TiDB ディザスタ リカバリ ソリューションの概要
このドキュメントでは、TiDB が提供するディザスタ リカバリ (DR) ソリューションについて紹介します。このドキュメントの構成は次のとおりです。
- DR の基本概念について説明します。
- TiDB、TiCDC、およびバックアップと復元 ( BR ) のアーキテクチャを紹介します。
- TiDBが提供するDRソリューションについて説明します。
- これらの DR ソリューションを比較します。
基本概念
- RTO (Recovery Time Objective): システムが障害から回復するのに必要な時間。
- RPO (目標復旧時点): 災害時に企業が許容できるデータ損失の最大量。
次の図は、これら 2 つの概念を示しています。
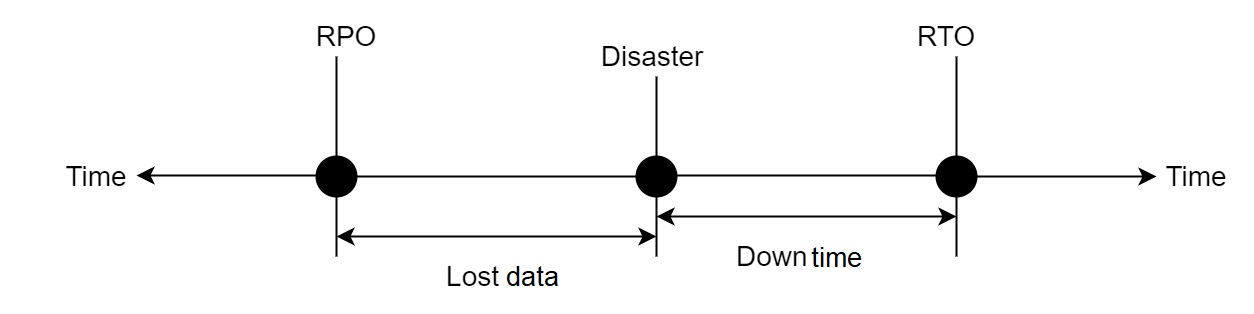
- エラー トレランスの目標: 災害はさまざまな地域に影響を与える可能性があるためです。このドキュメントでは、エラー トレランス目標という用語は、システムが許容できる障害の最大範囲を表すために使用されます。
- リージョン: このドキュメントは地域の DR に焦点を当てており、ここで言及されている「地域」は地理的なエリアまたは都市を指します。
コンポーネントアーキテクチャ
具体的な DR ソリューションを紹介する前に、このセクションでは、TiDB、TiCDC、 BRなど、DR の観点から TiDB コンポーネントのアーキテクチャを紹介します。
TiDB
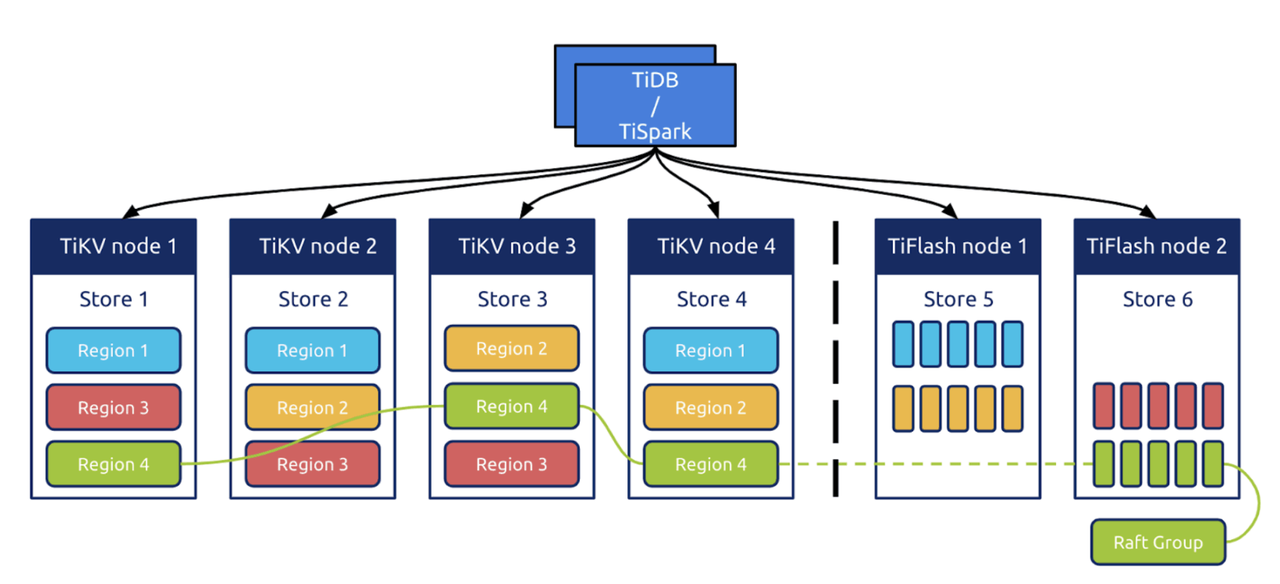
TiDB は、コンピューティングとstorageを分離したアーキテクチャで設計されています。
- TiDB は、システムの SQL コンピューティングレイヤーです。
