Sink to Cloud Storage
本文档描述如何创建 changefeed,将数据从 TiDB Cloud 流式同步到云存储。目前支持 Amazon S3、Google Cloud Storage (GCS) 和 Azure Blob Storage。
限制
- 每个 TiDB Cloud 集群最多可创建 100 个 changefeed。
- 由于 TiDB Cloud 使用 TiCDC 建立 changefeed,因此具有与 TiCDC 相同的限制。
- 如果待同步的表没有主键或非空唯一索引,则在某些重试场景下,由于同步过程中缺乏唯一约束,可能会导致下游插入重复数据。
步骤 1. 配置目标端
进入目标 TiDB 集群的集群总览页面。在左侧导航栏点击 Data > Changefeed,点击 Create Changefeed 进入 Destination 页面,然后根据集群所在云服务商选择 Amazon S3、GCS 或 Azure Blob Storage 作为目标端。不同目标端的配置流程有所不同。
对于 Amazon S3,你可以选择使用 AWS Role ARN 或 AWS access key 进行认证。推荐使用 AWS Role ARN,以获得更强的安全性和更便捷的管理。
选项 1:AWS Role ARN(推荐)
如需使用 IAM Role 进行认证,请按以下步骤操作:
在 Amazon S3 的 Destination 页面,填写 S3 URI。确保 S3 bucket 与 TiDB 集群处于同一 AWS 区域。
在 Bucket Access 下选择 AWS Role ARN。
