TiSpark ユーザーガイド
TiSparkはTiKVクラスターとPDクラスターに依存します。Sparkクラスターもセットアップする必要があります。このドキュメントでは、TiSparkのセットアップと使用方法について簡単に説明します。Apache Sparkに関する基本的な知識が必要です。詳細については、 Apache Sparkのウェブサイトご覧ください。
TiSparkはSpark Catalyst Engineと緊密に統合されており、コンピューティングを正確に制御できます。これにより、SparkはTiKVからデータを効率的に読み取ることができます。また、TiSparkはインデックスシークをサポートしており、高速なポイントクエリを可能にします。TiSparkは、コンピューティングをTiKVにプッシュすることでデータクエリを高速化し、Spark SQLで処理するデータ量を削減します。さらに、TiSparkはTiDBに組み込まれた統計情報を使用して、最適なクエリプランを選択できます。
TiSparkとTiDBを使用すると、ETLの構築と保守をすることなく、トランザクションタスクと分析タスクの両方を同じプラットフォームで実行できます。これにより、システムアーキテクチャが簡素化され、保守コストが削減されます。
TiDB でのデータ処理には、Spark エコシステムのツールを使用できます。
- TiSpark: データ分析とETL
- TiKV: データ取得
- スケジュールシステム:レポート生成
また、TiSparkはTiKVへの分散書き込みをサポートしています。SparkとJDBCを使用したTiDBへの書き込みと比較して、TiKVへの分散書き込みはトランザクション(すべてのデータが正常に書き込まれるか、すべての書き込みが失敗するかのいずれか)を実装でき、書き込み速度が速くなります。
次の図は TiSpark のアーキテクチャを示しています。
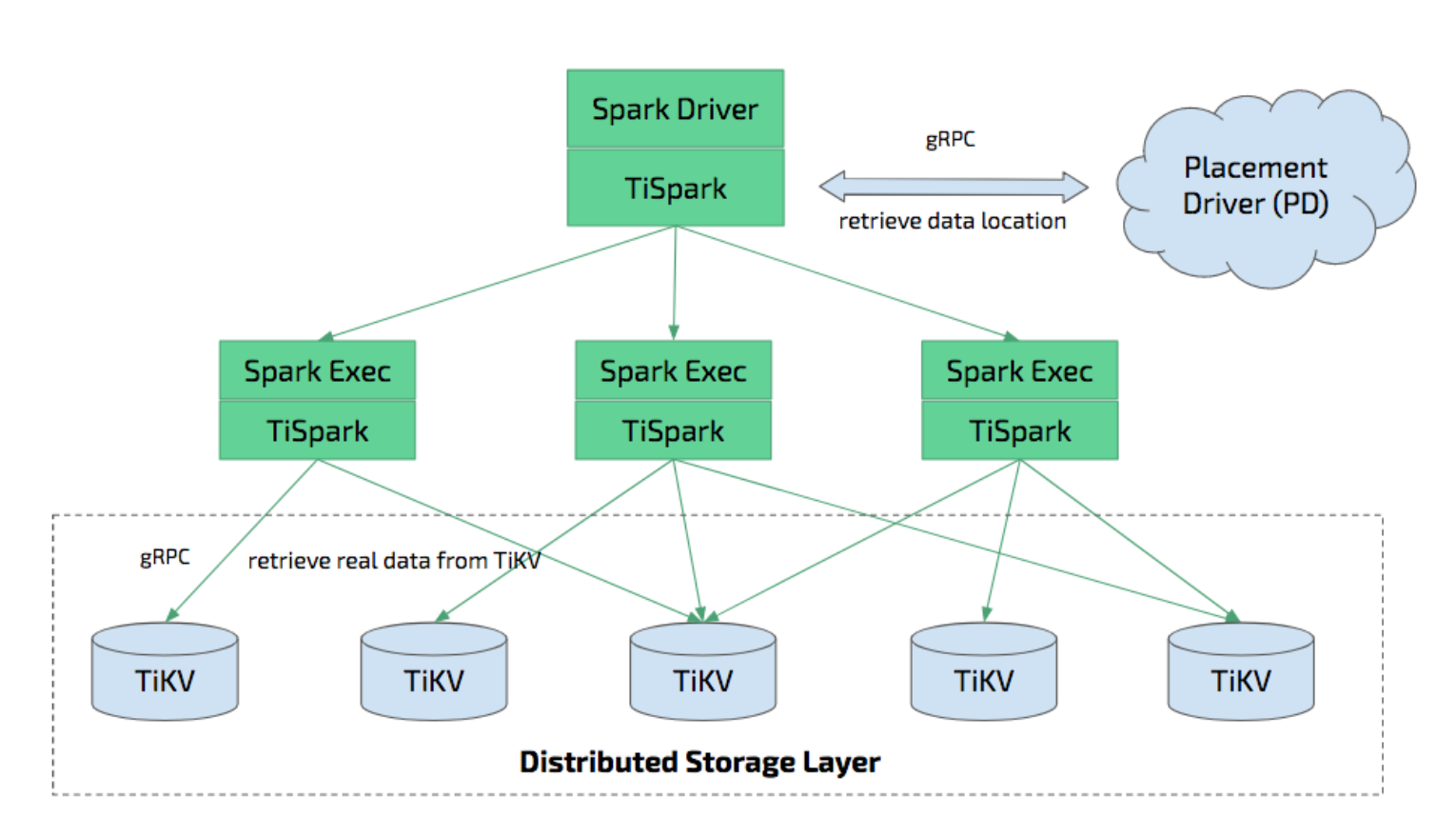
TiSparkとTiFlash
ティスパーク 、TiDB/TiKV上でApache Sparkを実行し、複雑なOLAPクエリに応答するために構築された薄いレイヤーです。Sparkプラットフォームと分散型TiKVクラスターの両方の利点を活用し、分散型OLTPデータベースであるTiDBとシームレスに統合することで、オンライントランザクションと分析の両方をワンストップで提供するハイブリッドトランザクション/分析処理(HTAP)ソリューションを提供します。
TiFlash HTAPを可能にするもう一つのツールです。TiFlashとTiSparkはどちらも、複数のホストを使用してOLTPデータに対してOLAPクエリを実行できます。TiFlashはデータを列形式で保存するため、より効率的な分析クエリを実行できます。TiFlashとTiSparkは併用可能です。
要件
- TiSpark は Spark 以降 2.3 をサポートします。
- TiSpark には JDK 1.8 および Scala 2.11/2.12 が必要です。
- TiSpark は、
YARN、Mesos、Standaloneなどの任意の Spark モードで実行されます。
Sparkの推奨デプロイメント構成
TiSpark は Spark の TiDB コネクタであるため、使用するには実行中の Spark クラスターが必要です。
このドキュメントでは、Spark の導入に関する基本的なアドバイスを提供します。詳細なハードウェア推奨事項については、 スパーク公式サイトをご覧ください。
Spark クラスターの独立したデプロイメントの場合:
- Sparkには32GBのメモリを割り当てることをお勧めします。オペレーティングシステムとバッファキャッシュ用に、メモリの少なくとも25%を確保してください。
- Spark には、マシンごとに少なくとも 8 ~ 16 個のコアをプロビジョニングすることをお勧めします。まず、すべての CPU コアを Spark に割り当てる必要があります。
以下はspark-env.sh構成に基づく例です。
SPARK_EXECUTOR_MEMORY = 32g
SPARK_WORKER_MEMORY = 32g
SPARK_WORKER_CORES = 8
TiSparkを入手
TiSpark は、TiKV の読み取りと書き込みの機能を提供する Spark 用のサードパーティ jar パッケージです。
mysql-connector-j を入手する
GPL ライセンスの制限により、 mysql-connector-java依存関係は提供されなくなりました。
TiSpark の jar の次のバージョンには、 mysql-connector-java含まれなくなります。
- TiSpark > 3.0.1
- TiSpark > 2.5.1 (TiSpark 2.5.x の場合)
- TiSpark > 2.4.3 (TiSpark 2.4.x 用)
ただし、TiSpark は書き込みと認証にmysql-connector-java必要とします。その場合は、以下のいずれかの方法でmysql-connector-java手動でインポートする必要があります。