- TiKV はシステムのstorageレイヤーであり、行ベースのstorageエンジンです。 リージョンは、TiKV でのデータのスケジューリングの基本単位です。 リージョン は、並べ替えられたデータ行のコレクションです。リージョン内のデータは少なくとも 3 つのレプリカに保存され、データの変更はRaftプロトコルを介してログレイヤーに複製されます。
- オプションのコンポーネントTiFlash は、分析クエリを高速化するために使用できる列指向のstorageエンジンです。データは、 Raftグループの学習者の役割を介して TiKV からTiFlashに複製されます。
TiDB は 3 つの完全なデータ レプリカを格納します。したがって、複数のレプリカに基づく DR も当然可能です。同時に、TiDB はRaftログを使用してトランザクション ログを複製するため、トランザクション ログの複製に基づく DR も提供できます。
TiCDC
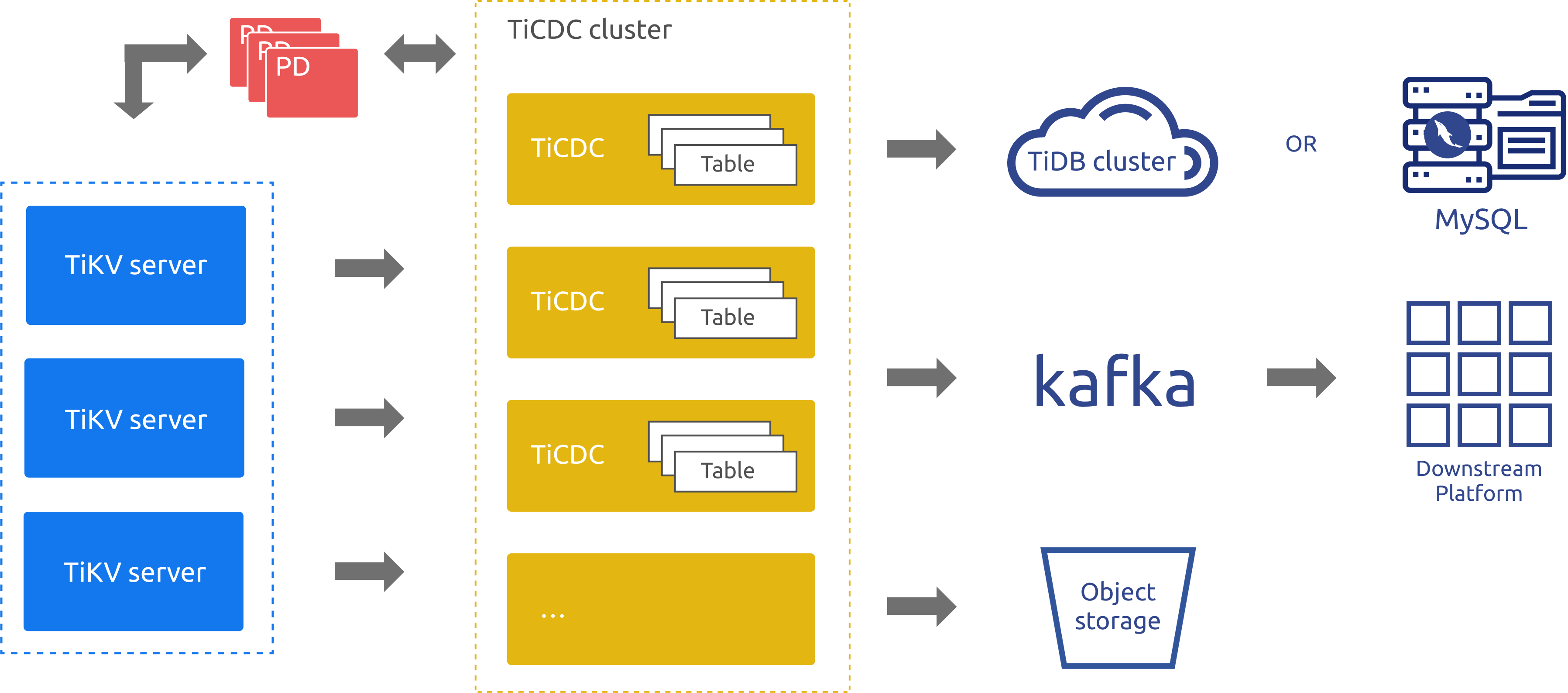
TiDB のインクリメンタル データ レプリケーション ツールとして、TiCDC は PD の etcd を介して高可用性を実現します。 TiCDC は、複数の Capture プロセスを介して TiKV ノードからデータの変更を取得し、データの変更を内部で並べ替えてマージします。その後、TiCDC は複数のレプリケーション タスクを使用して、複数のダウンストリーム システムにデータをレプリケートします。前のアーキテクチャ図では、次のようになります。
- TiKVサーバー: アップストリームのデータ変更を TiCDC ノードに送信します。 TiCDC ノードは、変更ログが連続していないことを検出すると、TiKVサーバーに変更ログの提供を積極的に要求します。
