统计信息简介
TiDB 使用统计信息作为优化器的输入,用于估算 SQL 语句每个执行计划步骤中处理的行数。优化器会估算每个可用执行计划的成本,包括 索引访问 和表连接的顺序,并为每个可用计划生成成本。然后,优化器选择总体成本最低的执行计划。
收集统计信息
本节介绍两种收集统计信息的方式:自动更新和手动收集。
自动更新
对于 INSERT、DELETE 或 UPDATE 语句,TiDB 会自动更新统计信息中的行数和已修改行数。
TiDB 每 60 秒持久化一次更新信息。
根据表的数据变更量,TiDB 会自动调度 ANALYZE 对这些表收集统计信息。该行为由以下系统变量控制。
| 系统变量 | 默认值 | 描述 |
|---|---|---|
tidb_auto_analyze_concurrency | 1 | TiDB 集群内自动分析操作的并发度。 |
tidb_auto_analyze_end_time | 23:59 +0000 | TiDB 可执行自动更新的每日结束时间。 |
tidb_auto_analyze_partition_batch_size | 8192 | TiDB 在分析分区表时(即自动更新分区表统计信息时)自动分析的分区数。 |
tidb_auto_analyze_ratio | 0.5 | 自动更新的阈值。 |
tidb_auto_analyze_start_time | 00:00 +0000 | TiDB 可执行自动更新的每日开始时间。 |
tidb_enable_auto_analyze | ON | 控制 TiDB 是否自动执行 ANALYZE。 |
tidb_enable_auto_analyze_priority_queue | ON | 控制是否启用优先队列调度自动收集统计信息的任务。启用后,TiDB 优先收集更有价值的表的统计信息,如新建索引和分区发生变化的分区表。此外,TiDB 会优先收集健康度较低的表,将其排在队列前面。 |
tidb_enable_stats_owner | ON | 控制对应的 TiDB 实例是否可以运行自动统计信息更新任务。 |
tidb_max_auto_analyze_time | 43200(12 小时) | 自动 ANALYZE 任务的最大执行时间,单位为秒。 |
当表中 tbl 的已修改行数与总行数的比值大于 tidb_auto_analyze_ratio,且当前时间在 tidb_auto_analyze_start_time 和 tidb_auto_analyze_end_time 之间时,TiDB 会在后台执行 ANALYZE TABLE tbl 语句,自动更新该表的统计信息。
为避免频繁修改小表数据时频繁触发自动更新,当表的行数小于 1000 时,TiDB 不会因修改而触发自动更新。你可以使用 SHOW STATS_META 语句查看表的行数。
手动收集
目前,TiDB 以全量方式收集统计信息。你可以执行 ANALYZE TABLE 语句来收集统计信息。
你可以使用以下语法进行全量收集。
收集
TableNameList中所有表的统计信息:ANALYZE TABLE TableNameList [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];WITH NUM BUCKETS指定生成直方图的最大桶数。WITH NUM TOPN指定生成的TOPN的最大数量。WITH NUM CMSKETCH DEPTH指定 CM Sketch 的深度。WITH NUM CMSKETCH WIDTH指定 CM Sketch 的宽度。WITH NUM SAMPLES指定采样数。WITH FLOAT_NUM SAMPLERATE指定采样率。
WITH NUM SAMPLES 和 WITH FLOAT_NUM SAMPLERATE 分别对应两种不同的采样算法。
详细说明请参见 直方图、Top-N 和 CMSketch(Count-Min Sketch)。关于 SAMPLES/SAMPLERATE,参见 提升收集性能。
关于持久化选项以便复用的信息,参见 持久化 ANALYZE 配置。
统计信息类型
本节介绍三种统计信息类型:直方图、Count-Min Sketch 和 Top-N。
直方图
直方图统计信息被优化器用于估算区间或范围谓词的选择性,也可能用于统计信息版本 2 中等值/IN 谓词的不同值个数估算(参见 统计信息版本)。
直方图是一种对数据分布的近似表示。它将整个取值范围划分为一系列桶,并用简单的数据描述每个桶,如落入该桶的值的数量。在 TiDB 中,会为每个表的特定列创建等深直方图。等深直方图可用于估算区间查询。
这里的“等深”指的是每个桶中落入的值的数量尽可能相等。例如,对于集合 {1.6, 1.9, 1.9, 2.0, 2.4, 2.6, 2.7, 2.7, 2.8, 2.9, 3.4, 3.5},如果要生成 4 个桶,则等深直方图为 [1.6, 1.9]、[2.0, 2.6]、[2.7, 2.8]、[2.9, 3.5],每个桶的深度为 3。
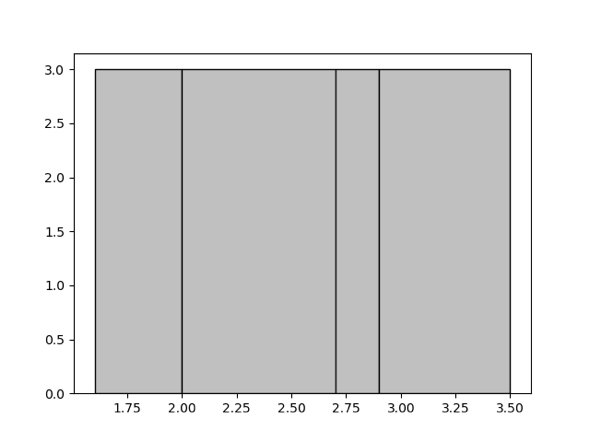
关于决定直方图桶数上限的参数,参见 手动收集。桶数越大,直方图的精度越高;但更高的精度会消耗更多内存资源。你可以根据实际场景适当调整该值。
Count-Min Sketch
Count-Min Sketch 是一种哈希结构。在处理如 a = 1 的等值查询或 IN 查询(如 a IN (1, 2, 3))时,TiDB 使用该数据结构进行估算。
由于 Count-Min Sketch 是哈希结构,可能会发生哈希冲突。在 EXPLAIN 语句中,如果等值查询的估算值与实际值偏差很大,可能是因为较大值和较小值被哈希到了一起。此时,你可以通过以下方式避免哈希冲突:
- 修改
WITH NUM TOPN参数。TiDB 会将高频(前 x 个)数据单独存储,其余数据存储在 Count-Min Sketch 中。因此,为防止较大值和较小值哈希到一起,可以增大WITH NUM TOPN的值。TiDB 默认值为 20,最大值为 1024。详细信息参见 手动收集。 - 修改
WITH NUM CMSKETCH DEPTH和WITH NUM CMSKETCH WIDTH两个参数。两者共同影响哈希桶数量和冲突概率。你可以根据实际场景适当增大这两个参数的值,以降低哈希冲突概率,但会增加统计信息的内存消耗。TiDB 中,WITH NUM CMSKETCH DEPTH默认值为 5,WITH NUM CMSKETCH WIDTH默认值为 2048。详细信息参见 手动收集。
