TiDB 锁冲突问题处理
TiDB 支持完整的分布式事务,自 v3.0 版本起,提供乐观事务与悲观事务两种事务模式。本文介绍如何使用 Lock View 排查锁相关的问题,以及如何处理使用乐观事务或者悲观事务的过程中常见的锁冲突问题。
使用 Lock View 排查锁相关的问题
自 v5.1 版本起,TiDB 支持 Lock View 功能。该功能在 information_schema 中内置了若干系统表,用于提供更多关于锁冲突和锁等待的信息。
关于这些系统表的详细说明,请参考以下文档:
TIDB_TRX与CLUSTER_TIDB_TRX:提供当前 TiDB 节点上或整个集群上所有运行中的事务的信息,包括事务是否处于等锁状态、等锁时间和事务曾经执行过的语句的 Digest 等信息。DATA_LOCK_WAITS:提供关于 TiKV 内的悲观锁等锁信息,包括阻塞和被阻塞的事务的start_ts、被阻塞的 SQL 语句的 Digest 和发生等待的 key。DEADLOCKS与CLUSTER_DEADLOCKS:提供当前 TiDB 节点上或整个集群上最近发生过的若干次死锁的相关信息,包括死锁环中事务之间的等待关系、事务当前正在执行的语句的 Digest 和发生等待的 key。
以下为排查部分问题的示例。
死锁错误
要获取最近发生的死锁错误的信息,可查询 DEADLOCKS 或 CLUSTER_DEADLOCKS 表。
以查询 DEADLOCKS 表为例,请执行以下 SQL 语句:
select * from information_schema.deadlocks;
示例输出:
+-------------+----------------------------+-----------+--------------------+------------------------------------------------------------------+-----------------------------------------+----------------------------------------+----------------------------------------------------------------------------------------------------+--------------------+
| DEADLOCK_ID | OCCUR_TIME | RETRYABLE | TRY_LOCK_TRX_ID | CURRENT_SQL_DIGEST | CURRENT_SQL_DIGEST_TEXT | KEY | KEY_INFO | TRX_HOLDING_LOCK |
+-------------+----------------------------+-----------+--------------------+------------------------------------------------------------------+-----------------------------------------+----------------------------------------+----------------------------------------------------------------------------------------------------+--------------------+
| 1 | 2021-08-05 11:09:03.230341 | 0 | 426812829645406216 | 22230766411edb40f27a68dadefc63c6c6970d5827f1e5e22fc97be2c4d8350d | update `t` set `v` = ? where `id` = ? ; | 7480000000000000355F728000000000000002 | {"db_id":1,"db_name":"test","table_id":53,"table_name":"t","handle_type":"int","handle_value":"2"} | 426812829645406217 |
