BRツールの概要
BR (バックアップと復元)は、TiDBクラスタデータの分散バックアップと復元のためのコマンドラインツールです。
Dumplingと比較して、BRは膨大なデータ量を伴うシナリオに適しています。
定期的なバックアップと復元に加えて、互換性が確保されている限り、BRを使用して大規模なデータ移行を行うこともできます。
このドキュメントでは、BRの実装原則、推奨される展開構成、使用制限、およびBRを使用するためのいくつかの方法について説明します。
実装の原則
BRは、バックアップまたは復元コマンドを各TiKVノードに送信します。これらのコマンドを受信した後、TiKVは対応するバックアップまたは復元操作を実行します。
各TiKVノードには、バックアップ操作で生成されたバックアップファイルが保存され、復元中に保存されたバックアップファイルが読み取られるパスがあります。
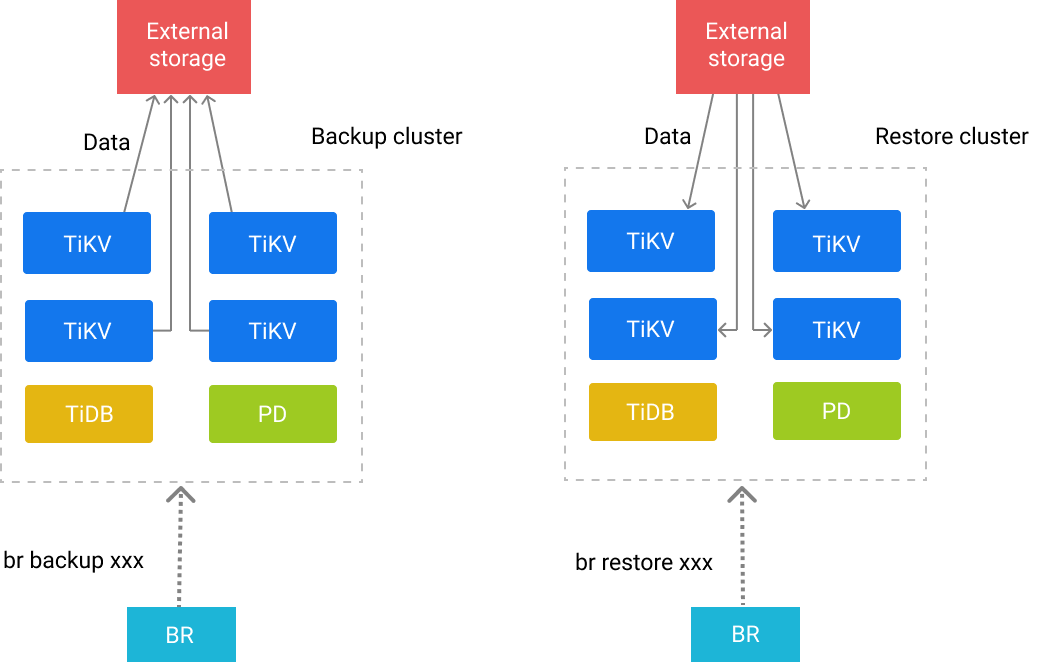
バックアップの原則
BRがバックアップ操作を実行すると、最初にPDから次の情報を取得します。
- バックアップスナップショットの時刻としての現在のTS(タイムスタンプ)
- 現在のクラスタのTiKVノード情報
これらの情報に従って、BRは内部でmysqlインスタンスを起動して、TSに対応するデータベースまたはテーブル情報を取得し、同時にシステムデータベース( information_schema )を除外しperformance_schema 。
backupサブコマンドによると、BRは次の2種類のバックアップロジックを採用しています。
- フルバックアップ:BRはすべてのテーブルをトラバースし、各テーブルに従ってバックアップされるKV範囲を構築します。
- 単一テーブルのバックアップ:BRは、単一のテーブルに従ってバックアップされるKV範囲を構築します。
最後に、BRはバックアップするKV範囲を収集し、完全なバックアップ要求をクラスタのTiKVノードに送信します。
リクエストの構造:
BackupRequest{
ClusterId, // The cluster ID.
StartKey, // The starting key of the backup (backed up).
EndKey, // The ending key of the backup (not backed up).
StartVersion, // The version of the last backup snapshot, used for the incremental backup.
EndVersion, // The backup snapshot time.
StorageBackend, // The path where backup files are stored.
RateLimit, // Backup speed (MB/s).