Top-N
Top-N 值是指某一列或索引中出现次数最多的前 N 个值。Top-N 统计信息也常被称为频率统计或数据倾斜。
TiDB 会记录 Top-N 值及其出现次数。N 由 WITH NUM TOPN 参数控制,默认值为 20,即收集出现频率最高的 20 个值。最大值为 1024。关于该参数的详细说明,参见 手动收集。
选择性统计信息收集
本节介绍如何有选择地收集统计信息。
收集索引统计信息
要收集 TableName 中 IndexNameList 所有索引的统计信息,使用以下语法:
ANALYZE TABLE TableName INDEX [IndexNameList] [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];
当 IndexNameList 为空时,该语法会收集 TableName 中所有索引的统计信息。
收集部分列的统计信息
在执行 SQL 语句时,优化器大多数情况下只会用到部分列的统计信息。例如,出现在 WHERE、JOIN、ORDER BY 和 GROUP BY 子句中的列,这些列称为谓词列(predicate columns)。
如果表中列很多,收集所有列的统计信息会带来较大开销。为降低开销,你可以只为特定列(自定义选择)或 PREDICATE COLUMNS(谓词列)收集统计信息,以供优化器使用。若需持久化任意子集的列列表以便后续复用,参见 持久化列配置。
要收集指定列的统计信息,使用以下语法:
ANALYZE TABLE TableName COLUMNS ColumnNameList [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];其中,
ColumnNameList指定目标列名列表。若需指定多个列名,使用英文逗号,分隔。例如:ANALYZE table t columns a, b。该语法除了收集指定表的特定列统计信息外,还会同时收集该表的索引列及所有索引的统计信息。要收集
PREDICATE COLUMNS的统计信息,使用以下语法:ANALYZE TABLE TableName PREDICATE COLUMNS [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];TiDB 每 300 秒会将
PREDICATE COLUMNS信息写入mysql.column_stats_usage系统表。除了收集指定表的
PREDICATE COLUMNS统计信息外,该语法还会同时收集该表的索引列及所有索引的统计信息。要收集所有列和索引的统计信息,使用以下语法:
ANALYZE TABLE TableName ALL COLUMNS [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];
收集分区统计信息
要收集
TableName中PartitionNameList所有分区的统计信息,使用以下语法:ANALYZE TABLE TableName PARTITION PartitionNameList [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];要收集
TableName中PartitionNameList所有分区的索引统计信息,使用以下语法:ANALYZE TABLE TableName PARTITION PartitionNameList INDEX [IndexNameList] [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];如果你只需收集部分分区的部分列统计信息,使用以下语法:
ANALYZE TABLE TableName PARTITION PartitionNameList [COLUMNS ColumnNameList|PREDICATE COLUMNS|ALL COLUMNS] [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];
动态裁剪模式下收集分区表统计信息
在 动态裁剪模式(自 v6.3.0 起为默认)下访问分区表时,TiDB 会收集表级统计信息,即分区表的全局统计信息。目前,全局统计信息是从所有分区的统计信息聚合而来。在动态裁剪模式下,表中任一分区的统计信息更新都可能触发该表全局统计信息的更新。
如果部分分区的统计信息为空,或部分分区缺少某些列的统计信息,则收集行为由 tidb_skip_missing_partition_stats 变量控制:
当触发全局统计信息更新且
tidb_skip_missing_partition_stats为OFF时:如果部分分区没有统计信息(如新建分区从未被分析过),全局统计信息生成会中断,并显示警告信息,提示分区上无统计信息。
如果某些分区缺少特定列的统计信息(这些分区分析时指定了不同的列),在聚合这些列的统计信息时,全局统计信息生成会中断,并显示警告信息,提示某些分区缺少某些列的统计信息。
当触发全局统计信息更新且
tidb_skip_missing_partition_stats为ON时:- 如果部分分区缺少全部或部分列的统计信息,TiDB 在生成全局统计信息时会跳过这些缺失的分区统计信息,不影响全局统计信息的生成。
在动态裁剪模式下,分区和表的 ANALYZE 配置应保持一致。因此,如果你在 ANALYZE TABLE TableName PARTITION PartitionNameList 语句后指定了 COLUMNS 配置,或在 WITH 后指定了 OPTIONS 配置,TiDB 会忽略这些配置并返回警告。
提升收集性能
TiDB 提供两种方式提升统计信息收集性能:
- 只收集部分列的统计信息。参见 收集部分列的统计信息。
- 采样。
统计信息采样
采样可通过 ANALYZE 语句的两个选项实现,每个选项对应不同的收集算法:
WITH NUM SAMPLES指定采样集大小,在 TiDB 中实现为蓄水池采样法。当表较大时,不建议使用该方法收集统计信息。因为蓄水池采样的中间结果集包含冗余结果,会对内存等资源造成额外压力。WITH FLOAT_NUM SAMPLERATE是 v5.3.0 引入的采样方法,取值范围为(0, 1],指定采样率。在 TiDB 中实现为伯努利采样,更适合大表采样,在收集效率和资源使用上表现更好。
