TiDB 高并发写入场景最佳实践
在 TiDB 的使用过程中,一个典型场景是高并发批量写入数据到 TiDB。本文阐述了该场景中的常见问题,旨在给出一个业务的最佳实践,帮助读者避免因使用 TiDB 不当而影响业务开发。
目标读者
本文假设你已对 TiDB 有一定的了解,推荐先阅读 TiDB 原理相关的三篇文章(讲存储,说计算,谈调度),以及 TiDB Best Practice。
高并发批量插入场景
高并发批量插入的场景通常出现在业务系统的批量任务中,例如清算以及结算等业务。此类场景存在以下特点:
- 数据量大
- 需要短时间内将历史数据入库
- 需要短时间内读取大量数据
这就对 TiDB 提出了以下挑战:
- 写入/读取能力是否可以线性水平扩展
- 随着数据持续大并发写入,数据库性能是否稳定不衰减
对于分布式数据库来说,除了本身的基础性能外,最重要的就是充分利用所有节点能力,避免让单个节点成为瓶颈。
TiDB 数据分布原理
如果要解决以上挑战,需要从 TiDB 数据切分以及调度的原理开始讲起。这里只作简单说明,详情可参阅谈调度。
TiDB 以 Region 为单位对数据进行切分,每个 Region 有大小限制(默认 96M)。Region 的切分方式是范围切分。每个 Region 会有多副本,每一组副本,称为一个 Raft Group。每个 Raft Group 中由 Leader 负责执行这块数据的读 & 写(TiDB 支持 Follower-Read)。Leader 会自动地被 PD 组件均匀调度在不同的物理节点上,用以均分读写压力。
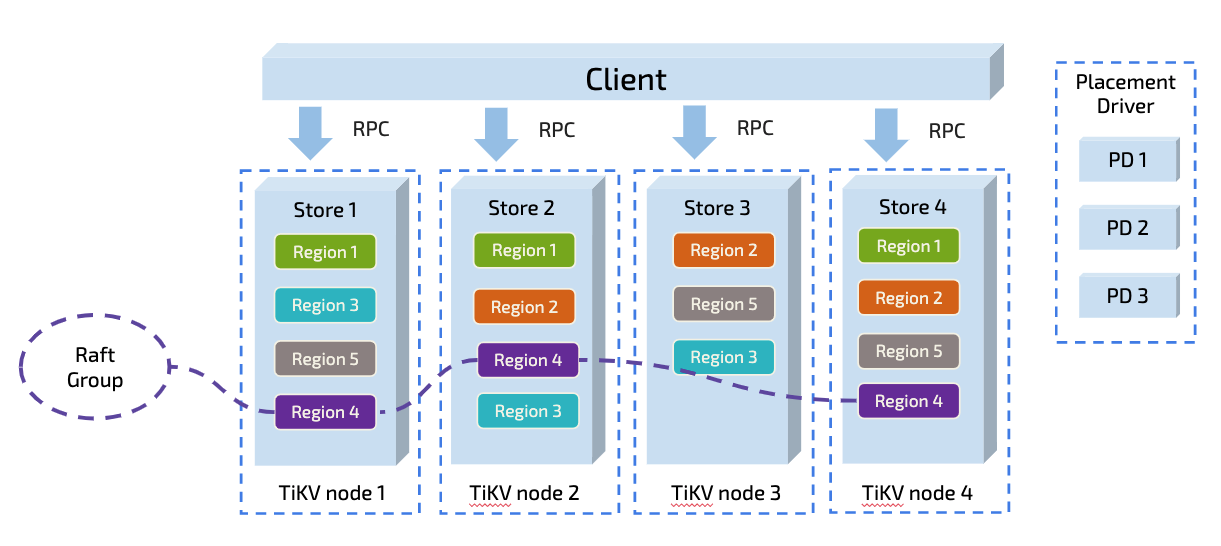