- TiCDC: 複数の Capture プロセスを実行します。各 Capture プロセスは、KV 変更ログの一部を取得し、取得したデータを並べ替えてから、変更を別のダウンストリーム システムにレプリケートします。
前のアーキテクチャ図から、TiCDC のアーキテクチャはトランザクション ログ レプリケーション システムのアーキテクチャに似ていますが、スケーラビリティと論理データ レプリケーションの利点が優れていることがわかります。したがって、TiCDC は、DR シナリオで TiDB を補完するのに適しています。
BR
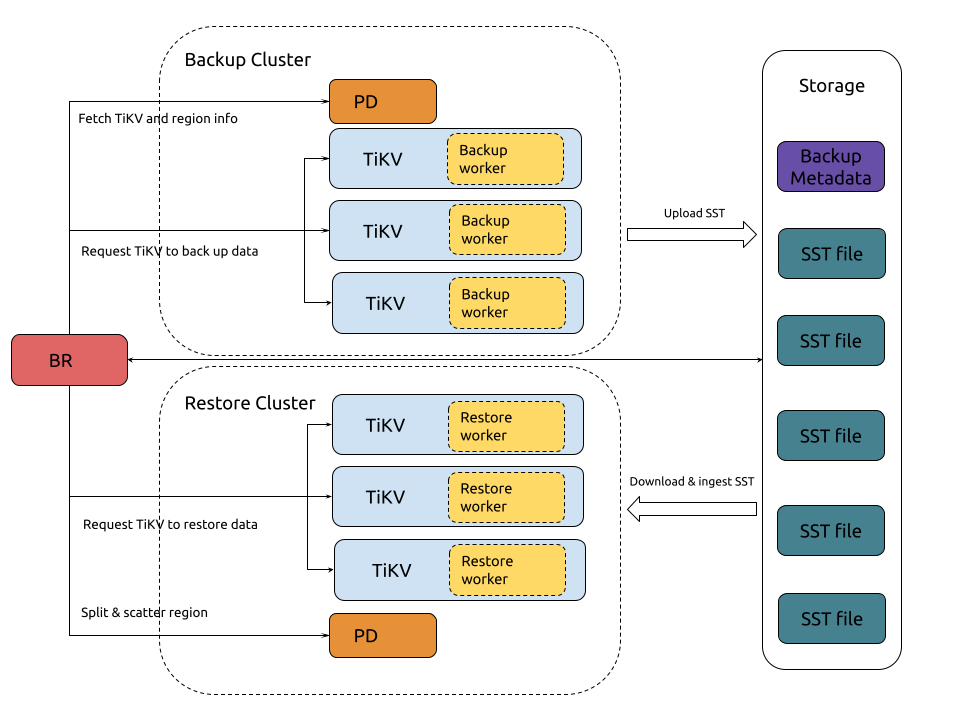
BR は、TiDB のバックアップおよび復元ツールとして、特定の時点に基づくフル スナップショット バックアップと、TiDB クラスターの連続ログ バックアップを実行できます。 TiDB クラスターが完全に利用できない場合は、バックアップ ファイルを新しいクラスターに復元できます。通常、 BRはデータ セキュリティの最後の手段と考えられています。
ソリューション紹介
プライマリ クラスタとセカンダリ クラスタに基づく DR ソリューション
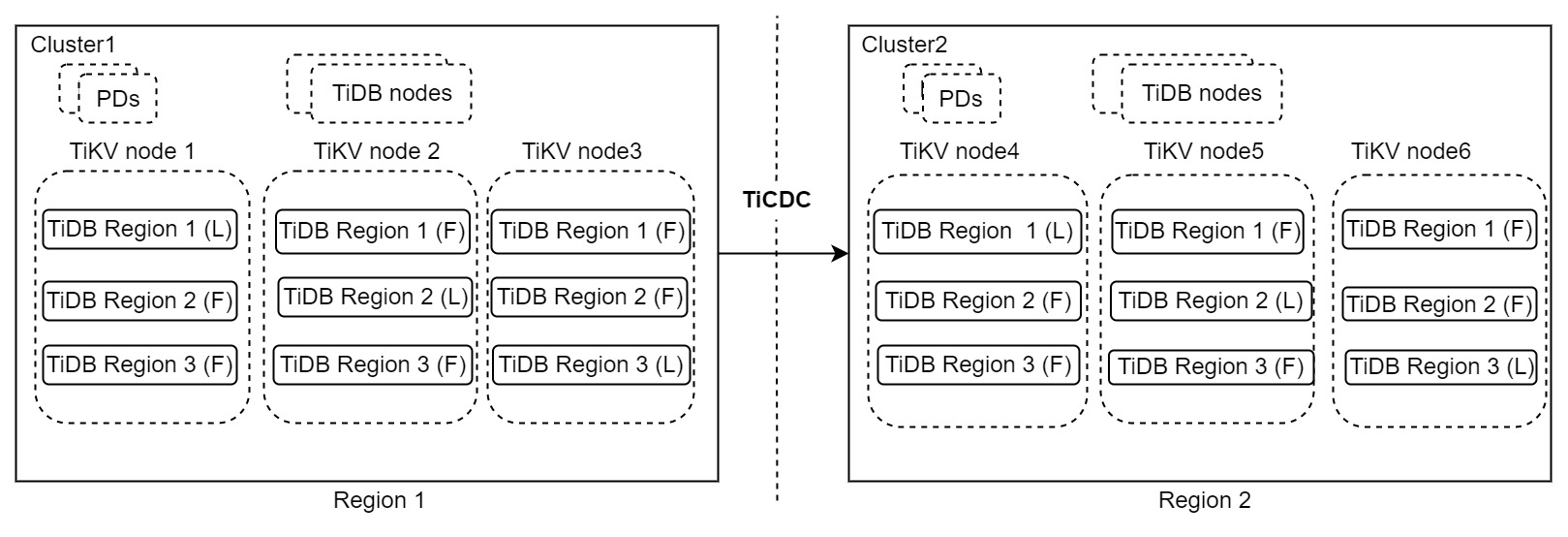
上記のアーキテクチャには 2 つの TiDB クラスターが含まれており、クラスター 1 はリージョン 1 で実行され、読み取りおよび書き込み要求を処理します。クラスタ2 はリージョン 2 で実行され、セカンダリ クラスタとして機能します。クラスター 1 が災害に遭遇すると、クラスター 2 がサービスを引き継ぎます。データの変更は、TiCDC を使用して 2 つのクラスター間で複製されます。このアーキテクチャは、「1:1」DR ソリューションとも呼ばれます。