v5.3.0 之前,TiDB 使用蓄水池采样法收集统计信息。从 v5.3.0 起,TiDB 统计信息版本 2 默认使用伯努利采样法。若需继续使用蓄水池采样法,可使用 WITH NUM SAMPLES 语句。
当前采样率基于自适应算法计算。当你可以通过 SHOW STATS_META 观察到表的行数时,可以用该行数计算对应 100,000 行的采样率。如果无法观察到该行数,可以用 SHOW TABLE REGIONS 结果中 APPROXIMATE_KEYS 列的所有值之和作为参考,计算采样率。
收集统计信息的内存配额
自 TiDB v6.1.0 起,你可以使用系统变量 tidb_mem_quota_analyze 控制 TiDB 收集统计信息时的内存配额。
设置 tidb_mem_quota_analyze 的合适值时,需要考虑集群数据量。在使用默认采样率时,主要考虑列数、列值大小和 TiDB 的内存配置。配置最大值和最小值时可参考以下建议:
- 最小值:应大于 TiDB 收集列数最多的表时的最大内存使用量。大致参考:默认配置下,TiDB 收集 20 列的表时最大内存约 800 MiB;收集 160 列的表时最大内存约 5 GiB。
- 最大值:应小于 TiDB 未收集统计信息时的可用内存。
持久化 ANALYZE 配置
自 v5.4.0 起,TiDB 支持持久化部分 ANALYZE 配置。通过该特性,可以方便地复用现有配置进行后续统计信息收集。
支持持久化的 ANALYZE 配置如下:
| 配置项 | 对应 ANALYZE 语法 |
|---|---|
| 直方图桶数 | WITH NUM BUCKETS |
| Top-N 数量 | WITH NUM TOPN |
| 采样数 | WITH NUM SAMPLES |
| 采样率 | WITH FLOATNUM SAMPLERATE |
ANALYZE 列类型 | AnalyzeColumnOption ::= ( 'ALL COLUMNS' | 'PREDICATE COLUMNS' | 'COLUMNS' ColumnNameList ) |
ANALYZE 列 | ColumnNameList ::= Identifier ( ',' Identifier )* |
启用 ANALYZE 配置持久化
ANALYZE 配置持久化特性默认关闭。要启用该特性,请确保系统变量 tidb_persist_analyze_options 为 ON,并将系统变量 tidb_analyze_version 设置为 2。
你可以通过该特性,在手动执行 ANALYZE 语句时记录指定的持久化配置。记录后,下次 TiDB 自动更新统计信息或你手动收集统计信息时未指定这些配置,TiDB 会按照已记录的配置收集统计信息。
要查询某张表用于自动分析操作的持久化配置,可执行以下 SQL 语句:
SELECT sample_num, sample_rate, buckets, topn, column_choice, column_ids FROM mysql.analyze_options opt JOIN information_schema.tables tbl ON opt.table_id = tbl.tidb_table_id WHERE tbl.table_schema = '{db_name}' AND tbl.table_name = '{table_name}';
TiDB 会用最新一次 ANALYZE 语句指定的新配置覆盖之前记录的持久化配置。例如,执行 ANALYZE TABLE t WITH 200 TOPN;,会设置 ANALYZE 语句的 top 200 值。随后执行 ANALYZE TABLE t WITH 0.1 SAMPLERATE;,会同时设置 top 200 值和采样率 0.1,等价于 ANALYZE TABLE t WITH 200 TOPN, 0.1 SAMPLERATE;。
关闭 ANALYZE 配置持久化
要关闭 ANALYZE 配置持久化特性,将系统变量 tidb_persist_analyze_options 设置为 OFF。由于 ANALYZE 配置持久化特性不适用于 tidb_analyze_version = 1,将 tidb_analyze_version 设置为 1 也可关闭该特性。
关闭后,TiDB 不会清除已持久化的配置记录。因此,若再次启用该特性,TiDB 会继续使用之前记录的持久化配置收集统计信息。
持久化列配置
如果你希望持久化 ANALYZE 语句中的列配置(包括 COLUMNS ColumnNameList、PREDICATE COLUMNS 和 ALL COLUMNS),请将系统变量 tidb_persist_analyze_options 设置为 ON,以启用 ANALYZE 配置持久化 特性。启用后:
- 当 TiDB 自动收集统计信息,或你手动执行
ANALYZE语句但未指定列配置时,TiDB 会继续使用之前持久化的配置收集统计信息。 - 当你多次手动执行带有列配置的
ANALYZE语句时,TiDB 会用最新一次ANALYZE语句指定的新配置覆盖之前记录的持久化配置。
要定位 PREDICATE COLUMNS 及已收集统计信息的列,可使用 SHOW COLUMN_STATS_USAGE 语句。
如下示例,执行 ANALYZE TABLE t PREDICATE COLUMNS; 后,TiDB 会收集列 b、c 和 d 的统计信息,其中 b 为谓词列,c 和 d 为索引列。
CREATE TABLE t (a INT, b INT, c INT, d INT, INDEX idx_c_d(c, d));
Query OK, 0 rows affected (0.00 sec)
-- 优化器在本查询中会用到列 b 的统计信息。
SELECT * FROM t WHERE b > 1;
Empty set (0.00 sec)
-- 等待一段时间(100 * stats-lease)后,TiDB 会将收集到的 `PREDICATE COLUMNS` 写入 mysql.column_stats_usage。
-- 指定 `last_used_at IS NOT NULL` 可显示 TiDB 收集到的 `PREDICATE COLUMNS`。
SHOW COLUMN_STATS_USAGE
WHERE db_name = 'test' AND table_name = 't' AND last_used_at IS NOT NULL;