从原理上来说,只要没有业务上的写入热点(即业务写入没有 AUTO_INCREMENT 的主键和单调递增的索引,更多细节可参阅 TiDB 正确使用方式),依靠这个架构,TiDB 不仅具备线性扩展的读写能力,也能够充分利用分布式资源。从这一点看,TiDB 尤其适合高并发批量写入场景的业务。
但理论场景和实际情况往往存在不同。以下实例说明了热点是如何产生的。
热点产生的实例
以下为一张示例表:
CREATE TABLE IF NOT EXISTS TEST_HOTSPOT(
id BIGINT PRIMARY KEY,
age INT,
user_name VARCHAR(32),
email VARCHAR(128)
)
这个表的结构非常简单,除了 id 为主键以外,没有额外的二级索引。将数据写入该表的语句如下,id 通过随机数离散生成:
SET SESSION cte_max_recursion_depth = 1000000;
INSERT INTO TEST_HOTSPOT
SELECT
n, -- ID
RAND()*80, -- 0 到 80 之间的随机数
CONCAT('user-',n),
CONCAT(
CHAR(65 + (RAND() * 25) USING ascii), -- 65 到 65+25 之间的随机数,转换为一个 A-Z 字符
'-user-',
n,
'@example.com'
)
FROM
(WITH RECURSIVE nr(n) AS
(SELECT 1 -- 从 1 开始 CTE
UNION ALL SELECT n + 1 -- 每次循环 n 增加 1