| 1 | 2021-08-05 11:09:03.230341 | 0 | 426812829645406217 | 22230766411edb40f27a68dadefc63c6c6970d5827f1e5e22fc97be2c4d8350d | update `t` set `v` = ? where `id` = ? ; | 7480000000000000355F728000000000000001 | {"db_id":1,"db_name":"test","table_id":53,"table_name":"t","handle_type":"int","handle_value":"1"} | 426812829645406216 |
+-------------+----------------------------+-----------+--------------------+------------------------------------------------------------------+-----------------------------------------+----------------------------------------+----------------------------------------------------------------------------------------------------+--------------------+
查询结果会显示死锁错误中多个事务之间的等待关系和各个事务当前正在执行的 SQL 语句的归一化形式(即去掉参数和格式的形式),以及发生冲突的 key 及其从 key 中解读出的一些信息。
例如在上述例子中,第一行意味着 ID 为 426812829645406216 的事务当前正在执行形如 update `t` set `v` = ? where `id` = ? ; 的语句,被另一个 ID 为 426812829645406217 的事务阻塞;而 426812829645406217 同样也在执行一条形如 update `t` set `v` = ? where `id` = ? ; 的语句,并被 ID 为 426812829645406216 的事务阻塞,两个事务因而构成死锁。
少数热点 key 造成锁排队
DATA_LOCK_WAITS 系统表提供 TiKV 节点上的等锁情况。查询该表时,TiDB 将自动从所有 TiKV 节点上获取当前时刻的等锁信息。当少数热点 key 频繁被上锁并阻塞较多事务时,你可以查询 DATA_LOCK_WAITS 表并按 key 对结果进行聚合,以尝试找出经常发生问题的 key:
select `key`, count(*) as `count` from information_schema.data_lock_waits group by `key` order by `count` desc;
示例输出:
+----------------------------------------+-------+
| key | count |
+----------------------------------------+-------+
| 7480000000000000415F728000000000000001 | 2 |
| 7480000000000000415F728000000000000002 | 1 |
+----------------------------------------+-------+
为避免偶然性,你可考虑进行多次查询。
如果已知频繁出问题的 key,可尝试从 TIDB_TRX 或 CLUSTER_TIDB_TRX 表中获取试图上锁该 key 的事务的信息。
