データ移行における DML レプリケーション メカニズム
このドキュメントでは、DM のコア処理ユニット Sync が、データ ソースまたはリレー ログから読み取った DML ステートメントを処理する方法を紹介します。このドキュメントでは、binlogの読み取り、フィルタリング、ルーティング、変換、最適化、および実行のロジックを含む、DM での DML イベントの完全な処理フローを紹介します。このドキュメントでは、DML 最適化ロジックと DML 実行ロジックについても詳しく説明します。
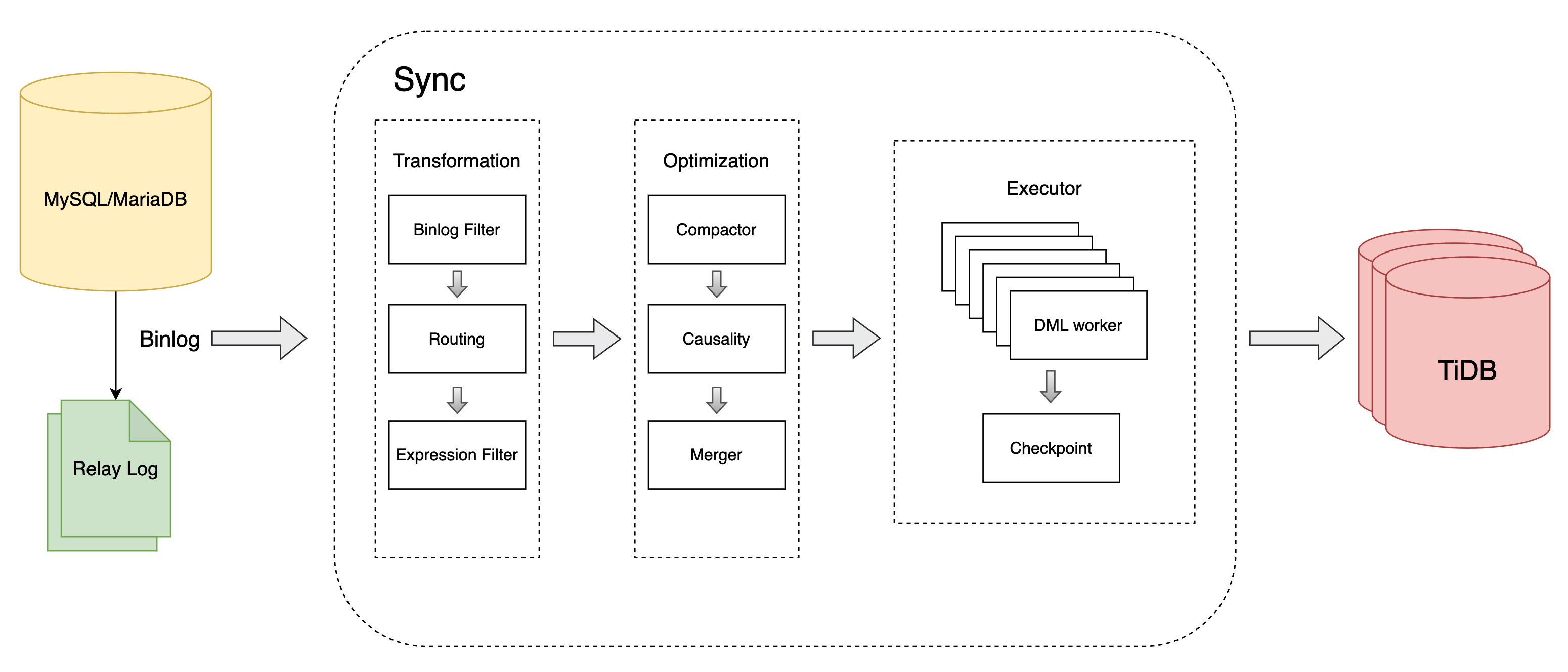
DML処理の流れ
同期ユニットは、DML ステートメントを次のように処理します。
MySQL、MariaDB、またはリレー ログからbinlogイベントを読み取ります。
データ ソースから読み取ったbinlogイベントを変換します。
- Binlogフィルター :
filtersで構成されたbinlog式に従ってbinlogイベントをフィルター処理します。 - テーブル ルーティング :
routesで構成された「データベース/テーブル」ルーティング ルールに従って「データベース/テーブル」名を変換します。 - 式フィルター :
expression-filterで構成された SQL 式に従ってbinlogイベントをフィルタリングします。
- Binlogフィルター :
DML 実行計画を最適化します。
DML をダウンストリームに実行します。
binlogの位置または GTID を定期的にチェックポイントに保存します。
DML 最適化ロジック
Sync ユニットは、Compactor、Causality、および Merger の 3 つのステップを通じて DML 最適化ロジックを実装します。
コンパクター
アップストリームのbinlogレコードに従って、DM はレコードの変更をキャプチャし、ダウンストリームにレプリケートします。アップストリームが短期間に同じレコードに複数の変更 ( INSERT / UPDATE / DELETE ) を行う場合、DM は Compactor を介して複数の変更を 1 つの変更に圧縮し、ダウンストリームへの圧力を軽減してスループットを向上させることができます。例えば:
INSERT + UPDATE => INSERT
INSERT + DELETE => DELETE
UPDATE + UPDATE => UPDATE
UPDATE + DELETE => DELETE
DELETE + INSERT => UPDATE
コンパクター機能はデフォルトで無効になっています。これを有効にするには、以下に示すように、レプリケーション タスクのsync構成モジュールでsyncer.compact ~ trueを設定します。
syncers: # The configuration parameters of the sync processing unit
global: # Configuration name
... # Other configurations are omitted
compact: true
因果関係
MySQL binlogのシーケンシャル レプリケーション モデルでは、 binlogイベントがbinlogの順序でレプリケートされる必要があります。このレプリケーション モデルは、高い QPS と低いレプリケーションレイテンシーの要件を満たすことができません。さらに、 binlogに関連するすべての操作に競合があるわけではないため、そのような場合には順次レプリケーションは必要ありません。
DM は、競合検出を通じて順次実行する必要があるbinlog を認識し、他のbinlogの同時実行性を最大化しながら、これらのbinlogが順次実行されるようにします。これにより、binlogレプリケーションのパフォーマンスが向上します。
