BRのユースケース
BRは、TiDBクラスタデータの分散バックアップと復元のためのツールです。
このドキュメントでは、次のユースケースでBRを実行する方法について説明します。
- 単一のテーブルをネットワークディスクにバックアップします(実稼働環境で推奨)
- ネットワークディスクからデータを復元する(実稼働環境で推奨)
- 単一のテーブルをローカルディスクにバックアップします(テスト環境で推奨)
- ローカルディスクからデータを復元する(テスト環境で推奨)
このドキュメントは、次の目標の達成を支援することを目的としています。
- ネットワークディスクまたはローカルディスクを使用してデータを正しくバックアップおよび復元します。
- メトリックの監視を通じて、バックアップまたは復元操作のステータスを取得します。
- 操作中にパフォーマンスを調整する方法を学びます。
- バックアップ操作中に発生する可能性のある異常のトラブルシューティングを行います。
観客
TiDBとTiKVの基本的な知識が必要です。
読み進める前に、 BRツールの概要 、特に使用制限とベストプラクティスを読んだことを確認してください。
前提条件
このセクションでは、TiDBをデプロイするための推奨される方法、クラスタのバージョン、TiKVクラスタのハードウェア情報、およびユースケースのデモンストレーション用のクラスタ構成を紹介します。
独自のハードウェアと構成に基づいて、バックアップまたは復元操作のパフォーマンスを見積もることができます。
展開方法
TiUPを使用してTiDBクラスタをデプロイし、 TiDBツールキットをダウンロードしてBRを取得することをお勧めします。
クラスターバージョン
- TiDB:v5.0.0
- TiKV:v5.0.0
- PD:v5.0.0
- BR:v5.0.0
ノート:
v5.0.0は、このドキュメントが作成された時点での最新バージョンでした。最新バージョンのTiDB / TiKV / PD / BRを使用し、BRバージョンがTiDBバージョンと一致していることを確認することをお勧めします。
TiKVハードウェア情報
- オペレーティングシステム:CentOS Linuxリリース7.6.1810(コア)
- CPU:16コアの共通KVMプロセッサ
- RAM:32GB
- ディスク:500G SSD * 2
- NIC:10ギガビットネットワークカード
クラスター構成
BRはコマンドをTiKVクラスタに直接送信し、TiDBサーバーに依存しないため、BRを使用するときにTiDBサーバーを構成する必要はありません。
- TiKV:デフォルト構成
- PD:デフォルト構成
ユースケース
このドキュメントでは、次の使用例について説明します。
- 単一のテーブルをネットワークディスクにバックアップします(実稼働環境で推奨)
- ネットワークディスクからデータを復元する(実稼働環境で推奨)
- 単一のテーブルをローカルディスクにバックアップします(テスト環境で推奨)
- ローカルディスクからデータを復元する(テスト環境で推奨)
ネットワークディスクを使用してデータをバックアップおよび復元することをお勧めします。これにより、バックアップファイルの収集が不要になり、特にTiKVクラスタが大規模な場合にバックアップ効率が大幅に向上します。
バックアップまたは復元操作の前に、いくつかの準備を行う必要があります。
バックアップの準備