需要注意 TIDB_TRX 和 CLUSTER_TIDB_TRX 表所展示的信息也是对其进行查询的时刻正在运行的事务的信息,并不展示已经结束的事务。如果并发的事务数量很大,该查询的结果集也可能很大,可以考虑添加 limit 子句,或用 where 子句筛选出等锁时间较长的事务。需要注意,对 Lock View 中的多张表进行 join 时,不同表之间的数据并不保证在同一时刻获取,因而不同表中的信息可能并不同步。
以用 where 子句筛选出等锁时间较长的事务为例,请执行以下 SQL 语句:
select trx.* from information_schema.data_lock_waits as l left join information_schema.cluster_tidb_trx as trx on l.trx_id = trx.id where l.key = "7480000000000000415F728000000000000001"\G
示例输出:
*************************** 1. row ***************************
INSTANCE: 127.0.0.1:10080
ID: 426831815660273668
START_TIME: 2021-08-06 07:16:00.081000
CURRENT_SQL_DIGEST: 06da614b93e62713bd282d4685fc5b88d688337f36e88fe55871726ce0eb80d7
CURRENT_SQL_DIGEST_TEXT: update `t` set `v` = `v` + ? where `id` = ? ;
STATE: LockWaiting
WAITING_START_TIME: 2021-08-06 07:16:00.087720
MEM_BUFFER_KEYS: 0
MEM_BUFFER_BYTES: 0
SESSION_ID: 77
USER: root
DB: test
ALL_SQL_DIGESTS: ["0fdc781f19da1c6078c9de7eadef8a307889c001e05f107847bee4cfc8f3cdf3","06da614b93e62713bd282d4685fc5b88d688337f36e88fe55871726ce0eb80d7"]
*************************** 2. row ***************************
INSTANCE: 127.0.0.1:10080
ID: 426831818019569665
START_TIME: 2021-08-06 07:16:09.081000
CURRENT_SQL_DIGEST: 06da614b93e62713bd282d4685fc5b88d688337f36e88fe55871726ce0eb80d7
CURRENT_SQL_DIGEST_TEXT: update `t` set `v` = `v` + ? where `id` = ? ;
STATE: LockWaiting
WAITING_START_TIME: 2021-08-06 07:16:09.290271
MEM_BUFFER_KEYS: 0
MEM_BUFFER_BYTES: 0
SESSION_ID: 75
USER: root
DB: test
ALL_SQL_DIGESTS: ["0fdc781f19da1c6078c9de7eadef8a307889c001e05f107847bee4cfc8f3cdf3","06da614b93e62713bd282d4685fc5b88d688337f36e88fe55871726ce0eb80d7"]
2 rows in set (0.00 sec)
事务被长时间阻塞
如果已知一个事务被另一事务(或多个事务)阻塞,且已知当前事务的 start_ts(即事务 ID),则可使用如下方式获取导致该事务阻塞的事务的信息。注意对 Lock View 中的多张表进行 join 时,不同表之间的数据并不保证在同一时刻获取,因而可能不同表中的信息可能并不同步。