若需创建新的 Role ARN,点击 Click here to create new one with AWS CloudFormation。该模板会自动配置所需权限。
如果你希望手动创建角色,请点击 Create Role ARN manually 查看 TiDB Cloud 账户信息及所需策略。
确保你的 IAM 角色对目标 bucket 至少拥有以下权限:
s3:ListBuckets3:PutObjects3:GetObjects3:DeleteObject
将生成的 Role ARN 粘贴到对应输入框中。
选项 2:AWS access key
如需使用 access key 认证,请按以下步骤操作:
在 Amazon S3 的 Destination 页面,填写 S3 URI。确保 S3 bucket 与 TiDB 集群处于同一 AWS 区域。
在 Bucket Access 下选择 AWS Access Key。
填写以下内容:
- Access Key ID
- Secret Access Key
对于 GCS,在填写 GCS Endpoint 前,需要先授予 GCS bucket 访问权限。请按以下步骤操作:
在 TiDB Cloud 控制台记录 Service Account ID,用于授权 TiDB Cloud 访问你的 GCS bucket。
在 Google Cloud 控制台为你的 GCS bucket 创建 IAM 角色。
登录 Google Cloud 控制台。
进入 Roles 页面,点击 Create role。
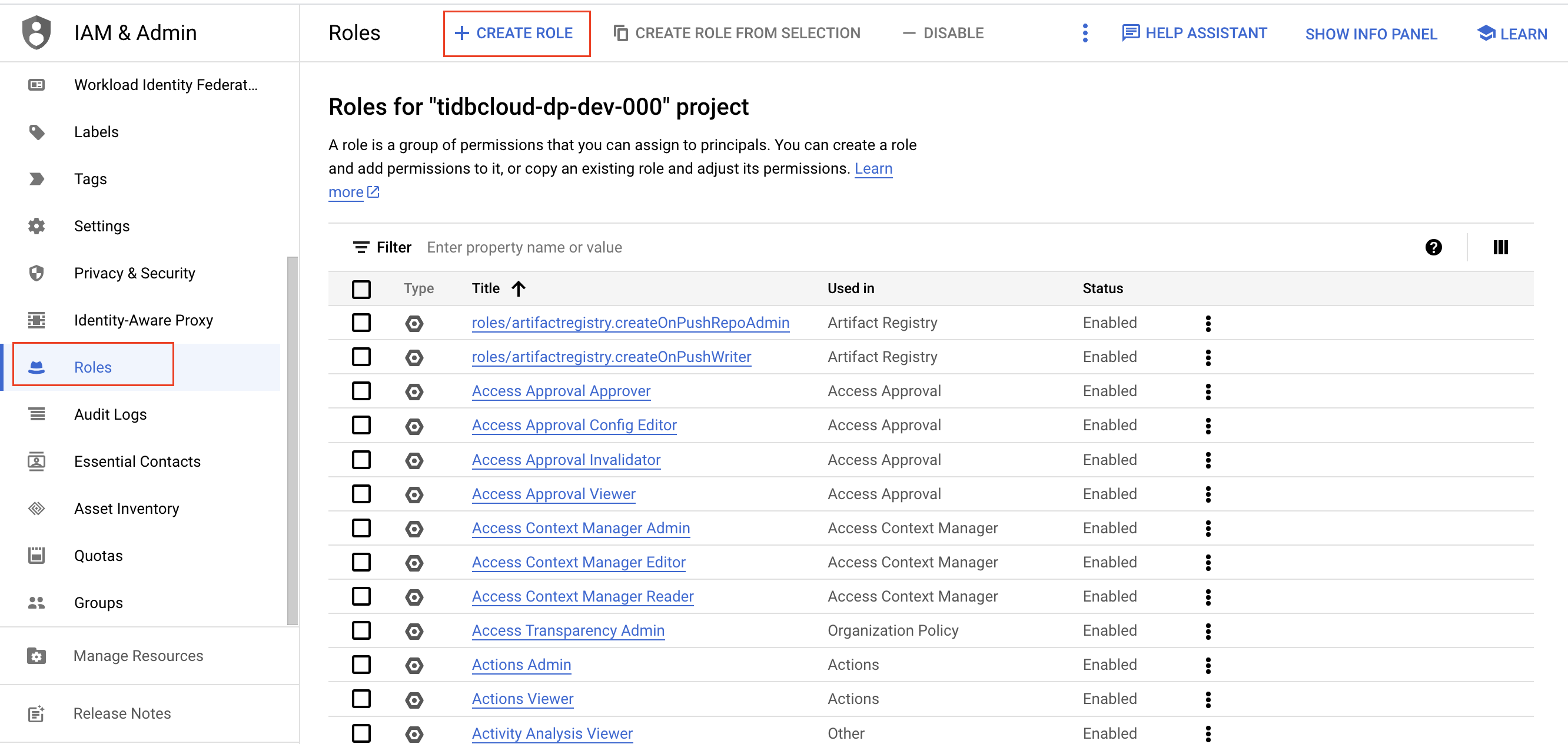
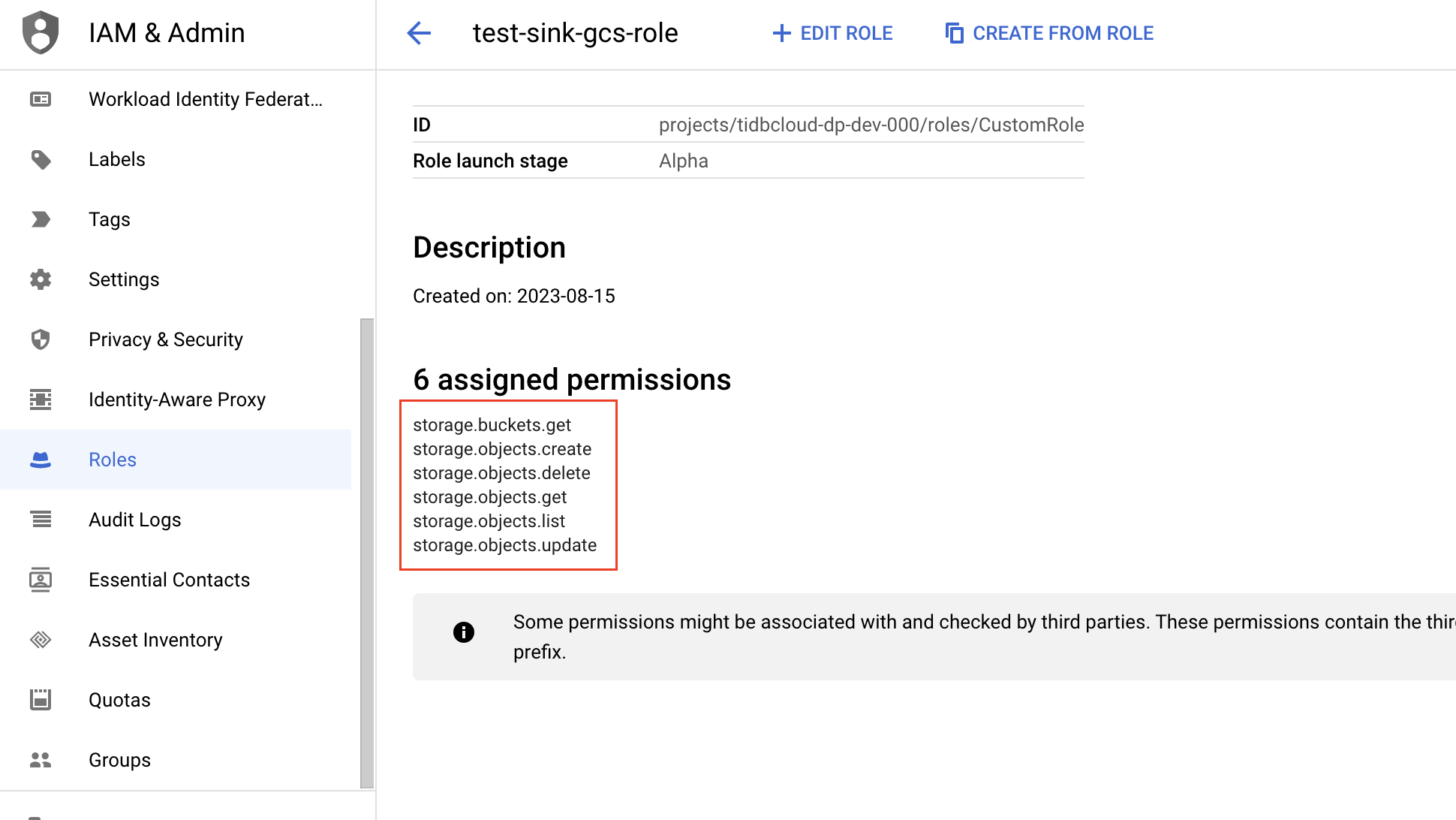
