TiDB X 架构
TiDB X 是一种全新的分布式 SQL 架构,其在设计上将云原生对象存储作为 TiDB 的核心存储基础。目前该架构已在 TiDB Cloud Starter 和 Essential 提供支持,能够为 AI 时代的工作负载带来弹性扩展、可预测性能以及优化的总体拥有成本(TCO)。
TiDB X 代表了从 经典 TiDB 的 shared-nothing(无共享)架构向云原生 shared-storage(共享存储)架构的根本性演进。通过将对象存储作为共享的持久化存储层,TiDB X 实现了计算工作负载的分离,从而将在线事务处理工作负载与资源密集型后台任务相隔离。
本文将介绍 TiDB X 架构,阐述 TiDB X 的设计动机,并说明与经典 TiDB 架构相比的关键创新点。
经典 TiDB 的局限性
本节将分析经典 TiDB 的架构及其局限性,这些局限性推动了 TiDB X 的诞生。
经典 TiDB 的优势
经典 TiDB 的 shared-nothing(无共享)架构解决了传统单体数据库的诸多限制。通过将计算与存储解耦,并利用 Raft 一致性算法,经典 TiDB 为分布式 SQL 工作负载提供了所需的高可用性和可扩展性。
经典 TiDB 架构具备以下基础能力:
- 水平扩展:支持读写性能的线性扩展。集群能够扩展到每秒处理数百万次查询(QPS),并管理超过 1 PiB 的数据和数千万张表。
- HTAP (Hybrid Transactional and Analytical Processing):统一事务处理与分析处理工作负载。通过将复杂的聚合和连接运算下推到 TiFlash(列式存储引擎),在无需复杂 ETL 管道的情况下即可对最新事务数据进行实时分析。
- 非阻塞的模式变更:采用完全在线的 DDL 实现方式。模式变更不会阻塞读写操作,使数据模型能够在几乎不影响应用延时或可用性的情况下持续演进。
- 高可用:支持无缝的集群升级和扩缩容操作,确保在维护或资源调整期间关键服务始终可用。
- 多云支持:作为开源解决方案,支持 Amazon Web Services (AWS)、Google Cloud、Microsoft Azure 和 Alibaba Cloud,提供云平台中立性,避免厂商锁定。
经典 TiDB 面临的挑战
尽管经典 TiDB 的 shared-nothing(无共享)架构具备较高的可靠性,但由于在本地节点上将存储与计算紧密耦合,在超大规模环境下仍会暴露出一些限制。随着数据规模的增长以及云原生需求的演进,若干结构性挑战逐渐显现。