このアーキテクチャはシンプルで、リージョン レベルのエラー トレランス目標、スケーラブルな書き込み機能、第 2 レベルの RPO、および分レベルの RTO またはそれ以下の高可用性を備えています。本番システムで RPO をゼロにする必要がない場合は、この DR ソリューションをお勧めします。このソリューションの詳細については、 プライマリ クラスタとセカンダリ クラスタに基づく DR ソリューションを参照してください。
単一クラスター内の複数のレプリカに基づく DR ソリューション
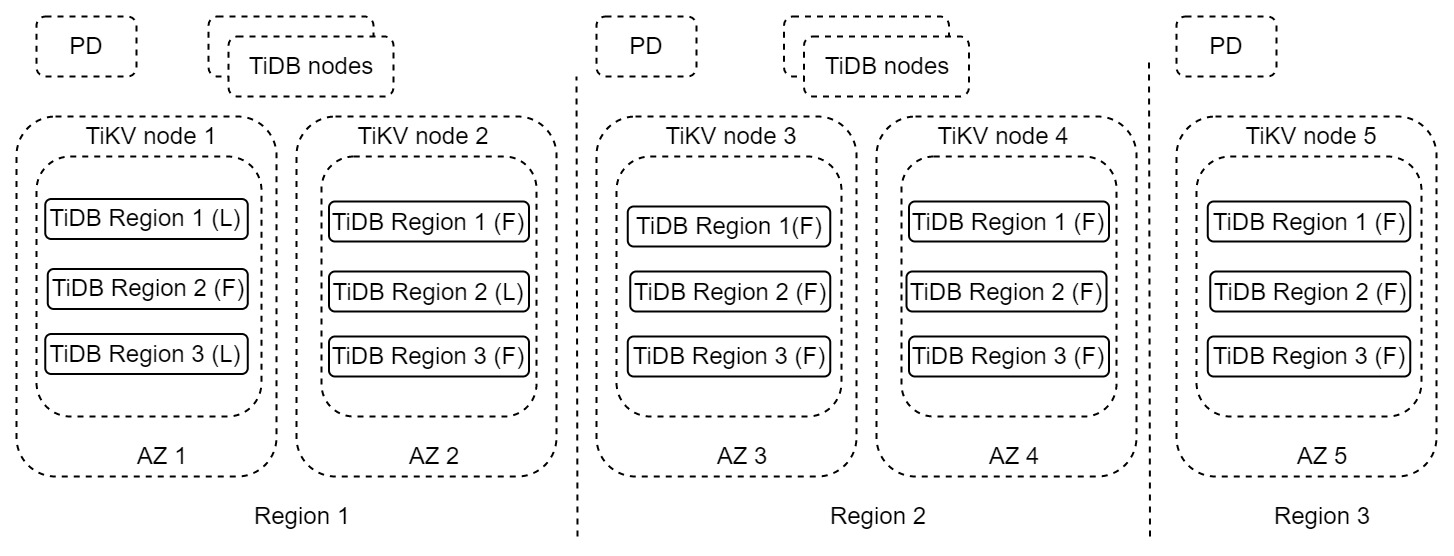
前のアーキテクチャでは、各リージョンには、異なる利用可能なゾーン (AZ) に配置された 2 つの完全なデータ レプリカがあります。クラスター全体が 3 つのリージョンにまたがっています。リージョン1 は、読み取りおよび書き込み要求を処理するプライマリ リージョンです。災害によりリージョン 1 が完全に使用できなくなった場合、リージョン 2 を DR リージョンとして使用できます。リージョン3 は、マジョリティ プロトコルを満たすために使用されるレプリカです。このアーキテクチャは、「2-2-1」ソリューションとも呼ばれます。
このソリューションは、リージョン レベルのエラー トレランス、スケーラブルな書き込み機能、ゼロ RPO、分単位またはそれ以下の RTO を提供します。本番システムでゼロ RPO が必要な場合は、この DR ソリューションを使用することをお勧めします。このソリューションの詳細については、 単一クラスター内の複数のレプリカに基づく DR ソリューションを参照してください。