+---------+------------+----------------+-------------+---------------------+------------------+
| Db_name | Table_name | Partition_name | Column_name | Last_used_at | Last_analyzed_at |
+---------+------------+----------------+-------------+---------------------+------------------+
| test | t | | b | 2022-01-05 17:21:33 | NULL |
+---------+------------+----------------+-------------+---------------------+------------------+
1 row in set (0.00 sec)
ANALYZE TABLE t PREDICATE COLUMNS;
Query OK, 0 rows affected, 1 warning (0.03 sec)
-- 指定 `last_analyzed_at IS NOT NULL` 可显示已收集统计信息的列。
SHOW COLUMN_STATS_USAGE
WHERE db_name = 'test' AND table_name = 't' AND last_analyzed_at IS NOT NULL;
+---------+------------+----------------+-------------+---------------------+---------------------+
| Db_name | Table_name | Partition_name | Column_name | Last_used_at | Last_analyzed_at |
+---------+------------+----------------+-------------+---------------------+---------------------+
| test | t | | b | 2022-01-05 17:21:33 | 2022-01-05 17:23:06 |
| test | t | | c | NULL | 2022-01-05 17:23:06 |
| test | t | | d | NULL | 2022-01-05 17:23:06 |
+---------+------------+----------------+-------------+---------------------+---------------------+
3 rows in set (0.00 sec)
统计信息版本
tidb_analyze_version 变量控制 TiDB 收集的统计信息版本。目前支持两种版本:tidb_analyze_version = 1 和 tidb_analyze_version = 2。
- 对于 TiDB 自建版,从 v5.3.0 起该变量默认值由
1变为2。 - 对于 TiDB Cloud,从 v6.5.0 起该变量默认值由
1变为2。 - 如果你的集群由早期版本升级而来,升级后
tidb_analyze_version的默认值不会改变。
推荐使用版本 2,且后续会持续增强,最终完全替代版本 1。与版本 1 相比,版本 2 在大数据量下提升了统计信息的准确性,并通过移除 Count-Min Sketch 统计信息收集(用于谓词选择性估算)和支持仅收集部分列(参见 收集部分列的统计信息)提升了收集性能。
下表列出了每个版本为优化器估算收集的信息:
| 信息 | 版本 1 | 版本 2 |
|---|---|---|
| 表的总行数 | ⎷ | ⎷ |
| 等值/IN 谓词估算 | ⎷(列/索引 Top-N & Count-Min Sketch) | ⎷(列/索引 Top-N & 直方图) |
| 范围谓词估算 | ⎷(列/索引 Top-N & 直方图) | ⎷(列/索引 Top-N & 直方图) |
NULL 谓词估算 | ⎷ | ⎷ |
| 列的平均长度 | ⎷ | ⎷ |
| 索引的平均长度 | ⎷ | ⎷ |
切换统计信息版本
建议确保所有表/索引(及分区)使用同一版本的统计信息收集。推荐使用版本 2,但不建议无正当理由(如当前版本出现问题)随意切换。切换版本期间,若所有表尚未用新版本分析,可能会出现一段时间无统计信息,影响优化器的执行计划选择。
常见切换理由如:在版本 1 下,因收集 Count-Min Sketch 统计信息时哈希冲突,导致等值/IN 谓词估算不准确。解决方法见 Count-Min Sketch 一节。或者,将 tidb_analyze_version 设为 2 并对所有对象重新执行 ANALYZE 也是一种解决方案。早期版本 2 存在 ANALYZE 后内存溢出的风险,该问题已修复,最初的解决方法是将 tidb_analyze_version 设为 1 并对所有对象重新执行 ANALYZE。
切换版本前的 ANALYZE 准备:
若手动执行
ANALYZE语句,请手动分析所有需分析的表。SELECT DISTINCT(CONCAT('ANALYZE TABLE ', table_schema, '.', table_name, ';')) FROM information_schema.tables JOIN mysql.stats_histograms ON table_id = tidb_table_id WHERE stats_ver = 2;若 TiDB 自动执行
ANALYZE(已开启自动分析),可执行以下语句生成DROP STATS语句:SELECT DISTINCT(CONCAT('DROP STATS ', table_schema, '.', table_name, ';')) FROM information_schema.tables JOIN mysql.stats_histograms ON table_id = tidb_table_id WHERE stats_ver = 2;若上述语句结果过长无法复制粘贴,可将结果导出到临时文本文件,再从文件执行:
SELECT DISTINCT ... INTO OUTFILE '/tmp/sql.txt'; mysql -h ${TiDB_IP} -u user -P ${TIDB_PORT} ... < '/tmp/sql.txt'