Causality は、union-find アルゴリズムと同様のアルゴリズムを採用して、各 DML を分類し、相互に関連する DML をグループ化します。
合併
MySQLbinlogプロトコルによると、各binlogは1 行のデータの変更操作に対応します。 Merger を介して、DM は複数のバイナリログを 1 つの DML にマージし、それをダウンストリームで実行して、ネットワークのやり取りを減らすことができます。例えば:
INSERT tb(a,b) VALUES(1,1);
+ INSERT tb(a,b) VALUES(2,2);
= INSERT tb(a,b) VALUES(1,1),(2,2);
UPDATE tb SET a=1, b=1 WHERE a=1;
+ UPDATE tb SET a=2, b=2 WHERE a=2;
= INSERT tb(a,b) VALUES(1,1),(2,2) ON DUPLICATE UPDATE a=VALUES(a), b=VALUES(b)
DELETE tb WHERE a=1
+ DELETE tb WHERE a=2
= DELETE tb WHERE (a) IN (1),(2);
マージ機能はデフォルトで無効になっています。これを有効にするには、以下に示すように、レプリケーション タスクのsync構成モジュールでsyncer.multiple-rows ~ trueを設定します。
syncers: # The configuration parameters of the sync processing unit
global: # Configuration name
... # Other configurations are omitted
multiple-rows: true
DML 実行ロジック
Sync ユニットが DML を最適化した後、実行ロジックを実行します。
DML 生成
DM には、アップストリームとダウンストリームのスキーマ情報を記録するスキーマ トラッカーが組み込まれています。
- DM が DDL ステートメントを受け取ると、DM は内部スキーマ トラッカーのテーブル スキーマを更新します。
- DM が DML ステートメントを受け取ると、DM はスキーマ トラッカーのテーブル スキーマに従って、対応する DML を生成します。
DML を生成するロジックは次のとおりです。
- 同期ユニットは、アップストリームの初期テーブル構造を記録します。
- フルおよびインクリメンタル タスクを開始する場合、Sync はアップストリームのフル データ移行中にエクスポートされたテーブル構造をアップストリームの初期テーブル構造として使用します。
- 増分タスクを開始するとき、MySQL binlog はテーブル構造情報を記録しないため、Sync はダウンストリームの対応するテーブルのテーブル構造をアップストリームの初期テーブル構造として使用します。
- ユーザーのアップストリームとダウンストリームのテーブル構造が一致していない可能性があります。たとえば、ダウンストリームにアップストリームよりも追加の列があるか、アップストリームとダウンストリームの主キーが一致していません。したがって、データ レプリケーションの正確性を確保するために、DM は対応するテーブルの主キーと一意のキー情報をダウンストリームに記録します。
- DM は DML を生成します。
- スキーマ トラッカーに記録された上流のテーブル構造を使用して、DML ステートメントの列名を生成します。
- binlogに記録された列の値を使用して、DML ステートメントの列の値を生成します。
- スキーマ トラッカーに記録されている下流の主キーまたは一意のキーを使用して、DML ステートメントの
WHERE条件を生成します。テーブル構造に一意のキーがない場合、DM はbinlogに記録されたすべての列の値をWHERE条件として使用します。
ワーカー数
