TiKV におけるステイル読み取りと safe-ts の理解
このガイドでは、TiKV のステイル読み取りと safe-ts について、またステイル読み取りに関連する一般的な問題を診断する方法について説明します。
ステイル読み取りとsafe-tsの概要
ステイル読み取り 、TiDB が TiDB に保存されているデータの履歴バージョンを読み取るために適用するメカニズムです。TiKV では、 ステイル読み取り はセーフティーズに依存します。リージョンピアへの読み取りリクエストのタイムスタンプ (ts) がそのリージョンの safe-ts 以下であれば、TiDB はピアからデータを安全に読み取ることができます。TiKV は、safe-ts が常にresolved-ts以下であることを保証することで、この安全性保証を実装しています。
安全なtとresolved-tsを理解する
このセクションでは、 safe-ts とresolved-tsの概念とメンテナンスについて説明します。
safe-tsとは何ですか?
safe-ts は、リージョン内の各ピアが保持するタイムスタンプです。この値より小さいタイムスタンプを持つすべてのトランザクションがローカルに適用されていることを保証し、ローカルステイル読み取りを可能にします。
resolved-tsとは何ですか?
resolved-ts)は、この値より小さいタイムスタンプを持つすべてのトランザクションがリーダーによって適用済みであることを保証するタイムスタンプです。ピア概念であるセーフトランザクション(safe-ts)とは異なり、resolved-ts )はリージョンリーダーによってのみ管理されます。フォロワーの適用インデックスはリーダーよりも小さい場合があるため、解決済みトランザクション(resolved-ts)をフォロワー内で直接セーフトランザクション(safe-ts)として扱うことはできません。
セーフティーの維持
RegionReadProgressモジュールは safe-ts を管理します。リージョンリーダーはresolved-tsを管理し、定期的に、 resolved-ts、このresolved-tsを検証するための最低限必要な適用インデックス、そしてリージョン自体を、CheckLeader RPC を介して全レプリカのRegionReadProgerssモジュールに送信します。
ピアがデータを適用すると、適用インデックスが更新され、保留中のresolved-ts が新しい safe-t になるかどうかがチェックされます。
resolved-tsの維持
リージョンリーダーは、resolved-ts を管理するためにリゾルバを使用します。このリゾルバは、 Raft適用時に変更ログを受信することで、LOCK CF(カラムファミリー)内のロックを追跡します。初期化されると、リゾルバはリージョン全体をスキャンしてロックを追跡します。
ステイル読み取りの問題を診断する
このセクションでは、Grafana、 tikv-ctl 、およびログを使用してステイル読み取り の問題を診断する方法を紹介します。
問題を特定する
Grafana > TiDBダッシュボード > KVリクエストダッシュボードでは、次のパネルにステイル読み取りのヒット率、OPS、トラフィックが表示されます。
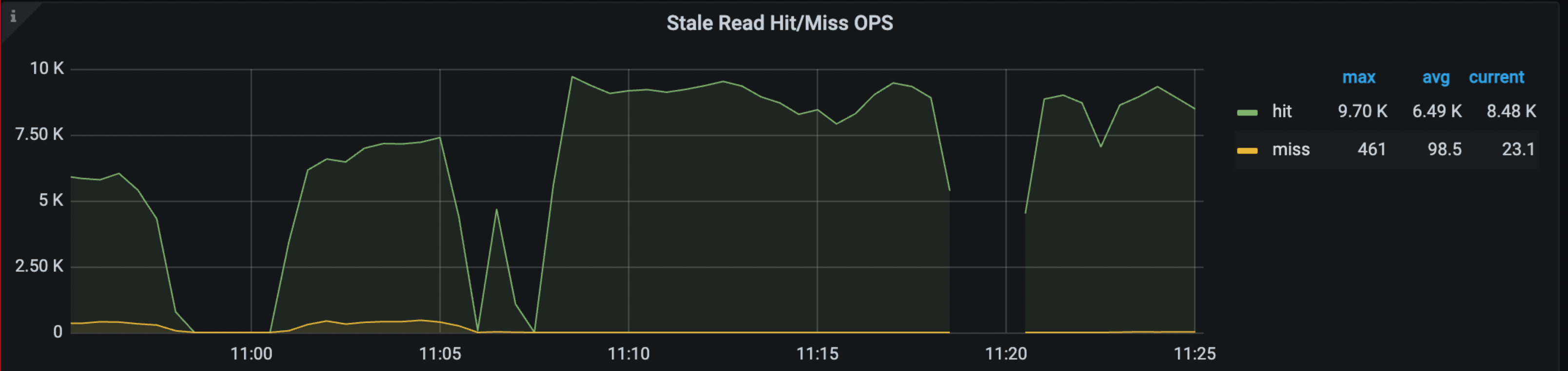
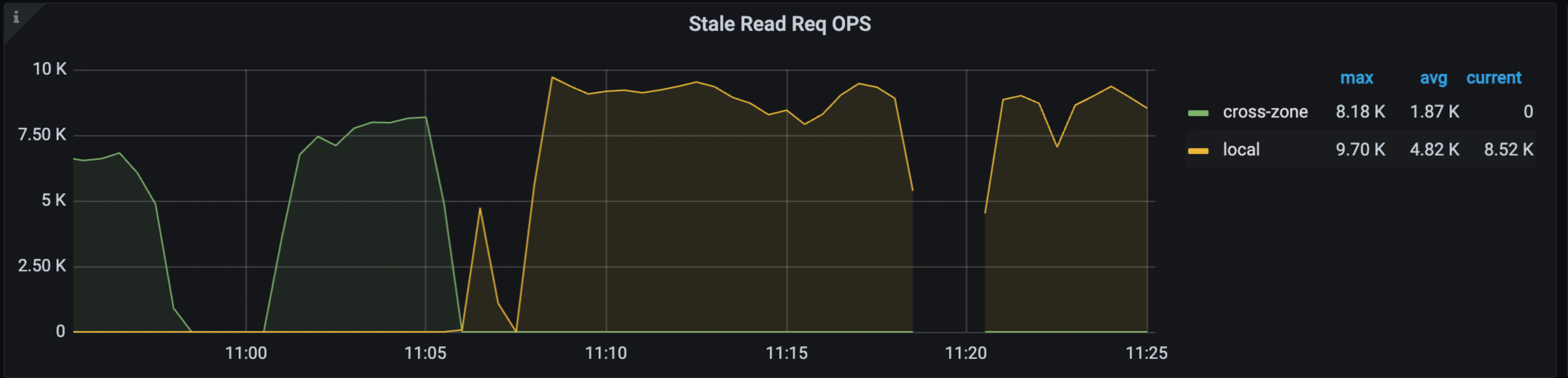
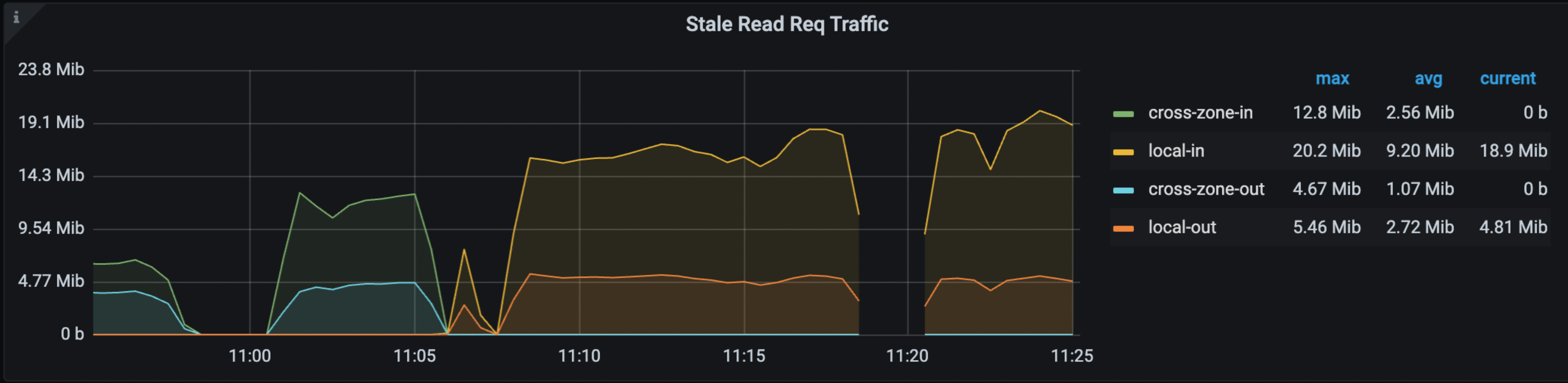
上記のメトリックの詳細については、 TiDB 監視メトリクス参照してください。