扩展性限制
数据迁移开销:在经典 TiDB 中,扩容(增加节点)或缩容(移除节点)都需要在节点之间进行 SST 文件的物理迁移。对于大规模数据集,这一过程耗时较长,并且在迁移过程中会消耗大量 CPU 和 I/O 资源,从而可能影响在线业务性能。
存储引擎瓶颈:经典 TiDB 底层使用的 RocksDB 存储引擎采用单一 LSM tree,并通过全局 mutex 互斥锁进行保护。这种设计会带来扩展性上限,当数据量很大时(例如单个 TiKV 节点超过 6 TiB 数据或超过 30 万个 SST 文件),系统难以充分利用硬件资源。
稳定性与性能干扰
资源争用:大量写入流量会触发本地 compaction 作业以合并 SST 文件。在经典 TiDB 中,由于 compaction 与在线流量运行在同一 TiKV 节点上,它们会竞争相同的 CPU 和 I/O 资源,从而可能影响在线应用。
缺乏物理隔离:逻辑 Region 与物理 SST 文件之间没有物理隔离。诸如 Region 迁移(负载均衡)等操作会引发 compaction 开销,并直接与用户查询竞争资源,可能导致性能抖动。
写入限流:在高写入压力下,如果后台 compaction 无法跟上前台写入速度,经典 TiDB 会触发流量控制机制以保护存储引擎。这会导致写吞吐受限,并使应用延时出现波动。
资源利用率与成本问题
过度预配:为了在高峰流量和后台维护任务同时存在时保持稳定性和性能,用户通常需要根据“高水位”需求进行硬件过度预配。
扩展不灵活:由于计算与存储耦合,用户可能不得不增加昂贵的高配置计算节点来获取更多存储容量,即使 CPU 利用率仍然较低。
TiDB X 的设计动机
TiDB X 的推出源于将数据与物理计算资源解耦的需求。通过从 shared-nothing(无共享)架构转向 shared-storage(共享存储)架构,TiDB X 解决了耦合节点带来的物理限制,并实现以下技术目标:
- 加速扩展:通过消除物理数据迁移需求,将扩缩容性能提升最高达 10 倍。
- 任务隔离:确保后台维护任务(例如 compaction)与在线事务流量之间实现零干扰。
- 资源弹性:实现真正的“按需付费”模型,使计算资源可以独立于存储容量进行弹性扩展。
有关该架构演进的更多背景信息,请参阅博客文章 The Making of TiDB X: Origins, Architecture, and What’s to Come。
