性能分析和调优概述
本文档介绍帮助你在 TiDB Cloud 中分析和调优 SQL 性能的步骤。
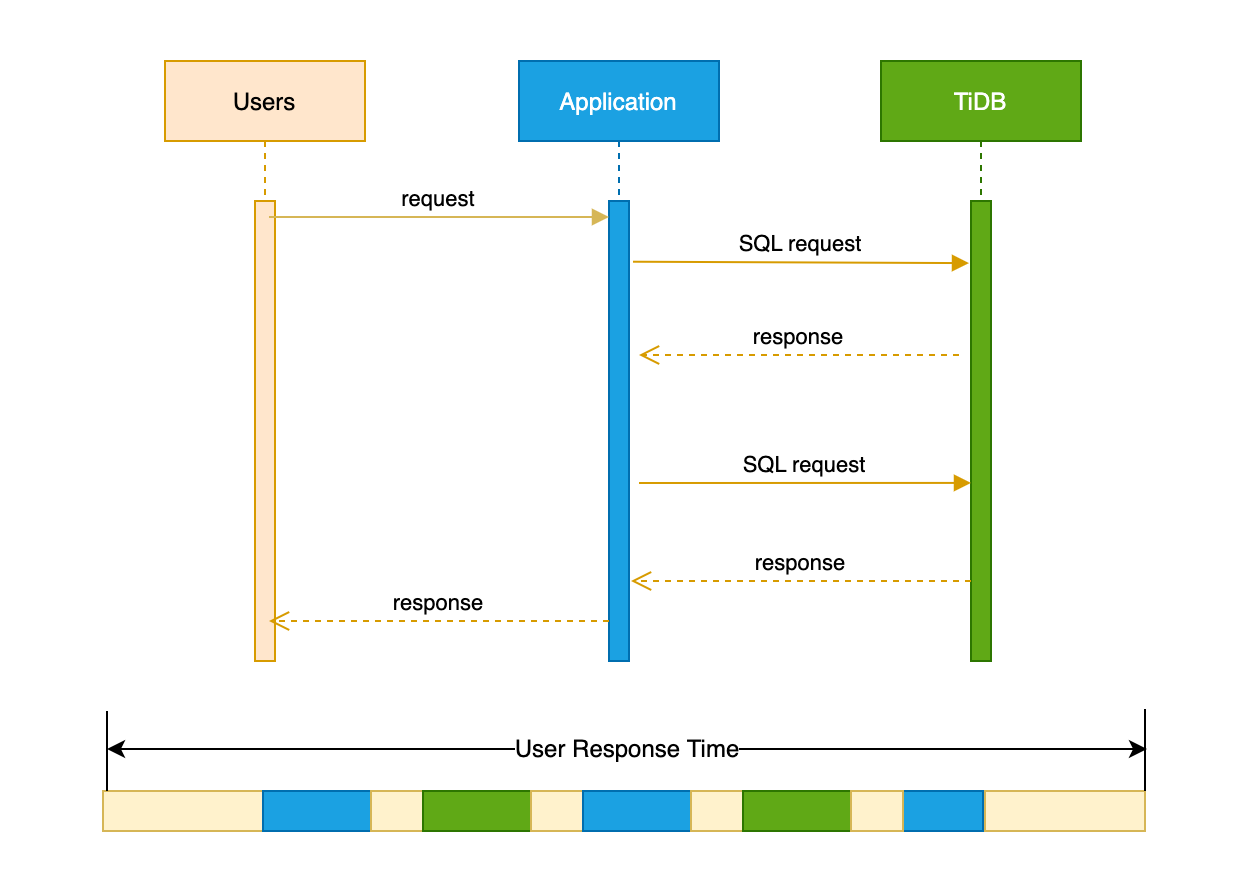
用户响应时间
用户响应时间表示应用程序返回用户请求结果所需的时间。从以下顺序时序图中可以看出,典型的用户请求时间包含以下内容:
- 用户与应用程序之间的网络延迟
- 应用程序的处理时间
- 应用程序与数据库交互期间的网络延迟
- 数据库的服务时间
用户响应时间受请求链上各个子系统的影响,如网络延迟和带宽、并发用户的数量和请求类型、服务器 CPU 和 I/O 的资源使用情况。要有效优化整个系统,你需要首先识别用户响应时间中的瓶颈。
要获取指定时间范围(ΔT)内的总用户响应时间,你可以使用以下公式:
ΔT 内的总用户响应时间 = 平均 TPS(每秒事务数)x 平均用户响应时间 x ΔT。
用户响应时间与系统吞吐量的关系
用户响应时间由服务时间、排队时间和完成用户请求的并发等待时间组成。
用户响应时间 = 服务时间 + 排队延迟 + 一致性延迟
- 服务时间:系统在处理请求时消耗某些资源的时间,例如,数据库完成 SQL 请求所消耗的 CPU 时间。
- 排队延迟:系统在处理请求时等待某些资源服务的队列时间。
- 一致性延迟:系统在处理请求时与其他并发任务通信和协作的时间,以便它可以访问共享资源。
系统吞吐量表示系统每秒可以完成的请求数。用户响应时间和吞吐量通常是相互反比的。当吞吐量增加时,系统资源利用率和请求服务的排队延迟相应增加。一旦资源利用率超过某个拐点,排队延迟将急剧增加。
