プライマリクラスタとセカンダリクラスタに基づくDRソリューション
プライマリデータベースとセカンダリデータベースに基づく災害復旧(DR)は、一般的なソリューションです。このソリューションでは、DRシステムはプライマリクラスタとセカンダリクラスタで構成されます。プライマリクラスタはユーザーリクエストを処理し、セカンダリクラスタはプライマリクラスタからデータをバックアップします。プライマリクラスタに障害が発生した場合、セカンダリクラスタがサービスを引き継ぎ、バックアップデータを使用してサービスの提供を継続します。これにより、障害による中断なしに、業務システムを正常に稼働し続けることができます。
プライマリ/セカンダリ DR ソリューションには、次の利点があります。
- 高可用性: プライマリ/セカンダリアーキテクチャによりシステムの可用性が向上し、あらゆる障害からの迅速な回復が保証されます。
- 高速スイッチオーバー: プライマリ クラスターに障害が発生した場合、システムはセカンダリ クラスターに迅速に切り替えて、サービスを継続的に提供できます。
- データの整合性:セカンダリクラスターは、プライマリクラスターのデータをほぼリアルタイムでバックアップします。これにより、障害発生時にシステムがセカンダリクラスターに切り替わった場合でも、データは基本的に最新の状態になります。
このドキュメントには次の内容が含まれています。
- プライマリ クラスターとセカンダリ クラスターをセットアップします。
- プライマリ クラスターからセカンダリ クラスターにデータを複製します。
- クラスターを監視します。
- DR スイッチオーバーを実行します。
また、このドキュメントでは、セカンダリ クラスターでビジネス データをクエリする方法と、プライマリ クラスターとセカンダリ クラスター間で双方向レプリケーションを実行する方法についても説明します。
TiCDC に基づいてプライマリ クラスターとセカンダリ クラスターを設定する
アーキテクチャ
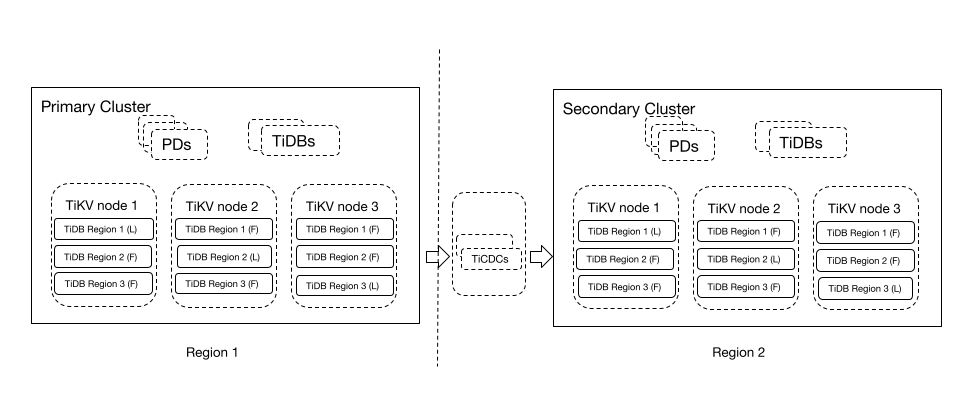
上記のアーキテクチャには、プライマリ クラスターとセカンダリ クラスターの 2 つの TiDB クラスターが含まれています。
- プライマリクラスター:リージョン1で実行され、3つのレプリカを持つアクティブクラスター。このクラスターは読み取りおよび書き込みリクエストを処理します。
- セカンダリ クラスター: リージョン 2 で実行され、TiCDC を介してプライマリ クラスターからデータを複製するスタンバイ クラスター。
このDRアーキテクチャはシンプルで使いやすいです。地域的な障害にも耐えられるため、プライマリクラスタの書き込みパフォーマンスの低下を防ぎ、セカンダリクラスタはレイテンシの影響を受けにくい読み取り専用業務を処理できます。このソリューションの目標復旧時点(RPO)は数秒単位、目標復旧時間(RTO)は数分、あるいはそれ以下も可能です。これは、多くのデータベースベンダーが重要な本番システム向けに推奨するソリューションです。
注記:
- TiKVの「リージョン」データの範囲を意味し、「リージョン」という用語は物理的な場所を意味します。この 2 つの用語は互換性がありません。
- セカンダリクラスターにデータを複製するために複数の変更フィードを実行したり、セカンダリクラスターが既に存在する状態で別のセカンダリクラスターを実行したりしないでください。そうしないと、セカンダリクラスターのデータトランザクションの整合性が保証されません。
プライマリクラスタとセカンダリクラスタを設定する
このドキュメントでは、TiDB のプライマリクラスタとセカンダリクラスタが 2 つの異なるリージョン(リージョン 1 とリージョン 2)にデプロイされています。プライマリクラスタとセカンダリクラスタの間には一定のネットワークレイテンシーがあるため、TiCDC はセカンダリクラスタと共にデプロイされています。TiCDC をセカンダリクラスタと共にデプロイすることで、ネットワークレイテンシーの影響を回避でき、最適なレプリケーションパフォーマンスを実現できます。このドキュメントで示されている例のデプロイトポロジは次のとおりです(1 つのコンポーネントノードが 1 つのサーバーにデプロイされています)。
| リージョン | ホスト | クラスタ | 成分 |
|---|---|---|---|
| リージョン1 | 10.0.1.9 | 主要な | モニター、Grafana、またはAlterManager |
| リージョン2 | 10.0.1.11 | 二次 | モニター、Grafana、またはAlterManager |
| リージョン1 | 10.0.1.1/10.0.1.2/10.0.1.3 | 主要な | PD |