FROM nr WHERE n < 1000000 -- 当 n 为 1_000_000 时停止循环
) SELECT n FROM nr
) a;
负载是短时间内密集地执行以上写入语句。
以上操作看似符合理论场景中的 TiDB 最佳实践,业务上没有热点产生。只要有足够的机器,就可以充分利用 TiDB 的分布式能力。要验证是否真的符合最佳实践,可以在实验环境中进行测试。
部署拓扑 2 个 TiDB 节点,3 个 PD 节点,6 个 TiKV 节点。请忽略 QPS,因为测试只是为了阐述原理,并非 benchmark。
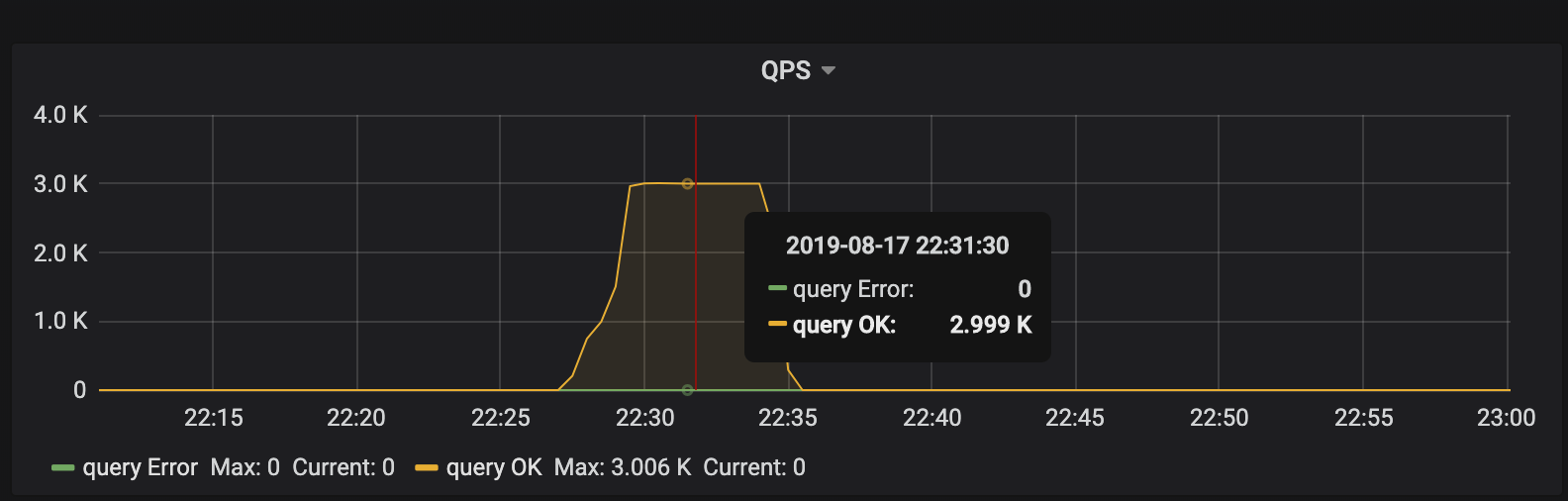
客户端在短时间内发起了“密集”的写入,TiDB 收到的请求是 3K QPS。理论上,压力应该均摊给 6 个 TiKV 节点。但是从 TiKV 节点的 CPU 使用情况上看,存在明显的写入倾斜(tikv - 3 节点是写入热点):
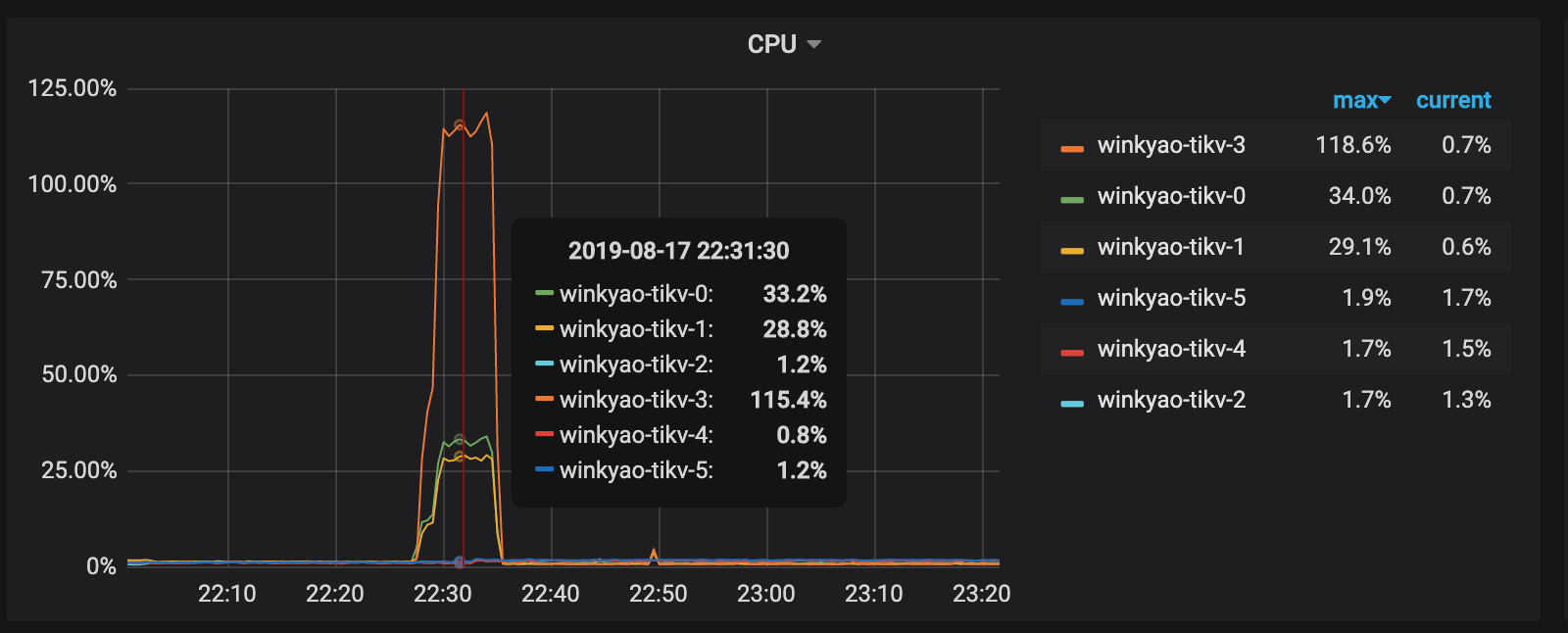
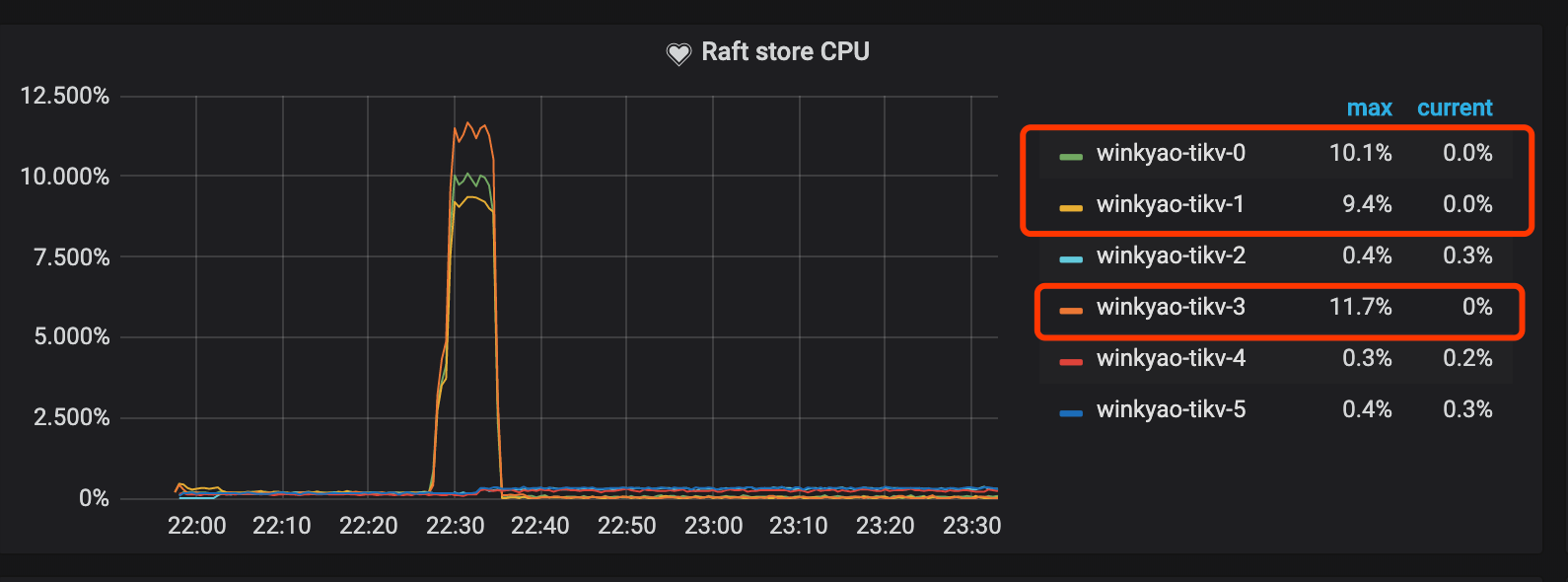
Raft store CPU 为 raftstore 线程的 CPU 使用率,通常代表写入的负载。在这个场景下 tikv-3 为 Raft Leader,tikv-0 和 tikv-1 是 Raft 的 Follower,其他的 TiKV 节点的负载几乎为空。
从 PD 的监控中也可以证明热点的产生:
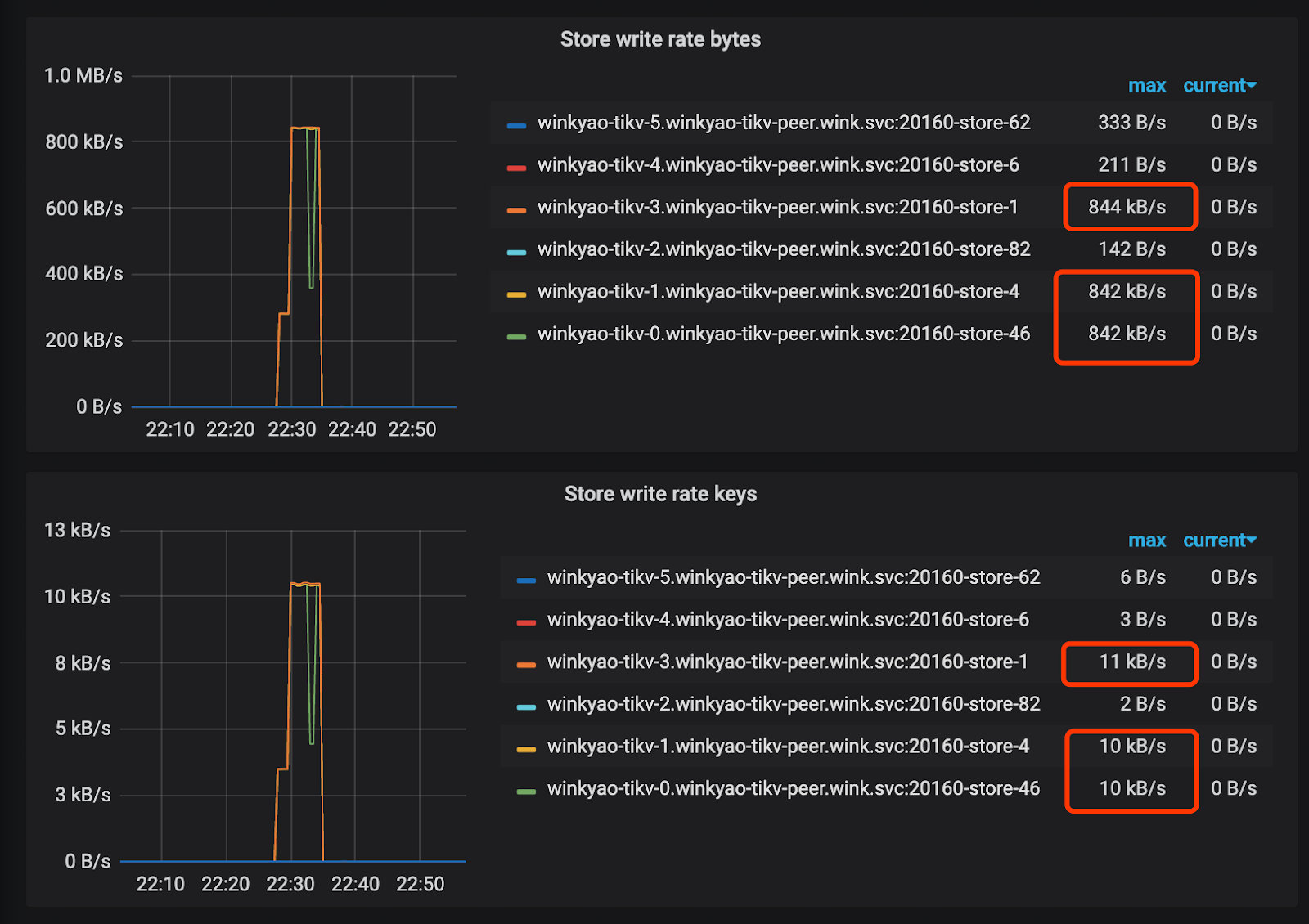
热点问题产生的原因