}
バックアップ要求を受信した後、TiKVノードはノード上のすべてのリージョンリーダーをトラバースして、このリクエストのKV範囲と重複するリージョンを見つけます。 TiKVノードは、範囲内のデータの一部またはすべてをバックアップし、対応するSSTファイルを生成します。
対応するリージョンのデータのバックアップが終了すると、TiKVノードはメタデータをBRに返します。 BRはメタデータを収集し、復元に使用されるbackupmetaのファイルに保存します。
StartVersionが0でない場合、バックアップは増分バックアップと見なされます。 KVに加えて、BRは[StartVersion, EndVersion)の間のDDLも収集します。データの復元中、これらのDDLが最初に復元されます。
バックアップコマンドの実行時にチェックサムが有効になっている場合、BRはデータチェックのためにバックアップされた各テーブルのチェックサムを計算します。
バックアップファイルの種類
バックアップファイルが保存されるパスには、次の2種類のバックアップファイルが生成されます。
- SSTファイル:TiKVノードがバックアップしたデータを保存します。
backupmetaファイル:バックアップファイルの数、キー範囲、サイズ、ハッシュ(sha256)値など、このバックアップ操作のメタデータを保存します。backup.lockファイル:複数のバックアップ操作が同じディレクトリにデータを保存するのを防ぎます。
SSTファイル名の形式
SSTファイルはstoreID_regionID_regionEpoch_keyHash_cfの形式で名前が付けられます。ここで
storeIDはTiKVノードIDです。regionIDはリージョンIDです。regionEpochはリージョンのバージョン番号です。keyHashは、範囲のstartKeyのハッシュ(sha256)値であり、キーの一意性を保証します。cfはRocksDBのカラムファミリーを示します(デフォルトではdefaultまたはwrite)。
修復の原則
データ復元プロセス中に、BRは次のタスクを順番に実行します。
バックアップパス内の
backupmetaのファイルを解析し、TiDBインスタンスを内部で開始して、解析された情報に基づいて対応するデータベースとテーブルを作成します。解析されたSSTファイルをテーブルに従って集約します。
SSTファイルのキー範囲に従ってリージョンを事前に分割し、すべてのリージョンが少なくとも1つのSSTファイルに対応するようにします。
復元する各テーブルと、各テーブルに対応するSSTファイルをトラバースします。
SSTファイルに対応するリージョンを検索し、ファイルをダウンロードするための要求を対応するTiKVノードに送信します。次に、ファイルが正常にダウンロードされた後、ファイルのロード要求を送信します。
TiKVがSSTファイルをロードする要求を受信した後、TiKVはRaftメカニズムを使用して、SSTデータの強力な整合性を確保します。ダウンロードしたSSTファイルが正常にロードされた後、ファイルは非同期で削除されます。
復元操作が完了すると、BRは復元されたデータに対してチェックサム計算を実行して、保存されたデータとバックアップされたデータを比較します。
デプロイを導入して使用する
推奨される展開構成
- PDノードにBRをデプロイすることをお勧めします。
- 高性能SSDをBRノードとすべてのTiKVノードにマウントすることをお勧めします。 10ギガビットネットワークカードをお勧めします。そうしないと、バックアップおよび復元プロセス中に帯域幅がパフォーマンスのボトルネックになる可能性があります。
ノート:
ネットワークディスクをマウントしない場合、または他の共有ストレージを使用しない場合、BRによってバックアップされるデータは各TiKVノードで生成されます。 BRはリーダーのレプリカのみをバックアップするため、リーダーのサイズに基づいて各ノードに予約されているスペースを見積もる必要があります。
TiDBはデフォルトでロードバランシングにリーダー数を使用するため、リーダーのサイズは大きく異なる可能性があります。これにより、各ノードでバックアップデータが不均一に分散される可能性があります。
使用制限
バックアップと復元にBRを使用する場合の制限は次のとおりです。
- BRがTiCDC/Drainerのアップストリームクラスタにデータを復元する場合、TiCDC/Drainerは復元されたデータをダウンストリームに複製できません。
- BRはKVデータのみをバックアップするため、BRは同じ
new_collations_enabled_on_first_bootstrapの値を持つクラスター間の操作のみをサポートします。バックアップするクラスタと復元するクラスタが異なる照合を使用する場合、データ検証は失敗します。したがって、クラスタを復元する前に、select VARIABLE_VALUE from mysql.tidb where VARIABLE_NAME='new_collation_enabled';ステートメントのクエリ結果からのスイッチ値がバックアッププロセス中のスイッチ値と一致していることを確認してください。
互換性
BRとTiDBクラスタの互換性の問題は、次のカテゴリに分類されます。
BRの一部のバージョンは、TiDBクラスタのインターフェースと互換性がありません。
- v5.4.0より前のBRバージョンは、
charset=GBKのテーブルのリカバリーをサポートしていません。 BRのどのバージョンも、v5.4.0より前のTiDBクラスターへのcharset=GBKのテーブルのリカバリーをサポートしていません。
- v5.4.0より前のBRバージョンは、
一部の機能が有効または無効になると、KV形式が変更される場合があります。これらの機能がバックアップおよび復元中に一貫して有効または無効にされていない場合、互換性の問題が発生する可能性があります。
これらの機能は次のとおりです。
ただし、バックアップおよび復元中に上記の機能が一貫して有効または無効になっていることを確認した後でも、BRとTiKV / TiDB / PD間の内部バージョンまたはインターフェイスの一貫性がないため、互換性の問題が発生する可能性があります。このような場合を回避するために、BRにはバージョンチェックが組み込まれています。