mysql-connector-javaSpark jar ファイルに入力します。Sparkジョブを送信するときに
mysql-connector-javaインポートします。次の例を参照してください。
spark-submit --jars tispark-assembly-3.0_2.12-3.1.0-SNAPSHOT.jar,mysql-connector-java-8.0.29.jar
TiSparkのバージョンを選択
TiDB および Spark のバージョンに応じて、TiSpark のバージョンを選択できます。
| TiSparkバージョン | TiDB、TiKV、PD バージョン | Sparkバージョン | Scalaバージョン |
|---|---|---|---|
| 2.4.x-scala_2.11 | 5.x、4.x | 2.3.x、2.4.x | 2.11 |
| 2.4.x-scala_2.12 | 5.x、4.x | 2.4.x | 2.12 |
| 2.5.x | 5.x、4.x | 3.0.x、3.1.x | 2.12 |
| 3.0.x | 5.x、4.x | 3.0.x、3.1.x、3.2.x | 2.12 |
| 3.1.x | 6.x、5.x、4.x | 3.0.x、3.1.x、3.2.x、3.3.x | 2.12 |
| 3.2.x | 6.x、5.x、4.x | 3.0.x、3.1.x、3.2.x、3.3.x | 2.12 |
TiSpark 2.4.4、2.5.3、3.0.3、3.1.7、および 3.2.3 は最新の安定バージョンであり、強く推奨されます。
TiSpark jarを入手する
次のいずれかの方法で TiSpark jar を取得できます。
- メイブンセントラルから取得して
pingcap検索 - TiSparkリリースから取得
- 以下の手順でソースからビルドします
注記:
現在、TiSpark をビルドするには java8 のみが選択肢となります。確認するには mvn -version を実行してください。
git clone https://github.com/pingcap/tispark.git
TiSpark ルート ディレクトリで次のコマンドを実行します。
// add -Dmaven.test.skip=true to skip the tests
mvn clean install -Dmaven.test.skip=true
// or you can add properties to specify spark version
mvn clean install -Dmaven.test.skip=true -Pspark3.2.1
TiSpark jarのアーティファクトID
TiSpark のアーティファクト ID は、TiSpark のバージョンによって異なります。
| TiSparkバージョン | アーティファクトID |
|---|---|
| 2.4.x-${scala_version}、2.5.0 | tisparkアセンブリ |
| 2.5.1 | tispark-アセンブリ-${spark_version} |
| 3.0.x、3.1.x、3.2.x | tispark-アセンブリ-{scala_version} |
はじめる
このドキュメントでは、spark-shell で TiSpark を使用する方法について説明します。
spark-shellを起動する
spark-shell で TiSpark を使用するには:
spark-defaults.confに次の構成を追加します。
spark.sql.extensions org.apache.spark.sql.TiExtensions
spark.tispark.pd.addresses ${your_pd_address}
spark.sql.catalog.tidb_catalog org.apache.spark.sql.catalyst.catalog.TiCatalog
spark.sql.catalog.tidb_catalog.pd.addresses ${your_pd_address}
--jarsオプションで spark-shell を起動します。
spark-shell --jars tispark-assembly-{version}.jar
TiSparkバージョンを入手
spark-shell で次のコマンドを実行すると、TiSpark のバージョン情報を取得できます。
spark.sql("select ti_version()").collect
TiSparkを使用してデータを読み取る
Spark SQL を使用して TiKV からデータを読み取ることができます。
spark.sql("use tidb_catalog")
spark.sql("select count(*) from ${database}.${table}").show
TiSparkを使用してデータを書き込む
Spark DataSource API を使用して、 ACIDが保証された TiKV にデータを書き込むことができます。