BRツールはすでにGCへの自己適応をサポートしています。 backupTS (デフォルトでは最新のPDタイムスタンプ)をPDのsafePointに自動的に登録して、バックアップ中にTiDBのGCセーフポイントが前進しないようにし、GC構成を手動で設定することを回避します。
br backupコマンドの使用法の詳細については、 バックアップと復元にBRコマンドラインを使用するを参照してください。
br backupコマンドを実行する前に、TiDBクラスタでDDLが実行されていないことを確認してください。- バックアップが作成されるストレージデバイスに十分なスペースがあることを確認してください(バックアップクラスタのディスクスペースの1/3以上)。
修復の準備
br restoreコマンドを実行する前に、新しいクラスタをチェックして、クラスタのテーブルに重複した名前がないことを確認してください。
単一のテーブルをネットワークディスクにバックアップします(実稼働環境で推奨)
br backupコマンドを使用して、単一のテーブルデータ--db batchmark --table order_lineをネットワークディスク内の指定されたパスlocal:///br_dataにバックアップします。
バックアップの前提条件
- バックアップの準備
- 高性能SSDハードディスクホストをデータを格納するNFSサーバーとして構成し、すべてのBRノード、TiKVノード、およびTiFlashノードをNFSクライアントとして構成します。 NFSクライアントがサーバーにアクセスできるように、同じパス(たとえば、
/br_data)をNFSサーバーにマウントします。 - NFSサーバーとすべてのNFSクライアント間の合計転送速度は、少なくとも
the number of TiKV instances * 150MB/sに達する必要があります。そうしないと、ネットワークI/Oがパフォーマンスのボトルネックになる可能性があります。
ノート:
- データのバックアップ中は、リーダーレプリカのデータのみがバックアップされるため、クラスタにTiFlashレプリカが存在する場合でも、BRはTiFlashノードをマウントせずにバックアップを完了できます。
- データを復元する場合、BRはすべてのレプリカのデータを復元します。また、TiFlashノードは、復元を完了するためにBRのバックアップデータにアクセスする必要があります。したがって、復元する前に、TiFlashノードをNFSサーバーにマウントする必要があります。
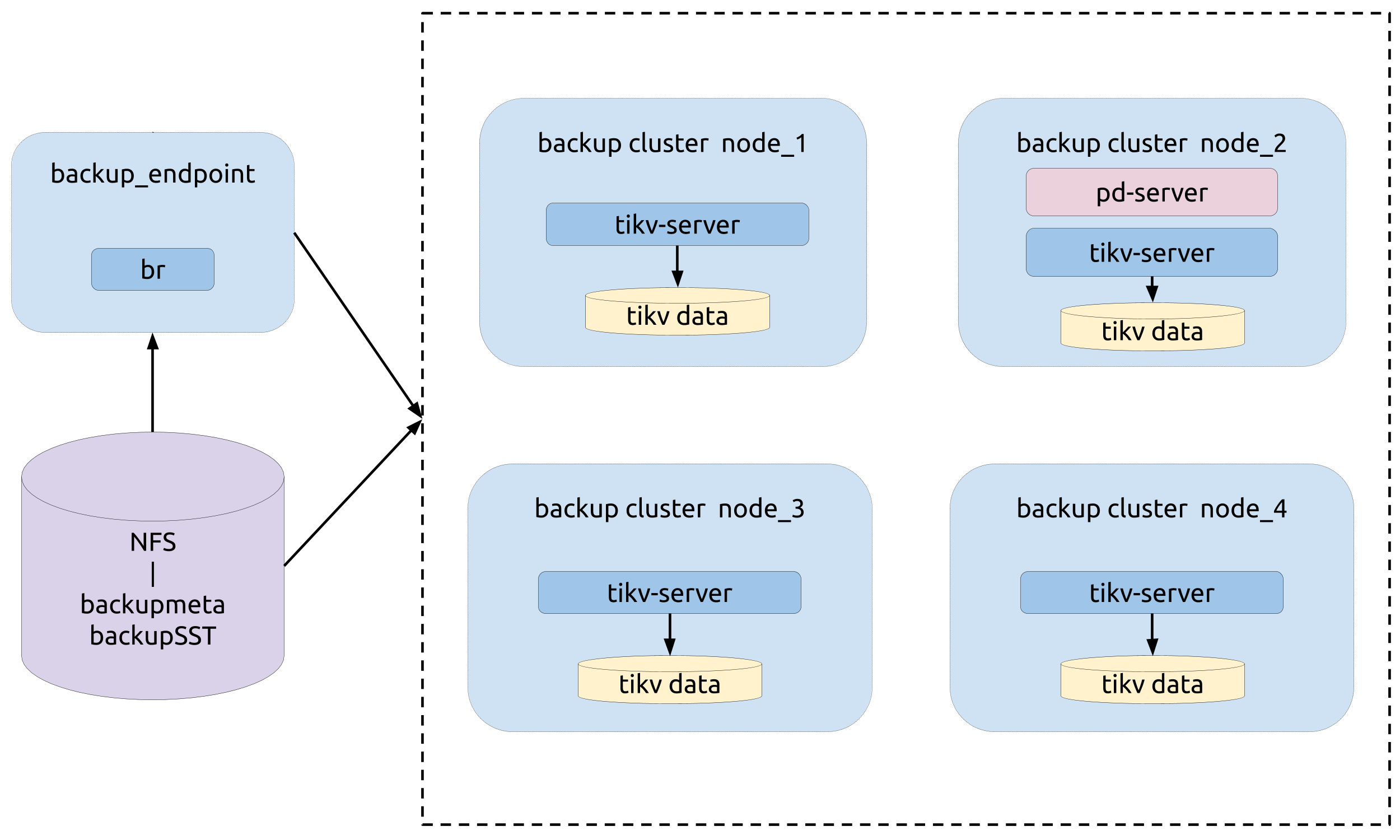
トポロジー
次の図は、BRの類型を示しています。
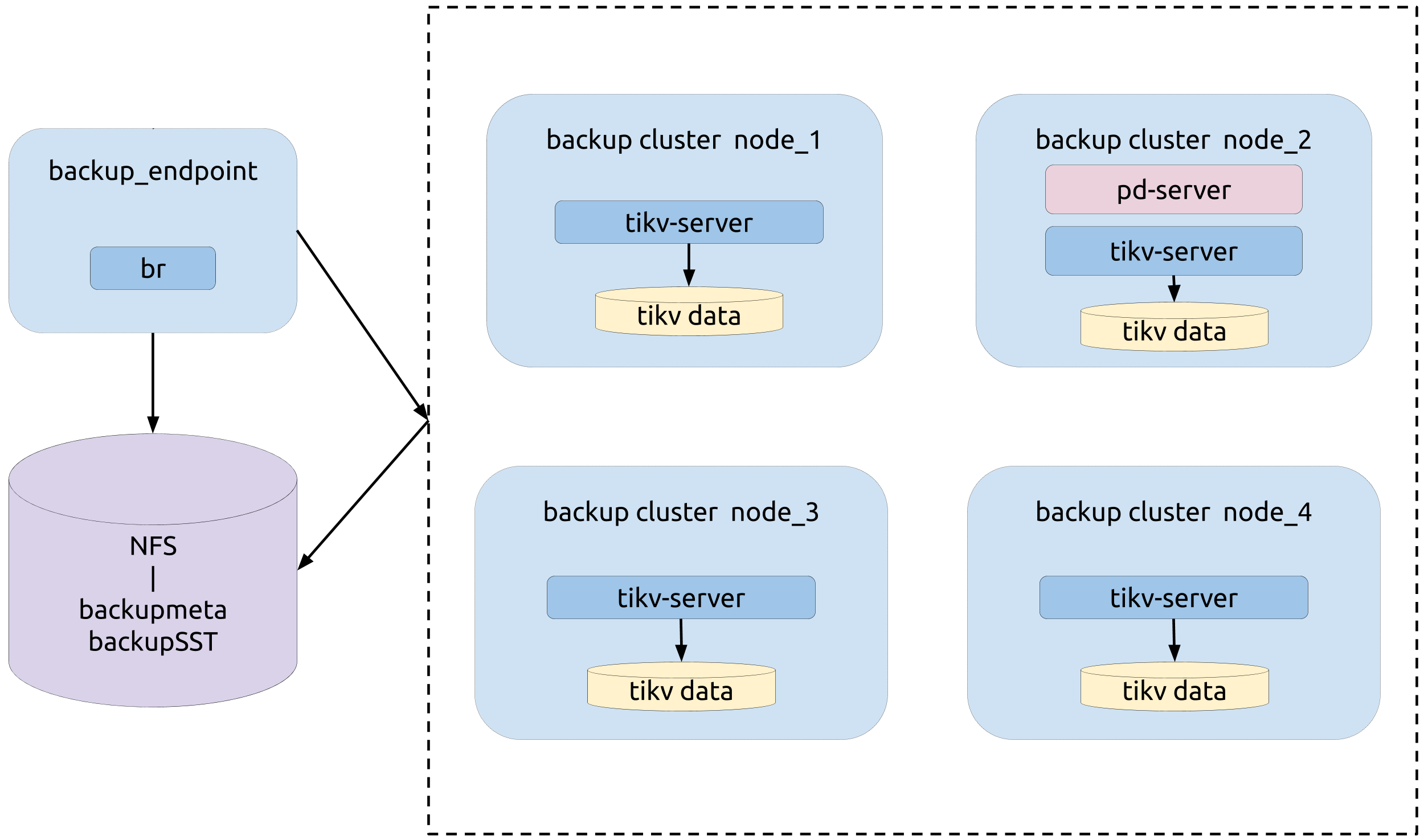
バックアップ操作
バックアップ操作の前に、 admin checksum table order_lineコマンドを実行して、バックアップするテーブルの統計情報を取得します( --db batchmark --table order_line )。次の画像は、この情報の例を示しています。
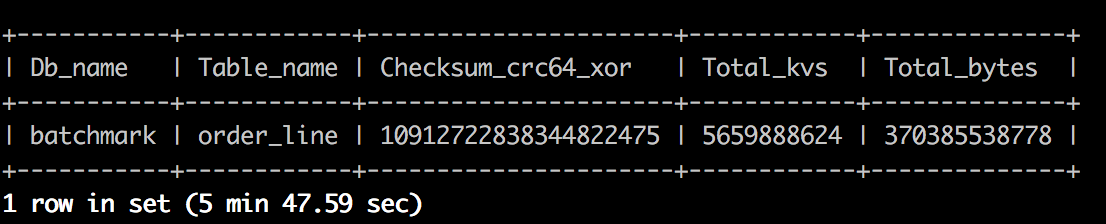
br backupコマンドを実行します。
bin/br backup table \
--db batchmark \
--table order_line \
-s local:///br_data \
--pd ${PD_ADDR}:2379 \