バージョンチェック
バックアップと復元を実行する前に、BRはTiDBクラスタのバージョンとBRのバージョンを比較およびチェックします。メジャーバージョンの不一致がある場合(たとえば、BRv4.xとTiDBv5.x)、BRは終了するようにリマインダーを表示します。バージョンチェックを強制的にスキップするには、 --check-requirements=falseを設定します。
バージョンチェックをスキップすると、非互換性が生じる可能性があることに注意してください。 BRバージョンとTiDBバージョン間のバージョン互換性情報は次のとおりです。
mysqlシステムスキーマのテーブルデータのバックアップと復元(実験的機能)
v5.1.0より前では、BRはバックアップ中にシステムスキーマmysqlからデータを除外していました。 v5.1.0以降、BRは、システムスキーマmysql.*を含むすべてのデータをデフォルトでバックアップします。ただし、 mysql.*でシステムテーブルを復元する技術的な実装はまだ完了していないため、システムスキーマmysqlのテーブルはデフォルトでは復元されません。
システムテーブルのデータ(たとえば、 mysql.usertable1 )をシステムスキーマmysqlに復元する場合は、 filterパラメータを設定してテーブル名( -f "mysql.usertable1" )をフィルタリングできます。設定後、システムテーブルは最初に一時スキーマに復元され、次に名前を変更してシステムスキーマに復元されます。
以下のシステムテーブルは、技術的な理由により正しく復元できないことに注意してください。 -f "mysql.*"を指定しても、これらのテーブルは復元されません。
- 統計に関連するテーブル: "stats_buckets"、 "stats_extended"、 "stats_feedback"、 "stats_fm_sketch"、 "stats_histograms"、 "stats_meta"、 "stats_top_n"
- 特権またはシステムに関連するテーブル: "tidb"、 "global_variables"、 "columns_priv"、 "db"、 "default_roles"、 "global_grants"、 "global_priv"、 "role_edges"、 "tables_priv"、 "user"、 "gc_delete_range "、" Gc_delete_range_done "、" schema_index_usage "
BRを実行するために必要な最小マシン構成
BRを実行するために必要な最小のマシン構成は次のとおりです。
一般的なシナリオ(バックアップと復元用に1000テーブル未満)では、実行時のBRのCPU消費量は200%を超えず、メモリ消費量は4GBを超えません。ただし、多数のテーブルをバックアップおよび復元する場合、BRは4GBを超えるメモリを消費する可能性があります。 24000テーブルをバックアップするテストでは、BRは約2.7 GBのメモリを消費し、CPU消費量は100%未満のままです。
ベストプラクティス
以下は、バックアップと復元にBRを使用するための推奨操作です。
- アプリケーションへの影響を最小限に抑えるために、オフピーク時にバックアップ操作を実行することをお勧めします。
- BRは、さまざまなトポロジのクラスターでの復元をサポートしています。ただし、オンラインアプリケーションは、復元操作中に大きな影響を受けます。オフピーク時に復元を実行するか、
rate-limitを使用してレートを制限することをお勧めします。 - 複数のバックアップ操作を連続して実行することをお勧めします。さまざまなバックアップ操作を並行して実行すると、バックアップのパフォーマンスが低下し、オンラインアプリケーションにも影響します。
- 複数の復元操作を連続して実行することをお勧めします。さまざまな復元操作を並行して実行すると、リージョンの競合が増加し、復元のパフォーマンスも低下します。
- バックアップファイルの収集と管理を容易にするために、
-sで指定されたバックアップパスに共有ストレージ(NFSなど)をマウントすることをお勧めします。 - ストレージハードウェアのスループットによってバックアップと復元の速度が制限されるため、スループットの高いストレージハードウェアを使用することをお勧めします。
- 移行時間を短縮するために、バックアップ操作中はチェックサム機能(
--checksum = false)を無効にし、復元操作中のみ有効にすることをお勧めします。これは、BRがデフォルトで、バックアップおよび復元操作の後にそれぞれチェックサム計算を実行して、保存されたデータを対応するクラスタデータと比較して精度を確保するためです。
BRの使い方
現在、BRツールを実行するために次のメソッドがサポートされています。
- SQLステートメントを使用する
- コマンドラインツールを使用する
- Kubernetes環境でBRを使用する
SQLステートメントを使用する
TiDBは、 BACKUPつとRESTOREのSQLステートメントの両方をサポートします。これらの操作の進行状況は、ステートメントSHOW BACKUPS|RESTORESで監視できます。
コマンドラインツールを使用する
brコマンドラインユーティリティは別ダウンロードとして使用できます。詳細については、 バックアップと復元にBRコマンドラインを使用するを参照してください。
Kubernetes環境で
Kubernetes環境では、BRツールを使用してTiDBクラスタデータをS3互換ストレージ、Googleクラウドストレージ(GCS)、永続ボリューム(PV)にバックアップし、それらを復元できます。
ノート:
AmazonS3およびGoogleCloudStorageのパラメーターの説明については、 外部ストレージのドキュメントを参照してください。
- BRを使用してS3互換ストレージにデータをバックアップする
- BRを使用してS3互換ストレージからデータを復元する
- BRを使用してデータをGCSにバックアップする
- BRを使用してGCSからデータを復元する
- BRを使用してデータをPVにバックアップする
- BRを使用してPVからデータを復元する