TiDB Lightning の概要
TiDB Lightning 、TB規模のデータをTiDBクラスタにインポートするためのツールです。TiDBクラスタへの初期データインポートによく使用されます。
TiDB Lightning は次のファイル形式をサポートしています。
- Dumplingによってエクスポートされたファイル
- CSVファイル
- Amazon Auroraによって生成された Apache Parquet ファイル 、Apache Hive、またはSnowflake
TiDB Lightning は次のソースからデータを読み取ることができます。
注記:
TiDB Lightningと比較すると、
IMPORT INTOステートメントは TiDB ノード上で直接実行でき、自動化された分散タスクスケジューリングとTiDB グローバルソートサポートし、デプロイメント、リソース利用率、タスク設定の利便性、呼び出しと統合の容易さ、高可用性、スケーラビリティにおいて大幅な改善が見られます。適切なシナリオでは、 TiDB LightningではなくIMPORT INTO使用を検討することをお勧めします。
TiDB Lightningアーキテクチャ
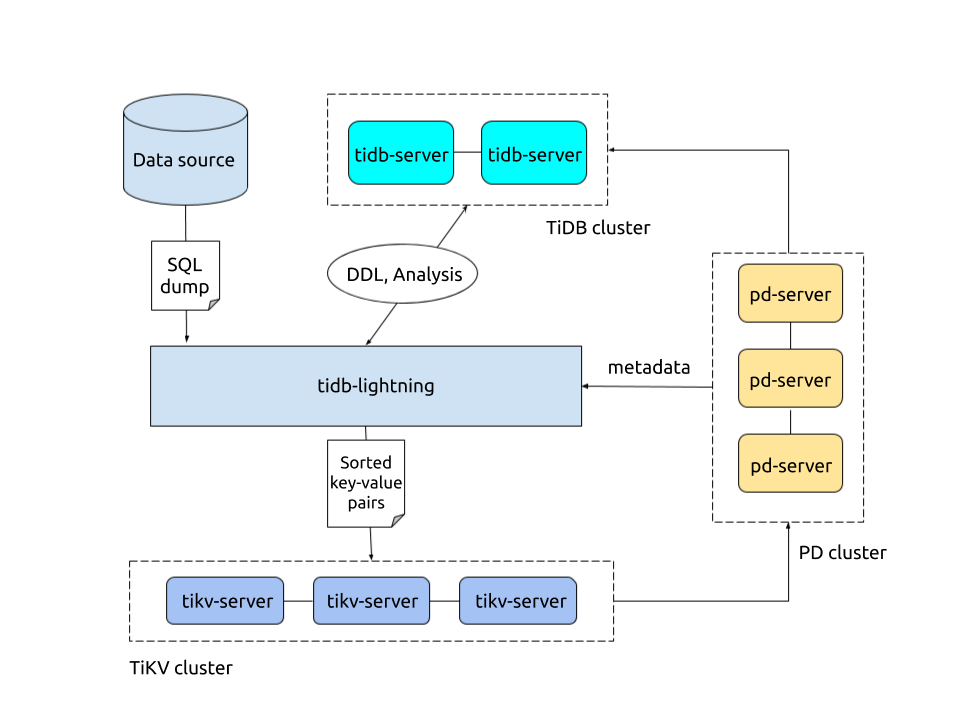
TiDB Lightning は、 backendで設定された 2 つのインポート モードをサポートしています。インポート モードによって、TiDB へのデータのインポート方法が決まります。
物理インポートモード : TiDB Lightningは、まずデータをキーと値のペアにエンコードし、ローカルの一時ディレクトリに保存します。次に、これらのキーと値のペアを各TiKVノードにアップロードし、最後にTiKV 取り込みインターフェースを呼び出してTiKVのRocksDBにデータを挿入します。初期インポートを実行する必要がある場合は、インポート速度が速い物理インポートモードを検討してください。物理インポートモードのバックエンドは
localです。論理インポートモード : TiDB Lightning はまずデータをSQL文にエンコードし、その後、これらのSQL文を直接実行してデータをインポートします。インポート対象のクラスターが本番の場合、またはインポート対象のテーブルに既にデータが含まれている場合は、論理インポートモードを使用してください。論理インポートモードのバックエンドは
tidbです。