TiKV 概述
TiKV 是一个分布式事务型键值数据库,提供符合 ACID 的事务 API。通过实现 Raft 共识算法 并将共识状态存储在 RocksDB 中,TiKV 保证了多个副本之间的数据一致性和高可用性。作为 TiDB 分布式数据库的存储层,TiKV 提供读写服务,并将应用程序写入的数据持久化。同时,它还存储 TiDB 集群的统计数据。
架构概述
TiKV 基于 Google Spanner 的设计实现了多 Raft 组副本机制。Region 是键值数据迁移的基本单元,指的是 Store 中的数据范围。每个 Region 会被复制到多个节点,这些副本组成一个 Raft 组。Region 的一个副本称为 Peer。通常一个 Region 有 3 个 Peer,其中一个为 Leader,负责提供读写服务。PD 组件会自动平衡所有的 Regions,以确保 TiKV 集群中所有节点的读写吞吐量均衡。在 PD 和精心设计的 Raft 组的配合下,TiKV 在水平扩展方面表现出色,能够轻松扩展存储超过 100 TB 的数据。
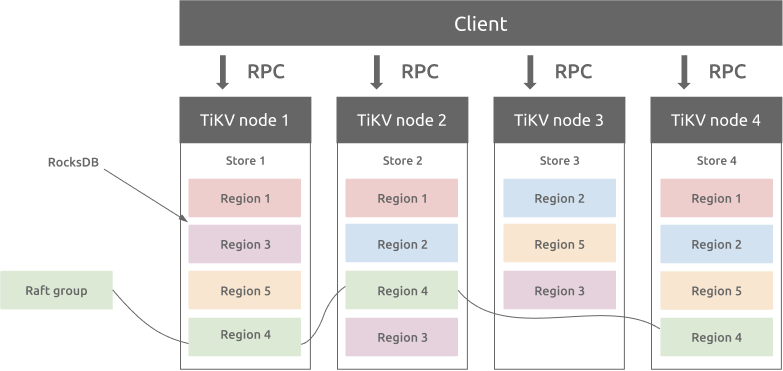
Region 和 RocksDB
每个 Store 内部都包含一个 RocksDB 数据库,用于将数据存储到本地磁盘。所有的 Region 数据都存储在每个 Store 中的同一个 RocksDB 实例中。用于 Raft 共识算法的所有日志存储在每个 Store 的另一个 RocksDB 实例中。这是因为顺序 I/O 的性能优于随机 I/O。通过不同的 RocksDB 实例存储 Raft 日志和 Region 数据,TiKV 将所有 Raft 日志的写入操作和 TiKV Region 的写入操作合并为一次 I/O 操作,从而提升性能。
Region 和 Raft 共识算法
Region 副本之间的数据一致性由 Raft 共识算法保证。只有 Region 的 Leader 才能提供写入服务,且只有在数据写入到大多数副本后,写操作才算成功。
TiKV 试图保持集群中每个 Region 的合适大小。目前默认的 Region 大小为 256 MiB。这一机制帮助 PD 组件在 TiKV 集群中平衡 Regions。当某个 Region 的大小超过阈值(默认 384 MiB)时,TiKV 会将其拆分成两个或多个 Region。当 Region 的大小小于阈值(默认 54 MiB)时,TiKV 会将两个相邻的小 Region 合并成一个 Region。
当 PD 将某个副本从一个 TiKV 节点迁移到另一个节点时,首先会在目标节点添加一个 Learner 副本,当 Learner 副本中的数据几乎与 Leader 副本相同时,PD 会将其切换为 Follower 副本,并在源节点删除 Follower 副本。
将 Leader 副本从一个节点迁移到另一个节点的机制类似。不同之处在于,Learner 副本变为 Follower 后,会进行一次 “Leader Transfer” 操作,即 Follower 主动提出选举自己为 Leader。最终,新 Leader 会在源节点删除旧的 Leader 副本。
分布式事务
TiKV 支持分布式事务。用户(或 TiDB)可以在不考虑是否属于同一 Region 的情况下,写入多个键值对。TiKV 采用两阶段提交(2PC)实现 ACID 约束。详情请参见 TiDB Optimistic Transaction Model。
TiKV Coprocessor
TiDB 将部分数据计算逻辑下推到 TiKV Coprocessor。TiKV Coprocessor 负责处理每个 Region 的计算请求。每个请求只涉及一个 Region 的数据。