--log-file backup-nfs.log
バックアップの監視メトリック
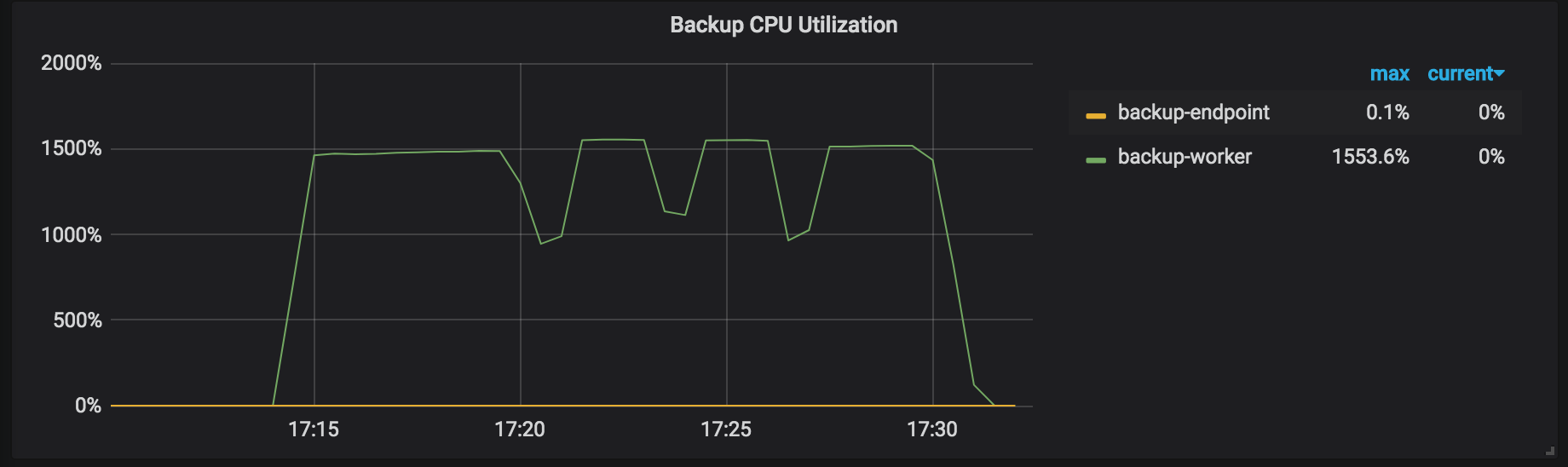
バックアッププロセス中は、監視パネルの次のメトリックに注意して、バックアッププロセスのステータスを取得してください。
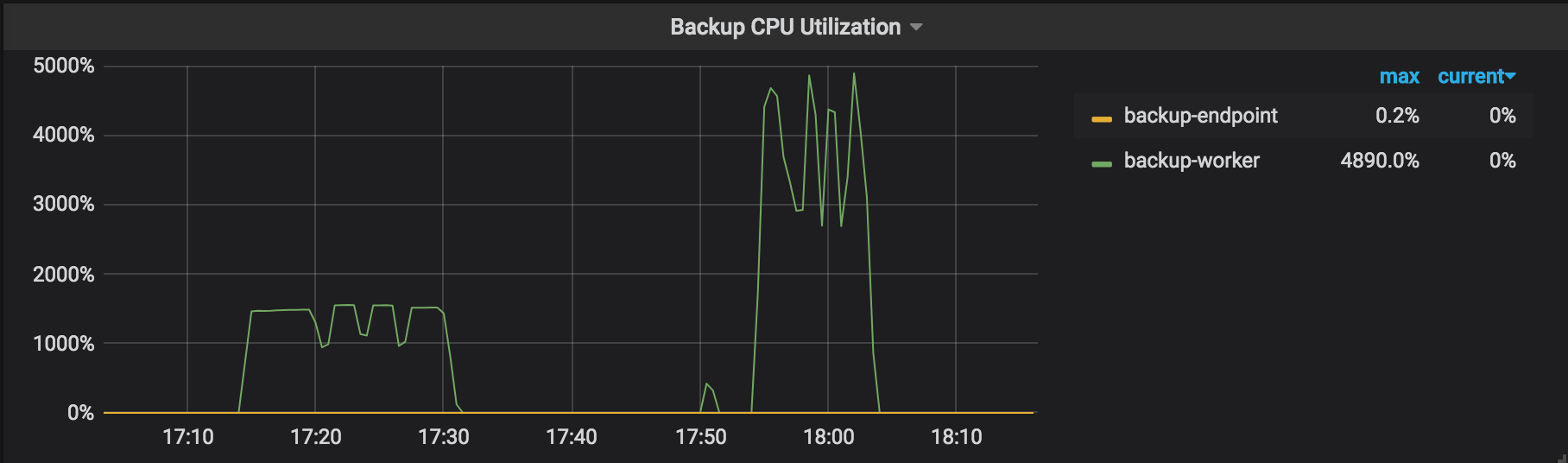
バックアップCPU使用率:バックアップ操作で動作している各TiKVノードのCPU使用率(たとえば、backup-workerとbackup-endpoint)。
IO使用率:バックアップ操作で動作している各TiKVノードのI/O使用率。
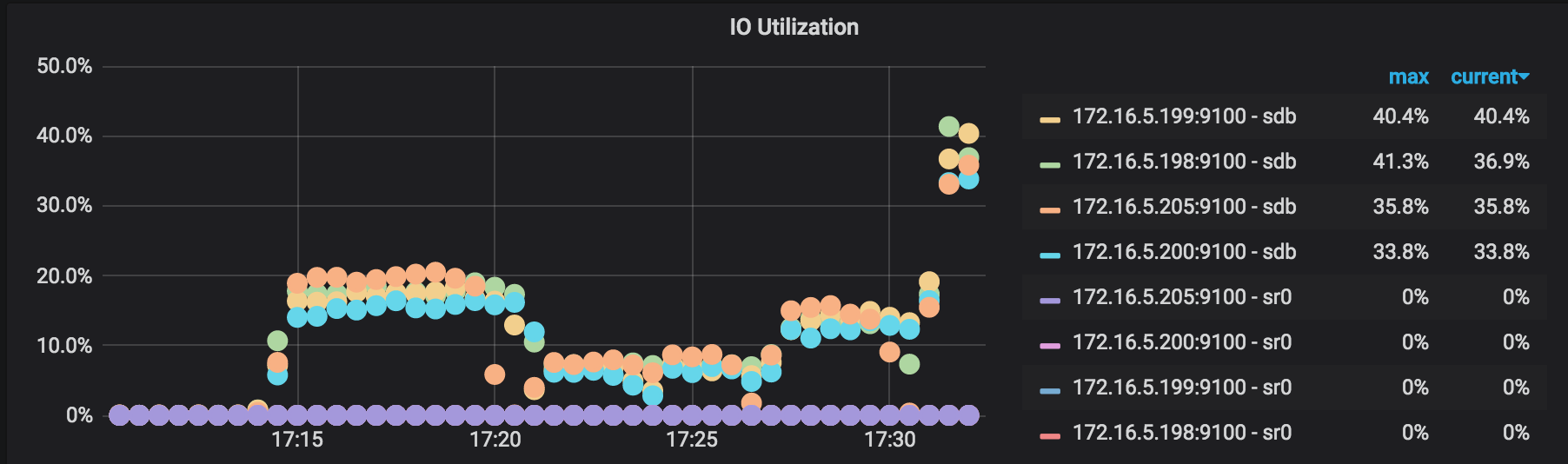
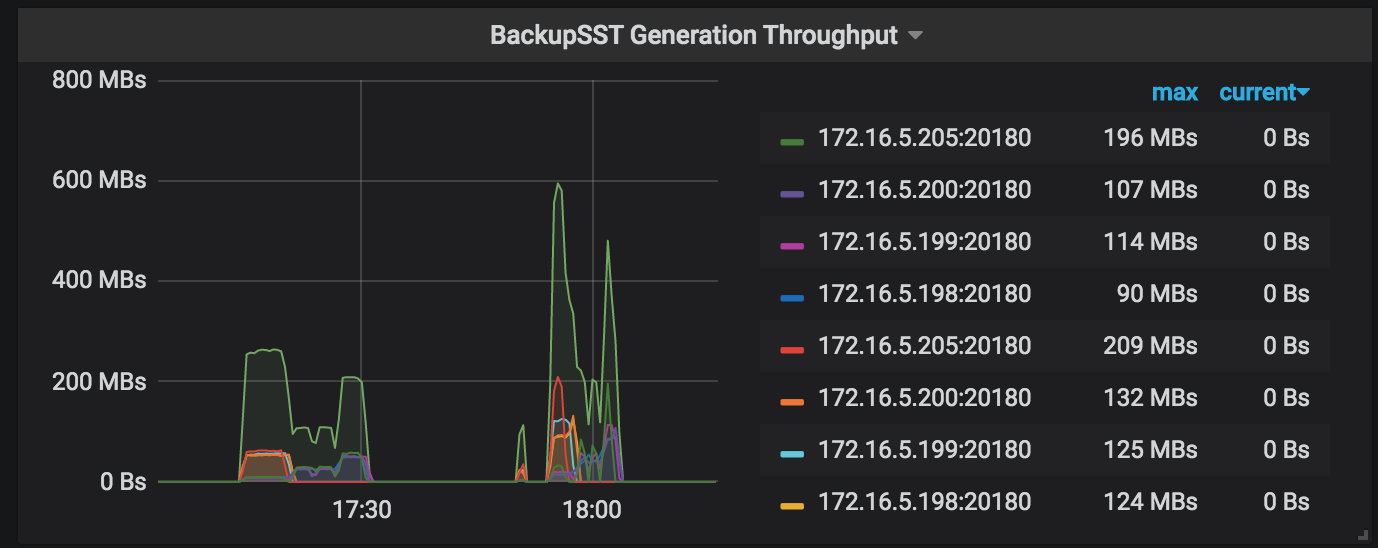
BackupSST生成スループット:バックアップ操作で動作している各TiKVノードのbackupSST生成スループット。通常は約150MB/秒です。
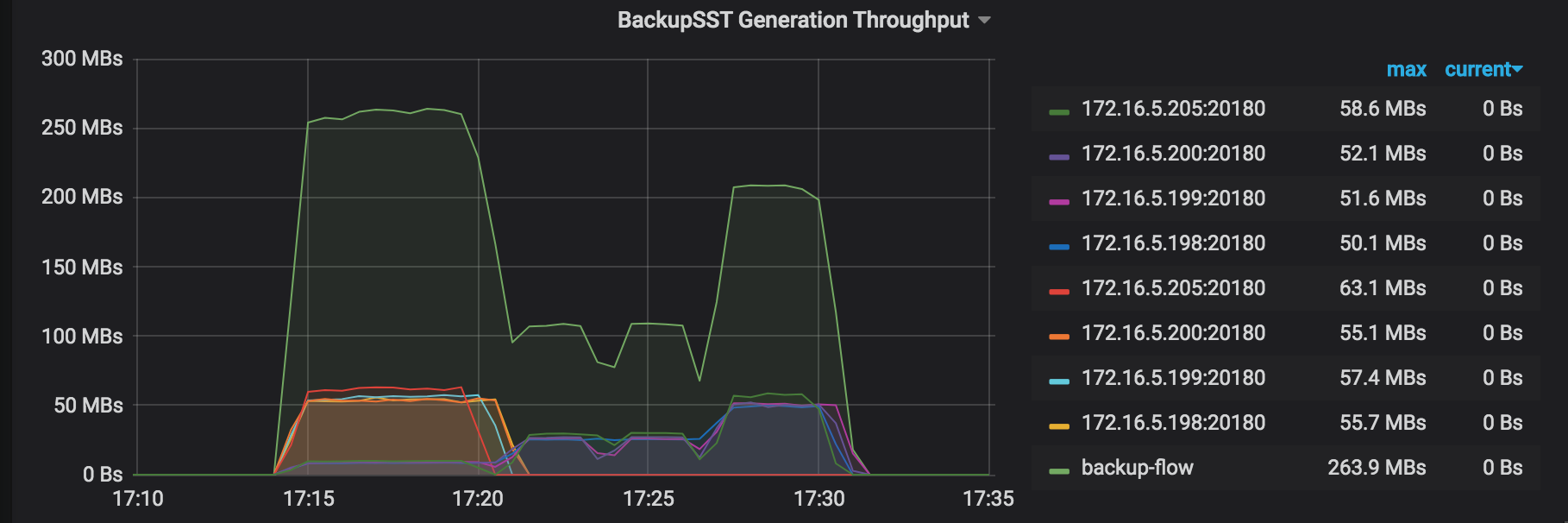
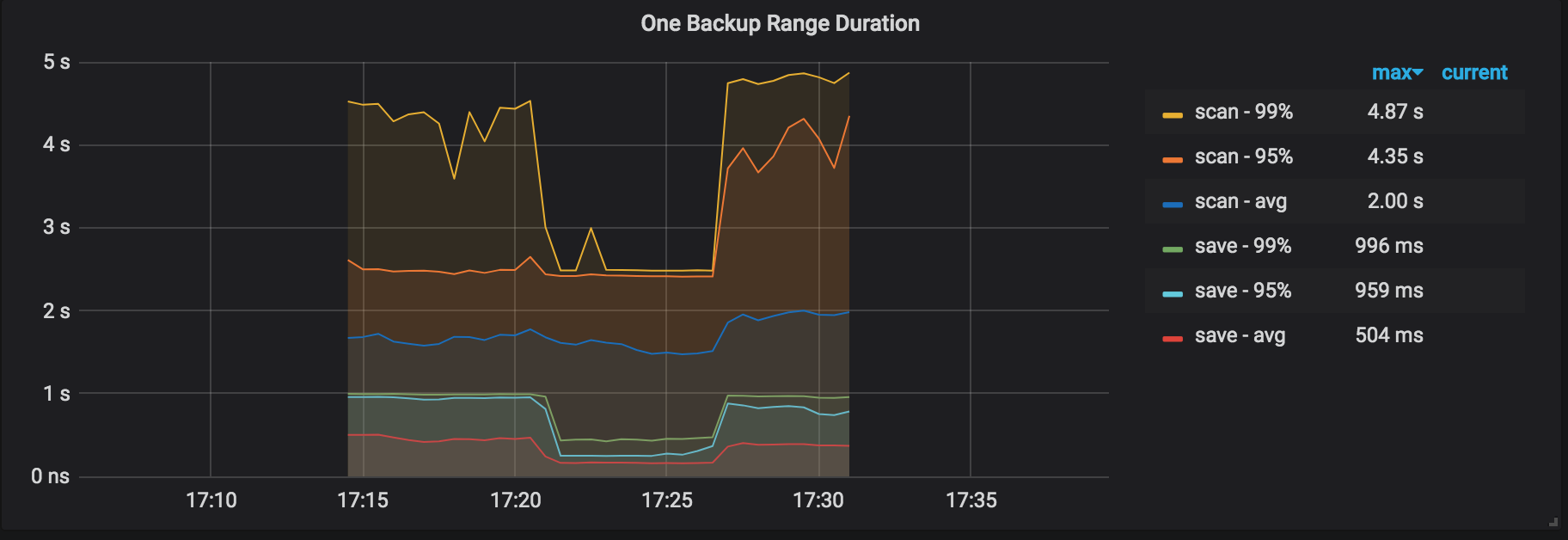
1つのバックアップ範囲期間:範囲をバックアップする期間。これは、KVをスキャンし、その範囲をbackupSSTファイルとして保存するための合計時間コストです。
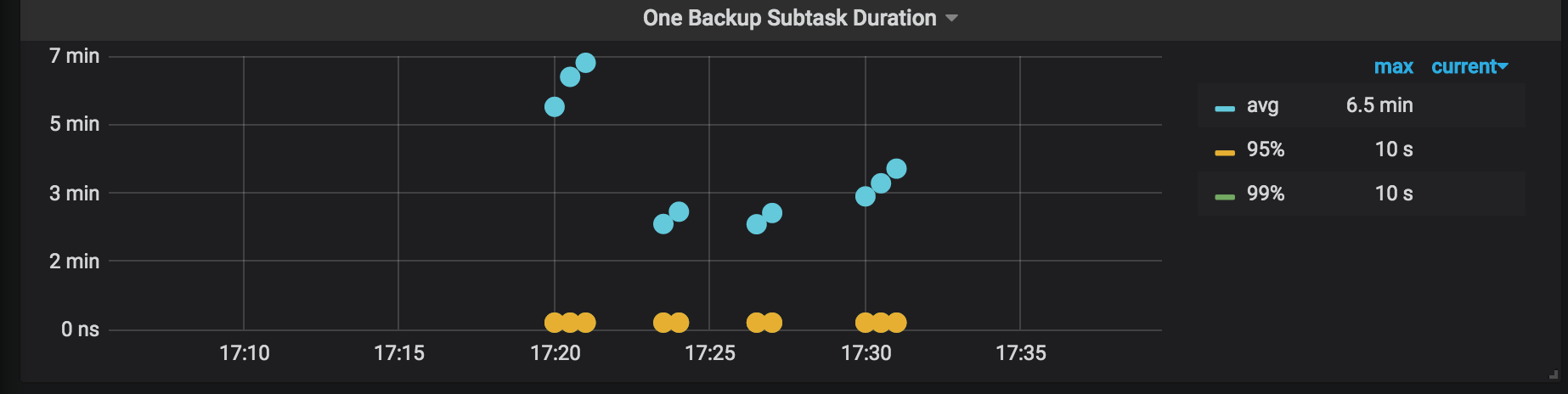
1つのバックアップサブタスク期間:バックアップタスクが分割される各サブタスクの期間。
ノート:
- このタスクでは、バックアップされる単一のテーブルに3つのインデックスがあり、タスクは通常4つのサブタスクに分割されます。
- 次の画像のパネルには13のポイントがあります。これは、9回(つまり、13〜4回)の再試行を意味します。リージョンのスケジューリングはバックアッププロセス中に発生する可能性があるため、数回の再試行が正常です。
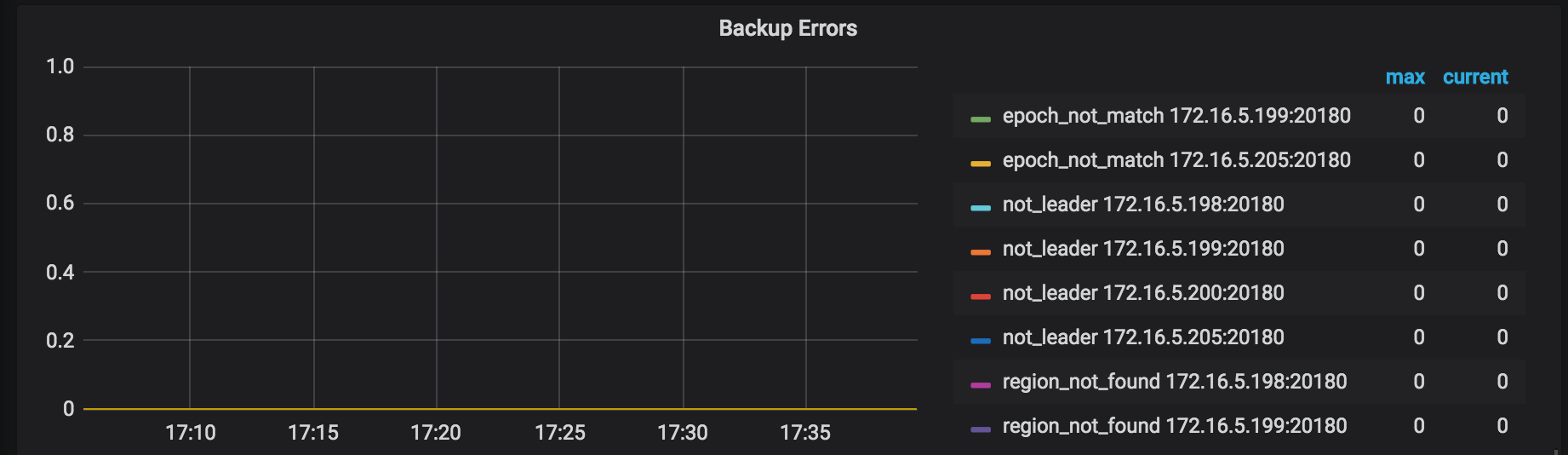
バックアップエラー:バックアッププロセス中に発生したエラー。通常の状況ではエラーは発生しません。いくつかのエラーが発生した場合でも、バックアップ操作には再試行メカニズムがあり、バックアップ時間が長くなる可能性がありますが、操作の正確性には影響しません。
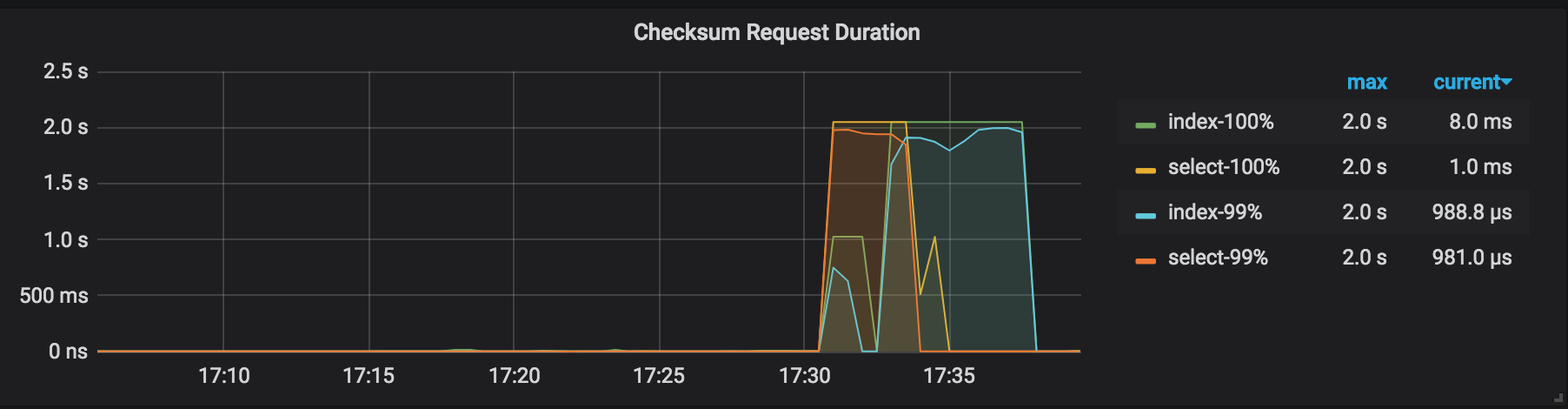
チェックサム要求期間:バックアップクラスタでの管理チェックサム要求の期間。
バックアップ結果の説明
バックアップが完了すると、BRはバックアップの概要をコンソールに出力します。
バックアップコマンドを実行する前に、ログが保存されるパスが指定されています。このログからバックアップ操作の統計情報を取得できます。このログで「概要」を検索すると、次の情報が表示されます。
["Full backup Success summary:
total backup ranges: 2,
total success: 2,
total failed: 0,
total take(Full backup time): 31.802912166s,
total take(real time): 49.799662427s,
total size(MB): 5997.49,
avg speed(MB/s): 188.58,
total kv: 120000000"]