select l.key, trx.*, tidb_decode_sql_digests(trx.all_sql_digests) as sqls from information_schema.data_lock_waits as l join information_schema.cluster_tidb_trx as trx on l.current_holding_trx_id = trx.id where l.trx_id = 426831965449355272\G
示例输出:
*************************** 1. row ***************************
key: 74800000000000004D5F728000000000000001
INSTANCE: 127.0.0.1:10080
ID: 426832040186609668
START_TIME: 2021-08-06 07:30:16.581000
CURRENT_SQL_DIGEST: 06da614b93e62713bd282d4685fc5b88d688337f36e88fe55871726ce0eb80d7
CURRENT_SQL_DIGEST_TEXT: update `t` set `v` = `v` + ? where `id` = ? ;
STATE: LockWaiting
WAITING_START_TIME: 2021-08-06 07:30:16.592763
MEM_BUFFER_KEYS: 1
MEM_BUFFER_BYTES: 19
SESSION_ID: 113
USER: root
DB: test
ALL_SQL_DIGESTS: ["0fdc781f19da1c6078c9de7eadef8a307889c001e05f107847bee4cfc8f3cdf3","a4e28cc182bdd18288e2a34180499b9404cd0ba07e3cc34b6b3be7b7c2de7fe9","06da614b93e62713bd282d4685fc5b88d688337f36e88fe55871726ce0eb80d7"]
sqls: ["begin ;","select * from `t` where `id` = ? for update ;","update `t` set `v` = `v` + ? where `id` = ? ;"]
1 row in set (0.01 sec)
上述查询中,对 CLUSTER_TIDB_TRX 表的 ALL_SQL_DIGESTS 列使用了 TIDB_DECODE_SQL_DIGESTS 函数,目的是将该列(内容为一组 SQL Digest)转换为其对应的归一化 SQL 语句,便于阅读。
如果当前事务的 start_ts 未知,可以尝试从 TIDB_TRX / CLUSTER_TIDB_TRX 表或者 PROCESSLIST / CLUSTER_PROCESSLIST 表中的信息进行判断。
处理乐观锁冲突问题
以下介绍乐观事务模式下常见的锁冲突问题的处理方式。
读写冲突
在 TiDB 中,读取数据时,会获取一个包含当前物理时间且全局唯一递增的时间戳作为当前事务的 start_ts。事务在读取时,需要读到目标 key 的 commit_ts 小于这个事务的 start_ts 的最新的数据版本。当读取时发现目标 key 上存在 lock 时,因为无法知道上锁的那个事务是在 Commit 阶段还是 Prewrite 阶段,所以就会出现读写冲突的情况,如下图:
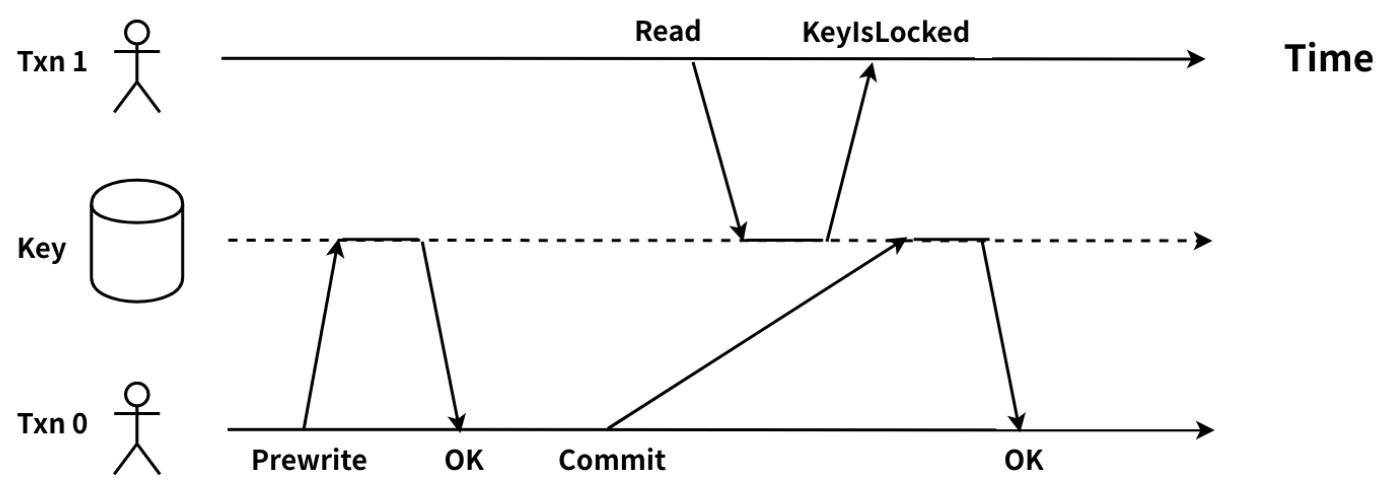
分析:
Txn0 完成了 Prewrite,在 Commit 的过程中 Txn1 对该 key 发起了读请求,Txn1 需要读取 start_ts > commit_ts 最近的 key 的版本。此时,Txn1 的 start_ts > Txn0 的 lock_ts,需要读取的 key 上的锁信息仍未清理,故无法判断 Txn0 是否提交成功,因此 Txn1 与 Txn0 出现读写冲突。