查看统计信息
你可以通过以下语句查看 ANALYZE 状态和统计信息。
ANALYZE 状态
执行 ANALYZE 语句时,可通过 SHOW ANALYZE STATUS 查看当前 ANALYZE 状态。
自 TiDB v6.1.0 起,SHOW ANALYZE STATUS 支持显示集群级任务。即使 TiDB 重启后,仍可通过该语句查看重启前的任务记录。TiDB v6.1.0 之前,SHOW ANALYZE STATUS 仅能显示实例级任务,且重启后任务记录会被清空。
SHOW ANALYZE STATUS 仅显示最近的任务记录。自 TiDB v6.1.0 起,你可以通过系统表 mysql.analyze_jobs 查看最近 7 天的历史任务。
当设置了 tidb_mem_quota_analyze,且后台自动 ANALYZE 任务使用内存超出阈值时,任务会被重试。你可以在 SHOW ANALYZE STATUS 输出中看到失败和重试的任务。
当 tidb_max_auto_analyze_time 大于 0,且后台自动 ANALYZE 任务执行时间超出阈值时,任务会被终止。
mysql> SHOW ANALYZE STATUS [ShowLikeOrWhere];
+--------------+------------+----------------+-------------------------------------------------------------------------------------------+----------------+---------------------+---------------------+----------+-------------------------------------------------------------------------------|
| Table_schema | Table_name | Partition_name | Job_info | Processed_rows | Start_time | End_time | State | Fail_reason |
+--------------+------------+----------------+-------------------------------------------------------------------------------------------+----------------+---------------------+---------------------+----------+-------------------------------------------------------------------------------|
| test | sbtest1 | | retry auto analyze table all columns with 100 topn, 0.055 samplerate | 2000000 | 2022-05-07 16:41:09 | 2022-05-07 16:41:20 | finished | NULL |
| test | sbtest1 | | auto analyze table all columns with 100 topn, 0.5 samplerate | 0 | 2022-05-07 16:40:50 | 2022-05-07 16:41:09 | failed | analyze panic due to memory quota exceeds, please try with smaller samplerate |
表的元数据
你可以使用 SHOW STATS_META 语句查看总行数和已更新行数。
表的健康状态
你可以使用 SHOW STATS_HEALTHY 语句检查表的健康状态,并大致估算统计信息的准确性。当 modify_count >= row_count 时,健康度为 0;当 modify_count < row_count 时,健康度为 (1 - modify_count/row_count) * 100。
列的元数据
你可以使用 SHOW STATS_HISTOGRAMS 语句查看所有列的不同值个数和 NULL 个数。
直方图的桶
你可以使用 SHOW STATS_BUCKETS 语句查看直方图的每个桶。
Top-N 信息
你可以使用 SHOW STATS_TOPN 语句查看 TiDB 当前收集到的 Top-N 信息。
删除统计信息
你可以通过 DROP STATS 语句删除统计信息。
加载统计信息
默认情况下,TiDB 会根据列统计信息的大小采用不同的加载方式:
- 对于占用内存较小的统计信息(如 count、distinctCount 和 nullCount),只要列数据有更新,TiDB 会自动将对应统计信息加载到内存中,供 SQL 优化阶段使用。
- 对于占用内存较大的统计信息(如直方图、TopN 和 Count-Min Sketch),为保证 SQL 执行性能,TiDB 会按需异步加载这些统计信息。例如,直方图统计信息只有在优化器需要使用某列的直方图时才会加载到内存。按需异步加载不会影响 SQL 执行性能,但可能导致 SQL 优化时统计信息不完整。
自 v5.4.0 起,TiDB 引入了同步加载统计信息特性。该特性允许 TiDB 在执行 SQL 语句时同步将大体积统计信息(如直方图、TopN 和 Count-Min Sketch)加载到内存,从而提升 SQL 优化时统计信息的完整性。
要启用该特性,请将 tidb_stats_load_sync_wait 系统变量设置为 SQL 优化可等待同步加载完整列统计信息的超时时间(单位:毫秒)。该变量默认值为 100,表示已启用该特性。
启用同步加载统计信息特性后,你可以通过修改 tidb_stats_load_pseudo_timeout 系统变量控制 SQL 优化等待超时后的行为。该变量默认值为 ON,表示超时后 SQL 优化过程不会使用任何列的直方图、TopN 或 CMSketch 统计信息。若设为 OFF,超时后 SQL 执行失败。
导出与导入统计信息
本节介绍如何导出和导入统计信息。
导出统计信息
导出统计信息的接口如下:
获取
${db_name}数据库中${table_name}表的 JSON 格式统计信息:http://${tidb-server-ip}:${tidb-server-status-port}/stats/dump/${db_name}/${table_name}例如:
curl -s http://127.0.0.1:10080/stats/dump/test/t1 -o /tmp/t1.json获取
${db_name}数据库中${table_name}表在指定时间点的 JSON 格式统计信息:http://${tidb-server-ip}:${tidb-server-status-port}/stats/dump/${db_name}/${table_name}/${yyyyMMddHHmmss}
导入统计信息
通常,导入的统计信息指的是通过导出接口获得的 JSON 文件。
加载统计信息可通过 LOAD STATS 语句完成。
例如:
LOAD STATS 'file_name';
file_name 为要导入的统计信息文件名。
锁定统计信息
自 v6.5.0 起,TiDB 支持锁定统计信息。表或分区的统计信息被锁定后,无法修改该表的统计信息,也无法对该表执行 ANALYZE 语句。例如:
创建表 t 并插入数据。当表 t 的统计信息未被锁定时,可以成功执行 ANALYZE 语句。
mysql> CREATE TABLE t(a INT, b INT);
Query OK, 0 rows affected (0.03 sec)
mysql> INSERT INTO t VALUES (1,2), (3,4), (5,6), (7,8);
Query OK, 4 rows affected (0.00 sec)
Records: 4 Duplicates: 0 Warnings: 0
mysql> ANALYZE TABLE t;
Query OK, 0 rows affected, 1 warning (0.02 sec)
mysql> SHOW WARNINGS;
+-------+------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Level | Code | Message |
+-------+------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Note | 1105 | Analyze use auto adjusted sample rate 1.000000 for table test.t, reason to use this rate is "Row count in stats_meta is much smaller compared with the row count got by PD, use min(1, 15000/4) as the sample-rate=1" |
+-------+------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
锁定表 t 的统计信息后执行 ANALYZE,警告信息显示 ANALYZE 语句已跳过表 t。
mysql> LOCK STATS t;
Query OK, 0 rows affected (0.00 sec)
mysql> SHOW STATS_LOCKED;
+---------+------------+----------------+--------+
| Db_name | Table_name | Partition_name | Status |
+---------+------------+----------------+--------+
| test | t | | locked |
+---------+------------+----------------+--------+
1 row in set (0.01 sec)
mysql> ANALYZE TABLE t;
Query OK, 0 rows affected, 2 warnings (0.00 sec)
mysql> SHOW WARNINGS;
+---------+------+-----------------------------------------------------------------------------------------------------------------------------------------+
| Level | Code | Message |
+---------+------+-----------------------------------------------------------------------------------------------------------------------------------------+
| Note | 1105 | Analyze use auto adjusted sample rate 1.000000 for table test.t, reason to use this rate is "use min(1, 110000/8) as the sample-rate=1" |
| Warning | 1105 | skip analyze locked table: test.t |
+---------+------+-----------------------------------------------------------------------------------------------------------------------------------------+
2 rows in set (0.00 sec)
解锁表 t 的统计信息后,可以再次成功执行 ANALYZE。
mysql> UNLOCK STATS t;
Query OK, 0 rows affected (0.01 sec)
mysql> ANALYZE TABLE t;
Query OK, 0 rows affected, 1 warning (0.03 sec)
mysql> SHOW WARNINGS;
+-------+------+-----------------------------------------------------------------------------------------------------------------------------------------+