val tidbOptions: Map[String, String] = Map(
"tidb.addr" -> "127.0.0.1",
"tidb.password" -> "",
"tidb.port" -> "4000",
"tidb.user" -> "root"
)
val customerDF = spark.sql("select * from customer limit 100000")
customerDF.write
.format("tidb")
.option("database", "tpch_test")
.option("table", "cust_test_select")
.options(tidbOptions)
.mode("append")
.save()
詳細はデータソース API ユーザーガイドご覧ください。
TiSpark 3.1以降では、Spark SQLを使用してTiKVにデータを書き込むことができます。詳細については、 挿入SQLご覧ください。
JDBC データソースを使用してデータを書き込む
TiSpark を使用せずに、Spark JDBC を使用して TiDB に書き込むこともできます。
これはTiSparkの範囲外です。このドキュメントでは例のみを示します。詳細についてはJDBC から他のデータベースへ参照してください。
import org.apache.spark.sql.execution.datasources.jdbc.JDBCOptions
val customer = spark.sql("select * from customer limit 100000")
// you might need to repartition the source to make it balanced across nodes
// and increase concurrency
val df = customer.repartition(32)
df.write
.mode(saveMode = "append")
.format("jdbc")
.option("driver", "com.mysql.jdbc.Driver")
// replace the host and port with yours and be sure to use rewrite batch
.option("url", "jdbc:mysql://127.0.0.1:4000/test?rewriteBatchedStatements=true")
.option("useSSL", "false")
// as tested, setting to `150` is a good practice
.option(JDBCOptions.JDBC_BATCH_INSERT_SIZE, 150)
.option("dbtable", s"cust_test_select") // database name and table name here
.option("isolationLevel", "NONE") // set isolationLevel to NONE
.option("user", "root") // TiDB user here
.save()
TiDB OOM につながる可能性のある大規模な単一トランザクションを回避し、 ISOLATION LEVEL does not supportエラーも回避するには、 isolationLevelをNONEに設定します (TiDB は現在REPEATABLE-READのみをサポートしています)。
TiSparkを使用してデータを削除する
Spark SQL を使用して TiKV からデータを削除できます。
spark.sql("use tidb_catalog")
spark.sql("delete from ${database}.${table} where xxx")
詳細は削除機能ご覧ください。
他のデータソースを操作する
次のように複数のカタログを使用して、異なるデータ ソースからデータを読み取ることができます。
// Read from Hive
spark.sql("select * from spark_catalog.default.t").show
// Join Hive tables and TiDB tables
spark.sql("select t1.id,t2.id from spark_catalog.default.t t1 left join tidb_catalog.test.t t2").show
TiSpark 構成
次の表の構成は、 spark-defaults.confと一緒にしたり、他の Spark 構成プロパティと同じ方法で渡すことができます。
| 鍵 | デフォルト値 | 説明 |
|---|---|---|
spark.tispark.pd.addresses | 127.0.0.1:2379 | カンマで区切られた PD クラスターのアドレス。 |
spark.tispark.grpc.framesize | 2147483647 | gRPC 応答の最大フレーム サイズ (バイト単位) (デフォルトは 2G)。 |