["backup checksum"=17.907153678s]
["backup fast checksum"=349.333µs]
["backup total regions"=43]
[BackupTS=422618409346269185]
[Size=826765915]
上記のログには、次の情報が含まれています。
- バックアップ期間:
total take(Full backup time): 31.802912166s - アプリケーションの合計実行時間:
total take(real time): 49.799662427s - バックアップデータサイズ:
total size(MB): 5997.49 - バックアップスループット:
avg speed(MB/s): 188.58 - バックアップされたKVペアの数:
total kv: 120000000 - バックアップチェックサム期間:
["backup checksum"=17.907153678s] - 各テーブルのチェックサム、KVペア、およびバイトを計算する合計期間:
["backup fast checksum"=349.333µs] - バックアップリージョンの総数:
["backup total regions"=43] - 圧縮後のディスク内のバックアップデータの実際のサイズ:
[Size=826765915] - バックアップデータのスナップショットタイムスタンプ:
[BackupTS=422618409346269185]
上記の情報から、単一のTiKVインスタンスのスループットを計算できます: avg speed(MB/s) / tikv_count = 62.86 。
性能調整
バックアッププロセス中にTiKVのリソース使用量が明らかなボトルネックにならない場合(たとえば、 バックアップの監視メトリックでは、バックアップワーカーのCPU使用率が最も高いのは約1500%で、全体的なI / O使用率は30%未満です)。パフォーマンスを調整するために、 --concurrency (デフォルトでは4 )の値を増やすことを試みることができます。ただし、このパフォーマンス調整方法は、多くの小さなテーブルのユースケースには適していません。次の例を参照してください。
bin/br backup table \
--db batchmark \
--table order_line \
-s local:///br_data/ \
--pd ${PD_ADDR}:2379 \
--log-file backup-nfs.log \
--concurrency 16
調整されたパフォーマンス結果は次のとおりです(同じデータサイズで)。
- バックアップ期間:
total take(s)が986.43から535.53に減少 - バックアップスループット:
avg speed(MB/s)が358.09から659.59に増加 - 単一のTiKVインスタンスのスループット:
avg speed(MB/s)/tikv_countが89から164.89に増加
ネットワークディスクからデータを復元する(実稼働環境で推奨)
br restoreコマンドを使用して、完全なバックアップデータをオフラインクラスタに復元します。現在、BRはオンラインクラスタへのデータの復元をサポートしていません。
復元の前提条件
トポロジー
次の図は、BRの類型を示しています。
復元操作