ステイル読み取り の問題が発生すると、前述の指標に変化が見られる場合があります。最も直接的な指標は、TiDB の WARN ログです。このログには、リージョンID がDataIsNotReadyで、検出されたsafe-ts報告されます。
一般的な原因
ステイル読み取りの有効性に影響を及ぼす最も一般的な原因は次のとおりです。
- コミットに長い時間を要するトランザクション。
- トランザクションがコミットされるまでの期間が長すぎます。
- CheckLeader の情報をリーダーからフォロワーにプッシュする際の遅延。
Grafanaを使って診断する
TiKV詳細>解決済みTSダッシュボードでは、各TiKVのresolved-tsとsafe-tsが最も小さいリージョンを特定できます。これらのタイムスタンプが実時間より大幅に遅れている場合は、 tikv-ctl使用してこれらのリージョンの詳細を確認する必要があります。
tikv-ctlを使用して診断する
tikv-ctlリゾルバの最新の詳細情報を提供し、 RegionReadProgressリゾルバの最新の詳細情報を提供します。詳細についてはリージョンのRegionReadProgressの状態を取得する参照してください。
次に例を示します。
./tikv-ctl --host 127.0.0.1:20160 get-region-read-progress -r 14 --log --min-start-ts 0
出力は次のようになります。
Region read progress:
exist: true,
safe_ts: 0,
applied_index: 92,
pending front item (oldest) ts: 0,
pending front item (oldest) applied index: 0,
pending back item (latest) ts: 0,
pending back item (latest) applied index: 0,
paused: false,
Resolver:
exist: true,
resolved_ts: 0,
tracked index: 92,
number of locks: 0,
number of transactions: 0,
stopped: false,
上記の出力は、次のことを判断するのに役立ちます。
- ロックがresolved-tsをブロックしているかどうか。
- 適用インデックスが小さすぎて safe-ts を更新できないかどうか。
- フォロワー ピアが存在する場合に、リーダーが十分に更新されたresolved-tsを送信しているかどうか。
ログを使用して診断する
TiKV は 10 秒ごとに次のメトリックをチェックします。
- resolved-tsが最小であるリージョンリーダー
- 安全度が最小のリージョンフォロワー
- resolved-tsが最小であるリージョンフォロワー
これらのタイムスタンプのいずれかが異常に小さい場合、TiKV はログを出力。
これらのログは、現在は存在しない過去の問題を診断する場合に特に役立ちます。
ログの例を以下に示します。
