TiFlash 性能分析和优化方法
本文介绍 TiFlash 资源使用率和关键的性能指标。你可以通过 Performance Overview 面板中的 TiFlash 面板,来监控和评估 TiFlash 集群的性能。
TiFlash 集群资源利用率
通过以下三个指标,你可以快速判断 TiFlash 集群的资源使用率:
- CPU:每个 TiFlash 实例的 CPU 使用率
- Memory:每个 TiFlash 实例内存的使用情况
- IO utilization:每个 TiFlash 实例的 IO 使用率
示例:CH-benCHmark 负载资源使用率
该 TiFlash 集群包含两个节点,每个节点配置均为 16 核、48G 内存。当 CH-benCHmark 负载运行时,CPU 利用率最高可达到 1500%,内存占用最大可达 20 GB,IO 利用率达到 91%。这表明 TiFlash 节点资源接近饱和状态。

TiFlash 关键性能指标
吞吐指标
通过以下指标,你可以了解 TiFlash 的吞吐情况:
- MPP Query count:每个 TiFlash 实例 MPP 查询数量的瞬时值,表示当前 TiFlash 实例需要处理的 MPP 查询数量(包括正在处理的以及还没被调度到的)。
- Request QPS:所有 TiFlash 实例收到的 coprocessor 请求数量。
run_mpp_task、dispatch_mpp_task和mpp_establish_conn为 MPP 请求。batch:batch 请求数量。cop:直接通过 coprocessor 接口发送的 coprocessor 请求数量。cop_execution:正在执行的 coprocessor 请求数量。remote_read、remote_read_constructed和remote_read_sent为 remote read 相关指标,remote read 增多一般意味着系统出现了问题。
- Executor QPS:所有 TiFlash 实例收到的请求中,每种 dag 算子的数量,其中
table_scan是扫表算子,selection是过滤算子,aggregation是聚合算子,top_n是 TopN 算子,limit是 limit 算子,join为关联算子,exchange_sender和exchange_receiver为数据发送和接收算子。
延迟指标
通过以下指标,你可以了解 TiFlash 的延迟处理情况:
Request Duration Overview:每秒所有 TiFlash 实例处理所有请求类型的总时长堆叠图。
如果请求类型为
run_mpp_task、dispatch_mpp_task或mpp_establish_conn,说明 SQL 语句的执行已经部分或者完全下推到 TiFlash 上进行,通常包含 join 和数据分发的操作,这是 TiFlash 最常见的请求类型。如果请求类型为