spark.tispark.grpc.timeout_in_sec | 10 | gRPC のタイムアウト時間(秒)。 |
spark.tispark.plan.allow_agg_pushdown | true | 集約が TiKV にプッシュダウンできるかどうか (TiKV ノードがビジーの場合)。 |
spark.tispark.plan.allow_index_read | true | 計画時にインデックスが有効になっているかどうか (TiKV に大きな負荷がかかる可能性があります)。 |
spark.tispark.index.scan_batch_size | 20000 | 同時インデックススキャンのバッチ内の行キーの数。 |
spark.tispark.index.scan_concurrency | 5 | 行キーを取得するインデックス スキャンのスレッドの最大数 (各 JVM 内のタスク間で共有)。 |
spark.tispark.table.scan_concurrency | 512 | テーブルスキャンのスレッドの最大数 (各 JVM 内のタスク間で共有されます)。 |
spark.tispark.request.command.priority | Low | 値のオプションはLow 、 Normal 、 Highです。この設定はTiKVに割り当てられるリソースに影響します。OLTPワークロードに影響を与えないため、 Low推奨されます。 |
spark.tispark.coprocess.codec_format | chblock | コプロセッサのデフォルトのコーデック形式を保持します。使用可能なオプションはdefault 、 chblock 、 chunkです。 |
spark.tispark.coprocess.streaming | false | レスポンスの取得にストリーミングを使用するかどうか (実験的)。 |
spark.tispark.plan.unsupported_pushdown_exprs | カンマ区切りの式のリスト。TiKVのバージョンが非常に古い場合、サポートされていない式のプッシュダウンを無効にすることができます。 | |
spark.tispark.plan.downgrade.index_threshold | 1000000000 | 元のリクエストにおいて、あるリージョンのインデックススキャンの範囲がこの制限を超える場合、このリージョンのリクエストを、計画されたインデックススキャンではなくテーブルスキャンにダウングレードします。デフォルトでは、ダウングレードは無効になっています。 |
spark.tispark.show_rowid | false | ID が存在する場合に行 ID を表示するかどうか。 |
spark.tispark.db_prefix | TiDB内のすべてのデータベースに追加されるプレフィックスを示す文字列。この文字列は、TiDB内のデータベースと、同じ名前を持つHiveデータベースを区別します。 | |
spark.tispark.request.isolation.level | SI | 基盤となるTiDBクラスタのロックを解決するかどうか。「RC」を使用すると、 tsoより小さいレコードの最新バージョンを取得し、ロックを無視します。「SI」を使用すると、解決されたロックがコミットされたか中止されたかに応じて、ロックを解決し、レコードを取得します。 |
spark.tispark.coprocessor.chunk_batch_size | 1024 | コプロセッサから取得された行。 |
spark.tispark.isolation_read_engines | tikv,tiflash | TiSpark の読み取り可能なエンジンのリスト(カンマ区切り)。リストにないストレージエンジンは読み込まれません。 |
spark.tispark.stale_read | オプション | 古い読み取りタイムスタンプ(ミリ秒)。詳細はここ参照してください。 |
spark.tispark.tikv.tls_enable | false | TiSpark TLS を有効にするかどうか。 |
spark.tispark.tikv.trust_cert_collection | リモート PD の証明書を検証するために使用される、TiKV クライアントの信頼された証明書 (例: /home/tispark/config/root.pem 。ファイルには、X.509 証明書コレクションが含まれている必要があります。 | |
spark.tispark.tikv.key_cert_chain | TiKV クライアントの X.509 証明書チェーン ファイル (例: /home/tispark/config/client.pem )。 | |
spark.tispark.tikv.key_file | TiKV クライアントの PKCS#8 秘密鍵ファイル (例: /home/tispark/client_pkcs8.key )。 | |