输入角色名称、描述、ID 及角色发布阶段。角色创建后名称不可更改。
点击 Add permissions,为角色添加以下权限,然后点击 Add。
- storage.buckets.get
- storage.objects.create
- storage.objects.delete
- storage.objects.get
- storage.objects.list
- storage.objects.update
进入 Bucket 页面,选择你希望 TiDB Cloud 访问的 GCS bucket。注意,GCS bucket 必须与 TiDB 集群处于同一区域。
在 Bucket details 页面,点击 Permissions 标签页,然后点击 Grant access。
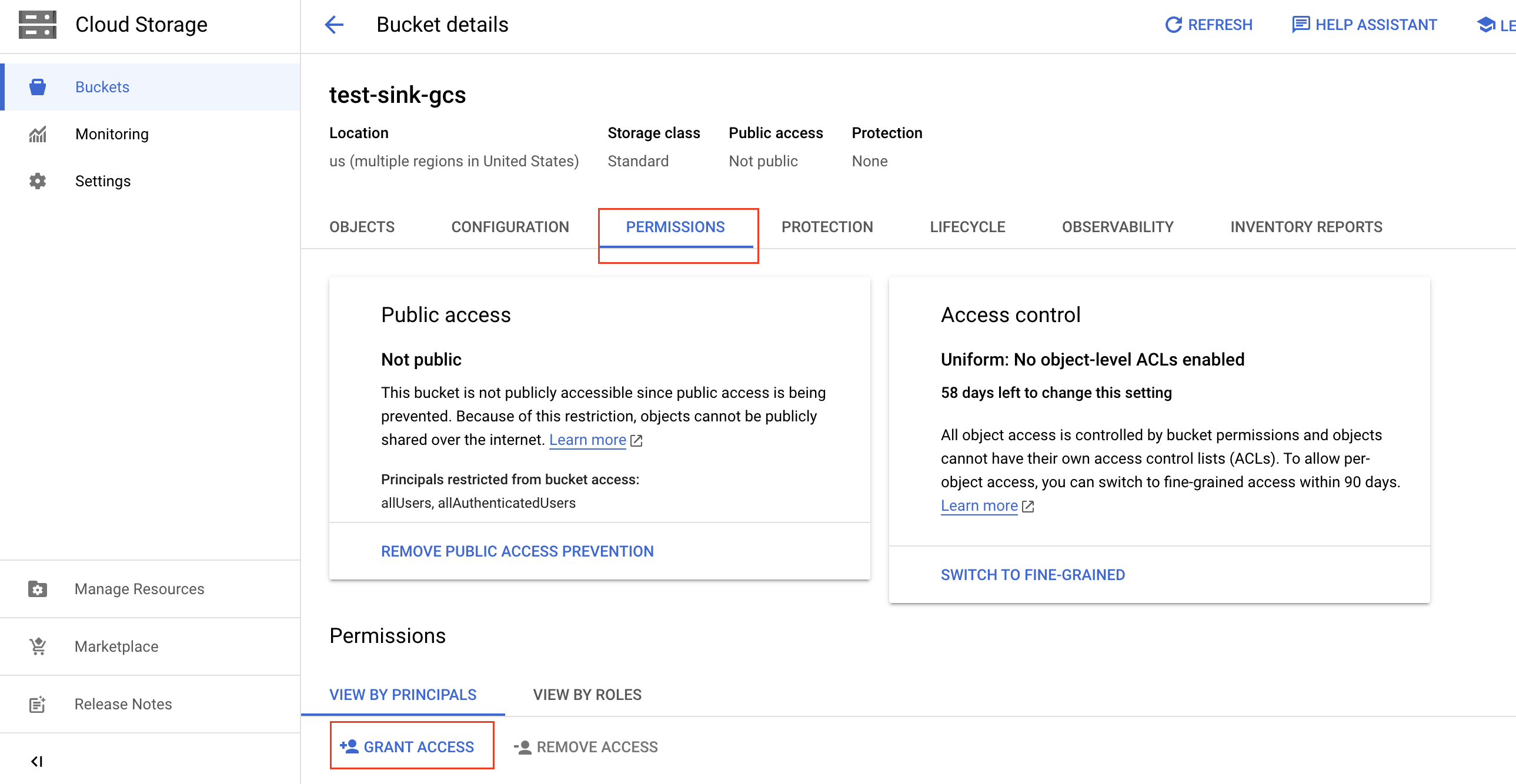
填写以下信息以授予 bucket 访问权限,然后点击 Save。
- 在 New Principals 输入框中,粘贴之前记录的目标 TiDB 集群的 Service Account ID。
- 在 Select a role 下拉列表中,输入刚刚创建的 IAM 角色名称,并从筛选结果中选择该名称。
在 Bucket details 页面,点击 Objects 标签页。
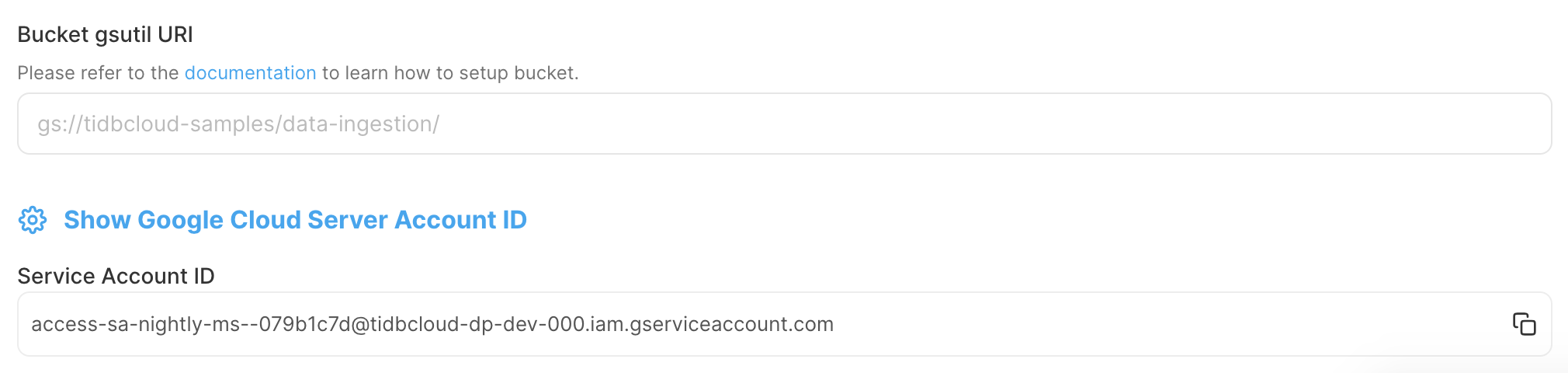
获取 bucket 的 gsutil URI:点击复制按钮,并在前面加上
gs://前缀。例如,bucket 名为test-sink-gcs,则 URI 为gs://test-sink-gcs/。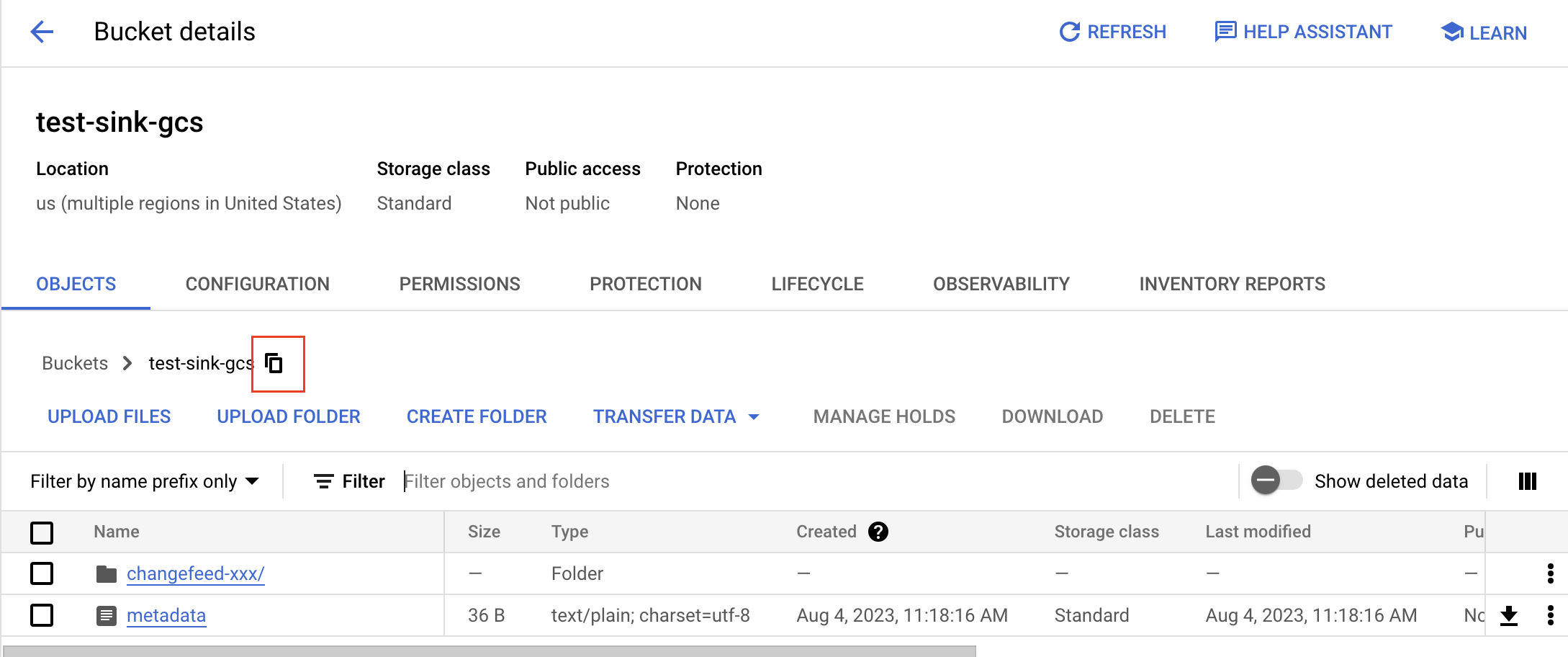