你可以通过如下两种途径来检测当前环境中是否存在读写冲突:
TiDB 监控及日志
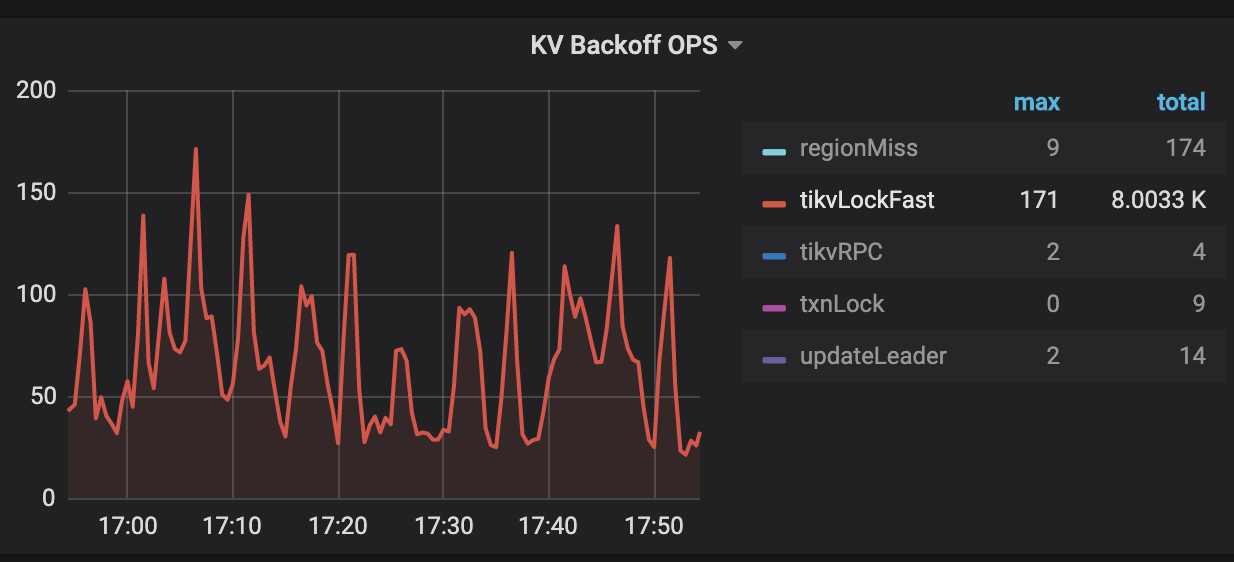
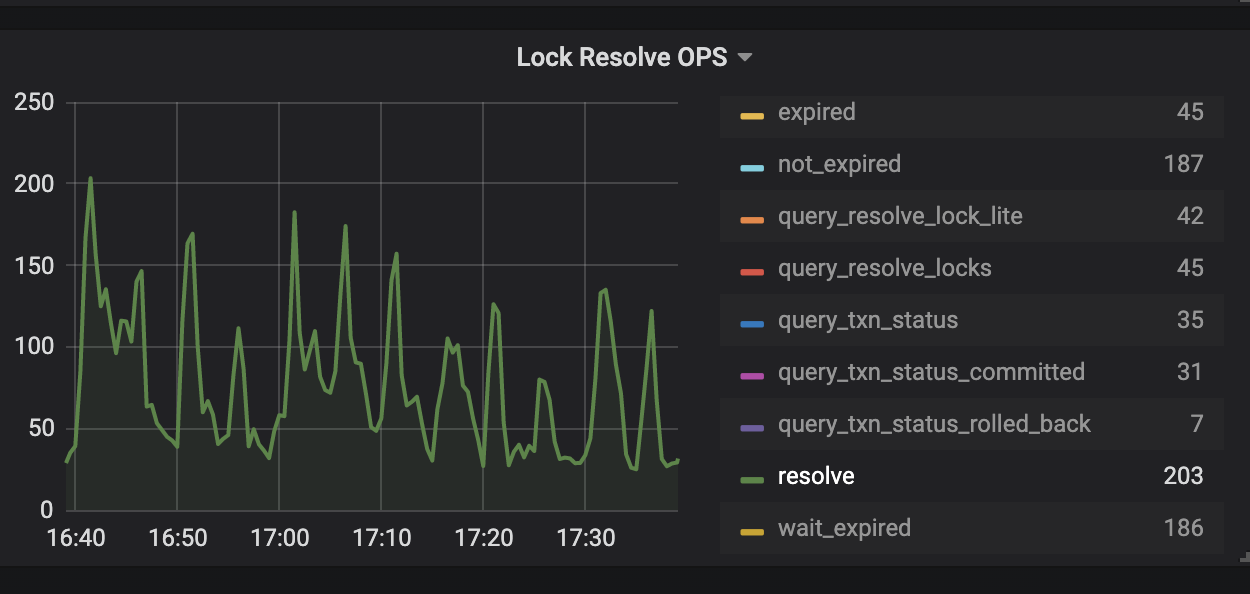
通过 TiDB Grafana 监控分析:
观察 KV Errors 下 Lock Resolve OPS 面板中的 not_expired/resolve 监控项以及 KV Backoff OPS 面板中的 tikvLockFast 监控项,如果有较为明显的上升趋势,那么可能是当前的环境中出现了大量的读写冲突。其中,not_expired 是指对应的锁还没有超时,resolve 是指尝试清锁的操作,tikvLockFast 代表出现了读写冲突。
通过 TiDB 日志分析:
在 TiDB 的日志中可以看到下列信息:
[INFO] [coprocessor.go:743] ["[TIME_COP_PROCESS] resp_time:406.038899ms txnStartTS:416643508703592451 region_id:8297 store_addr:10.8.1.208:20160 backoff_ms:255 backoff_types:[txnLockFast,txnLockFast] kv_process_ms:333 scan_total_write:0 scan_processed_write:0 scan_total_data:0 scan_processed_data:0 scan_total_lock:0 scan_processed_lock:0"]- txnStartTS:发起读请求的事务的 start_ts,如上面示例中的 416643508703592451
- backoff_types:读写发生了冲突,并且读请求进行了 backoff 重试,重试的类型为 txnLockFast
- backoff_ms:读请求 backoff 重试的耗时,单位为 ms,如上面示例中的 255
- region_id:读请求访问的目标 region 的 id
通过 TiKV 日志分析:
在 TiKV 的日志可以看到下列信息:
[ERROR] [endpoint.rs:454] [error-response] [err=""locked primary_lock:7480000000000004D35F6980000000000000010380000000004C788E0380000000004C0748 lock_version: 411402933858205712 key: 7480000000000004D35F7280000000004C0748 lock_ttl: 3008 txn_size: 1""]这段报错信息表示出现了读写冲突,当读数据时发现 key 有锁阻碍读,这个锁包括未提交的乐观锁和未提交的 prewrite 后的悲观锁。
- primary_lock:锁对应事务的 primary lock。
- lock_version:锁对应事务的 start_ts。
- key:表示被锁的 key。
- lock_ttl: 锁的 TTL。
- txn_size:锁所在事务在其 Region 的 key 数量,指导清锁方式。
处理建议:
在遇到读写冲突时会有 backoff 自动重试机制,如上述示例中 Txn1 会进行 backoff 重试,单次初始 10 ms,单次最大 3000 ms,总共最大 20000 ms
可以使用 TiDB Control 的子命令 decoder 来查看指定 key 对应的行的 table id 以及 rowid:
./tidb-ctl decoder "t\x00\x00\x00\x00\x00\x00\x00\x1c_r\x00\x00\x00\x00\x00\x00\x00\xfa" format: table_row table_id: -9223372036854775780 row_id: -9223372036854775558