| リージョン2 | 10.1.1.1/10.1.1.2/10.1.1.3 | 二次 | PD |
| リージョン2 | 10.1.1.9/10.1.1.10 | 主要な | TiCDC |
| リージョン1 | 10.0.1.4/10.0.1.5 | 主要な | TiDB |
| リージョン2 | 10.1.1.4/10.1.1.5 | 二次 | TiDB |
| リージョン1 | 10.0.1.6/10.0.1.7/10.0.1.8 | 主要な | TiKV |
| リージョン2 | 10.1.1.6/10.1.1.7/10.1.1.8 | 二次 | TiKV |
サーバー構成については、次のドキュメントを参照してください。
TiDB プライマリ クラスターとセカンダリ クラスターを展開する方法の詳細については、 TiDBクラスタをデプロイ参照してください。
TiCDC を展開する場合、セカンダリ クラスターと TiCDC を一緒に展開および管理する必要があり、それらの間のネットワークが接続されている必要があることに注意してください。
既存のプライマリ クラスターに TiCDC をデプロイするには、 TiCDCをデプロイ参照してください。
新しいプライマリ クラスターと TiCDC をデプロイするには、次のデプロイ テンプレートを使用し、必要に応じて構成パラメータを変更します。
global: user: "tidb" ssh_port: 22 deploy_dir: "/tidb-deploy" data_dir: "/tidb-data" server_configs: {} pd_servers: - host: 10.0.1.1 - host: 10.0.1.2 - host: 10.0.1.3 tidb_servers: - host: 10.0.1.4 - host: 10.0.1.5 tikv_servers: - host: 10.0.1.6 - host: 10.0.1.7 - host: 10.0.1.8 monitoring_servers: - host: 10.0.1.9 grafana_servers: - host: 10.0.1.9 alertmanager_servers: - host: 10.0.1.9 cdc_servers: - host: 10.1.1.9 gc-ttl: 86400 data_dir: "/cdc-data" ticdc_cluster_id: "DR_TiCDC" - host: 10.1.1.10 gc-ttl: 86400 data_dir: "/cdc-data" ticdc_cluster_id: "DR_TiCDC"
プライマリクラスタからセカンダリクラスタにデータを複製する
TiDB プライマリ クラスターとセカンダリ クラスターを設定したら、まずプライマリ クラスターからセカンダリ クラスターにデータを移行し、次にプライマリ クラスターからセカンダリ クラスターにリアルタイムの変更データを複製するレプリケーション タスクを作成します。
外部storageを選択
データの移行とリアルタイムの変更データのレプリケーションには外部storageを使用します。Amazon S3 が推奨されます。TiDB クラスターを自社構築のデータセンターにデプロイする場合は、以下の方法が推奨されます。
- バックアップstorageシステムとしてミニオ構築し、S3 プロトコルを使用してデータを MinIO にバックアップします。
- ネットワーク ファイル システム (NFS、NAS など) ディスクを br コマンドライン ツール、TiKV、および TiCDC インスタンスにマウントし、POSIX ファイル システム インターフェイスを使用して、対応する NFS ディレクトリにバックアップ データを書き込みます。
以下の例では、storageシステムとしてMinIOを使用していますが、参考用です。リージョン1またはリージョン2にMinIOをデプロイするには、別途サーバーを用意する必要があります。
wget https://dl.min.io/server/minio/release/linux-amd64/minio
chmod +x minio
# Configure access-key and access-secret-id to access MinIO
export HOST_IP='10.0.1.10' # Replace it with the IP address of MinIO
export MINIO_ROOT_USER='minio'
export MINIO_ROOT_PASSWORD='miniostorage'