修復する前に、 修復の準備を参照して準備してください。
br restoreコマンドを実行します。
bin/br restore table --db batchmark --table order_line -s local:///br_data --pd 172.16.5.198:2379 --log-file restore-nfs.log
復元の監視メトリック
復元プロセス中は、監視パネルの次のメトリックに注意して、復元プロセスのステータスを取得してください。
CPU使用率:復元操作で動作している各TiKVノードのCPU使用率。
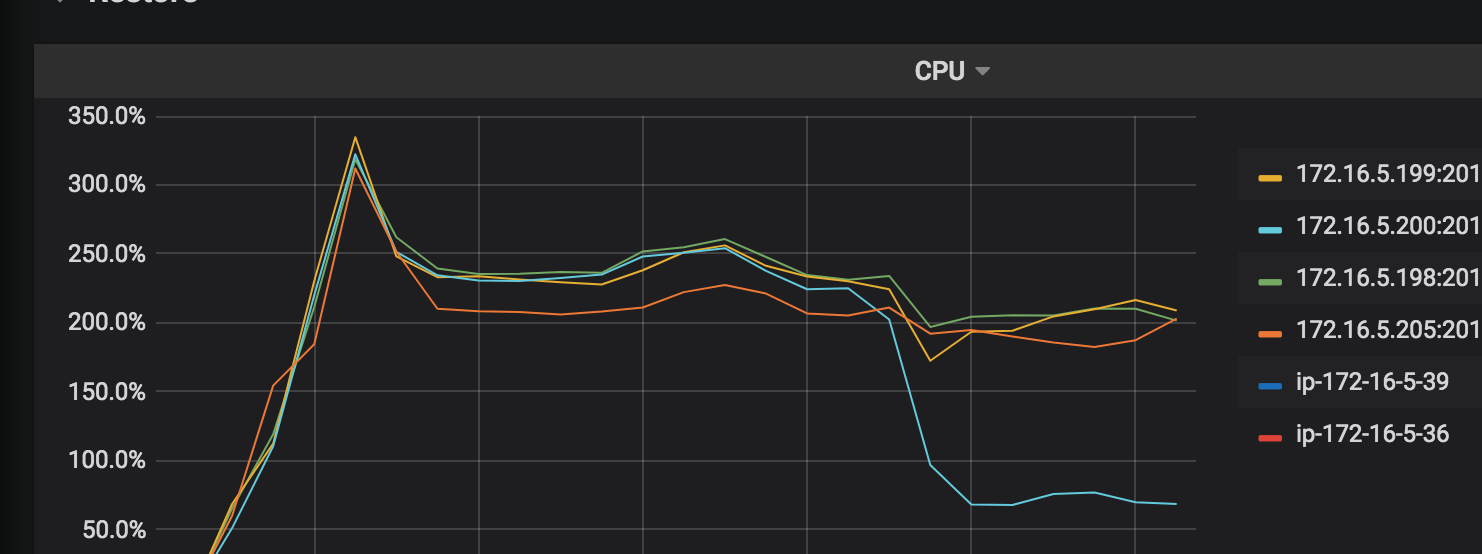
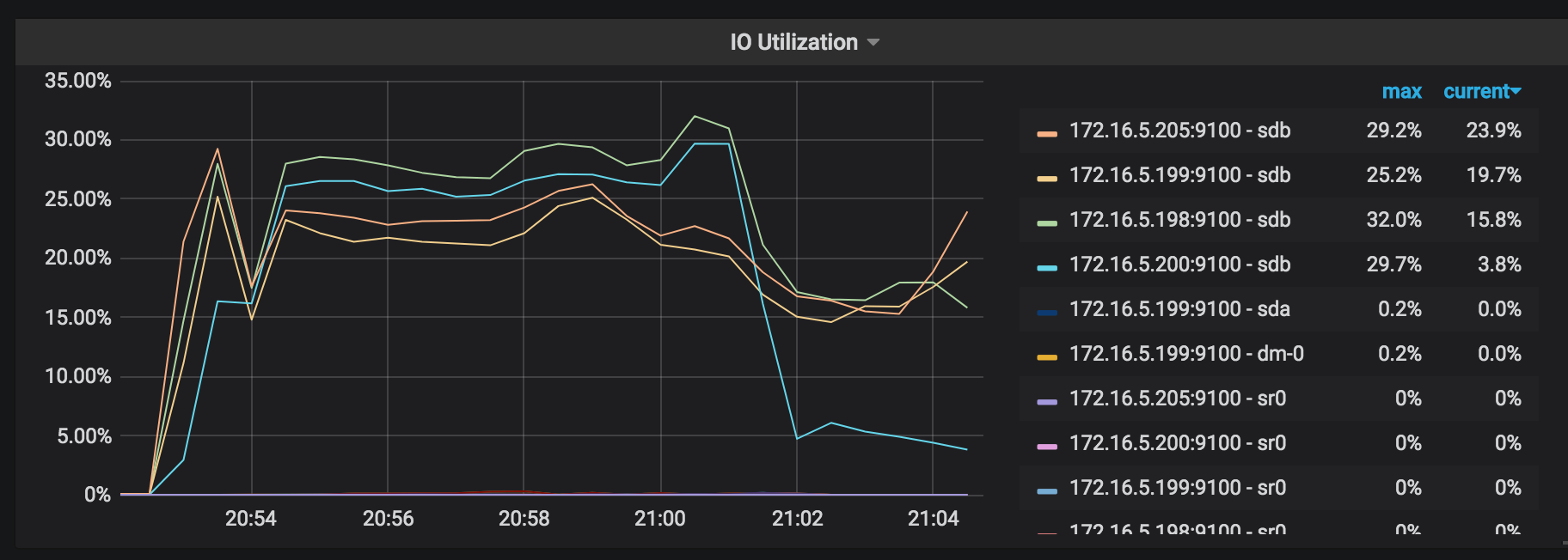
IO使用率:復元操作で動作している各TiKVノードのI/O使用率。
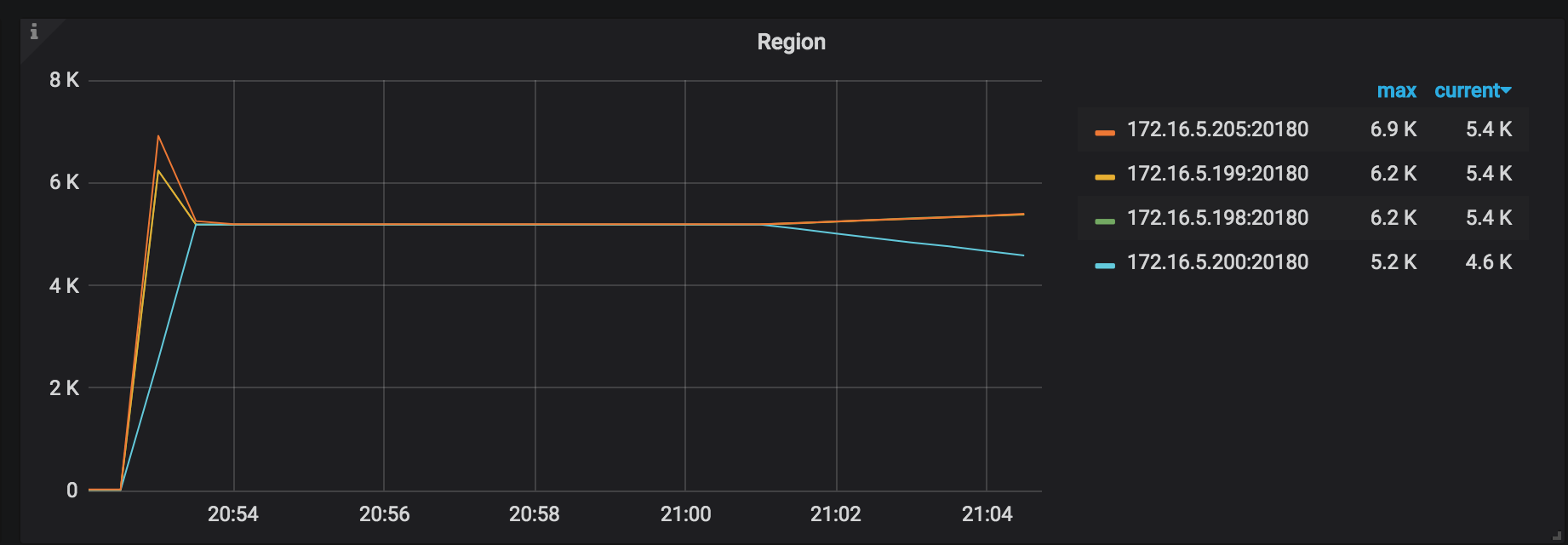
地域:地域の分布。リージョンが均等に分散されるほど、復元リソースがより適切に使用されます。
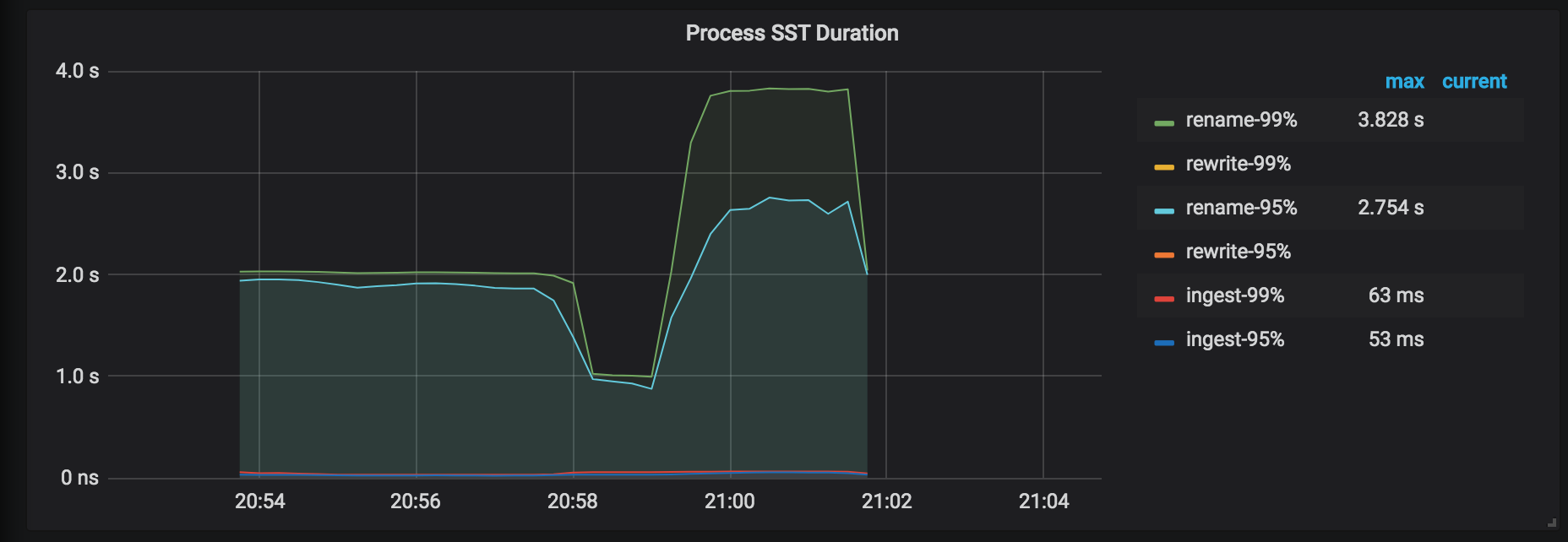
SSTの処理時間:SSTファイルの処理の遅延。テーブルを復元するときに、 tableIDが変更された場合は、 tableIDを書き直す必要があります。それ以外の場合、 tableIDは名前が変更されます。一般的に、書き換えの遅延は名前変更の遅延よりも長くなります。
SSTスループットのダウンロード:外部ストレージからSSTファイルをダウンロードするスループット。
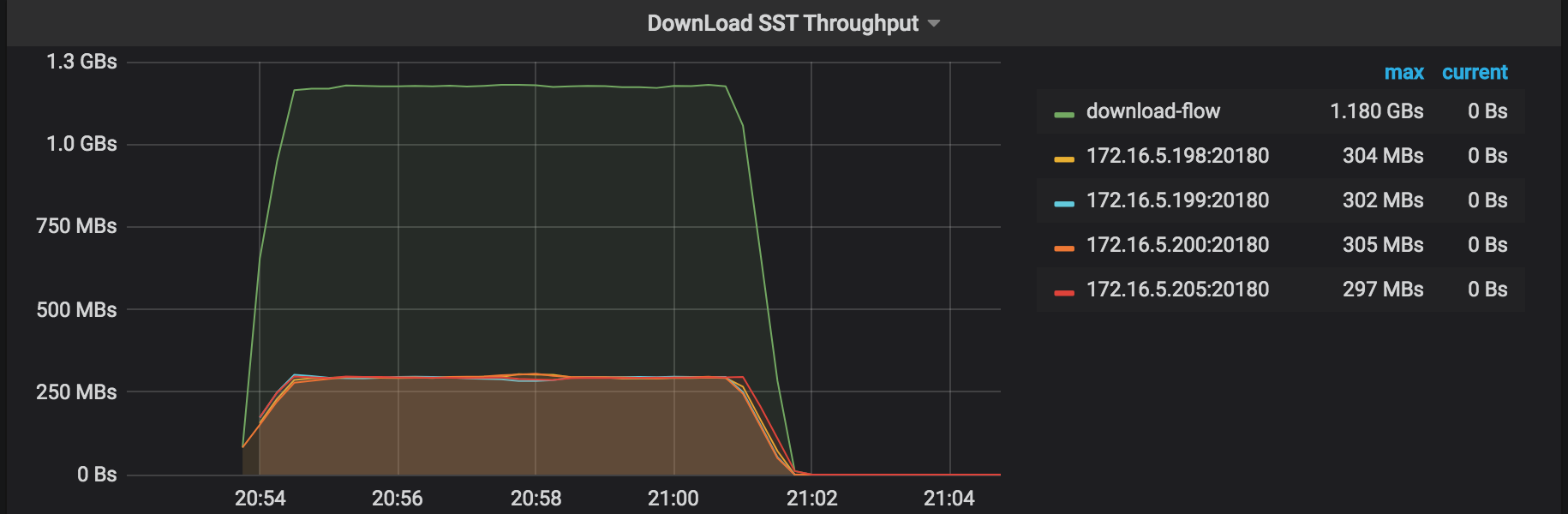
復元エラー:復元プロセス中に発生したエラー。
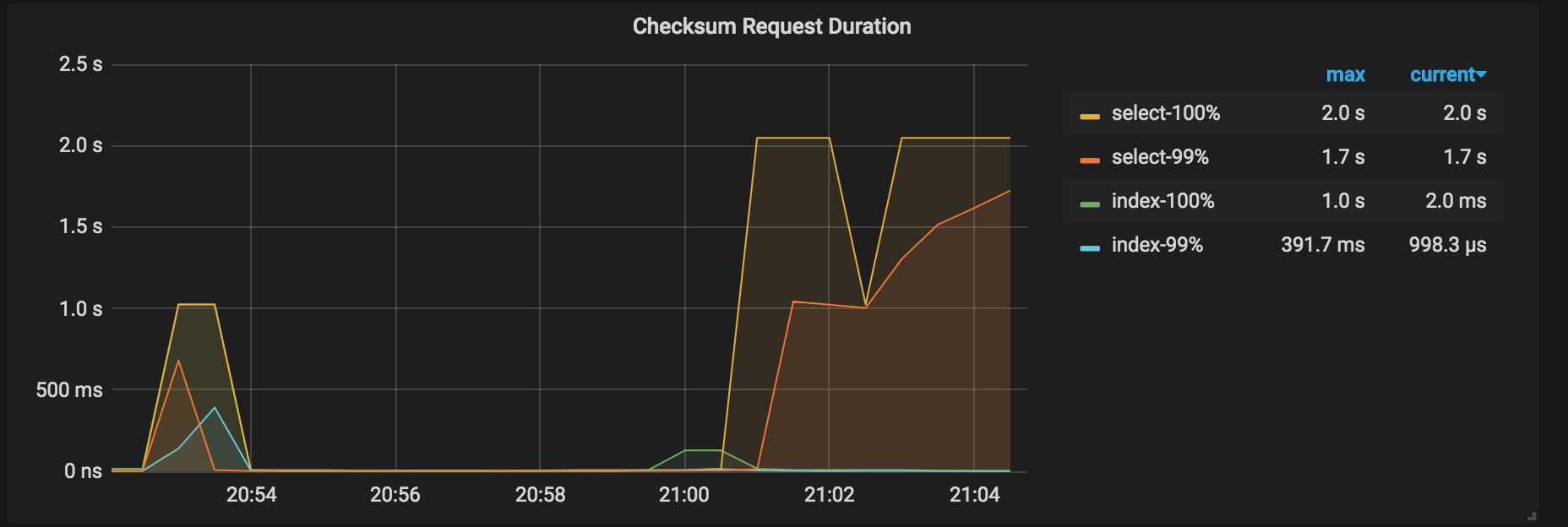
チェックサム要求期間:管理者チェックサム要求の期間。この復元の期間は、バックアップの期間よりも長くなります。
復元結果の説明
復元コマンドを実行する前に、ログが保存されるパスが指定されています。このログから復元操作の統計情報を取得できます。このログで「概要」を検索すると、次の情報が表示されます。
["Table Restore summary:
total restore tables: 1,
total success: 1,
total failed: 0,
total take(Full restore time): 17m1.001611365s,
total take(real time): 16m1.371611365s,
total kv: 5659888624,
total size(MB): 353227.18,
avg speed(MB/s): 367.42"]
["restore files"=9263]
["restore ranges"=6888]
["split region"=49.049182743s]
["restore checksum"=6m34.879439498s]
[Size=48693068713]
上記のログには、次の情報が含まれています。
- 復元期間:
total take(Full restore time): 17m1.001611365s - アプリケーションの合計実行時間:
total take(real time): 16m1.371611365s - 復元データサイズ:
total size(MB): 353227.18 - KVペア番号を復元:
total kv: 5659888624 - スループットの復元:
avg speed(MB/s): 367.42 Region Split期間:take=49.049182743s- チェックサム期間の復元:
restore checksum=6m34.879439498s - ディスクに復元されたデータの実際のサイズ:
[Size=48693068713]
上記の情報から、以下の項目を計算することができます。
- 単一のTiKVインスタンスのスループット
91.8avg speed(MB/s)=tikv_count - 単一のTiKVインスタンスの平均復元速度:
total size(MB)/(split time+restore time)/tikv_count=87.4
性能調整
復元プロセス中にTiKVのリソース使用量が明らかなボトルネックにならない場合は、デフォルトで128である--concurrencyの値を増やすことを試みることができます。次の例を参照してください。
bin/br restore table --db batchmark --table order_line -s local:///br_data/ --pd 172.16.5.198:2379 --log-file restore-concurrency.log --concurrency 1024
調整されたパフォーマンス結果は次のとおりです(同じデータサイズで)。
- 復元期間:
total take(s)が961.37から443.49に減少 - 復元スループット:
avg speed(MB/s)が367.42から796.47に増加 - 単一の
199.1インスタンスのスループット:avg speed(MB/s)がtikv_countから91.8に増加 - 単一のTiKVインスタンスの平均復元速度:
total size(MB)/(split time+restore time)/tikv_countが87.4から162.3に増加しました
単一のテーブルをローカルディスクにバックアップします(テスト環境で推奨)
br backupコマンドを使用して、単一のテーブル--db batchmark --table order_lineをローカルディスクの指定されたパスlocal:///home/tidb/backup_localにバックアップします。
バックアップの前提条件
- バックアップの準備
- 各TiKVノードには、backupSSTファイルを保存するための個別のディスクがあります。
backup_endpointノードには、backupmetaファイルを保存するための個別のディスクがあります。- TiKVと
backup_endpointノードは、バックアップ用に同じディレクトリ(たとえば、/home/tidb/backup_local)を持っている必要があります。
トポロジー
次の図は、BRの類型を示しています。
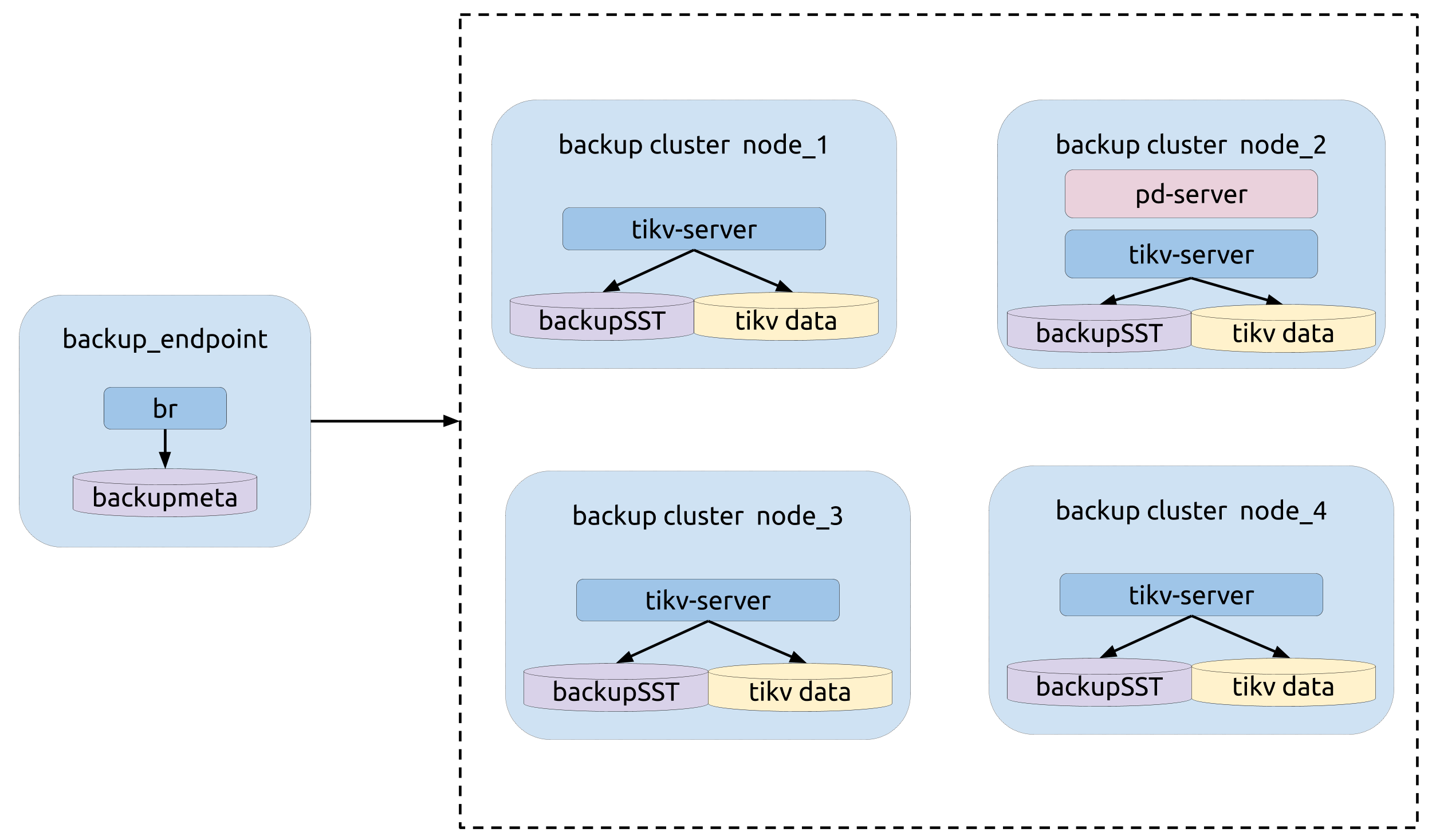
バックアップ操作
バックアップ操作の前に、 admin checksum table order_lineコマンドを実行して、バックアップするテーブルの統計情報を取得します( --db batchmark --table order_line )。次の画像は、この情報の例を示しています。
br backupコマンドを実行します。
bin/br backup table \