[2023/08/29 16:48:18.118 +08:00] [INFO] [endpoint.rs:505] ["the max gap of leader resolved-ts is large"] [last_resolve_attempt="Some(LastAttempt { success: false, ts: TimeStamp(443888082736381953), reason: \"lock\", lock: Some(7480000000000000625F728000000002512B5C) })"] [duration_to_last_update_safe_ts=10648ms] [min_memory_lock=None] [txn_num=0] [lock_num=0] [min_lock=None] [safe_ts=443888117326544897] [gap=110705ms] [region_id=291]
[2023/08/29 16:48:18.118 +08:00] [INFO] [endpoint.rs:526] ["the max gap of follower safe-ts is large"] [oldest_candidate=None] [latest_candidate=None] [applied_index=3276] [duration_to_last_consume_leader=11460ms] [resolved_ts=443888117117353985] [safe_ts=443888117117353985] [gap=111503ms] [region_id=273]
[2023/08/29 16:48:18.118 +08:00] [INFO] [endpoint.rs:547] ["the max gap of follower resolved-ts is large; it's the same region that has the min safe-ts"]
トラブルシューティングのヒント
遅いトランザクションコミットを処理する
コミットに長い時間がかかるトランザクションは、多くの場合、大規模なトランザクションです。このような低速トランザクションの書き込み前フェーズではロックがいくつか残りますが、コミットフェーズでロックがクリアされるまでに時間がかかりすぎます。この問題のトラブルシューティングを行うには、ロックが属するトランザクションを特定し、ログなどを使用してロックが存在する理由を突き止めるようにしてください。
以下に実行できるアクションをいくつか示します。
tikv-ctlコマンドで--logオプションを指定し、TiKV ログをチェックして、start_ts を持つ特定のロックを見つけます。トランザクションの問題を特定するには、TiDB ログと TiKV ログの両方で start_ts を検索します。
クエリの実行時間が60秒を超える場合、SQL文に
expensive_queryログが出力されます。start_tsの値を使用して、ログと一致させることができます。以下に例を示します。[2023/07/17 19:32:09.403 +08:00] [WARN] [expensivequery.go:145] [expensive_query] [cost_time=60.025022732s] [cop_time=0.00346666s] [process_time=8.358409508s] [wait_time=0.013582596s] [request_count=278] [total_keys=9943616] [process_keys=9943360] [num_cop_tasks=278] [process_avg_time=0.030066221s] [process_p90_time=0.045296042s] [process_max_time=0.052828934s] [process_max_addr=192.168.31.244:20160] [wait_avg_time=0.000