# Create the redo and backup directories. `backup` and `redo` are bucket names.
mkdir -p data/redo
mkdir -p data/backup
# Start minio at port 6060
nohup ./minio server ./data --address :6060 &
上記のコマンドは、Amazon S3 サービスをシミュレートするために、1 つのノードで MinIOサーバーを起動します。コマンドのパラメータは次のように設定されています。
endpoint:http://10.0.1.10:6060/access-key:miniosecret-access-key:miniostoragebucketbackupredo
リンクは次のとおりです。
s3://backup?access-key=minio&secret-access-key=miniostorage&endpoint=http://10.0.1.10:6060&force-path-style=true
データの移行
バックアップと復元機能使用して、プライマリ クラスターからセカンダリ クラスターにデータを移行します。
GCを無効にします。増分マイグレーション中に新しく書き込まれたデータが削除されないようにするには、バックアップ前に上流クラスタのGCを無効にする必要があります。これにより、履歴データが削除されなくなります。
GC を無効にするには、次のステートメントを実行します。
SET GLOBAL tidb_gc_enable=FALSE;変更が有効になっていることを確認するには、
tidb_gc_enableの値を照会します。SELECT @@global.tidb_gc_enable;値が
0場合、GC が無効であることを意味します。+-------------------------+ | @@global.tidb_gc_enable | +-------------------------+ | 0 | +-------------------------+ 1 row in set (0.00 sec)注記:
本番のクラスタでは、GCを無効にしてバックアップを実行すると、クラスタのパフォーマンスに影響する可能性があります。パフォーマンスの低下を防ぐため、データのバックアップはオフピーク時間帯に行い、
RATE_LIMIT適切な値に設定することをお勧めします。データをバックアップします。アップストリームクラスターで
BACKUPステートメントを実行してデータをバックアップします。BACKUP DATABASE * TO '`s3://backup?access-key=minio&secret-access-key=miniostorage&endpoint=http://10.0.1.10:6060&force-path-style=true`';+----------------------+----------+--------------------+---------------------+---------------------+ | Destination | Size | BackupTS | Queue Time | Execution Time | +----------------------+----------+--------------------+---------------------+---------------------+ | s3://backup | 10315858 | 431434047157698561 | 2022-02-25 19:57:59 | 2022-02-25 19:57:59 | +----------------------+----------+--------------------+---------------------+---------------------+ 1 row in set (2.11 sec)BACKUP文が実行されると、TiDBはバックアップデータに関するメタデータを返しますBackupTSに注目してください。これは、バックアップされる前に生成されたデータです。このドキュメントでは、BackupTS増分移行の開始として使用します。データを復元します。セカンダリクラスターで
RESTOREステートメントを実行してデータを復元します。RESTORE DATABASE * FROM '`s3://backup?access-key=minio&secret-access-key=miniostorage&endpoint=http://10.0.1.10:6060&force-path-style=true`';+----------------------+----------+----------+---------------------+---------------------+ | Destination | Size | BackupTS | Queue Time | Execution Time | +----------------------+----------+----------+---------------------+---------------------+ | s3://backup | 10315858 | 0 | 2022-02-25 20:03:59 | 2022-02-25 20:03:59 | +----------------------+----------+----------+---------------------+---------------------+ 1 row in set (41.85 sec)
増分データを複製する
前のセクションで説明したようにデータを移行した後、 BackupTSから開始して、プライマリ クラスターからセカンダリ クラスターに増分データを複製できます。
変更フィードを作成します。
changefeed 構成ファイル