spark.tispark.tikv.jks_enable | false | X.509 証明書の代わりに JAVA キー ストアを使用するかどうか。 |
spark.tispark.tikv.jks_trust_path | keytoolによって生成された、TiKV クライアントの JKS 形式の証明書 (例: /home/tispark/config/tikv-truststore )。 | |
spark.tispark.tikv.jks_trust_password | spark.tispark.tikv.jks_trust_pathのパスワード。 | |
spark.tispark.tikv.jks_key_path | keytoolによって生成された、 TiKV クライアントの JKS 形式キー (例: /home/tispark/config/tikv-clientstore )。 | |
spark.tispark.tikv.jks_key_password | spark.tispark.tikv.jks_key_pathのパスワード。 | |
spark.tispark.jdbc.tls_enable | false | JDBC コネクタを使用するときに TLS を有効にするかどうか。 |
spark.tispark.jdbc.server_cert_store | JDBCの信頼できる証明書。1 keytool生成されたJavaキーストア(JKS)形式の証明書(例: /home/tispark/config/jdbc-truststore )です。デフォルト値は "" で、TiSparkはTiDBサーバーを検証しません。 | |
spark.tispark.jdbc.server_cert_password | spark.tispark.jdbc.server_cert_storeのパスワード。 | |
spark.tispark.jdbc.client_cert_store | JDBC用のPKCS#12証明書。1 によって生成されたJKS keytoolの証明書(例: /home/tispark/config/jdbc-clientstore )です。デフォルトは "" で、TiDBサーバーはTiSparkを検証しません。 | |
spark.tispark.jdbc.client_cert_password | spark.tispark.jdbc.client_cert_storeのパスワード。 | |
spark.tispark.tikv.tls_reload_interval | 10s | 再読み込み中の証明書があるかどうかを確認する間隔。デフォルト値は10s (10秒)です。 |
spark.tispark.tikv.conn_recycle_time | 60s | TiKVを使用して期限切れの接続を消去する間隔。証明書の再読み込みが有効になっている場合にのみ有効になります。デフォルト値は60s (60秒)です。 |
spark.tispark.host_mapping | パブリックIPアドレスとイントラネットIPアドレスのマッピングを設定するためのルートマップです。TiDBクラスタがイントラネット上で実行されている場合、外部のSparkクラスタがアクセスできるように、イントラネットIPアドレスのセットをパブリックIPアドレスにマッピングできます。形式は{Intranet IP1}:{Public IP1};{Intranet IP2}:{Public IP2}です(例: 192.168.0.2:8.8.8.8;192.168.0.3:9.9.9.9 )。 | |
spark.tispark.new_collation_enable | TiDBで新しい照合順序有効になっている場合、この設定はtrueに設定できます。TiDBでnew collation有効になっていない場合、この設定はfalseに設定できます。この項目が設定されていない場合、TiSparkはTiDBのバージョンに基づいて自動的にnew collation設定します。設定ルールは次のとおりです。TiDBのバージョンがv6.0.0以上の場合はtrue 、それ以外の場合はfalseです。 | |
spark.tispark.replica_read | leader | 読み取るレプリカのタイプ。値のオプションはleader 、 follower 、 learnerです。複数のタイプを同時に指定することができ、TiSparkは順序に従ってタイプを選択します。 |
spark.tispark.replica_read.label | 対象となるTiKVノードのラベル。形式はlabel_x=value_x,label_y=value_yで、項目は論理積で接続されます。 |
TLS構成
TiSpark TLSは、TiKVクライアントTLSとJDBCコネクタTLSの2つの部分で構成されています。TiSparkでTLSを有効にするには、両方を設定する必要があります。1 spark.tispark.tikv.xxx TiKVクライアントがPDおよびTiKVサーバーとのTLS接続を確立するために使用されます。3 spark.tispark.jdbc.xxx JDBCがTiDBサーバーとのTLS接続を確立するために使用されます。