获取文件夹的 gsutil URI:进入文件夹,点击复制按钮,并在前面加上
gs://前缀。例如,bucket 名为test-sink-gcs,文件夹名为changefeed-xxx,则 URI 为gs://test-sink-gcs/changefeed-xxx/。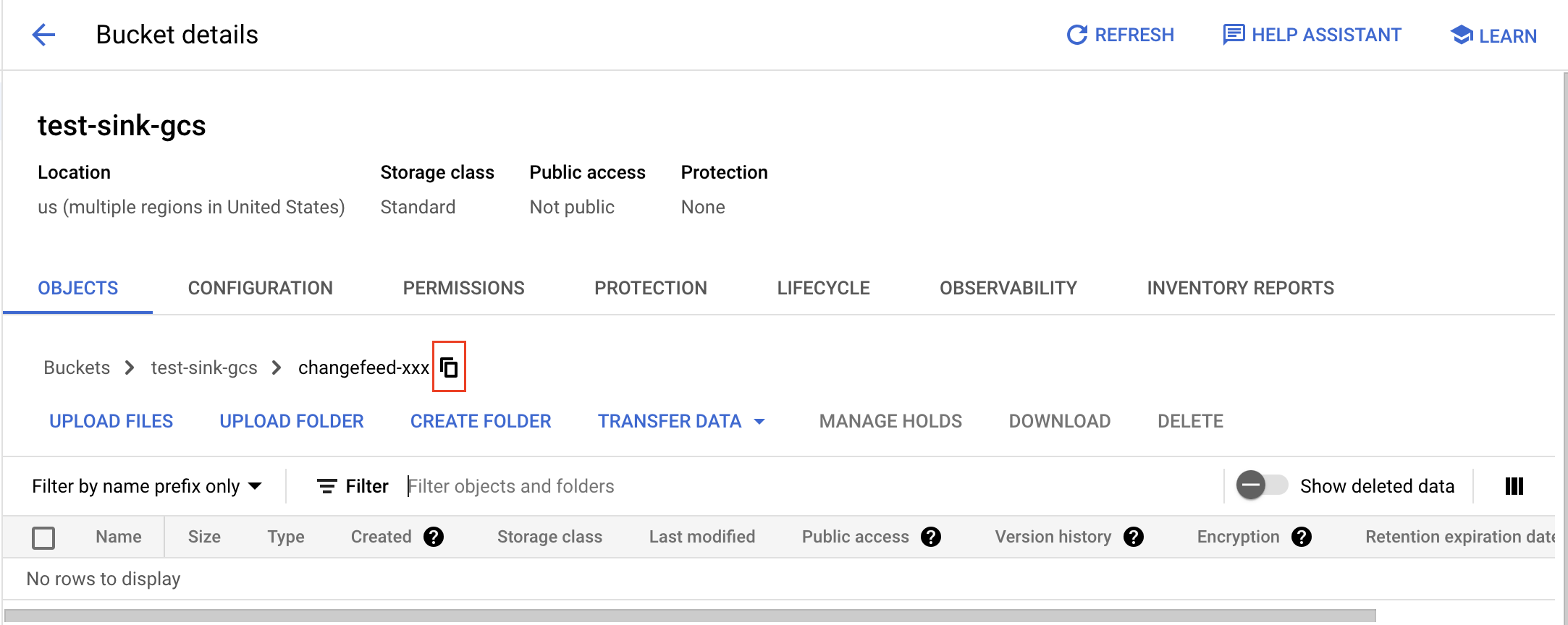
在 TiDB Cloud 控制台,进入 Changefeed 的 Destination 页面,在 bucket gsutil URI 输入框中填写 URI。
对于 Azure Blob Storage,你需要先在 Azure 门户配置容器并获取 SAS token。请按以下步骤操作:
在 Azure 门户 创建用于存储 changefeed 数据的容器。
- 在左侧导航栏点击 Storage Accounts,选择你的存储账户。
- 在存储账户导航菜单中,选择 Data storage > Containers,然后点击 + Container。
- 输入新容器名称,设置匿名访问级别(推荐选择 Private),然后点击 Create。
获取目标容器的 URL。
- 在容器列表中,选择目标容器。
- 点击容器的 ...,选择 Container properties。
- 保存 URL,例如
https://<storage_account>.blob.core.windows.net/<container>,以备后用。
生成 SAS token。
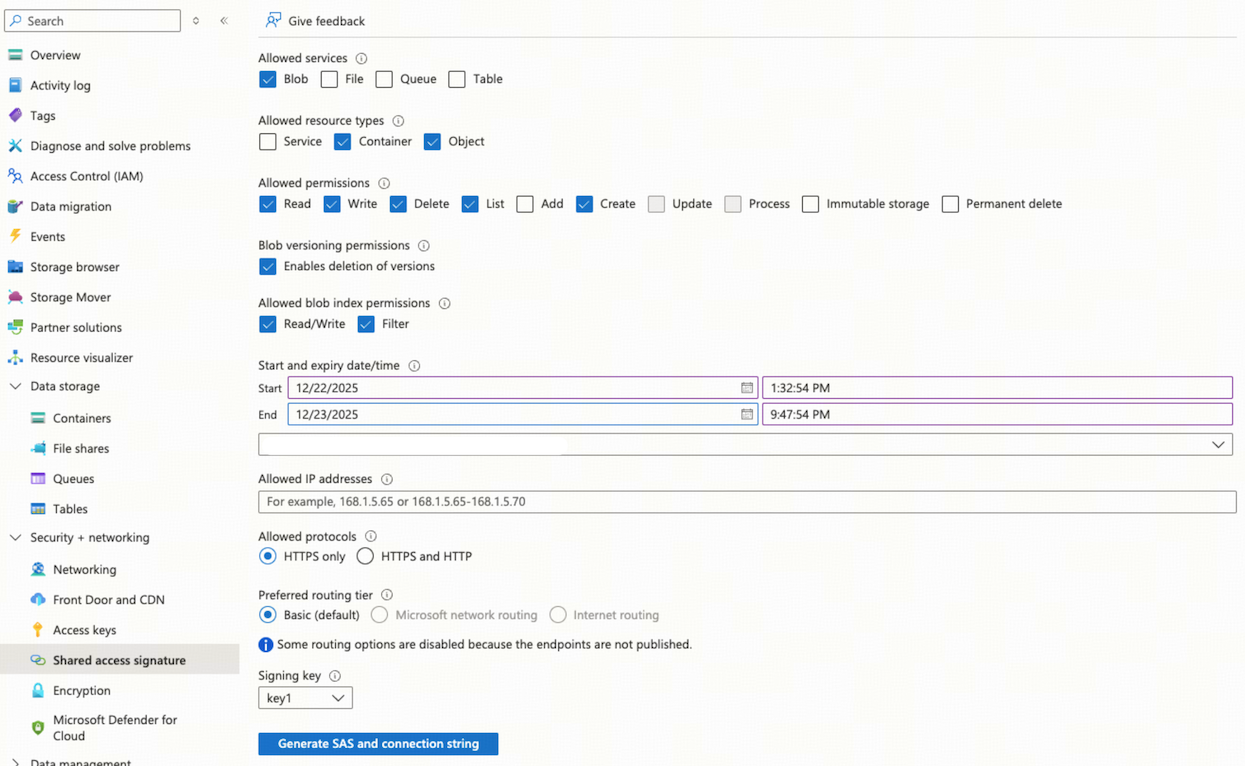