changefeed.tomlを作成します。[consistent] # eventual consistency: redo logs are used to ensure eventual consistency in disaster scenarios. level = "eventual" # The size of a single redo log, in MiB. The default value is 64, and the recommended value is less than 128. max-log-size = 64 # The interval for refreshing or uploading redo logs to Amazon S3, in milliseconds. The default value is 1000, and the recommended value range is 500-2000. flush-interval = 2000 # The path where redo logs are saved. storage = "s3://redo?access-key=minio&secret-access-key=miniostorage&endpoint=http://10.0.1.10:6060&force-path-style=true"プライマリ クラスターで次のコマンドを実行して、プライマリ クラスターからセカンダリ クラスターへの変更フィードを作成します。
tiup cdc cli changefeed create --server=http://10.1.1.9:8300 \ --sink-uri="mysql://{username}:{password}@10.1.1.4:4000" \ --changefeed-id="dr-primary-to-secondary" --start-ts="431434047157698561"changefeed 構成の詳細については、 TiCDC Changefeedフィード構成参照してください。
changefeed タスクが正常に実行されているかどうかを確認するには、コマンド
changefeed queryを実行します。クエリ結果には、タスク情報とタスク状態が含まれます。引数--simpleまたは-sを指定すると、基本的なレプリケーション状態とチェックポイント情報のみが表示されます。この引数を指定しない場合は、詳細なタスク設定、レプリケーション状態、レプリケーションテーブル情報が出力されます。tiup cdc cli changefeed query -s --server=http://10.1.1.9:8300 --changefeed-id="dr-primary-to-secondary"{ "state": "normal", "tso": 431434047157998561, # The TSO to which the changefeed has been replicated "checkpoint": "2020-08-27 10:12:19.579", # The physical time corresponding to the TSO "error": null }GC を有効にします。
TiCDCは、履歴データが複製される前にガベージコレクションされないようにします。そのため、プライマリクラスターからセカンダリクラスターへの変更フィードを作成した後、次のステートメントを実行してガベージコレクションを再度有効にすることができます。
GC を有効にするには、次のステートメントを実行します。
SET GLOBAL tidb_gc_enable=TRUE;変更が有効になっていることを確認するには、
tidb_gc_enableの値を照会します。SELECT @@global.tidb_gc_enable;値が
1の場合、GC が有効であることを意味します。+-------------------------+ | @@global.tidb_gc_enable | +-------------------------+ | 1 | +-------------------------+ 1 row in set (0.00 sec)
プライマリクラスタとセカンダリクラスタを監視する
現在、TiDB には DR ダッシュボードがありません。以下のダッシュボードを使用して TiDB プライマリクラスターとセカンダリクラスターのステータスを確認し、DR スイッチオーバーを実行するかどうかを判断できます。
DRスイッチオーバーを実行する
このセクションでは、計画された DR スイッチオーバー、災害発生時の DR スイッチオーバーを実行する方法、およびセカンダリ クラスターを再構築する手順について説明します。
計画的なプライマリおよびセカンダリの切り替え
重要な業務システムについては、信頼性をテストするために定期的にDRドリルを実施することが重要です。以下はDRドリルの推奨手順です。なお、業務書き込みのシミュレーションやプロキシサービスを使用したデータベースアクセスは考慮されていないため、手順は実際のアプリケーションシナリオと異なる場合があります。必要に応じて構成を変更できます。
プライマリ クラスターでのビジネス書き込みを停止します。
書き込みがなくなったら、TiDBクラスターの最新のTSO(
Position)をクエリします。BEGIN; SELECT TIDB_CURRENT_TSO(); ROLLBACK;Query OK, 0 rows affected (0.00 sec) +--------------------+ | TIDB_CURRENT_TSO() | +--------------------+ | 452654700157468673 | +--------------------+ 1 row in set (0.00 sec) Query OK, 0 rows affected (0.00 sec)条件