TiCDC と複数のレプリカに基づく DR ソリューション
上記の 2 つのソリューションは、地域の DR を提供します。ただし、複数のリージョンが同時に利用できない場合、それらは機能しません。システムが非常に重要で、複数の領域をカバーするためにエラー トレランスの目標が必要な場合は、これら 2 つのソリューションを組み合わせる必要があります。
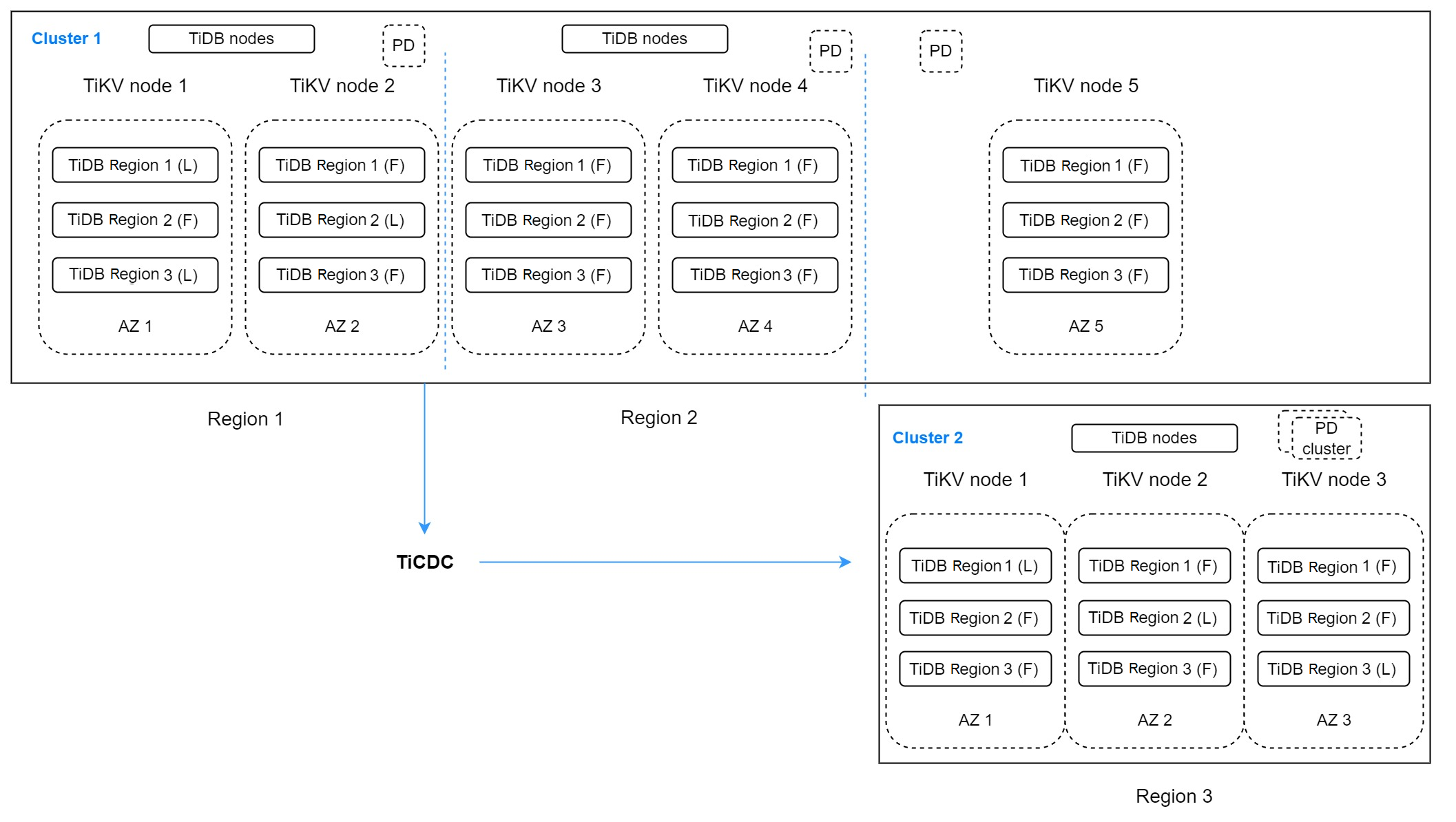
前述のアーキテクチャには、2 つの TiDB クラスターがあります。クラスタ1 には、3 つのリージョンにまたがる 5 つのレプリカがあります。リージョン1 には、プライマリ リージョンとして機能し、書き込み要求を処理する 2 つのレプリカが含まれています。リージョン2 には、リージョン 1 の DR リージョンとして機能する 2 つのレプリカがあります。このリージョンは、レイテンシーの影響を受けない読み取りサービスを提供します。リージョン3 にある最後のレプリカが投票に使用されます。
リージョン 1 とリージョン 2 の DR クラスターとして、クラスター 2 はリージョン 3 で実行され、3 つのレプリカが含まれます。 TiCDC はクラスター 1 からデータをレプリケートします。このアーキテクチャは複雑に見えますが、エラー トレランスの目標を複数のリージョンに増やすことができます。複数のリージョンが同時に利用できないときに RPO をゼロにする必要がない場合は、このアーキテクチャが適しています。このアーキテクチャは、「2-2-1:1」ソリューションとも呼ばれます。
もちろん、エラー トレランスの目標が複数のリージョンであり、RPO をゼロにする必要がある場合は、5 つのリージョンにまたがる少なくとも 9 つのレプリカを持つクラスターを作成することも検討できます。このアーキテクチャは、「2-2-2-2-1」ソリューションとも呼ばれます。