KeyIsLocked 错误
事务在 Prewrite 阶段的第一步就会检查是否有写写冲突,第二步会检查目标 key 是否已经被另一个事务上锁。当检测到该 key 被 lock 后,会在 TiKV 端报出 KeyIsLocked。目前该报错信息没有打印到 TiDB 以及 TiKV 的日志中。与读写冲突一样,在出现 KeyIsLocked 时,后台会自动进行 backoff 重试。
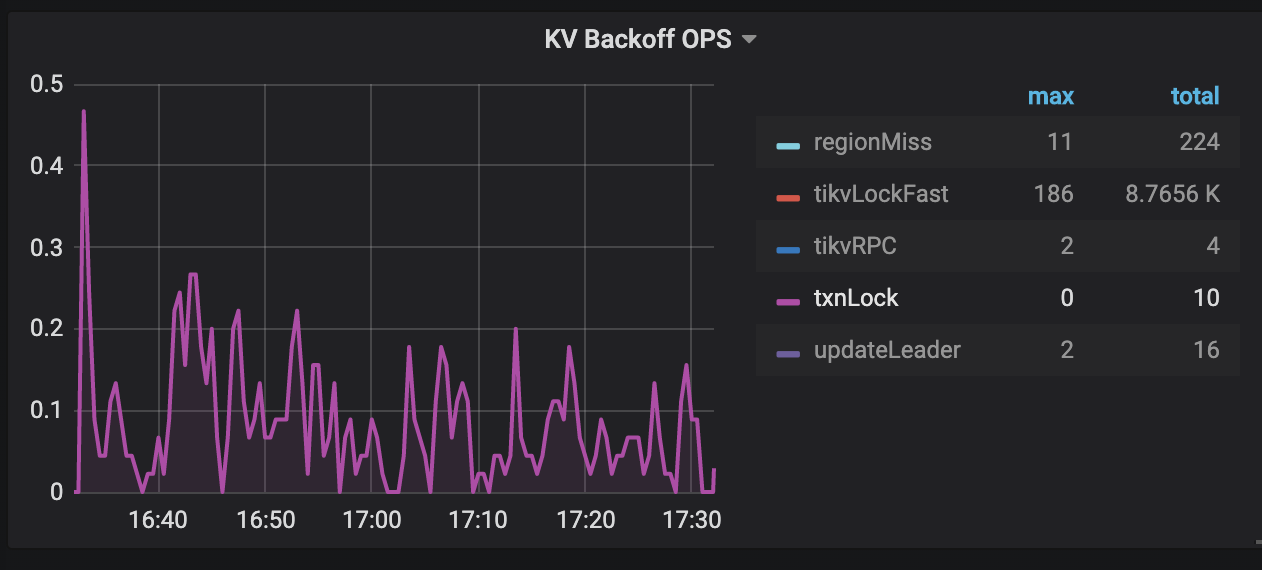
你可以通过 TiDB Grafana 监控检测 KeyIsLocked 错误:
观察 KV Errors 下 Lock Resolve OPS 面板中的 resolve 监控项以及 KV Backoff OPS 面板中的 txnLock 监控项,会有比较明显的上升趋势,其中 resolve 是指尝试清锁的操作,txnLock 代表出现了写冲突。
处理建议:
- 监控中出现少量 txnLock,无需过多关注。后台会自动进行 backoff 重试,单次初始 100 ms,单次最大 3000 ms。
- 如果出现大量的 txnLock,需要从业务的角度评估下冲突的原因。
- 使用悲观锁模式。
锁被清除 (LockNotFound) 错误
TxnLockNotFound 错误是由于事务提交的慢了,超过了 TTL 的时间。当要提交时,发现被其他事务给 Rollback 掉了。在开启 TiDB 自动重试事务的情况下,会自动在后台进行事务重试(注意显示和隐式事务的差别)。
你可以通过如下两种途径来查看 LockNotFound 报错信息:
查看 TiDB 日志
如果出现了 TxnLockNotFound 的报错,会在 TiDB 的日志中看到下面的信息:
[WARN] [session.go:446] ["commit failed"] [conn=149370] ["finished txn"="Txn{state=invalid}"] [error="[kv:6]Error: KV error safe to retry tikv restarts txn: Txn(Mvcc(TxnLockNotFound{ start_ts: 412720515987275779, commit_ts: 412720519984971777, key: [116, 128, 0, 0, 0, 0, 1, 111, 16, 95, 114, 128, 0, 0, 0, 0, 0, 0, 2] })) [try again later]"]- start_ts:出现 TxnLockNotFound 报错的事务的 start_ts,如上例中的 412720515987275779
- commit_ts:出现 TxnLockNotFound 报错的事务的 commit_ts,如上例中的 412720519984971777
查看 TiKV 日志
如果出现了 TxnLockNotFound 的报错,在 TiKV 的日志中同样可以看到相应的报错信息:
Error: KV error safe to retry restarts txn: Txn(Mvcc(TxnLockNotFound)) [ERROR [Kv.rs:708] ["KvService::batch_raft send response fail"] [err=RemoteStoped]
处理建议:
通过检查 start_ts 和 commit_ts 之间的提交间隔,可以确认是否超过了默认的 TTL 的时间。
查看提交间隔:
tiup ctl:v<CLUSTER_VERSION> pd tso [start_ts] tiup ctl:v<CLUSTER_VERSION> pd tso [commit_ts]建议检查下是否是因为写入性能的缓慢导致事务提交的效率差,进而出现了锁被清除的情况。
在关闭 TiDB 事务重试的情况下,需要在应用端捕获异常,并进行重试。
处理悲观锁冲突问题
以下介绍悲观事务模式下常见的锁冲突问题的处理方式。
读写冲突