TiSpark TLS が有効になっている場合は、 tikv.trust_cert_collection 、 tikv.key_cert_chain 、 tikv.key_file構成で X.509 証明書を構成するか、 tikv.jks_enable 、 tikv.jks_trust_path 、 tikv.jks_key_pathで JKS 証明書を構成する必要があります。 jdbc.server_cert_storeとjdbc.client_cert_storeオプションです。
TiSpark は TLSv1.2 と TLSv1.3 のみをサポートします。
- 以下は、TiKV クライアントで X.509 証明書を使用して TLS 構成を開く例です。
spark.tispark.tikv.tls_enable true
spark.tispark.tikv.trust_cert_collection /home/tispark/root.pem
spark.tispark.tikv.key_cert_chain /home/tispark/client.pem
spark.tispark.tikv.key_file /home/tispark/client.key
- 以下は、TiKV クライアントで JKS 構成を使用して TLS を有効にする例です。
spark.tispark.tikv.tls_enable true
spark.tispark.tikv.jks_enable true
spark.tispark.tikv.jks_key_path /home/tispark/config/tikv-truststore
spark.tispark.tikv.jks_key_password tikv_trustore_password
spark.tispark.tikv.jks_trust_path /home/tispark/config/tikv-clientstore
spark.tispark.tikv.jks_trust_password tikv_clientstore_password
JKS証明書とX.509証明書の両方が設定されている場合、JKS証明書の方が優先されます。つまり、TLSビルダーはJKS証明書を最初に使用します。したがって、共通のPEM証明書のみを使用する場合は、 spark.tispark.tikv.jks_enable=true設定しないでください。
- 以下は、JDBC コネクタで TLS を有効にする例です。
spark.tispark.jdbc.tls_enable true
spark.tispark.jdbc.server_cert_store /home/tispark/jdbc-truststore
spark.tispark.jdbc.server_cert_password jdbc_truststore_password
spark.tispark.jdbc.client_cert_store /home/tispark/jdbc-clientstore
spark.tispark.jdbc.client_cert_password jdbc_clientstore_password
- TiDB TLS を開く方法の詳細については、 TiDBクライアントとサーバー間のTLSを有効にする参照してください。
- JAVA キーストアの生成方法の詳細については、 SSLを使用した安全な接続参照してください。
Log4jの設定
spark-shellまたはspark-sqlを起動してクエリを実行すると、次の警告が表示される場合があります。
Failed to get database ****, returning NoSuchObjectException
Failed to get database ****, returning NoSuchObjectException
ここで、 ****データベース名です。
これらの警告は無害であり、Spark が自身のカタログ内で****見つけられないために発生します。これらの警告は無視して構いません。
ミュートするには、次のテキストを${SPARK_HOME}/conf/log4j.propertiesに追加します。
# tispark disable "WARN ObjectStore:568 - Failed to get database"
log4j.logger.org.apache.hadoop.hive.metastore.ObjectStore=ERROR
タイムゾーンの設定
-Duser.timezoneシステム プロパティ (たとえば、 -Duser.timezone=GMT-7 ) を使用してタイム ゾーンを設定します。これはTimestampタイプに影響します。
spark.sql.session.timeZone使用しないでください。
特徴
TiSpark の主な機能は次のとおりです。
| 機能サポート | TiSpark 2.4.x | TiSpark 2.5.x | TiSpark 3.0.x | TiSpark 3.1.x |