在存储账户导航菜单中,选择 Security + networking > Shared access signature。
在 Allowed services 区域选择 Blob。
在 Allowed resource types 区域选择 Container 和 Object。
在 Allowed permissions 区域选择 Read、Write、Delete、List 和 Create。
指定一个足够长的 SAS token 有效期,以满足你的需求。
点击 Generate SAS and connection string,保存 SAS token。
在 TiDB Cloud 控制台,进入 Changefeed 的 Destination 页面,填写以下内容:
- Blob URL:输入第 2 步获取的容器 URL,可选添加前缀。
- SAS Token:输入第 3 步获取的 SAS token。
点击 Next,建立 TiDB Cloud Dedicated 集群与 Amazon S3、GCS 或 Azure Blob Storage 的连接。TiDB Cloud 会自动测试并验证连接是否成功。
- 若连接成功,将进入下一步配置。
- 若连接失败,会显示连接错误,你需要处理该错误。错误解决后,点击 Next 重试连接。
步骤 2. 配置同步
自定义 Table Filter,筛选你希望同步的表。规则语法详见 table filter rules。
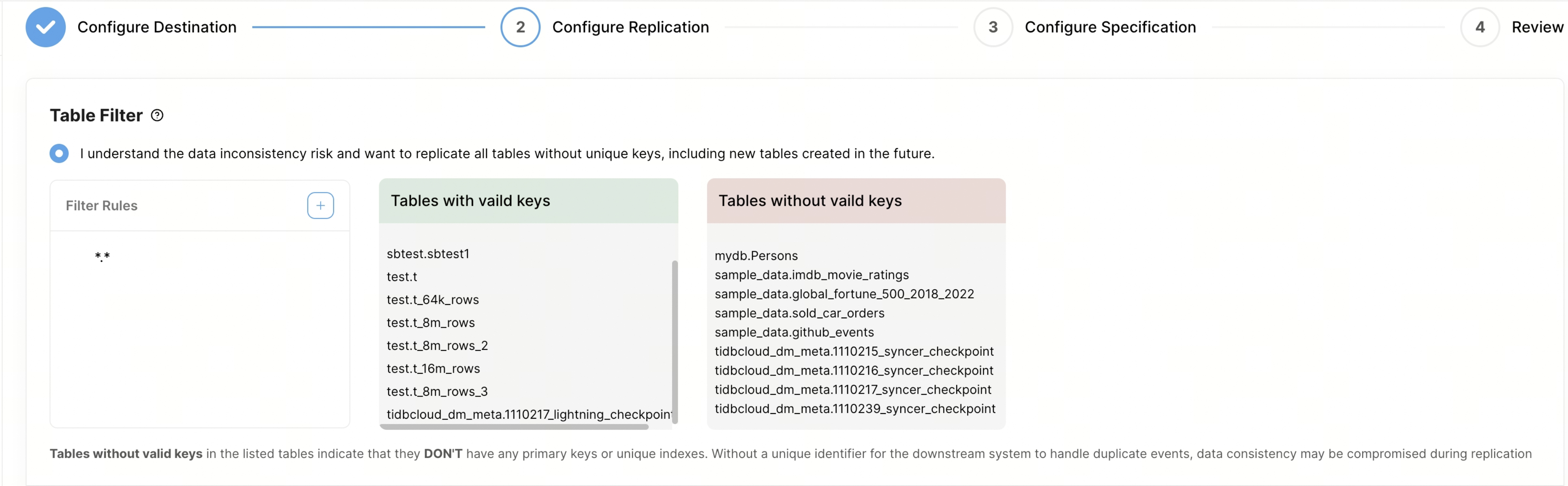
- Case Sensitive:你可以设置过滤规则中数据库和表名的匹配是否大小写敏感。默认情况下,匹配不区分大小写。
