロトコル
さらに、TiKV の実装はより困難な問題に直面しています。それは、1 台のマシンに障害が発生した場合にデータの安全性を確保することです。
簡単な方法は、複数のマシンにデータをレプリケートすることです。これにより、1 つのマシンに障害が発生した場合でも、他のマシンのレプリカは引き続き使用できます。つまり、信頼性が高く、効率的で、レプリカが失敗した状況を処理できるデータ レプリケーション スキームが必要です。これらはすべて、 Raftアルゴリズムによって可能になります。
Raft はコンセンサスアルゴリズムです。このドキュメントではRaft を簡単に紹介するだけです。詳細については、 わかりやすいコンセンサスアルゴリズムを求めてを参照してください。 Raft にはいくつかの重要な機能があります。
- Leader選挙
- メンバーシップの変更 (レプリカの追加、レプリカの削除、リーダーの移動など)
- ログのレプリケーション
TiKV はRaft を使用してデータ レプリケーションを実行します。各データ変更はRaftログとして記録されます。 Raftログの複製により、データはRaftグループの複数のノードに安全かつ確実に複製されます。ただし、 Raftプロトコルによると、書き込みが成功するには、データが大部分のノードに複製されるだけで済みます。
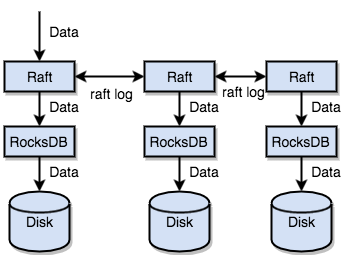
要約すると、TiKV は、スタンドアロン マシン RocksDB を介してディスクにデータをすばやく保存し、マシンの障害が発生した場合にRaftを介して複数のマシンにデータを複製できます。データは、RocksDB ではなく、 Raftのインターフェースを介して書き込まれます。 Raftの実装により、TiKV は分散 Key-Valuestorageになります。いくつかのマシンに障害が発生した場合でも、TiKV はアプリケーションに影響を与えないネイティブRaftプロトコルによってレプリカを自動的に完成させることができます。
リージョン
わかりやすくするために、すべてのデータに 1 つのレプリカしかないと仮定しましょう。前述のように、TiKV は大規模で整然とした KV マップと見なすことができるため、水平方向のスケーラビリティを実現するためにデータが複数のマシンに分散されます。 KV システムの場合、複数のマシンにデータを分散するための一般的なソリューションが 2 つあります。
- ハッシュ: キーでハッシュを作成し、ハッシュ値に従って対応するstorageノードを選択します。
- 範囲: シリアル キーのセグメントがノードに格納されているキーで範囲を分割します。
TiKV は、Key-Value スペース全体を一連の連続する Key セグメントに分割する 2 番目のソリューションを選択します。各セグメントはリージョンと呼ばれます。各リージョンは、左が閉じて右が開いた間隔である[StartKey, EndKey)で表すことができます。各リージョンのデフォルトのサイズ制限は 96 MiB で、サイズは構成できます。
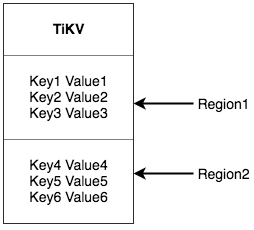
ここでのリージョン は、 SQL のテーブルとは関係がないことに注意してください。このドキュメントでは、SQL のことは忘れて、今のところ KV に焦点を当てます。データをリージョンに分割した後、TiKV は 2 つの重要なタスクを実行します。
- クラスター内のすべてのノードにデータを分散し、リージョンを基本単位として使用します。各ノードのリージョン数がほぼ同じになるように最善を尽くしてください。
- リージョンでRaftレプリケーションとメンバーシップ管理を実行します。
この 2 つのタスクは非常に重要であり、1 つずつ紹介します。
