RocksDBの概要
RocksDBは、Key-Valueストアおよび読み取り/書き込み機能を提供するLSMツリーストレージエンジンです。 Facebookによって開発され、LevelDBに基づいています。ユーザーによって書き込まれたキーと値のペアは、最初にログ先行書き込み(WAL)に挿入され、次にメモリ内のスキップリスト(MemTableと呼ばれるデータ構造)に書き込まれます。 LSMツリーエンジンは、ランダムな変更(挿入)をWALファイルへの順次書き込みに変換するため、Bツリーエンジンよりも優れた書き込みスループットを提供します。
メモリ内のデータが特定のサイズに達すると、RocksDBはコンテンツをディスク内のSorted String Table(SST)ファイルにフラッシュします。 SSTファイルは複数のレベルで編成されています(デフォルトは最大6レベルです)。レベルの合計サイズがしきい値に達すると、RocksDBはSSTファイルの一部を選択し、それらを次のレベルにマージします。後続の各レベルは前のレベルの10倍であるため、データの90%が最後のレイヤーに格納されます。
RocksDBを使用すると、ユーザーは複数の列ファミリー(CF)を作成できます。 CFには独自のSkipListファイルとSSTファイルがあり、同じWALファイルを共有します。このように、CFが異なれば、アプリケーションの特性に応じて設定も異なります。同時にWALへの書き込み回数が増えることはありません。
TiKVアーキテクチャ
TiKVのアーキテクチャは次のように示されています。
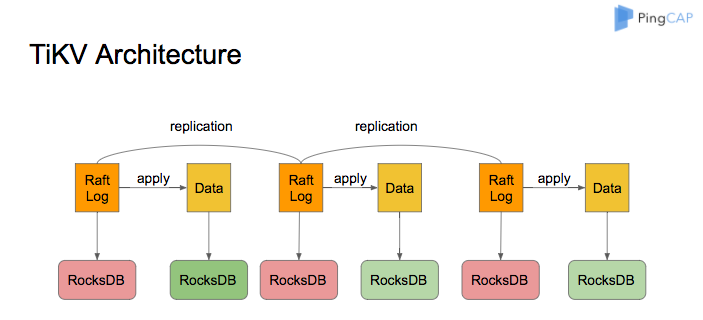
TiKVのストレージエンジンとして、RocksDBはRaftログとユーザーデータを保存するために使用されます。 TiKVノードのすべてのデータは2つのRocksDBインスタンスを共有します。 1つはRaftログ(多くの場合raftdbと呼ばれます)用で、もう1つはユーザーデータとMVCCメタデータ(多くの場合kvdbと呼ばれます)用です。 kvdbには、raft、lock、default、およびwriteの4つのCFがあります。
- raft CF:各リージョンのメタデータを保存します。占有するスペースはごくわずかで、ユーザーは気にする必要がありません。
- ロックCF:ペシミスティックトランザクションのペシミスティックロックと分散トランザクションのプリライトロックを保存します。トランザクションがコミットされた後、ロックCF内の対応するデータはすぐに削除されます。したがって、ロックCFのデータのサイズは通常非常に小さい(1 GB未満)。ロックCFのデータが大幅に増加する場合は、多数のトランザクションがコミットされるのを待機していること、およびシステムがバグまたは障害に遭遇したことを意味します。
- 書き込みCF:ユーザーの実際に書き込まれたデータとMVCCメタデータ(データが属するトランザクションの開始タイムスタンプとコミットタイムスタンプ)を保存します。ユーザーがデータの行を書き込むとき、データ長が255バイト未満の場合、そのデータは書き込みCFに格納されます。それ以外の場合は、デフォルトのCFに保存されます。 TiDBでは、非一意インデックスに格納されている値が空であり、一意インデックスに格納されている値が主キーインデックスであるため、セカンダリインデックスは書き込みCFのスペースのみを占有します。
- デフォルトCF:255バイトより長いデータを保存します。
RocksDBのメモリ使用量
RocksDBは、読み取りパフォーマンスを向上させ、ディスクへの読み取り操作を減らすために、ディスクに保存されているファイルを特定のサイズ(デフォルトは64 KB)に基づいてブロックに分割します。ブロックを読み取るとき、最初にデータがメモリ内のBlockCacheにすでに存在するかどうかをチェックします。 trueの場合、ディスクにアクセスせずにメモリから直接データを読み取ることができます。
BlockCacheは、LRUアルゴリズムに従って、最も使用頻度の低いデータを破棄します。デフォルトでは、TiKVはシステムメモリの45%をBlockCacheに割り当てます。ユーザーは、 storage.block-cache.capacityの構成を自分で適切な値に変更することもできます。ただし、システムメモリ全体の60%を超えることはお勧めしません。