- Filter Rules:你可以在此列设置过滤规则。默认有一条规则
*.*,表示同步所有表。添加新规则后,TiDB Cloud 会查询 TiDB 中所有表,并仅在右侧框中显示符合规则的表。最多可添加 100 条过滤规则。 - Tables with valid keys:此列显示具有有效键(包括主键或唯一索引)的表。
- Tables without valid keys:此列显示缺少主键或唯一键的表。这些表在同步时存在挑战,因为缺乏唯一标识符,处理下游重复事件时可能导致数据不一致。为保证数据一致性,建议在同步前为这些表添加唯一键或主键,或通过过滤规则排除这些表。例如,可通过规则
"!test.tbl1"排除表test.tbl1。
自定义 Event Filter,筛选你希望同步的事件。
- Tables matching:你可以设置事件过滤器应用于哪些表。规则语法与前述 Table Filter 区域相同。每个 changefeed 最多可添加 10 条事件过滤规则。
- Event Filter:你可以使用以下事件过滤器排除特定事件类型:
- Ignore event:排除指定事件类型。
- Ignore SQL:排除符合指定表达式的 DDL 事件。例如,
^drop排除以DROP开头的语句,add column排除包含ADD COLUMN的语句。 - Ignore insert value expression:排除满足特定条件的
INSERT语句。例如,id >= 100排除id大于等于 100 的INSERT语句。 - Ignore update new value expression:排除新值满足指定条件的