例如,对于运行 OLTP 负载的数据库系统,当其 CPU 利用率超过 65% 后,CPU 排队调度延迟会显著增加。这是因为系统的并发请求并非完全独立,这意味着这些请求可以协作和竞争共享资源。例如,来自不同用户的请求可能对相同的数据执行互斥锁定操作。当资源利用率增加时,排队和调度延迟也会增加,这导致共享资源无法及时释放,进而延长了其他任务等待共享资源的时间。
排查用户响应时间中的瓶颈
TiDB Cloud 控制台中有几个页面可以帮助你排查用户响应时间。
诊断:
- SQL 语句使你能够直接在页面上观察 SQL 执行情况,无需查询系统表即可轻松定位性能问题。你可以点击 SQL 语句进一步查看查询的执行计划以进行故障排除和分析。有关 SQL 性能调优的更多信息,请参见 SQL 调优概述。
- Key Visualizer 帮助你观察 TiDB 的数据访问模式和数据热点。
指标:在此页面上,你可以查看请求单位、已用存储大小、每秒查询数和平均查询持续时间等指标。
要请求其他指标,请联系 TiDB Cloud 支持。
如果你遇到延迟和性能问题,请参考以下部分中的步骤进行分析和故障排除。
TiDB 集群外部的瓶颈
观察概览标签页上的延迟(P80)。如果此值远低于用户响应时间的 P80 值,你可以确定主要瓶颈可能在 TiDB 集群之外。在这种情况下,你可以使用以下步骤排查瓶颈。
在概览标签页左侧查看 TiDB 版本。如果是 v6.0.0 或更早版本,建议联系 PingCAP 支持团队确认是否可以启用 Prepared plan cache、Raft-engine 和 TiKV AsyncIO 功能。启用这些功能,再加上应用程序端的调优,可以显著提高吞吐性能并降低延迟和资源利用率。
如有必要,你可以增加 TiDB token 限制以提高吞吐量。
如果启用了 prepared plan cache 功能,并且你在用户端使用 JDBC,建议使用以下配置:
useServerPrepStmts=true&cachePrepStmts=true& prepStmtCacheSize=1000&prepStmtCacheSqlLimit=20480&useConfigs=maxPerformance如果你不使用 JDBC 并且想要充分利用当前 TiDB 集群的 prepared plan cache 功能,你需要在客户端缓存 prepared statement 对象。你不需要重置对 StmtPrepare 和 StmtClose 的调用。将每个查询要调用的命令数从 3 减少到 1。这需要一些开发工作,具体取决于你的性能要求和客户端更改的数量。你可以咨询 PingCAP 支持团队寻求帮助。
TiDB 集群中的瓶颈
如果你确定性能瓶颈在 TiDB 集群内,建议你执行以下操作:
- 优化慢 SQL 查询。
- 解决热点问题。
- 扩容集群以扩展容量。
优化慢 SQL 查询
有关 SQL 性能调优的更多信息,请参见 SQL 调优概述。
解决热点问题
你可以在 Key Visualizer 标签页上查看热点问题。以下截图显示了一个热力图示例。图的横坐标是时间,纵坐标是表和索引。颜色越亮表示流量越高。你可以在工具栏中切换显示读取或写入流量。
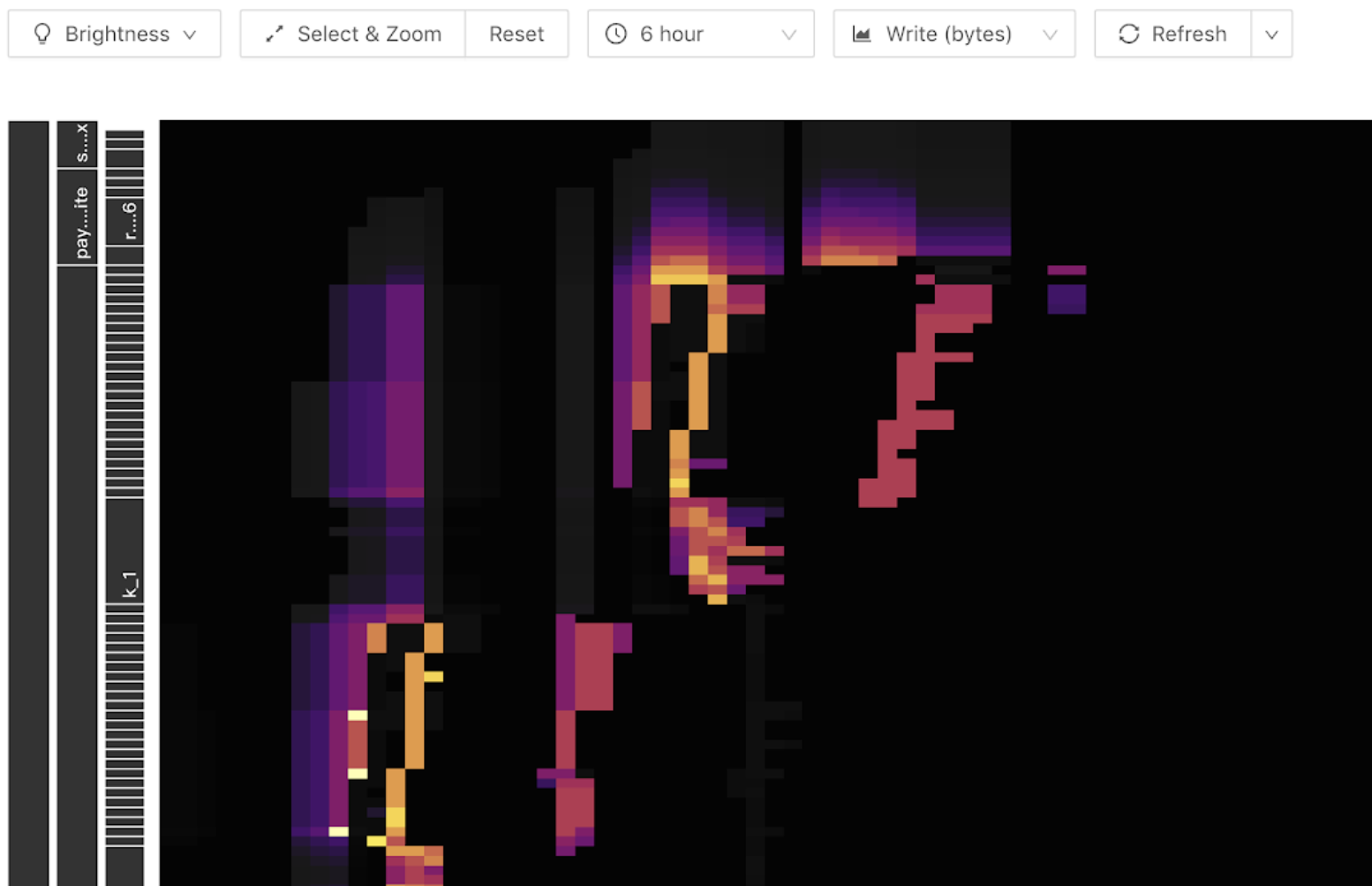
以下截图显示了一个写入热点的示例。在写入流量图中出现一条明亮的对角线(向上或向下对角),写入流量仅出现在线的末端。随着表 Region 数量的增长,它变成阶梯状模式。这表明表中存在写入热点。当出现写入热点时,你需要检查是否使用了自增主键,或者没有主键,或者使用了依赖时间的插入语句或索引。