以上测试并未达到理论场景中最佳实践,因为刚创建表的时候,这个表在 TiKV 中只会对应为一个 Region,范围是:
[CommonPrefix + TableID, CommonPrefix + TableID + 1)
短时间内大量数据会持续写入到同一个 Region 上。
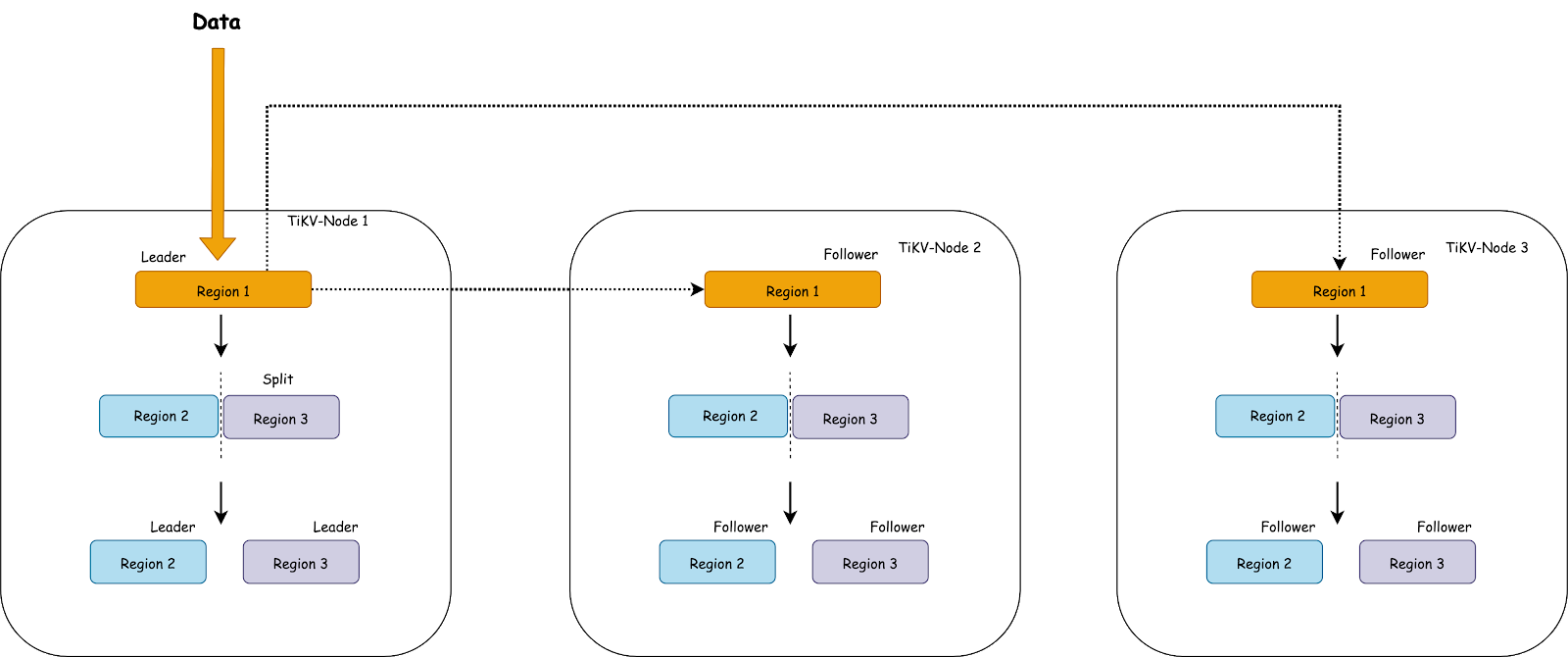
上图简单描述了这个过程,随着数据持续写入,TiKV 会将一个 Region 切分为多个。但因为首先发起选举的是原 Leader 所在的 Store,所以新切分好的两个 Region 的 Leader 很可能还会在原 Store 上。新切分好的 Region 2,3 上,也会重复之前发生在 Region 1 上的过程。也就是压力会密集地集中在 TiKV-Node 1 上。
在持续写入的过程中,PD 发现 Node 1 中产生了热点,会将 Leader 均分到其他的 Node 上。如果 TiKV 的节点数多于副本数的话,TiKV 会尽可能将 Region 迁移到空闲的节点上。这两个操作在数据插入的过程中,也能在 PD 监控中得到印证:
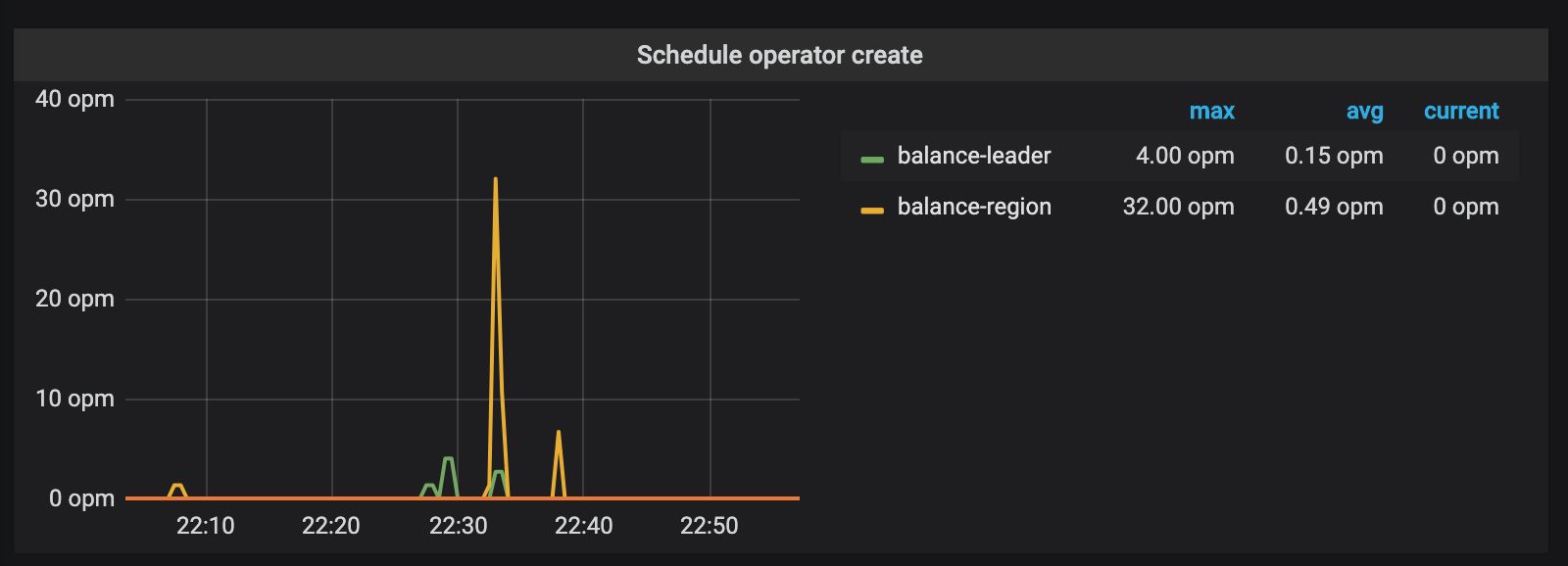
在持续写入一段时间后,整个集群会被 PD 自动地调度成一个压力均匀的状态,到那个时候整个集群的能力才会真正被利用起来。在大多数情况下,以上热点产生的过程是没有问题的,这个阶段属于表 Region 的预热阶段。
但是对于高并发批量密集写入场景来说,应该避免这个阶段。
热点问题的规避方法
为了达到场景理论中的最佳性能,可跳过这个预热阶段,直接将 Region 切分为预期的数量,提前调度到集群的各个节点中。