--db batchmark \
--table order_line \
-s local:///home/tidb/backup_local/ \
--pd ${PD_ADDR}:2379 \
--log-file backup_local.log
バックアッププロセス中は、監視パネルのメトリックに注意して、バックアッププロセスのステータスを取得してください。詳細については、 バックアップの監視メトリックを参照してください。
バックアップ結果の説明
バックアップコマンドを実行する前に、ログが保存されるパスが指定されています。このログからバックアップ操作の統計情報を取得できます。このログで「概要」を検索すると、次の情報が表示されます。
["Table backup summary: total backup ranges: 4, total success: 4, total failed: 0, total take(s): 551.31, total kv: 5659888624, total size(MB): 353227.18, avg speed(MB/s): 640.71"] ["backup total regions"=6795] ["backup checksum"=6m33.962719217s] ["backup fast checksum"=22.995552ms]
上記のログの情報は次のとおりです。
- バックアップ期間:
total take(s): 551.31 - データサイズ:
total size(MB): 353227.18 - バックアップスループット:
avg speed(MB/s): 640.71 - バックアップチェックサム期間:
take=6m33.962719217s
上記の情報から、単一のTiKVインスタンスのスループットを計算できます: avg speed(MB/s) / tikv_count = 160 。
ローカルディスクからデータを復元する(テスト環境で推奨)
br restoreコマンドを使用して、完全なバックアップデータをオフラインクラスタに復元します。現在、BRはオンラインクラスタへのデータの復元をサポートしていません。
復元の前提条件
- 修復の準備
- TiKVクラスタとバックアップデータに重複するデータベースまたはテーブルがありません。現在、BRはテーブルルートをサポートしていません。
- 各TiKVノードには、backupSSTファイルを保存するための個別のディスクがあります。
restore_endpointノードには、backupmetaファイルを保存するための個別のディスクがあります。- TiKVと
restore_endpointノードは、復元のために同じディレクトリ(たとえば、/home/tidb/backup_local/)を持っている必要があります。
復元する前に、次の手順に従ってください。
- すべてのbackupSSTファイルを同じディレクトリに収集します。
- 収集したbackupSSTファイルをクラスタのすべてのTiKVノードにコピーします。
backupmetaファイルをrestore endpointノードにコピーします。
トポロジー
次の図は、BRの類型を示しています。
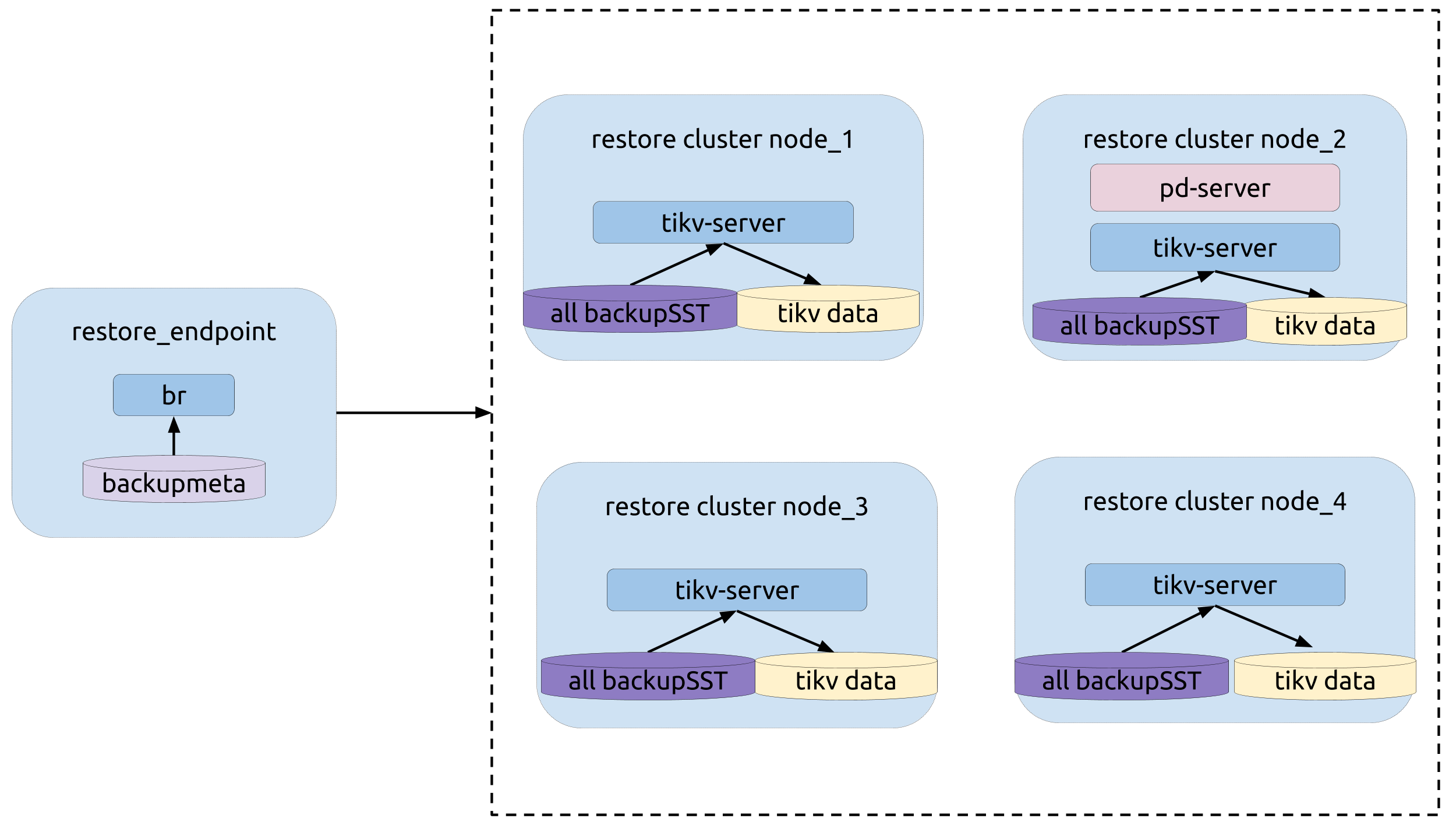
復元操作
br restoreコマンドを実行します。