读取热点在热力图中通常表现为一条明亮的水平线,通常是一个查询量大的小表,如下截图所示。

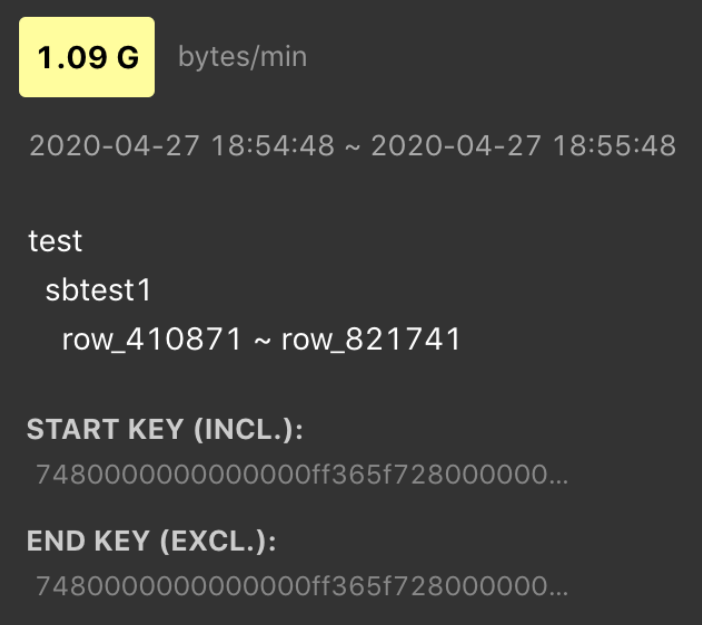
将鼠标悬停在高亮块上可以看到哪个表或索引有高流量,如下截图所示。
扩容
在集群概览页面上,检查存储空间、CPU 利用率和 TiKV IO 速率指标。如果其中任何一个长期接近上限,可能是当前集群规模无法满足业务需求。建议联系 PingCAP 支持团队确认是否需要扩容集群。
其他问题
如果上述方法无法解决性能问题,你可以联系 PingCAP 支持团队寻求帮助。建议提供以下信息以加快故障排除过程。
- 集群 ID
- 问题时间段和一个可比较的正常时间段
- 问题现象和预期行为
- 业务工作负载特征,如读写比例和主要行为
总结
一般来说,你可以使用以下优化方法来分析和解决性能问题。
| 操作 | 效果 |
|---|---|
| Prepared plan cache + JDBC | 吞吐性能将大幅提升,延迟将显著降低,平均 TiDB CPU 利用率将显著降低。 |
| 在 TiKV 中启用 AsyncIO 和 Raft-engine | 吞吐性能会有一定提升。你需要联系 PingCAP 支持团队启用它。 |
| 聚簇索引 | 吞吐性能将大幅提升。 |
| 扩容 TiDB 节点 | 吞吐性能将大幅提升。 |
| 客户端优化。将 1 个 JVM 拆分为 3 个 | 吞吐性能将显著提升,如果进一步拆分可能会继续提高吞吐容量。 |
| 限制应用程序和数据库之间的网络延迟 | 高网络延迟会导致吞吐量降低和延迟增加。 |
未来,TiDB Cloud 将引入更多可观察的指标和自诊断服务。它们将为你提供更全面的性能指标理解和运营建议,以改善你的使用体验。