TiDB 在 v3.0.x 以及 v2.1.13 后支持一个叫 Split Region 的新特性。这个特性提供了新的语法:
SPLIT TABLE table_name [INDEX index_name] BETWEEN (lower_value) AND (upper_value) REGIONS region_num
SPLIT TABLE table_name [INDEX index_name] BY (value_list) [, (value_list)]
但是 TiDB 并不会自动提前完成这个切分操作。原因如下:
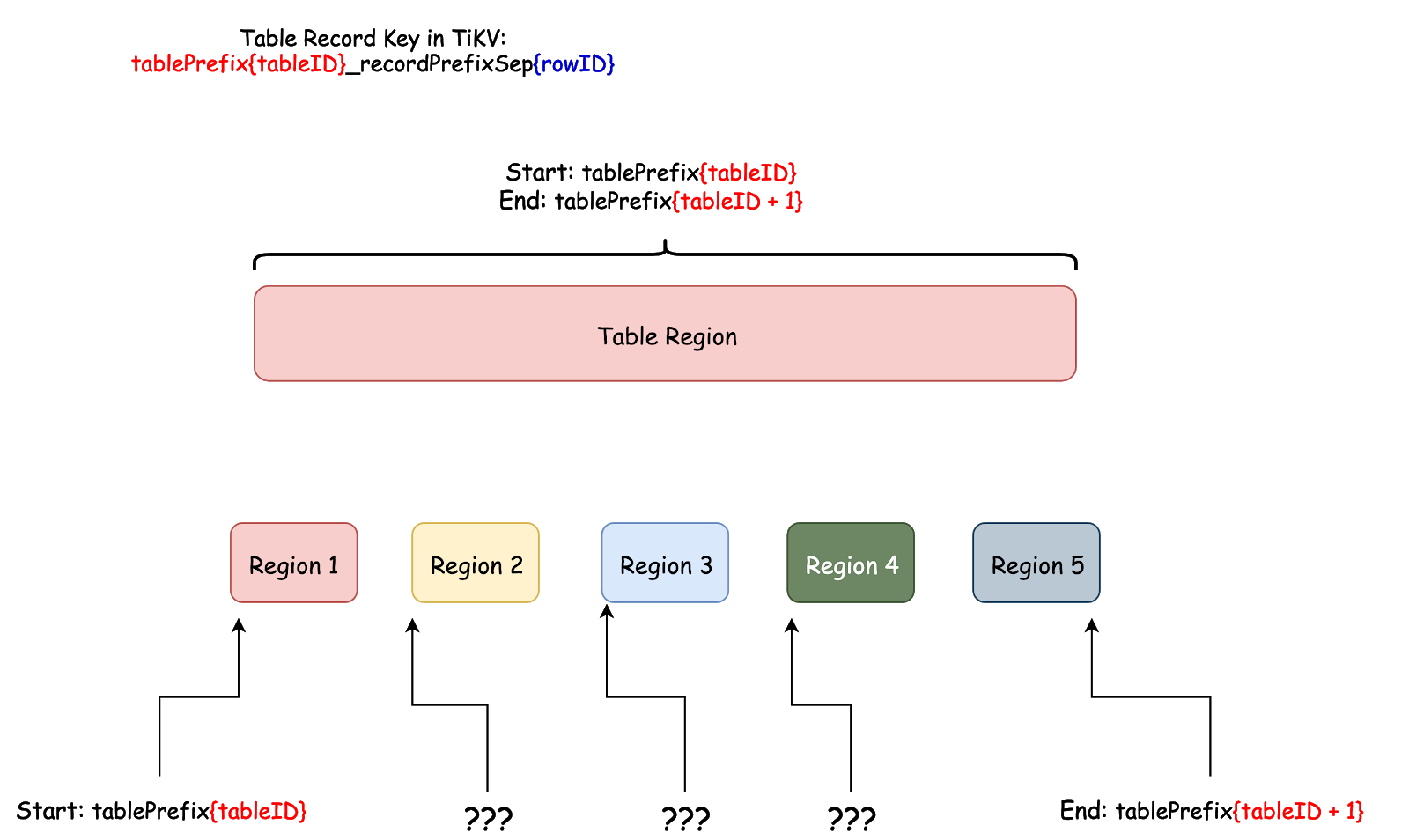
从上图可知,根据行数据 key 的编码规则,行 ID (rowID) 是行数据中唯一可变的部分。在 TiDB 中,rowID 是一个 Int64 整型。但是用户不一定能将 Int64 整型范围均匀切分成需要的份数,然后均匀分布在不同的节点上,还需要结合实际情况。
如果行 ID 的写入是完全离散的,那么上述方式是可行的。如果行 ID 或者索引有固定的范围或者前缀(例如,只在 [2000w, 5000w) 的范围内离散插入数据),这种写入依然在业务上不产生热点,但是如果按上面的方式进行切分,那么有可能一开始数据仍只写入到某个 Region 上。
作为一款通用数据库,TiDB 并不对数据的分布作假设,所以开始只用一个 Region 来对应一个表。等到真实数据插入进来以后,TiDB 自动根据数据的分布来作切分。这种方式是较通用的。