UPDATE语句。例如,gender = 'male'排除将gender修改为male的更新。 - Ignore update old value expression:排除旧值满足指定条件的
UPDATE语句。例如,age < 18排除旧值age小于 18 的更新。 - Ignore delete value expression:排除满足指定条件的
DELETE语句。例如,name = 'john'排除name为'john'的删除。
在 Start Replication Position 区域,选择以下同步起始位置之一:
- 从现在开始同步
- 从指定的 TSO 开始同步
- 从指定时间开始同步
在 Data Format 区域,选择 CSV 或 Canal-JSON 格式。
配置 CSV 格式时,需填写以下内容:
- Binary Encode Method:二进制数据的编码方式。可选择 base64(默认)或 hex。如需与 AWS DMS 集成,建议选择 hex。
- Date Separator:按年、月、日轮转数据,或选择不轮转。
- Delimiter:指定 CSV 文件中用于分隔值的字符。逗号(
,)是最常用的分隔符。 - Quote:指定用于包裹包含分隔符或特殊字符值的字符。通常使用双引号(
")作为引用字符。 - Null/Empty Values:指定 CSV 文件中空值或空字符串的表示方式。这对于正确处理和解析数据非常重要。
- Include Commit Ts:控制是否在 CSV 行中包含
commit-ts。
Canal-JSON 是一种纯 JSON 文本格式。配置时需填写以下内容:
- Date Separator:按年、月、日轮转数据,或选择不轮转。