TSO >= Position満たすまで、変更フィードdr-primary-to-secondaryポーリングします。tiup cdc cli changefeed query -s --server=http://10.1.1.9:8300 --changefeed-id="dr-primary-to-secondary" { "state": "normal", "tso": 438224029039198209, # The TSO to which the changefeed has been replicated "checkpoint": "2022-12-22 14:53:25.307", # The physical time corresponding to the TSO "error": null }チェンジフィードを停止します
dr-primary-to-secondary。チェンジフィードを削除すると一時停止できます。tiup cdc cli changefeed remove --server=http://10.1.1.9:8300 --changefeed-id="dr-primary-to-secondary"パラメータ
start-ts指定せずにchangefeeddr-secondary-to-primaryを作成します。changefeedは現在時刻からデータのレプリケーションを開始します。ビジネスアプリケーションのデータベースアクセス設定を変更します。ビジネスアプリケーションを再起動して、セカンダリクラスターにアクセスできるようにします。
業務アプリケーションが正常に実行されているかどうかを確認します。
上記の手順を繰り返すことで、以前のプライマリおよびセカンダリ クラスターの構成を復元できます。
災害時のプライマリとセカンダリの切り替え
プライマリクラスタが配置されている地域で停電などの災害が発生した場合、プライマリクラスタとセカンダリクラスタ間のレプリケーションが突然中断される可能性があります。その結果、セカンダリクラスタのデータがプライマリクラスタのデータと不整合になる可能性があります。
セカンダリクラスターをトランザクション整合性のある状態に復元します。具体的には、リージョン2の任意のTiCDCノードで以下のコマンドを実行し、REDOログをセカンダリクラスターに適用します。
tiup cdc redo apply --storage "s3://redo?access-key=minio&secret-access-key=miniostorage&endpoint=http://10.0.1.10:6060&force-path-style=true" --tmp-dir /tmp/redo --sink-uri "mysql://{username}:{password}@10.1.1.4:4000"このコマンドのパラメータの説明は次のとおりです。
--storage: Amazon S3 で REDO ログが保存されるパス--tmp-dir: Amazon S3 から REDO ログをダウンロードするためのキャッシュディレクトリ--sink-uri: セカンダリクラスタのアドレス
ビジネスアプリケーションのデータベースアクセス設定を変更します。ビジネスアプリケーションを再起動して、セカンダリクラスターにアクセスできるようにします。
業務アプリケーションが正常に実行されているかどうかを確認します。
プライマリクラスタとセカンダリクラスタを再構築する
プライマリクラスタで発生した災害が解決した後、またはプライマリクラスタが一時的に復旧できない場合、セカンダリクラスタのみがプライマリクラスタとして稼働しているため、TiDBクラスタは脆弱な状態になります。システムの信頼性を維持するには、DRクラスタを再構築する必要があります。
TiDBプライマリクラスタとセカンダリクラスタを再構築するには、新しいクラスタをデプロイして新しいDRシステムを構築できます。詳細については、以下のドキュメントをご覧ください。
- プライマリクラスタとセカンダリクラスタを設定する
- プライマリクラスタからセカンダリクラスタにデータを複製する
- 上記の手順が完了したら、新しいプライマリ クラスターを作成するには、 プライマリとセカンダリの切り替え参照してください。
注記:
プライマリ クラスターとセカンダリ クラスター間のデータの不整合を解決できる場合は、新しいクラスターを展開する代わりに、修復されたクラスターを使用して DR システムを再構築できます。
セカンダリクラスターでビジネスデータをクエリする
プライマリ・セカンダリDRシナリオでは、セカンダリクラスターを読み取り専用クラスターとして使用し、レイテンシの影響を受けないクエリを実行するのが一般的です。TiDBも、プライマリ・セカンダリDRソリューションでこの機能を提供します。
changefeed を作成する際は、設定ファイルで Syncpoint 機能を有効にしてください。その後、changefeed は定期的に( sync-point-intervalで)セカンダリクラスタでSET GLOBAL tidb_external_ts = @@tidb_current_ts実行することで、セカンダリクラスタにレプリケートされた一貫性のあるスナップショットポイントを設定します。
セカンダリクラスターからデータをクエリするには、ビジネスアプリケーションでSET GLOBAL|SESSION tidb_enable_external_ts_read = ON;設定します。これにより、プライマリクラスターとトランザクション的に整合性のあるデータを取得できます。
# Starting from v6.4.0, only the changefeed with the SYSTEM_VARIABLES_ADMIN or SUPER privilege can use the TiCDC Syncpoint feature.
enable-sync-point = true
# Specifies the interval at which Syncpoint aligns the primary and secondary snapshots. It also indicates the maximum latency at which you can read the complete transaction, for example, read the transaction data generated on the primary cluster two minutes ago from the secondary cluster.