所以 TiDB 提供了 Split Region 语法,专门针对短时批量写入场景作优化。基于以上案例,下面尝试用 Split Region 语法提前切散 Region,再观察负载情况。
由于测试的写入数据在正数范围内完全离散,所以用以下语句,在 Int64 空间内提前将表切分为 128 个 Region:
SPLIT TABLE TEST_HOTSPOT BETWEEN (0) AND (9223372036854775807) REGIONS 128;
切分完成以后,可以通过 SHOW TABLE test_hotspot REGIONS; 语句查看打散的情况。如果 SCATTERING 列值全部为 0,代表调度成功。
也可以通过以下 SQL 语句查看 Region 的分布。你需要将 table_name 替换为实际的表名。
SELECT
p.STORE_ID,
COUNT(s.REGION_ID) PEER_COUNT
FROM
INFORMATION_SCHEMA.TIKV_REGION_STATUS s
JOIN INFORMATION_SCHEMA.TIKV_REGION_PEERS p ON s.REGION_ID = p.REGION_ID
WHERE
TABLE_NAME = 'table_name'
AND p.is_leader = 1
GROUP BY
p.STORE_ID
ORDER BY
PEER_COUNT DESC;
再重新运行写入负载:
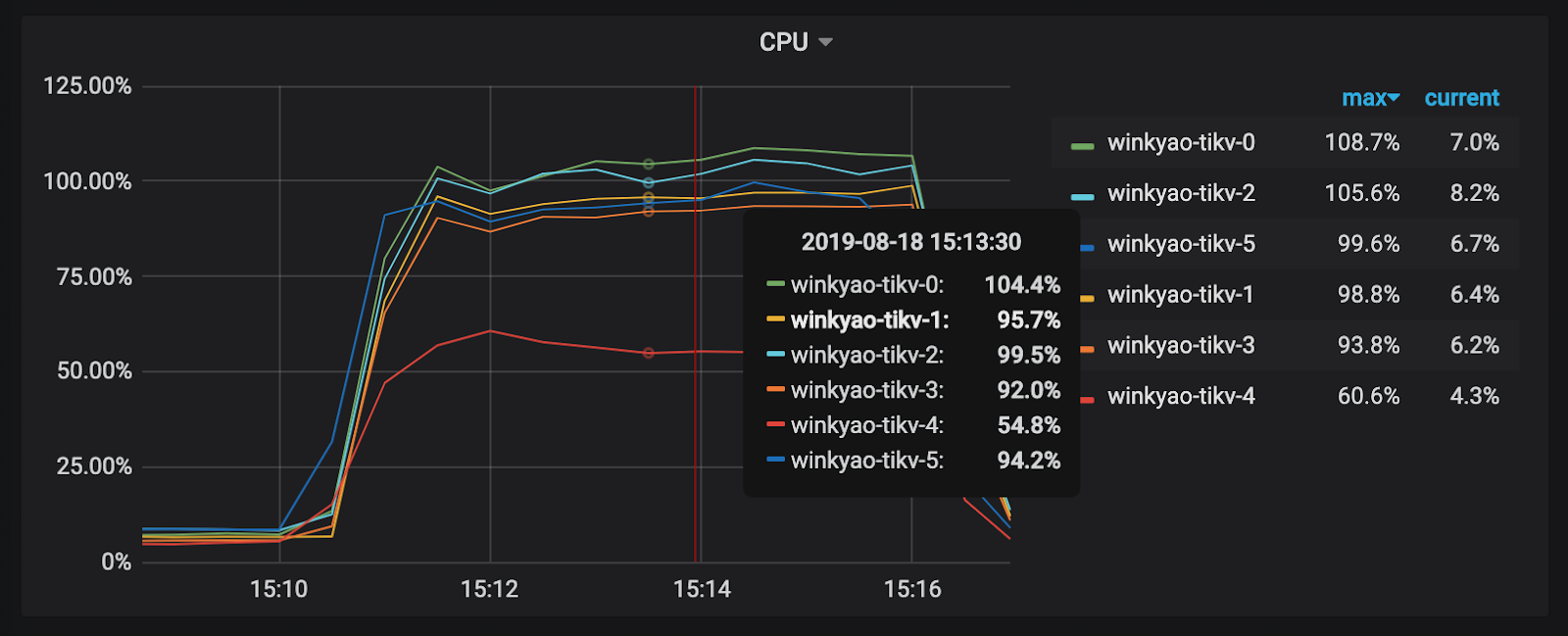
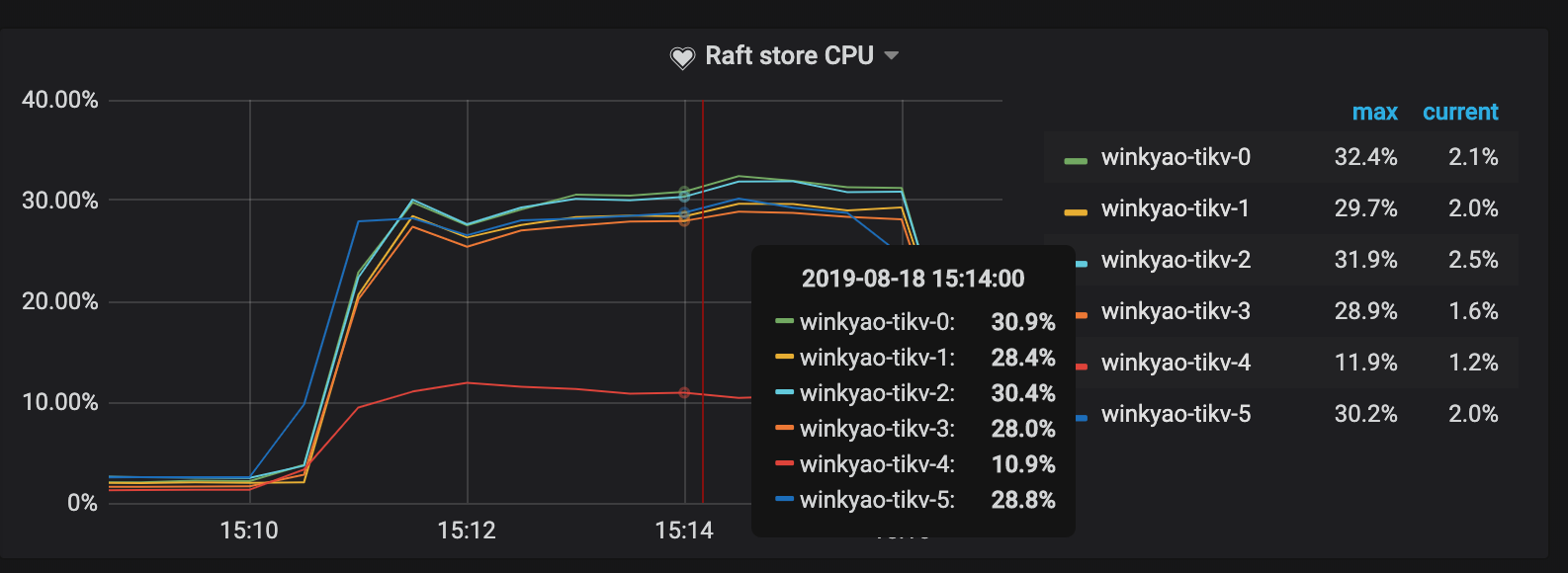