因果関係は、競合検出を通じてbinlog を複数のグループに分割し、それらをダウンストリームで同時に実行できます。 DM はworker-countを設定して同時実行を制御します。ダウンストリーム TiDB の CPU 使用率が高くない場合、同時実行数を増やすと、データ レプリケーションのスループットを効果的に向上させることができます。
syncer.worker-count構成アイテムを変更することで、DML を同時に移行するスレッドの数を変更できます。
バッチ
DM は、複数の DML を 1 つのトランザクションにまとめて、ダウンストリームに実行します。 DML ワーカーは、DML を受信すると、DML をキャッシュに追加します。キャッシュ内の DML の数が事前に設定されたしきい値に達するか、DML ワーカーが長時間 DML を受信しない場合、DML ワーカーはキャッシュ内の DML をダウンストリームに実行します。
syncer.batch構成アイテムを変更することで、トランザクションに含まれる DML の数を変更できます。
チェックポイント
DML を実行してチェックポイントを更新する操作はアトミックではありません。
DM では、チェックポイントはデフォルトで 30 秒ごとに更新されます。複数の DML ワーカー プロセスがあるため、チェックポイント プロセスは、すべての DML ワーカーの最も早いレプリケーションの進行状況のbinlog位置を計算し、この位置を現在のレプリケーション チェックポイントとして使用します。この位置より前のすべてのバイナリログは、ダウンストリームに対して正常に実行されることが保証されています。
ノート
トランザクションの一貫性
DM は行レベルでデータをレプリケートし、トランザクションの一貫性を保証しません。 DM では、アップストリーム トランザクションは複数の行に分割され、同時実行のために異なる DML ワーカーに分散されます。したがって、DM レプリケーション タスクがエラーを報告して一時停止した場合、またはユーザーが手動でタスクを一時停止した場合、ダウンストリームは中間状態にある可能性があります。つまり、アップストリーム トランザクションの DML ステートメントが部分的にダウンストリームにレプリケートされ、ダウンストリームが一貫性のない状態になる可能性があります。
DM v5.3.0 以降、タスクが一時停止されたときにダウンストリームが一貫した状態になるように、DM はタスクを一時停止する前に 10 秒間待機して、アップストリームからのすべてのトランザクションがダウンストリームに複製されるようにします。ただし、トランザクションが 10 秒以内にダウンストリームに複製されない場合、ダウンストリームは依然として不整合な状態にある可能性があります。
セーフモード
DML の実行とチェックポイントの更新の操作はアトミックではなく、チェックポイントの更新とダウンストリームへのデータの書き込みの操作もアトミックではありません。 DM が異常終了した場合、チェックポイントは終了時間の前の復旧ポイントのみを記録する場合があります。したがって、タスクが再開されると、DM は同じデータを複数回書き込む可能性があります。これは、DM が実際に「少なくとも 1 回の処理」ロジックを提供し、同じデータが複数回処理される可能性があることを意味します。
データが再入可能であることを確認するために、DM は異常終了からの再起動時にセーフ モードに入ります。
セーフ モードが有効になっている場合、データを複数回処理できるようにするために、DM は次の変換を実行します。
- アップストリームの
INSERTステートメントをREPLACEステートメントに書き換えます。 - アップストリームの
UPDATEステートメントをDELETE+REPLACEステートメントに書き換えます。
1 回限りの処理
現在、DM は結果整合性のみを保証し、「正確に 1 回の処理」と「トランザクションの元の順序を維持する」をサポートしていません。