まず、データはキーに従って多くのリージョンに分割され、各リージョンのデータは 1 つのノードにのみ格納されます (複数のレプリカは無視されます)。 TiDB システムには、クラスター内のすべてのノードにリージョンをできるだけ均等に分散させる PDコンポーネントがあります。このようにして、storage容量が水平方向にスケーリングされます (他のノードのリージョンは、新しく追加されたノードに自動的にスケジュールされます)。一方で、ロード バランシングが実現されます (1 つのノードに多くのデータがあり、他のノードにはほとんどデータがないという状況は発生しません)。
同時に、上位のクライアントが必要なデータに確実にアクセスできるようにするために、システムにはコンポーネント(PD) があり、ノード上のリージョンの分布を記録します。つまり、キーの正確なリージョンと任意のキーを介して配置されたそのリージョンのノード。
2 番目のタスクでは、TiKV はデータをリージョンにレプリケートします。つまり、1 つのリージョンのデータには「Replica」という名前のレプリカが複数存在します。リージョンの複数のレプリカが異なるノードに格納されてRaftグループを形成し、 Raftアルゴリズムによって一貫性が保たれます。
レプリカの 1 つはグループのLeaderとして機能し、もう 1 つはFollowerとして機能します。デフォルトでは、すべての読み取りと書き込みはLeaderを介して処理され、そこで読み取りが行われ、書き込みがフォロワーにレプリケートされます。次の図は、 リージョンとRaftグループに関する全体像を示しています。
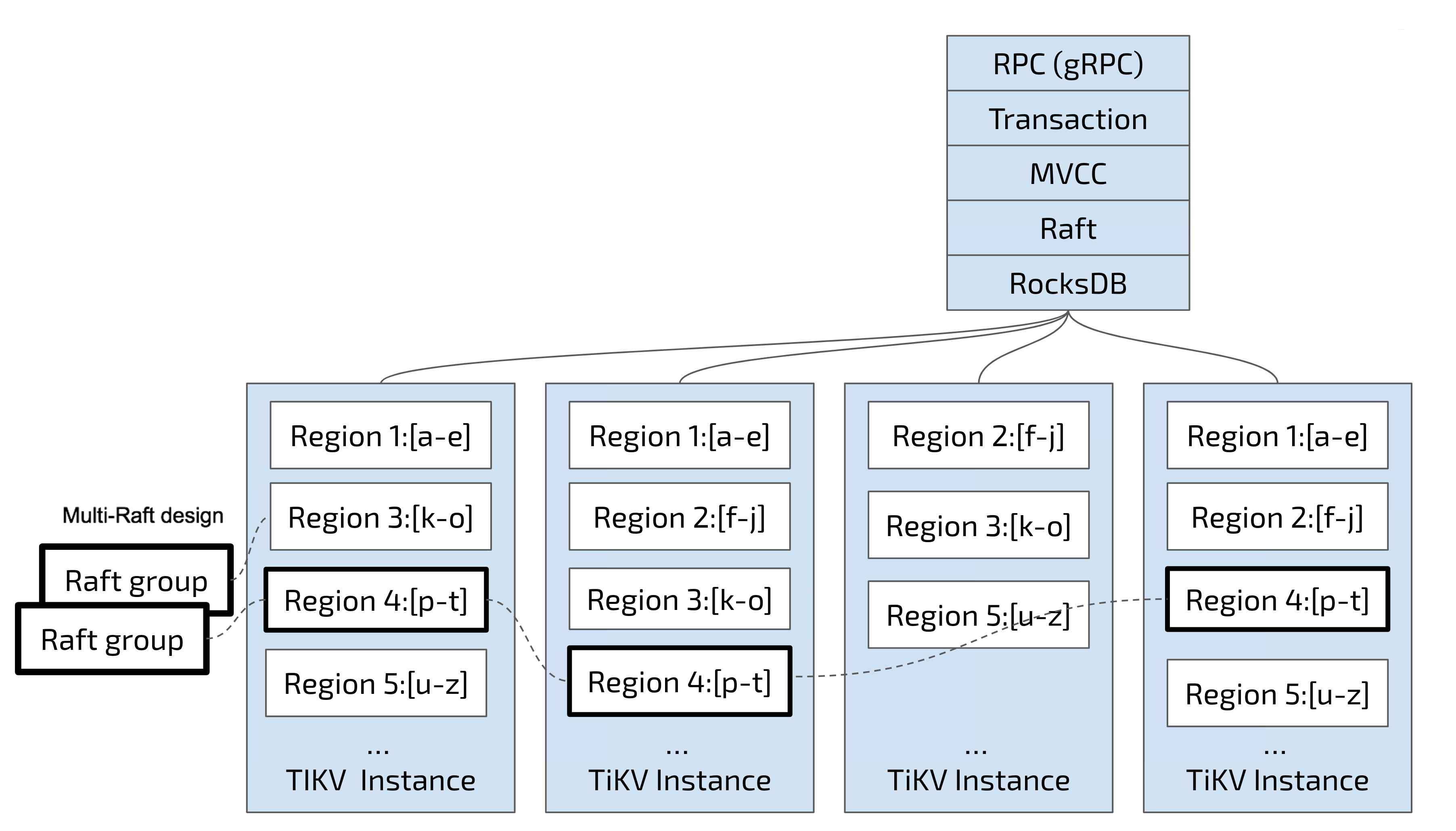
リージョンでデータを分散および複製するため、分散 Key-Value システムがあり、これにはある程度の災害復旧機能があります。容量、ディスク障害、データ損失について心配する必要はもうありません。
MVCC
多くのデータベースはマルチバージョン同時実行制御 (MVCC) を実装しており、TiKV も例外ではありません。 2 つのクライアントが同時に Key の値を変更する状況を想像してください。 MVCC がなければ、データをロックする必要があります。分散シナリオでは、パフォーマンスとデッドロックの問題が発生する可能性があります。 TiKV の MVCC 実装は、キーにバージョン番号を追加することによって実現されます。つまり、MVCC がない場合、TiKV のデータ レイアウトは次のようになります。
Key1 -> Value
Key2 -> Value
……
KeyN -> Value
MVCC では、TiKV のキー配列は次のようになります。
Key1_Version3 -> Value
Key1_Version2 -> Value
Key1_Version1 -> Value
……
Key2_Version4 -> Value
Key2_Version3 -> Value
Key2_Version2 -> Value
Key2_Version1 -> Value
……
KeyN_Version2 -> Value
KeyN_Version1 -> Value
……
同じキーの複数のバージョンについては、番号が大きいバージョンが最初に配置されることに注意してください (キーが順番に配置されているキー値セクションを参照)。そのため、キー + バージョンを通じて値を取得すると、MVCC のキーをキーで構築できます。バージョンはKey_Versionです。次に、RocksDB のSeekPrefix(Key_Version) API を使用して、このKey_Version以上の最初の位置を直接見つけることができます。
分散ACIDトランザクション
TiKV のトランザクションは、 Google が BigTable で使用しているモデルを採用しています: パーコレーター 。 TiKV の実装は、この論文に触発され、多くの最適化が行われています。詳細は取引概要参照してください。