RocksDBに書き込まれるデータは、最初にMemTableに書き込まれます。 MemTableのサイズが128MBを超えると、新しいMemTableに切り替わります。 TiKVには2つのRocksDBインスタンス、合計4つのCFがあります。 CFごとの単一のMemTableのサイズ制限は128MBです。最大5つのMemTableが同時に存在できます。それ以外の場合、フォアグラウンド書き込みはブロックされます。この部分が占めるメモリは、最大で2.5 GB(4 x 5 x 128 MB)です。メモリのコストが少なくなるため、この制限を変更することはお勧めしません。
RocksDBのスペース使用量
- マルチバージョン:RocksDBはLSMツリー構造のKey-Valueストレージエンジンであるため、MemTableのデータは最初にL0にフラッシュされます。ファイルは生成された順序で配置されているため、L0のSSTの範囲が重複している可能性があります。その結果、同じキーのL0に複数のバージョンが含まれる場合があります。ファイルがL0からL1にマージされると、特定のサイズ(デフォルトは8 MB)の複数のファイルにカットされます。同じレベルの各ファイルのキー範囲は互いに重複しないため、L1以降のレベルの各キーには1つのバージョンしかありません。
- スペースの増幅:各レベルのファイルの合計サイズは、前のレベルのx(デフォルトは10)倍であるため、データの90%が最後のレベルに保存されます。また、RocksDBのスペース増幅が1.11を超えないことも意味します(L0のデータは少なく、無視できます)。
- TiKVの空間増幅:TiKVには独自のMVCC戦略があります。ユーザーがキーを書き込むと、RocksDBに書き込まれる実際のデータはkey + commit_tsになります。つまり、更新と削除によってRocksDBに新しいキーも書き込まれます。 TiKVは(RocksDBのDeleteインターフェイスを介して)古いバージョンのデータを定期的に削除するため、ユーザーがTiKVに保存したデータの実際のスペースは1.11に、過去10分間に書き込まれたデータを加えたものに拡大されたと見なすことができます。 (TiKVが古いデータをすぐにクリーンアップすると仮定します)。
RocksDBのバックグラウンドスレッドと圧縮
RocksDBでは、MemTableをSSTファイルに変換したり、さまざまなレベルでSSTファイルをマージしたりするなどの操作は、バックグラウンドスレッドプールで実行されます。バックグラウンドスレッドプールのデフォルトサイズは8です。マシン内のCPUの数が8以下の場合、バックグラウンドスレッドプールのデフォルトサイズはCPUの数から1を引いたものです。
一般的に、ユーザーはこの構成を変更する必要はありません。ユーザーがマシンに複数のTiKVインスタンスをデプロイする場合、またはマシンの読み取り負荷が比較的高く、書き込み負荷が低い場合は、必要に応じてrocksdb/max-background-jobsから3または4に調整できます。
WriteStall
RocksDBのL0は他のレベルとは異なります。 L0のSSTは、生成順に並べられています。 SST間のキー範囲は重複する可能性があります。したがって、クエリを実行するときに、L0の各SSTを順番にクエリする必要があります。クエリのパフォーマンスに影響を与えないように、L0にファイルが多すぎる場合、WriteStallがトリガーされて書き込みがブロックされます。
書き込み遅延が急激に増加した場合は、最初にGrafanaRocksDBKVパネルでWriteStallReasonメトリックを確認できます。 L0ファイルが多すぎるために発生したWriteStallの場合は、次の構成を64に調整できます。
rocksdb.defaultcf.level0-slowdown-writes-trigger
rocksdb.writecf.level0-slowdown-writes-trigger
rocksdb.lockcf.level0-slowdown-writes-trigger
rocksdb.defaultcf.level0-stop-writes-trigger
rocksdb.writecf.level0-stop-writes-trigger
rocksdb.lockcf.level0-stop-writes-trigger