报错信息以及处理建议同乐观锁模式。
pessimistic lock retry limit reached
在冲突非常严重的场景下,或者当发生 write conflict 时,乐观事务会直接终止,而悲观事务会尝试用最新数据重试该语句直到没有 write conflict。因为 TiDB 的加锁操作是一个写入操作,且操作过程是先读后写,需要 2 次 RPC。如果在这中间发生了 write conflict,那么会重试。每次重试都会打印日志,不用特别关注。重试次数由 pessimistic-txn.max-retry-count 定义。
可通过查看 TiDB 日志查看报错信息:
悲观事务模式下,如果发生 write conflict,并且重试的次数达到了上限,那么在 TiDB 的日志中会出现含有下述关键字的报错信息。如下:
err="pessimistic lock retry limit reached"
处理建议:
- 如果上述报错出现的比较频繁,建议从业务的角度进行调整。
- 如果业务中包含对同一行(同一个 key)的高并发上锁而频繁冲突,可以尝试启用系统变量
tidb_pessimistic_txn_fair_locking。需要注意启用该选项可能对存在锁冲突的事务带来一定程度的吞吐下降(平均延迟上升)的代价。对于新部署的集群,该选项默认启用 (ON) 。
Lock wait timeout exceeded
在悲观锁模式下,事务之间出现会等锁的情况。等锁的超时时间由 TiDB 的 innodb_lock_wait_timeout 参数来定义,这个是 SQL 语句层面的最大允许等锁时间,即一个 SQL 语句期望加锁,但锁一直获取不到,超过这个时间,TiDB 不会再尝试加锁,会向客户端返回相应的报错信息。
可通过查看 TiDB 日志查看报错信息:
当出现等锁超时的情况时,会向客户端返回下述报错信息:
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
处理建议:
- 如果出现的次数非常频繁,建议从业务逻辑的角度来进行调整。
TTL manager has timed out
除了有不能超出 GC 时间的限制外,悲观锁的 TTL 有上限,默认为 1 小时,所以执行时间超过 1 小时的悲观事务有可能提交失败。这个超时时间由 TiDB 参数 performance.max-txn-ttl 指定。
可通过查看 TiDB 日志查看报错信息:
当悲观锁的事务执行时间超过 TTL 时,会出现下述报错:
TTL manager has timed out, pessimistic locks may expire, please commit or rollback this transaction
处理建议:
当遇到该报错时,建议确认下业务逻辑是否可以进行优化,如将大事务拆分为小事务。在未使用大事务的前提下,大事务可能会触发 TiDB 的事务限制。
可适当调整相关参数,使其符合事务要求。
Deadlock found when trying to get lock
死锁是指两个或两个以上的事务在执行过程中,由于竞争资源而造成的一种阻塞的现象,若无外力作用,它们都将无法推进下去,将永远在互相等待。此时,需要终止其中一个事务使其能够继续推进下去。
TiDB 在使用悲观锁的情况下,多个事务之间出现了死锁,必定有一个事务 abort 来解开死锁。在客户端层面行为和 MySQL 一致,在客户端返回表示死锁的 Error 1213。如下:
[err="[executor:1213]Deadlock found when trying to get lock; try restarting transaction"]
处理建议:
- 如果难以确认产生死锁的原因,对于 v5.1 及以后的版本,建议尝试查询
INFORMATION_SCHEMA.DEADLOCKS或INFORMATION_SCHEMA.CLUSTER_DEADLOCKS系统表来获取死锁的等待链信息。详情请参考死锁错误小节和DEADLOCKS表文档。 - 如果死锁出现非常频繁,需要调整业务代码来降低发生概率。