BRに基づくDRソリューション

このアーキテクチャでは、TiDB クラスター 1 はリージョン 1 にデプロイされますBR は定期的にクラスター 1 のデータをリージョン 2 にバックアップし、このクラスターのデータ変更ログをリージョン 2 にも継続的にバックアップします。リージョン 1 で障害が発生し、クラスター 1 を回復できない場合、バックアップ データとデータ変更ログを使用して、リージョン 2 で新しいクラスター (クラスター 2) を復元し、サービスを提供できます。
BRに基づく DR ソリューションは、5 分未満の RPO と、復元するデータのサイズによって異なる RTO を提供します。 BR v6.5.0 の場合、 スナップショット リストアのパフォーマンスと影響とPITRのパフォーマンスと影響を参照して復元速度を確認できます。通常、リージョン間でのバックアップ機能は、データ セキュリティの最後の手段であり、ほとんどのシステムにとって必須のソリューションであると考えられています。このソリューションの詳細については、 BRに基づくDRソリューションを参照してください。
一方、v6.5.0 から、 BR はEBS ボリュームのスナップショットから TiDB クラスターを復元するをサポートします。クラスターが Kubernetes で実行されていて、クラスターに影響を与えずにできるだけ早くクラスターを復元したい場合は、この機能を使用してシステムの RTO を削減できます。
その他の DR ソリューション
前述の DR ソリューションに加えて、同じ都市のデュアル センター シナリオでゼロ RPO が必須である場合は、DR-AUTO 同期ソリューションを使用することもできます。詳細については、 1 つの地域に展開された 2 つのデータ センターを参照してください。