cop,说明整个语句并没有完全下推到 TiFlash,通常 TiDB 会将全表扫描算子下推到 TiFlash 上进行数据访问和过滤。在堆叠图中,如果cop占据主导地位,需要仔细权衡是否合理。- 如果 SQL 访问的数据量很大,优化器可能根据成本模型估算 TiFlash 全表扫描的成本更低。
- 如果表结构缺少合适的索引,即使访问的数据量很少,优化器也只能将查询下推到 TiFlash 进行全表扫描。在这种情况下,创建合适的索引,通过 TiKV 访问数据更加高效。
Request Duration:所有 TiFlash 实例每种 MPP 和 coprocessor 请求类型的总处理时间,包含平均和 P99 处理延迟。
Request Handle Duration:指
cop和batch cop从开始执行到执行结束的时间,不包括等待时间,只包含cop和batch cop两种类型,包含平均和 P99 延迟。
示例 1 :TiFlash MPP 请求处理时间概览
如下图所示,在此负载中,run_mpp_task 和 mpp_establish_conn 请求的处理时间占比最高,表明大部分请求都是完全下推到 TiFlash 上执行的 MPP 任务。
而 cop 请求处理时间占比较小,说明存在一部分请求是通过 coprocessor 下推到 TiFlash 上进行数据访问和过滤的。

示例 2 :TiFlash cop 请求处理时间占比高
如下图所示,在此负载中,cop 请求的处理时间占比最高,可以通过查看 SQL 执行计划来确认 cop 请求产生的原因。

Raft 相关指标
通过以下指标,你可以了解 TiFlash 的 Raft 同步情况:
Raft Wait Index Duration:所有 TiFlash 实例等待本地 Region index >= read_index 所花费的时间,即进行 wait_index 操作的延迟。如果 Wait Index 延迟过高,说明 TiKV 和 TiFlash 之间数据同步存在明显的延迟,可能的原因包括:
- TiKV 资源过载
- TiFlash 资源过载,特别是 IO 资源
- TiKV 和 TiFlash 之间存在网络瓶颈
Raft Batch Read Index Duration:所有 TiFlash 实例
read_index的延迟。如果该指标过高,说明 TiFlash 和 TiKV 之间的交互速度较慢,可能的原因包括:- TiFlash 资源过载
- TiKV 资源过载
- TiFlash 和 TiKV 之间存在网络瓶颈
IO 流量指标
通过以下指标,你可以了解 TiFlash 的 IO 流量情况:
Write Throughput By Instance:每个 TiFlash 实例写入数据的吞吐量,包括 apply Raft 数据日志以及 Raft 快照的写入吞吐量。
Write flow:所有 TiFlash 实例磁盘写操作的流量。
- File Descriptor:TiFlash 所使用的 DeltaTree 存储引擎的稳定层。
- Page:指 Pagestore,TiFlash 所使用的 DeltaTree 存储引擎的 Delta 变更层。
Read flow:所有 TiFlash 实例磁盘读操作的流量。
- File Descriptor:TiFlash 所使用的 DeltaTree 存储引擎的稳定层。
- Page:指 Pagestore,TiFlash 所使用的 DeltaTree 存储引擎的 Delta 变更层。
你可以通过 (Read flow + Write flow) ÷ 总的 Write Throughput By Instance 计算出整个 TiFlash 集群的写放大倍数。
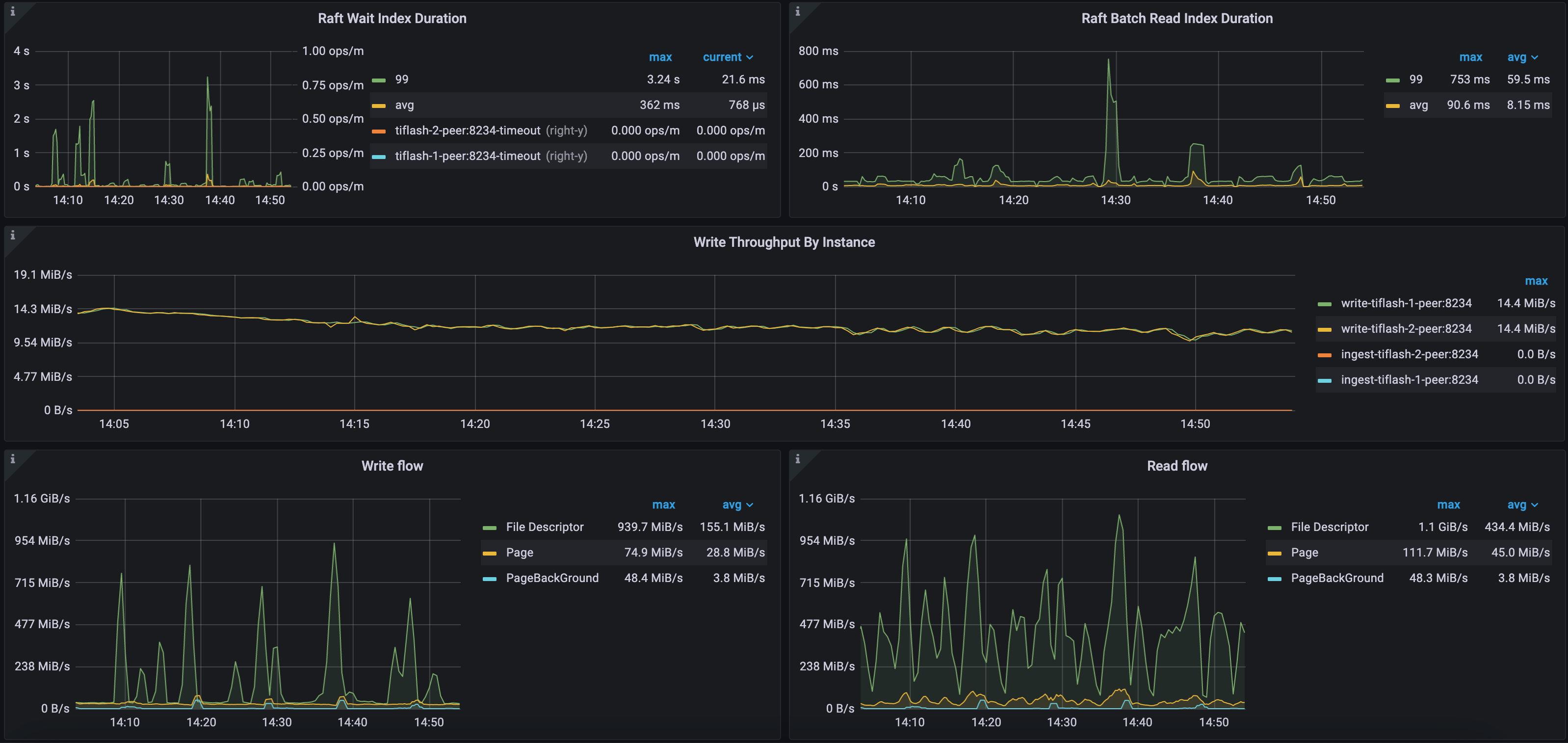
示例 1 :CH-benCHmark 负载本地部署环境 Raft 和 IO 指标
如下图所示,该 TiFlash 集群的 Raft Wait Index Duration 和 Raft Batch Read Index Duration 的 99 分位数较高,分别为 3.24 秒和 753 毫秒。这是因为该集群的 TiFlash 负载较高,数据同步存在延迟。
该集群包含两个 TiFlash 节点,每秒 TiKV 同步到 TiFlash 的增量数据约为 28 MB。稳定层 (File Descriptor) 的文件描述符最大写流量为 939 MB/s,最大读流量为 1.1 GiB/s,而 Delta 层 (Page) 最大写流量为 74 MB/s,最大读流量为 111 MB/s。该环境中的 TiFlash 使用独立的 NVME 盘,具有较强的 IO 吞吐能力。
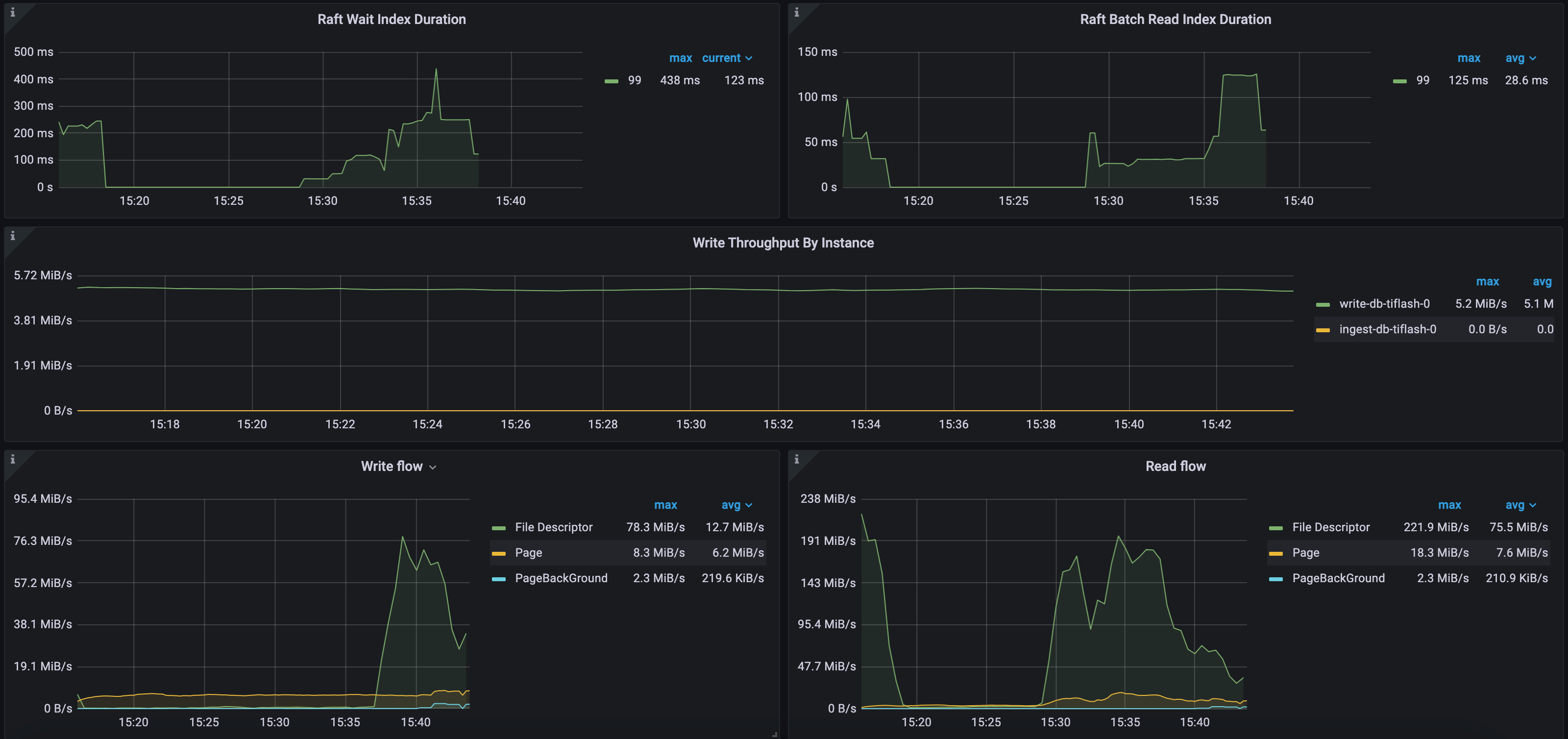
示例 2 :CH-benCHmark 负载 公有云环境 Raft 和 IO 指标
如下图所示,Raft Wait Index Duration 等待时间 99 分位数最高为 438 毫秒,Raft Batch Read Index Duration 等待时间 99 分位数最高为 125 毫秒。该集群只有一个 TiFlash 节点,每秒 TiKV 同步到 TiFlash 的增量数据约为 5 MB。稳定层 (File Descriptor) 的最大写入流量为 78 MB/s,最大读取流量为 221 MB/s,Delta 层 (Page) 最大写入流量为 8 MB/s,最大读取流量为 18 MB/s。这个环境中的 TiFlash 使用的是 AWS EBS 云盘,其 IO 吞吐能力相对较弱。