bin/br restore table --db batchmark --table order_line -s local:///home/tidb/backup_local/ --pd 172.16.5.198:2379 --log-file restore_local.log
復元プロセス中は、監視パネルのメトリックに注意して、復元プロセスのステータスを取得します。詳細については、 復元の監視メトリックを参照してください。
復元結果の説明
復元コマンドを実行する前に、ログが保存されるパスが指定されています。このログから復元操作の統計情報を取得できます。このログで「概要」を検索すると、次の情報が表示されます。
["Table Restore summary: total restore tables: 1, total success: 1, total failed: 0, total take(s): 908.42, total kv: 5659888624, total size(MB): 353227.18, avg speed(MB/s): 388.84"] ["restore files"=9263] ["restore ranges"=6888] ["split region"=58.7885518s] ["restore checksum"=6m19.349067937s]
上記のログには、次の情報が含まれています。
- 復元期間:
total take(s): 908.42 - データサイズ:
total size(MB): 353227.18 - 復元スループット:
avg speed(MB/s): 388.84 Region Split期間:take=58.7885518s- 復元チェックサム期間:
take=6m19.349067937s
上記の情報から、以下の項目を計算することができます。
- 単一のTiKVインスタンスのスループット
97.2avg speed(MB/s)=tikv_count - 単一のTiKVインスタンスの平均復元速度:
total size(MB)/(split time+restore time)/tikv_count=92.4
バックアップ中のエラー処理
このセクションでは、バックアッププロセス中に発生する一般的なエラーを紹介します。
key locked Error
ログのエラーメッセージ: log - ["backup occur kv error"][error="{\"KvError\":{\"locked\":
バックアッププロセス中にキーがロックされている場合、BRはロックを解決しようとします。これらのエラーのいくつかは、バックアップの正確さに影響を与えません。
バックアップの失敗
ログのエラーメッセージ: log - Error: msg:"Io(Custom { kind: AlreadyExists, error: \"[5_5359_42_123_default.sst] is already exists in /dir/backup_local/\" })"
バックアップ操作が失敗し、上記のメッセージが表示された場合は、次のいずれかの操作を実行してから、バックアップ操作を再開してください。
- バックアップ用のディレクトリを変更します。たとえば、
/dir/backup-2020-01-01/を/dir/backup_local/に変更します。 - すべてのTiKVノードとBRノードのバックアップディレクトリを削除します。