TiDB X 架构概览
TiDB X 是经典 TiDB 分布式设计的云原生演进版本。它继承了经典 TiDB 的以下架构优势:
- 无状态 SQL 层:SQL 层(TiDB server)是无状态的,负责查询解析、优化和执行,但不存储持久化数据。
- 网关与连接管理:TiProxy(或负载均衡器)维护持久的客户端连接并无缝路由 SQL 流量。TiProxy 最初用于支持在线升级,现在已成为天然的网关组件。
- 基于 Region 的动态分片:TiKV 使用基于范围的分片单元 Region(默认 256 MiB)。数据被拆分为数百万个 Region,系统会自动管理 Region 的放置、迁移和负载均衡。
TiDB X 在这些基础之上,将本地 shared-nothing(无共享)存储替换为 云原生 shared-storage(共享存储)对象存储。这一转变实现了“计算与计算分离”模型,将资源密集型任务卸载到弹性资源池,从而实现即时扩展和可预测性能。
TiDB X 的整体架构如下图所示:
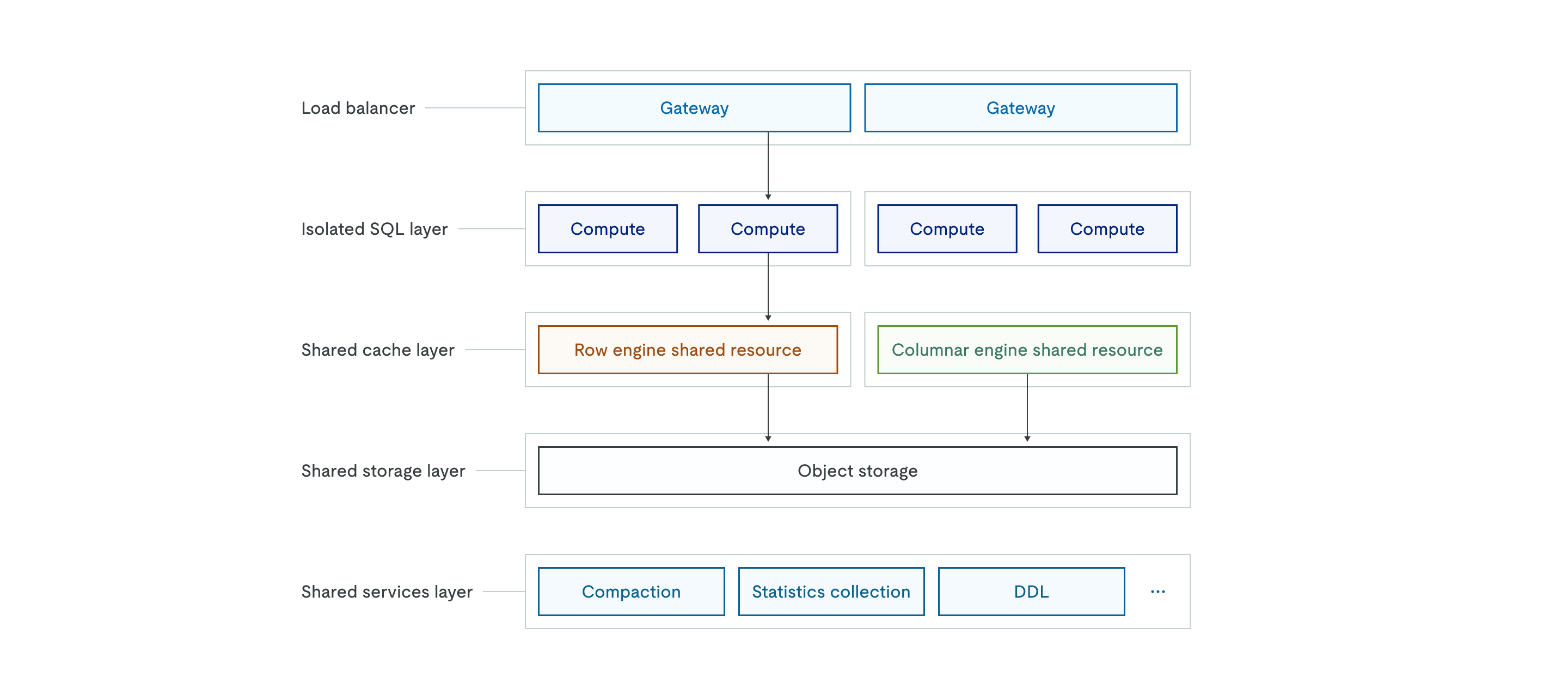
对象存储支持
TiDB X 使用对象存储(例如 Amazon S3)作为所有数据的唯一来源。与经典架构中将数据存储在本地磁盘不同,TiDB X 将所有持久化数据存储在 共享对象存储层 中,而上层的 共享缓存层(行存引擎和列存引擎)则作为高性能缓存以保证低延时。
由于所有数据已存储在对象存储中,备份操作只需依赖存储在 S3 中的增量 Raft 日志和元信息,因此无论数据量多大,备份都可以在数秒内完成。在扩容场景中,新加入的 TiKV 节点无需从现有节点复制大量数据,而是直接连接对象存储并按需加载所需数据,从而显著加快扩容速度。
自动扩缩容机制
TiDB X 架构为弹性扩展而设计,并通过负载均衡器以及 隔离 SQL 层 的无状态特性实现自动扩缩容。共享缓存层可以根据 CPU 使用率或磁盘容量进行弹性扩展,系统能够在数秒内自动增加或减少计算 Pod,以适应实时工作负载变化。
这种技术弹性使按量计费的付费模式成为可能。用户无需再为峰值流量预配资源,而是可以在流量高峰时自动扩容,在空闲时自动缩容,从而降低成本。
微服务化与工作负载隔离
TiDB X 通过精细化的职责分离来确保不同类型的工作负载互不干扰。隔离 SQL 层 由多个独立的计算节点组组成,可支持工作负载隔离或多租户场景,使不同应用在共享数据的同时使用各自专用的计算资源。