048858s] [wait_p90_time=0.00006057s] [wait_max_time=0.00040991s] [wait_max_addr=192.168.31.244:20160] [stats=t:442916666913587201] [conn=2826881778407440457] [user=root] [database=test] [table_ids="[100]"] [**txn_start_ts**=442916790435840001] [mem_max="2514229289 Bytes (2.34 GB)"] [sql="update t set b = b + 1"]ログからロックに関する十分な情報を取得できない場合は、テーブル
CLUSTER_TIDB_TRXを使用してアクティブなトランザクションを見つけます。SHOW PROCESSLIST実行すると、同じTiDBサーバーに接続されている現在のセッションと、現在のステートメントに費やされた時間が表示されます。ただし、start_tsは表示されません。
進行中の大規模トランザクションが原因でロックが存在する場合は、これらのロックによって解決の進行が妨げられる可能性があるため、アプリケーション ロジックの変更を検討してください。
ロックが進行中のトランザクションに属していない場合は、コーディネーター(TiDB)がロックを事前書き込みした後にクラッシュしたことが原因の可能性があります。この場合、TiDBは自動的にロックを解決します。問題が解決しない限り、特に対処する必要はありません。
長期トランザクションを処理する
長時間アクティブなトランザクションは、最終的にはすぐにコミットしたとしても、 resolved-tsの進行をブロックする可能性があります。これは、 resolved-ts の計算に、これらの長時間アクティブなトランザクションの start-ts が使用されるためです。
この問題に対処するには:
トランザクションの特定:まず、ロックに関連するトランザクションを特定します。ロックが存在する理由を理解することが重要です。ログを活用すると特に役立ちます。
アプリケーション ロジックを調べる: トランザクションの所要時間が長くなっている原因がアプリケーションのロジックにある場合は、そのような事態が発生しないようにロジックを修正することを検討してください。
遅いクエリに対処する: 遅いクエリが原因でトランザクションの期間が長くなる場合は、これらのクエリの解決を優先して問題を軽減します。
CheckLeaderの問題に対処する
CheckLeader の問題に対処するには、 TiKV詳細>解決済みTSダッシュボードでネットワークとCheck Leader Durationメトリックを確認します。
例
次のように、 ステイル読み取り OPSのミス率が増加していることがわかります。
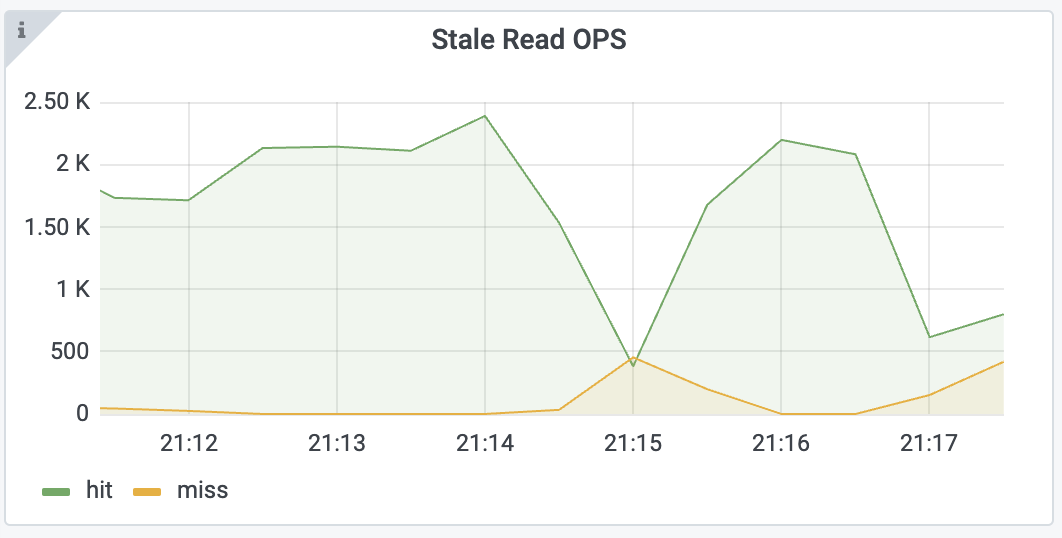
まず、次のTiKV詳細>解決済みTSダッシュボードの最大解決 TS ギャップと最小解決 TSリージョンメトリックを確認します。
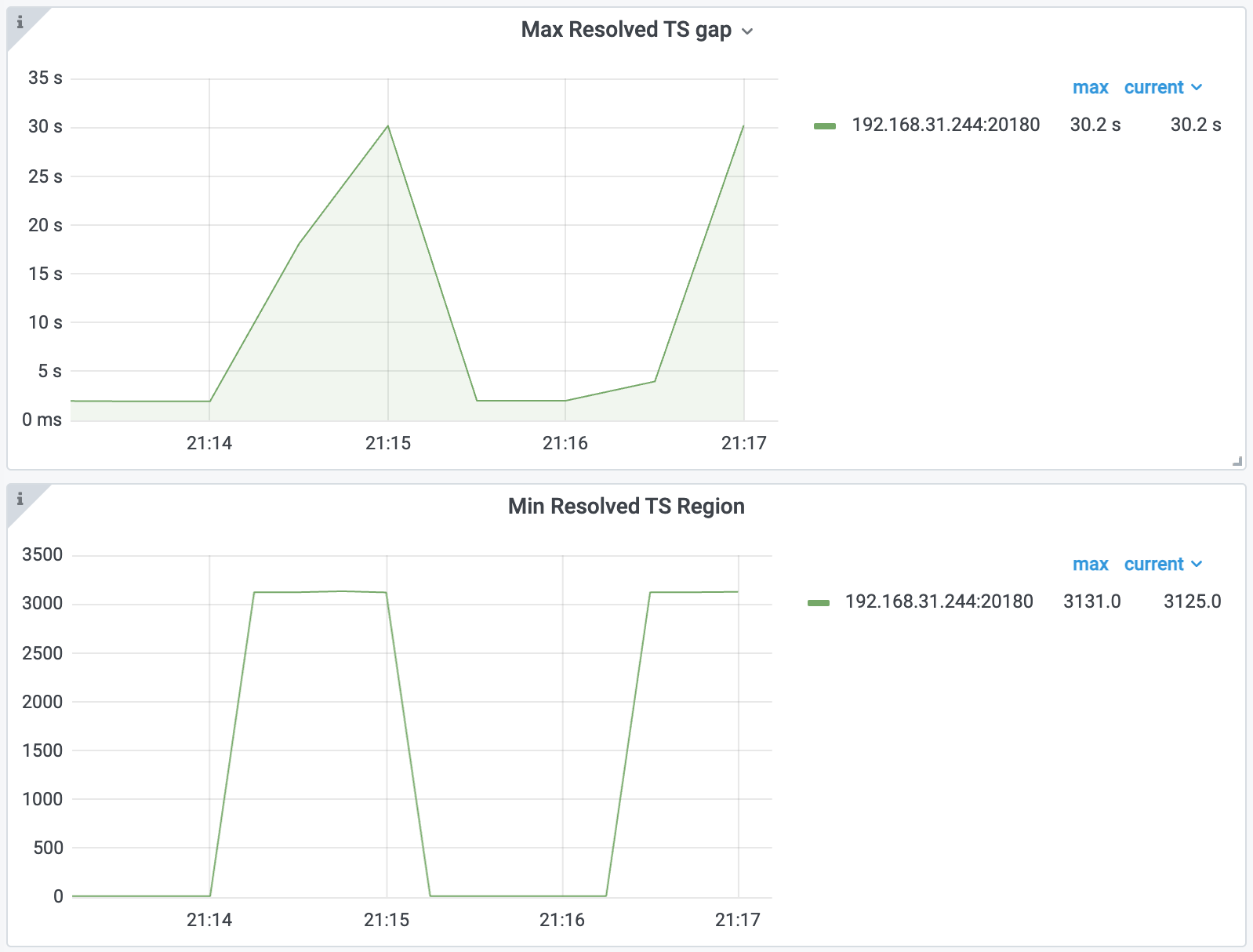
上記のメトリックから、リージョン3121と他のいくつかのリージョンが、resolved-ts を時間内に更新していないことがわかります。
リージョン3121の状態に関する詳細を取得するには、次のコマンドを実行します。
./tikv-ctl --host 127.0.0.1:20160 get-region-read-progress -r 3121 --log