| Level | Code | Message |
+-------+------+-----------------------------------------------------------------------------------------------------------------------------------------+
| Note | 1105 | Analyze use auto adjusted sample rate 1.000000 for table test.t, reason to use this rate is "use min(1, 110000/8) as the sample-rate=1" |
+-------+------+-----------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
此外,你还可以通过 LOCK STATS 锁定分区的统计信息。例如:
创建分区表 t 并插入数据。当分区 p1 的统计信息未被锁定时,可以成功执行 ANALYZE 语句。
mysql> CREATE TABLE t(a INT, b INT) PARTITION BY RANGE (a) (PARTITION p0 VALUES LESS THAN (10), PARTITION p1 VALUES LESS THAN (20), PARTITION p2 VALUES LESS THAN (30));
Query OK, 0 rows affected (0.03 sec)
mysql> INSERT INTO t VALUES (1,2), (3,4), (5,6), (7,8);
Query OK, 4 rows affected (0.00 sec)
Records: 4 Duplicates: 0 Warnings: 0
mysql> ANALYZE TABLE t;
Query OK, 0 rows affected, 6 warning (0.02 sec)
mysql> SHOW WARNINGS;
+---------+------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Level | Code | Message |
+---------+------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Warning | 1105 | disable dynamic pruning due to t has no global stats |
| Note | 1105 | Analyze use auto adjusted sample rate 1.000000 for table test.t's partition p0, reason to use this rate is "Row count in stats_meta is much smaller compared with the row count got by PD, use min(1, 15000/4) as the sample-rate=1" |
| Warning | 1105 | disable dynamic pruning due to t has no global stats |
| Note | 1105 | Analyze use auto adjusted sample rate 1.000000 for table test.t's partition p1, reason to use this rate is "TiDB assumes that the table is empty, use sample-rate=1" |
| Warning | 1105 | disable dynamic pruning due to t has no global stats |
| Note | 1105 | Analyze use auto adjusted sample rate 1.000000 for table test.t's partition p2, reason to use this rate is "TiDB assumes that the table is empty, use sample-rate=1" |
+---------+------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
6 rows in set (0.01 sec)
锁定分区 p1 的统计信息后执行 ANALYZE,警告信息显示 ANALYZE 语句已跳过分区 p1。
mysql> LOCK STATS t PARTITION p1;
Query OK, 0 rows affected (0.00 sec)
mysql> SHOW STATS_LOCKED;
+---------+------------+----------------+--------+
| Db_name | Table_name | Partition_name | Status |
+---------+------------+----------------+--------+
| test | t | p1 | locked |
+---------+------------+----------------+--------+
1 row in set (0.00 sec)
mysql> ANALYZE TABLE t PARTITION p1;
Query OK, 0 rows affected, 2 warnings (0.01 sec)
mysql> SHOW WARNINGS;
+---------+------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Level | Code | Message |
+---------+------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Note | 1105 | Analyze use auto adjusted sample rate 1.000000 for table test.t's partition p1, reason to use this rate is "TiDB assumes that the table is empty, use sample-rate=1" |