- Enable TiDB Extension:启用后,TiCDC 会发送 WATERMARK 事件 并在 Canal-JSON 消息中添加 TiDB 扩展字段。
在 Flush Parameters 区域,你可以配置以下两项:
- Flush Interval:默认 60 秒,可在 2 秒至 10 分钟范围内调整;
- File Size:默认 64 MB,可在 1 MB 至 512 MB 范围内调整。

在 Split Event 区域,选择是否将
UPDATE事件切分为独立的DELETE和INSERT事件,或保留为原始UPDATE事件。详情参见 Split primary or unique key UPDATE events for non-MySQL sinks。
步骤 3. 配置规范
点击 Next 配置 changefeed 规范。
- 在 Changefeed Specification 区域,指定 changefeed 使用的 Replication Capacity Units(RCU)数量。
- 在 Changefeed Name 区域,指定 changefeed 的名称。
步骤 4. 审核配置并启动同步
点击 Next 审核 changefeed 配置。
- 若确认所有配置无误,点击 Create 继续创建 changefeed。
- 若需修改配置,点击 Previous 返回并进行相应调整。
sink 很快会启动,你会看到 sink 状态从 Creating 变为 Running。
点击 changefeed 名称可进入详情页面。在该页面,你可以查看更多 changefeed 信息,包括 checkpoint 状态、同步延时及其他相关统计/指标(信息)。