出力は次のようになります。
Region read progress:
exist: true,
safe_ts: 442918444145049601,
applied_index: 2477,
read_state.ts: 442918444145049601,
read_state.apply_index: 1532,
pending front item (oldest) ts: 0,
pending front item (oldest) applied index: 0,
pending back item (latest) ts: 0,
pending back item (latest) applied index: 0,
paused: false,
discarding: false,
Resolver:
exist: true,
resolved_ts: 442918444145049601,
tracked index: 2477,
number of locks: 480000,
number of transactions: 1,
stopped: false,
ここで注目すべき点は、リゾルバのapplied_index tracked indexと等しいことです。したがって、リゾルバがこの問題の根本原因であると思われます。また、このリージョンに480000個のロックを残すトランザクションが1つあることもわかります。これが原因である可能性があります。
正確なトランザクションと一部のロックのキーを取得するには、TiKVログを確認し、 grep locks withを実行します。出力は次のようになります。
[2023/07/17 21:16:44.257 +08:00] [INFO] [resolver.rs:213] ["locks with the minimum start_ts in resolver"] [keys="[74800000000000006A5F7280000000000405F6, ... , 74800000000000006A5F72800000000000EFF6, 74800000000000006A5F7280000000000721D9, 74800000000000006A5F72800000000002F691]"] [start_ts=442918429687808001] [region_id=3121]
TiKVログから、トランザクションのstart_ts 442918429687808001 )を取得できます。ステートメントとトランザクションに関する詳細情報を取得するには、TiDBログでこのタイムスタンプをgrepしてください。出力は以下のとおりです。
[2023/07/17 21:16:18.287 +08:00] [INFO] [2pc.go:685] ["[BIG_TXN]"] [session=2826881778407440457] ["key sample"=74800000000000006a5f728000000000000000] [size=319967171] [keys=10000000] [puts=10000000] [dels=0] [locks=0] [checks=0] [txnStartTS=442918429687808001]