ソリューション比較
このセクションでは、このドキュメントに記載されている DR ソリューションを比較します。これに基づいて、ビジネス ニーズを満たす適切な DR ソリューションを選択できます。
| DR ソリューション | TCO | エラー許容度目標 | RPO | RTO | ネットワークレイテンシー要件 | 対象システム |
|---|---|---|---|---|---|---|
| 単一クラスター内の複数のレプリカに基づく DR ソリューション (2-2-1) | 高い | 単一リージョン | 0 | 分レベル | リージョン間で 30 ミリ秒未満 | DR と対応に関する特定の要件がある本番システム (RPO = 0) |
| プライマリ クラスタとセカンダリ クラスタに基づく DR ソリューション (1:1) | 中くらい | 単一リージョン | 10秒未満 | 5分以内 | リージョン間で 100 ミリ秒未満 | DR と対応に関する特定の要件がある本番システム (RPO > 0) |
| TiCDC と複数のレプリカ (2-2-1:1) に基づく DR ソリューション | 高い | 複数の地域 | 10秒未満 | 5分以内 | DR に複数のレプリカを使用するリージョンでは 30 ミリ秒未満。第 3 リージョンおよびその他のリージョンでは 100 ミリ秒未満 | DR と対応に関する要件が厳しい本番システム |
| BRに基づくDRソリューション | 低い | 単一リージョン | 5分以内 | 時間レベル | 特別な要件なし | 5 分未満の RPO と最大 1 時間の RTO を受け入れる本番システム |