共享服务层 将复杂的数据库操作拆分为独立的微服务,包括 compaction、统计信息收集和 DDL 执行等。通过将索引创建、大规模数据导入等资源密集型后台操作卸载到该层,TiDB X 能够避免这些操作与处理在线流量的计算节点竞争 CPU 和内存资源。这一设计为关键应用提供了更可预测的性能,并允许网关、SQL 计算层、缓存层和后台服务层根据各自需求独立扩展。
TiDB X 的关键创新
下图对经典 TiDB 与 TiDB X 架构进行了并排对比,展示了从 shared-nothing(无共享) 设计到 shared-storage(共享存储) 设计的转变,以及计算工作负载分离的引入。
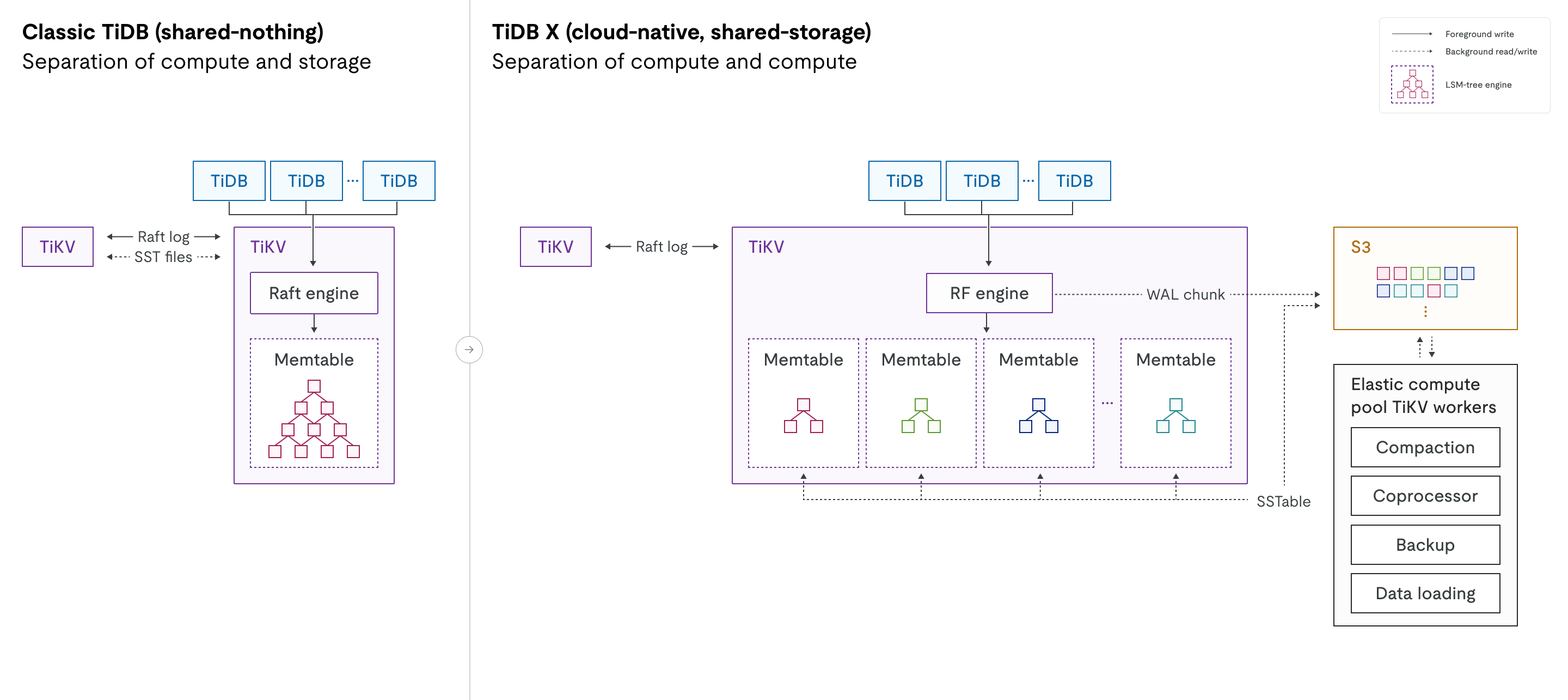
引擎演进:在经典 TiDB 中,Raft engine 负责 multi-raft log 管理,RocksDB 负责本地磁盘上的物理数据存储。在 TiDB X 中,这些组件被全新的 RF engine(Raft 引擎) 和重新设计的 KV engine 所取代。新的 KV engine 是一种 LSM tree 存储引擎,用于替代 RocksDB。两种新引擎都针对高性能和对象存储的无缝集成进行了专门优化。
计算工作负载分离:图中的虚线表示与对象存储层之间的后台读写操作。在 TiDB X 中,RF/KV engine 与对象存储之间的交互与前台进程解耦,确保后台操作不会影响在线流量的延时。
计算与计算分离
虽然经典 TiDB 已经实现了计算层(SQL 层)与存储层(TiKV)的分离,但 TiDB X 在 SQL 层和存储层内部进一步实现了更细粒度的分离,将 轻量计算 与 重计算 明确区分。
轻量计算:专用于 OLTP 工作负载的资源,例如用户查询。
对于轻量 OLTP 工作负载,由于重计算任务被卸载到弹性计算池,处理用户流量的 TiKV 服务器可以专注于在线查询处理。因此,TiDB X 能够以更少的资源提供更稳定、更可预测的性能,并确保后台任务不会干扰在线事务处理。
重计算:用于后台任务的独立弹性计算池,例如 compaction、备份、统计信息收集、数据加载和慢查询处理。
对于 DDL 操作和大规模数据导入等重计算任务,TiDB X 可以自动调度弹性计算资源,以全速运行这些工作负载,并将对在线流量的影响降到最低。例如,在创建索引时,系统会根据数据量动态调度 TiDB worker、Coprocessor worker 和 TiKV worker。这些弹性计算资源与处理在线流量的 TiDB/TiKV 服务器相互隔离,避免资源竞争。在实际场景中,索引创建速度可以比经典 TiDB 提升最多 5 倍,同时不会影响在线业务。