[2023/07/17 21:16:22.703 +08:00] [WARN] [expensivequery.go:145] [expensive_query] [cost_time=60.047172498s] [cop_time=0.004575113s] [process_time=15.356963423s] [wait_time=0.017093811s] [request_count=397] [total_keys=20000398] [process_keys=10000000] [num_cop_tasks=397] [process_avg_time=0.038682527s] [process_p90_time=0.082608262s] [process_max_time=0.116321331s] [process_max_addr=192.168.31.244:20160] [wait_avg_time=0.000043057s] [wait_p90_time=0.00004007s] [wait_max_time=0.00075014s] [wait_max_addr=192.168.31.244:20160] [stats=t:442918428521267201] [conn=2826881778407440457] [user=root] [database=test] [table_ids="[106]"] [txn_start_ts=442918429687808001] [mem_max="2513773983 Bytes (2.34 GB)"] [sql="update t set b = b + 1"]
これで、問題の原因となったステートメントを基本的に特定できます。さらに確認するには、 SHOW PROCESSLISTステートメントを実行してください。出力は以下のようになります。
+---------------------+------+---------------------+--------+---------+------+------------+---------------------------+
| Id | User | Host | db | Command | Time | State | Info |
+---------------------+------+---------------------+--------+---------+------+------------+---------------------------+
| 2826881778407440457 | root | 192.168.31.43:58641 | test | Query | 48 | autocommit | update t set b = b + 1 |
| 2826881778407440613 | root | 127.0.0.1:45952 | test | Execute | 0 | autocommit | select * from t where a=? |
| 2826881778407440619 | root | 192.168.31.43:60428 | <null> | Query | 0 | autocommit | show processlist |
+---------------------+------+---------------------+--------+---------+------+------------+---------------------------+
出力を見ると、誰かが予期しないUPDATEステートメント ( update t set b = b + 1 ) を実行しており、その結果トランザクションが大きくなってステイル読み取りが妨げられていることがわかります。
この問題を解決するには、このUPDATEステートメントを実行しているアプリケーションを停止します。