|---|---|---|---|---|
| tidb_catalog なしの SQL 選択 | ✔ | ✔ | ||
| tidb_catalogを使用したSQL選択 | ✔ | ✔ | ✔ | |
| データフレームの追加 | ✔ | ✔ | ✔ | ✔ |
| DataFrameの読み取り | ✔ | ✔ | ✔ | ✔ |
| SQL 表示データベース | ✔ | ✔ | ✔ | ✔ |
| SQL 表示テーブル | ✔ | ✔ | ✔ | ✔ |
| SQL認証 | ✔ | ✔ | ✔ | |
| SQL削除 | ✔ | ✔ | ||
| SQL挿入 | ✔ | |||
| TLS | ✔ | ✔ | ||
| データフレーム認証 | ✔ |
式インデックスのサポート
TiDB v5.0 は表現インデックスサポートします。
TiSpark は現在、 expression indexを使用してテーブルからデータを取得することをサポートしていますが、 expression index TiSpark のプランナーによって使用されません。
TiFlashの操作
TiSpark は、構成spark.tispark.isolation_read_enginesを介してTiFlashからデータを読み取ることができます。
パーティションテーブルのサポート
TiDBからパーティションテーブルを読み取る
TiSpark は、TiDB から範囲およびハッシュ パーティション テーブルを読み取ることができます。
現在、TiSparkはMySQL/TiDBパーティションテーブル構文select col_name from table_name partition(partition_name)サポートしていません。ただし、 where条件を使用してパーティションをフィルタリングすることは可能です。
TiSpark は、テーブルに関連付けられたパーティション タイプとパーティション式に応じて、パーティション プルーニングを適用するかどうかを決定します。
TiSpark は、パーティション式が次のいずれかである場合にのみ、範囲パーティション分割にパーティション プルーニングを適用します。
- 列式
YEAR($argument)引数は列であり、その型は datetime または datetime として解析できる文字列リテラルです。
パーティション プルーニングが適用できない場合、TiSpark の読み取りはすべてのパーティションに対してテーブル スキャンを実行することと同じです。
パーティションテーブルに書き込む
現在、TiSpark は、次の条件下でのみ、範囲パーティション テーブルおよびハッシュ パーティション テーブルへのデータの書き込みをサポートしています。
- パーティション式は列式です。
- パーティション式は
YEAR($argument)で、引数は列であり、その型は datetime または datetime として解析できる文字列リテラルです。
パーティション テーブルに書き込むには、次の 2 つの方法があります。
- データ ソース API を使用して、置換および追加のセマンティクスをサポートするパーティション テーブルに書き込みます。
- Spark SQL で delete ステートメントを使用します。
注記:
現在、TiSpark は、utf8mb4_bin照合順序が有効になっているパーティション テーブルへの書き込みのみをサポートしています。
Security
TiSpark v2.5.0 以降のバージョンを使用している場合は、TiDB を使用して TiSpark ユーザーを認証および承認できます。
認証と認可機能はデフォルトで無効になっています。有効にするには、Spark構成ファイルspark-defaults.confに以下の設定を追加してください。
// Enable authentication and authorization
spark.sql.auth.enable true
// Configure TiDB information
spark.sql.tidb.addr $your_tidb_server_address
spark.sql.tidb.port $your_tidb_server_port
spark.sql.tidb.user $your_tidb_server_user
spark.sql.tidb.password $your_tidb_server_password
詳細についてはTiDBサーバーを介した認可と認証参照してください。
その他の機能
統計情報
TiSpark は統計情報を次の目的で使用します。
- 最小の推定コストでクエリ プランで使用するインデックスを決定します。
- 効率的なブロードキャスト参加を可能にする小さなテーブル ブロードキャスト。
TiSpark が統計情報にアクセスできるようにするには、関連するテーブルが分析されていることを確認してください。
テーブルを分析する方法の詳細については、 統計入門参照してください。
TiSpark 2.0 以降では、統計情報はデフォルトで自動的に読み込まれます。
FAQ
TiSparkFAQ参照。