从 shared-nothing 到 shared-storage 的转变
TiDB X 从经典的 shared-nothing(无共享) 架构(需要在 TiKV 节点之间物理复制数据)转变为 shared-storage(共享存储) 架构。在 TiDB X 中,对象存储(如 Amazon S3)而非本地磁盘成为所有持久化数据的唯一来源。这一变化消除了扩缩容过程中复制大量数据的需求,实现了快速弹性扩展。
迁移到对象存储并不会降低前台读写性能:
- 读操作:轻量读请求直接从本地缓存和磁盘提供服务;只有重读请求才会被卸载到远程弹性 Coprocessor worker。
- 写操作:与对象存储的交互是异步的。Raft 日志首先持久化到本地磁盘,Raft WAL(预写式日志)块随后在后台上传到对象存储。
- Compaction:当 MemTable 写满并 flush 到本地磁盘后,Region Leader 会将 SST 文件上传到对象存储;远程 compaction 在弹性 compaction worker 上完成后,TiKV 节点会被通知从对象存储加载合并后的 SST 文件。
弹性 TCO(按需付费)
在经典 TiDB 中,为了同时处理高峰流量和后台任务,集群通常需要过度预配资源。TiDB X 支持 自动扩缩容,使用户只需为实际消耗的资源付费(按需付费)。后台任务所需的资源可以按需动态申请,任务完成后自动释放,从而避免成本浪费。
TiDB X 使用 Request Capacity Unit(RCU)来衡量计算能力。一个 RCU 提供固定的计算资源,可处理一定数量的 SQL 请求。用户配置的 RCU 数量决定了集群的基准性能和吞吐能力,同时可以设置上限以控制成本,并仍然享受弹性扩展带来的优势。
从 LSM tree 到 LSM forest
在经典 TiDB 中,每个 TiKV 节点运行一个单独的 RocksDB 实例,将所有 Region 的数据混合存储在一个大的 LSM tree 中。由于来自成千上万个 Region 的数据混合在一起,在进行 Region 迁移、扩缩容等操作时往往会触发大量 compaction,从而消耗大量 CPU 和 I/O 资源,并可能影响在线流量。该单一 LSM tree 由全局 mutex 保护,当数据规模增长到较大规模时(例如单节点超过 6 TiB 数据或 30 万个 SST 文件),全局 mutex 的竞争会影响读写性能。
