TiKVの概要
TiKVは、分散型のトランザクション型Key-Valueデータベースであり、トランザクション型APIにACID準拠を提供します。 RocksDBに保存されているいかだコンセンサスアルゴリズムとコンセンサス状態の実装により、TiKVは複数のレプリカ間のデータの一貫性と高可用性を保証します。 TiKVは、TiDB分散データベースのストレージレイヤーとして、読み取りおよび書き込みサービスを提供し、アプリケーションからの書き込みデータを永続化します。また、TiDBクラスタの統計データも保存されます。
アーキテクチャの概要
TiKVは、GoogleSpannerの設計に基づいてマルチラフトグループレプリカメカニズムを実装します。リージョンは、Key-Valueデータ移動の基本単位であり、ストア内のデータ範囲を指します。各リージョンは複数のノードに複製されます。これらの複数のレプリカは、ラフトグループを形成します。リージョンのレプリカはピアと呼ばれます。通常、リージョンには3つのピアがあります。そのうちの1つは、読み取りおよび書き込みサービスを提供するリーダーです。 PDコンポーネントは、すべてのリージョンのバランスを自動的に取り、TiKVクラスタのすべてのノード間で読み取りと書き込みのスループットのバランスが取れていることを保証します。 PDと慎重に設計されたRaftグループにより、TiKVは水平方向のスケーラビリティに優れており、100TBを超えるデータを格納するために簡単に拡張できます。
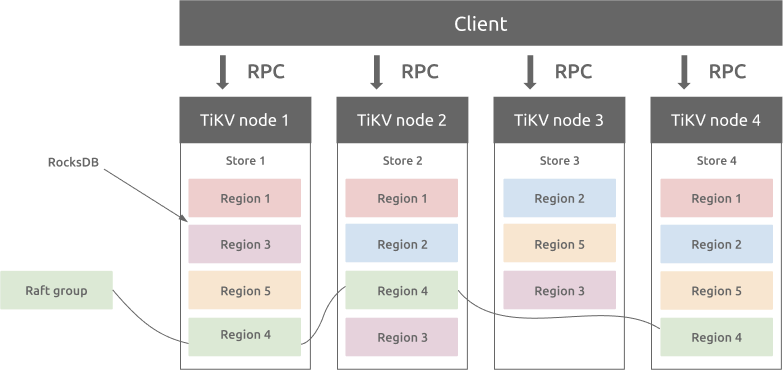
リージョンとRocksDB
各ストア内にRocksDBデータベースがあり、データをローカルディスクに保存します。すべてのリージョンデータは、各ストアの同じRocksDBインスタンスに保存されます。 Raftコンセンサスアルゴリズムに使用されるすべてのログは、各ストアの別のRocksDBインスタンスに保存されます。これは、シーケンシャルI/OのパフォーマンスがランダムI/Oよりも優れているためです。 Raftログとリージョンデータを格納するさまざまなRocksDBインスタンスを使用して、TiKVはRaftログとTiKVリージョンのすべてのデータ書き込み操作を1つのI / O操作に結合して、パフォーマンスを向上させます。
地域およびいかだコンセンサスアルゴリズム
リージョンのレプリカ間のデータの一貫性は、RaftConsensusAlgorithmによって保証されています。リージョンのリーダーのみが書き込みサービスを提供でき、データがリージョンのレプリカの大部分に書き込まれる場合にのみ、書き込み操作が成功します。
リージョンのサイズがしきい値(デフォルトでは144 MB)を超えると、TiKVはそれを2つ以上のリージョンに分割します。この操作により、クラスタのすべてのリージョンのサイズがほぼ同じになることが保証されます。これにより、PDコンポーネントがTiKVクラスタのノード間でリージョンのバランスを取るのに役立ちます。リージョンのサイズがしきい値よりも小さい場合、TiKVは2つの小さい隣接するリージョンを1つのリージョンにマージします。
PDがレプリカをあるTiKVノードから別のノードに移動するとき、最初にターゲットノードにLearnerレプリカを追加します。次に、LearnerレプリカのデータがLeaderレプリカのデータとほぼ同じになった後、PDはそれをFollowerレプリカに変更して削除します。ソースノードのフォロワーレプリカ。
リーダーレプリカをあるノードから別のノードに移動する場合も、同様のメカニズムがあります。違いは、学習者のレプリカがフォロワーのレプリカになった後、フォロワーのレプリカがリーダーとして自分自身を選出するための選挙を積極的に提案する「リーダーの転送」操作があることです。最後に、新しいリーダーは、ソースノードの古いリーダーレプリカを削除します。
分散トランザクション
TiKVは分散トランザクションをサポートしています。ユーザー(またはTiDB)は、同じリージョンに属しているかどうかを気にすることなく、複数のキーと値のペアを作成できます。 TiKVは、2フェーズコミットを使用してACID制約を実現します。詳細については、 TiDBオプティミスティックトランザクションモデルを参照してください。
TiKVコプロセッサー
TiDBは、一部のデータ計算ロジックをTiKVコプロセッサーにプッシュします。 TiKVコプロセッサーは、各リージョンの計算を処理します。 TiKVコプロセッサーに送信される各要求には、1つのリージョンのデータのみが含まれます。