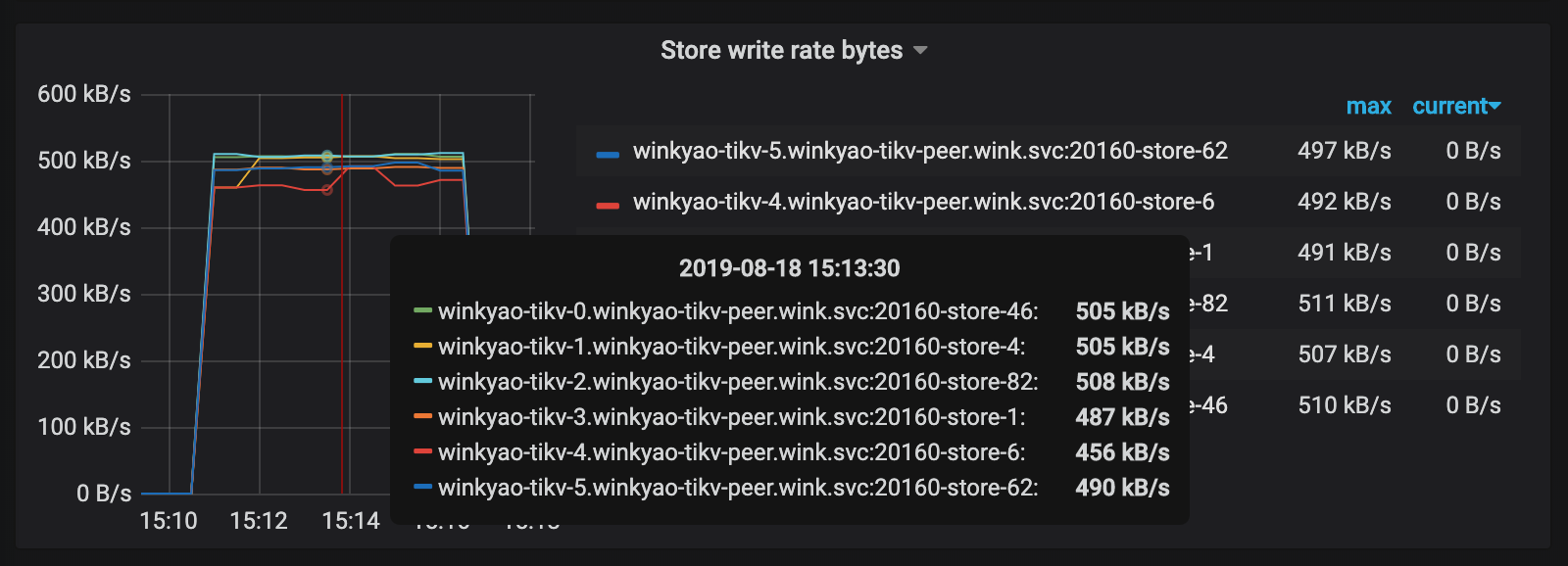
可以看到已经消除了明显的热点问题了。
本示例仅为一个简单的表,还有索引热点的问题需要考虑。读者可参阅 Split Region 文档来了解如何预先切散索引相关的 Region。
更复杂的热点问题
问题一:
如果表没有主键或者主键不是整数类型,而且用户也不想自己生成一个随机分布的主键 ID 的话,TiDB 内部有一个隐式的 _tidb_rowid 列作为行 ID。在不使用 SHARD_ROW_ID_BITS 的情况下,_tidb_rowid 列的值基本也为单调递增,此时也会有写热点存在(参阅 SHARD_ROW_ID_BITS 的详细说明)。
要避免由 _tidb_rowid 带来的写入热点问题,可以在建表时,使用 SHARD_ROW_ID_BITS 和 PRE_SPLIT_REGIONS 这两个建表选项(参阅 PRE_SPLIT_REGIONS 的详细说明)。
SHARD_ROW_ID_BITS 用于将 _tidb_rowid 列生成的行 ID 随机打散。PRE_SPLIT_REGIONS 用于在建完表后预先进行 Split region。
以下全局变量会影响 PRE_SPLIT_REGIONS 的行为,需要特别注意:
tidb_scatter_region:该变量用于控制建表完成后是否等待预切分和打散 Region 完成后再返回结果。如果建表后有大批量写入,需要设置该变量值为1,表示等待所有 Region 都切分和打散完成后再返回结果给客户端。否则未打散完成就进行写入会对写入性能影响有较大的影响。
示例:
create table t (a int, b int) SHARD_ROW_ID_BITS = 4 PRE_SPLIT_REGIONS=3;
SHARD_ROW_ID_BITS = 4表示 tidb_rowid 的值会随机分布成 16 (16=2^4) 个范围区间。PRE_SPLIT_REGIONS=3表示建完表后提前切分出 8 (2^3) 个 Region。
开始写数据进表 t 后,数据会被写入提前切分好的 8 个 Region 中,这样也避免了刚开始建表完后因为只有一个 Region 而存在的写热点问题。
问题二:
如果表的主键为整数类型,并且该表使用了 AUTO_INCREMENT 来保证主键唯一性(不需要连续或递增)的表而言,由于 TiDB 直接使用主键行值作为 _tidb_rowid,此时无法使用 SHARD_ROW_ID_BITS 来打散热点。
要解决上述热点问题,可以利用 AUTO_RANDOM 列属性(参阅 AUTO_RANDOM 的详细说明),将 AUTO_INCREMENT 改为 AUTO_RANDOM,插入数据时让 TiDB 自动为整型主键列分配一个值,消除行 ID 的连续性,从而达到打散热点的目的。
参数配置
TiDB 2.1 版本中在 SQL 层引入了 latch 机制,用于在写入冲突比较频繁的场景中提前发现事务冲突,减少 TiDB 和 TiKV 事务提交时写写冲突导致的重试。通常,跑批场景使用的是存量数据,所以并不存在事务的写入冲突。可以把 TiDB 的 latch 功能关闭,以减少为细小对象分配内存:
[txn-local-latches]
enabled = false