TiDB X 对存储引擎进行了重新设计,从单一 LSM tree 转变为 LSM forest。在保留逻辑 Region 抽象的同时,TiDB X 为每个 Region 分配独立的 LSM tree。这种物理隔离消除了跨 Region compaction 的开销,使扩缩容、Region 迁移和数据加载等操作只影响各自的树结构,不再存在全局 mutex 竞争。
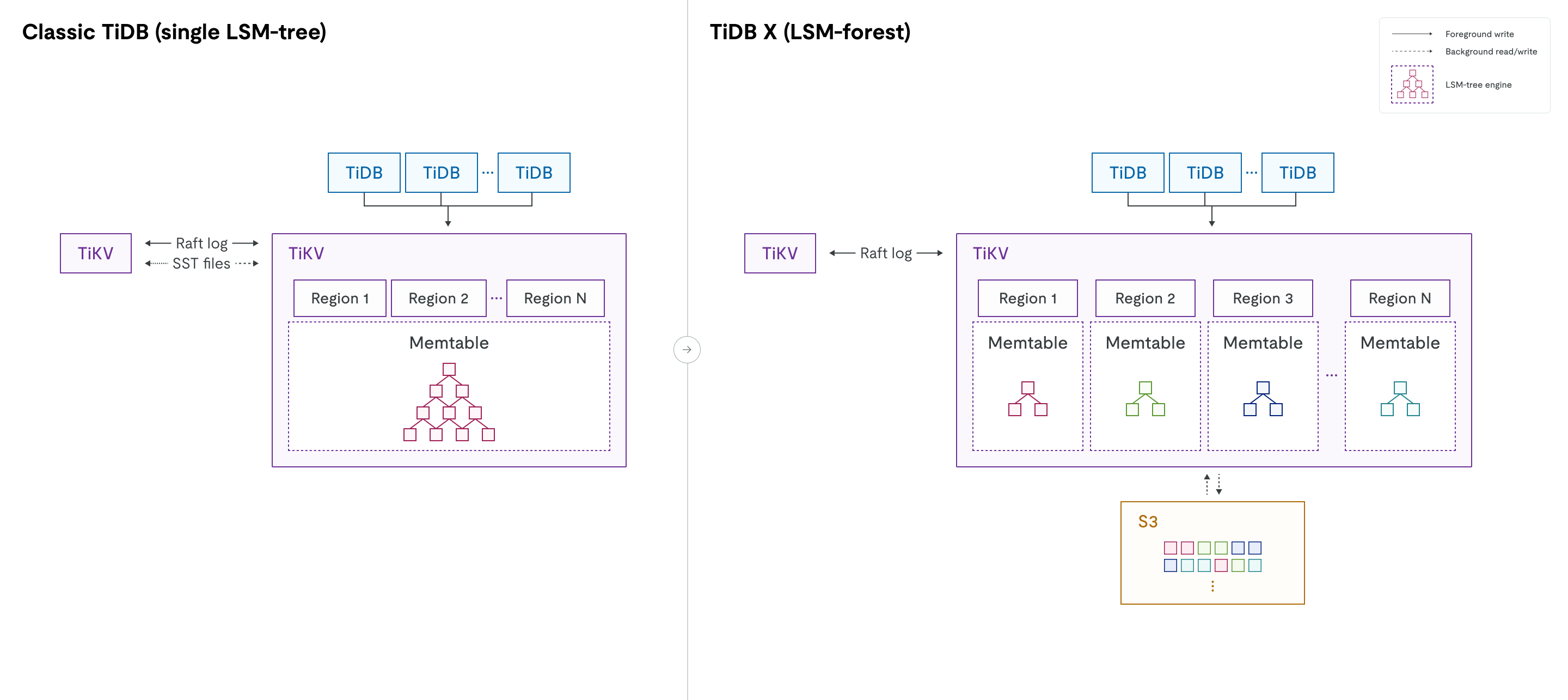
快速弹性扩展
由于数据存储在共享对象存储中,并且每个 Region 由独立的 LSM tree 管理,TiDB X 在新增或移除 TiKV 节点时无需进行物理数据迁移或大规模 compaction。因此,扩缩容操作比经典 TiDB 快 5× 至 10×,同时能够保持在线工作负载的稳定延时。
架构对比总结
下表总结了从经典 TiDB 到 TiDB X 的架构转变,并说明 TiDB X 在扩展性、性能隔离和成本效率方面的改进。
| 特性 | 经典 TiDB | TiDB X | TiDB X 的主要收益 |
|---|---|---|---|
| 架构 | Shared-nothing(数据存储在本地磁盘) | Shared-storage(对象存储作为持久化存储) | 对象存储实现云原生弹性 |
| 稳定性 | 前台与后台任务共享资源 | 计算与计算分离(重任务使用弹性计算池) | 在高写入或维护负载下保护 OLTP 工作负载 |
| 性能 | OLTP 与后台任务争用 CPU 和 I/O | 重任务使用独立弹性资源池 | 更低的 OLTP 延时,同时加速后台任务 |
| 扩展机制 | 物理数据迁移(节点间复制 SST 文件) | TiKV 通过对象存储读写 SST 文件 | 扩缩容速度提升 5×–10× |
| 存储引擎 | 每节点单一 LSM tree(RocksDB) | LSM forest(每 Region 独立 LSM tree) | 消除全局 mutex 竞争并减少 compaction 干扰 |
| DDL 执行 | 与用户流量竞争本地 CPU/I/O | DDL 卸载到弹性计算资源 | 更快的模式变更和更稳定的延时 |
| 成本模型 | 需要按峰值过度预配 | 弹性 TCO(按需付费) | 仅为实际使用的资源付费 |
| 备份 | 与数据量相关的物理备份 | 基于元信息并集成对象存储 | 备份操作显著加速 |