| Warning | 1105 | skip analyze locked table: test.t partition (p1) |
+---------+------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------+
2 rows in set (0.00 sec)
解锁分区 p1 的统计信息后,可以再次成功执行 ANALYZE。
mysql> UNLOCK STATS t PARTITION p1;
Query OK, 0 rows affected (0.00 sec)
mysql> ANALYZE TABLE t PARTITION p1;
Query OK, 0 rows affected, 1 warning (0.01 sec)
mysql> SHOW WARNINGS;
+-------+------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Level | Code | Message |
+-------+------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Note | 1105 | Analyze use auto adjusted sample rate 1.000000 for table test.t's partition p1, reason to use this rate is "TiDB assumes that the table is empty, use sample-rate=1" |
+-------+------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
锁定统计信息的行为
- 如果你锁定了分区表的统计信息,则该分区表所有分区的统计信息都会被锁定。
- 如果你截断表或分区,则该表或分区的统计信息锁会被释放。
下表描述了锁定统计信息的行为:
| 删除整张表 | 截断整张表 | 截断分区 | 新建分区 | 删除分区 | 重组分区 | 交换分区 | |
|---|---|---|---|---|---|---|---|
| 非分区表被锁定 | 锁失效 | 锁失效,因 TiDB 删除旧表,锁信息也被删除 | / | / | / | / | / |
| 分区表且整表被锁定 | 锁失效 | 锁失效,因 TiDB 删除旧表,锁信息也被删除 | 旧分区锁信息失效,新分区自动加锁 | 新分区自动加锁 | 被删除分区锁信息清除,整表锁继续生效 | 被删除分区锁信息清除,新分区自动加锁 | 锁信息转移到被交换表,新分区自动加锁 |
| 分区表且仅部分分区被锁定 | 锁失效 | 锁失效,因 TiDB 删除旧表,锁信息也被删除 | 锁失效,因 TiDB 删除旧表,锁信息也被删除 | / | 被删除分区锁信息清除 | 被删除分区锁信息清除 | 锁信息转移到被交换表 |
管理 ANALYZE 任务与并发度
本节介绍如何终止后台 ANALYZE 任务及控制 ANALYZE 并发度。
终止后台 ANALYZE 任务
自 TiDB v6.0 起,TiDB 支持使用 KILL 语句终止后台运行的 ANALYZE 任务。如果你发现后台 ANALYZE 任务消耗大量资源影响业务,可以按以下步骤终止该任务:
执行以下 SQL 语句:
SHOW ANALYZE STATUS通过结果中的
instance列和process_id列,可以获取后台ANALYZE任务所在 TiDB 实例地址及任务ID。终止正在后台运行的
ANALYZE任务。要终止
ANALYZE任务,可执行KILL TIDB ${id};,其中${id}为上一步获取的后台ANALYZE任务ID。
更多关于 KILL 语句的信息,参见 KILL。
控制 ANALYZE 并发度
执行 ANALYZE 语句时,你可以通过系统变量调整并发度,以控制其对系统的影响。
相关系统变量的关系如下图所示:

tidb_build_stats_concurrency、tidb_build_sampling_stats_concurrency 和 tidb_analyze_partition_concurrency 之间为上下游关系,如上图所示。实际总并发度为:tidb_build_stats_concurrency * (tidb_build_sampling_stats_concurrency + tidb_analyze_partition_concurrency)。修改这些变量时需同时考虑各自的取值。建议按 tidb_analyze_partition_concurrency、tidb_build_sampling_stats_concurrency、tidb_build_stats_concurrency 的顺序逐一调整,并观察对系统的影响。三者值越大,对系统资源消耗越大。
tidb_build_stats_concurrency
执行 ANALYZE 语句时,任务会被拆分为多个小任务,每个小任务只处理一个列或索引的统计信息。你可以通过 tidb_build_stats_concurrency 变量控制同时运行的小任务数。默认值为 2。v7.4.0 及更早版本默认值为 4。
tidb_build_sampling_stats_concurrency
分析普通列时,可以通过 tidb_build_sampling_stats_concurrency 控制采样任务的并发度。默认值为 2。
tidb_analyze_partition_concurrency
执行 ANALYZE 语句时,可以通过 tidb_analyze_partition_concurrency 控制分区表读写统计信息的并发度。默认值为 2。v7.4.0 及更早版本默认值为 1。
tidb_distsql_scan_concurrency
分析普通列时,可以通过 tidb_distsql_scan_concurrency 变量控制一次读取的 Region 数。默认值为 15。注意,修改该值会影响查询性能,请谨慎调整。
tidb_index_serial_scan_concurrency
分析索引列时,可以通过 tidb_index_serial_scan_concurrency 变量控制一次读取的 Region 数。默认值为 1。注意,修改该值会影响查询性能,请谨慎调整。