# The format is in h m s. For example, "1h30m30s". The default value is "10m" and the minimum value is "30s".
sync-point-interval = "10m"
# Specifies how long the data is retained by Syncpoint in the downstream table. When this duration is exceeded, the data is cleaned up.
# The format is in h m s. For example, "24h30m30s". The default value is "24h".
sync-point-retention = "1h"
[consistent]
# eventual consistency: redo logs are used to ensure eventual consistency in disaster scenarios.
level = "eventual"
# The size of a single redo log, in MiB. The default value is 64, and the recommended value is less than 128.
max-log-size = 64
# Interval for refreshing or uploading redo logs to Amazon S3, in milliseconds. The default value is 1000, and the recommended value range is 500-2000.
flush-interval = 2000
# The path where redo logs are saved.
storage = "s3://redo?access-key=minio&secret-access-key=miniostorage&endpoint=http://10.0.1.10:6060&force-path-style=true"
注記:
プライマリ・セカンダリDRアーキテクチャでは、セカンダリクラスタは1つの変更フィードからのみデータを複製できます。そうでない場合、セカンダリクラスタのデータトランザクションの整合性は保証されません。
プライマリクラスタとセカンダリクラスタ間の双方向レプリケーションを実行する
この DR シナリオでは、2 つのリージョンの TiDB クラスターが互いの災害復旧クラスターとして機能できます。つまり、ビジネス トラフィックはリージョン構成に基づいて対応する TiDB クラスターに書き込まれ、2 つの TiDB クラスターが互いのデータをバックアップします。
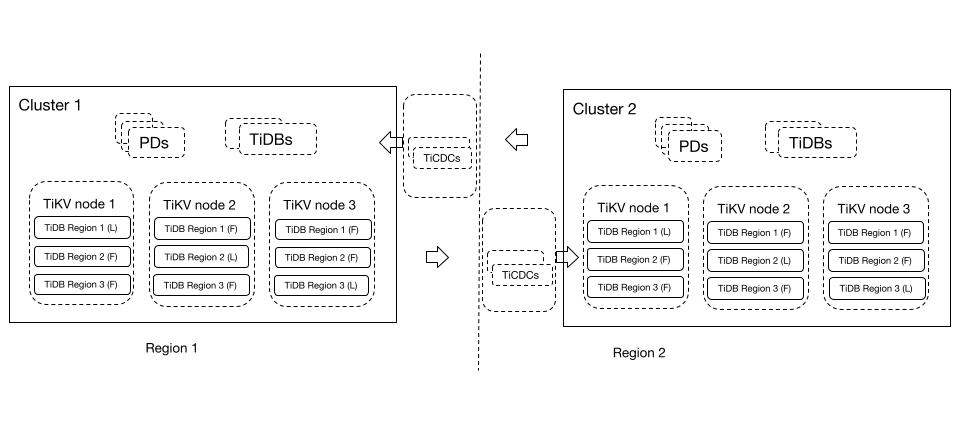
双方向レプリケーション機能により、2つのリージョンにあるTiDBクラスターは互いのデータを複製できます。このDRソリューションは、データのセキュリティと信頼性を保証するだけでなく、データベースへの書き込みパフォーマンスも確保します。計画的なDRスイッチオーバーでは、新しい変更フィードを開始する前に実行中の変更フィードを停止する必要がないため、運用と保守が簡素化されます。
双方向 DR クラスターを構築するには、 TiCDC 双方向レプリケーション参照してください。
トラブルシューティング
前の手順で問題が発生した場合は、まずTiDBに関するよくある質問で問題の解決策を見つけてください。問題が解決しない場合はバグを報告する進んでください。