Data Migration 高可用机制
为了保障迁移服务的连续性,Data Migration (DM) 中的组件 DM master 和 DM worker 均实现了高可用机制,避免单点故障。本文将详述其高可用机制的内部机制,以及对迁移任务的影响。
在详细了解 DM 高可用机制之前,请先了解 DM 整体架构以及各个关键组件的作用。
DM master 内部架构
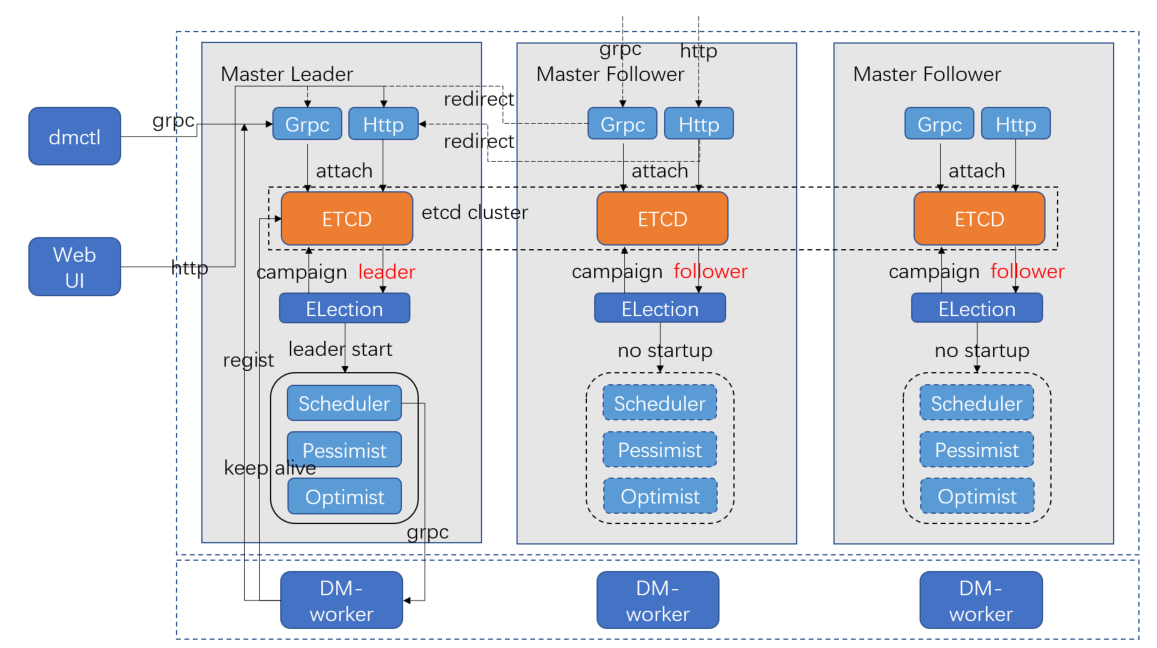
gRPC 和 HTTP 接口。DM master 对外提供 gRPC 以及 HTTP 接口,供其他组件调用,如 dmctl、WebUI、DM worker。DM master 的 Follower 节点在收到 gRPC 和 HTTP 请求后,会 redirect 给 DM master 的 Leader 节点进行处理。
etcd。DM master 内部嵌入 etcd 来组成集群,同时 etcd 也作为 DM master、DM worker、Source、Task 等配置或者状态的存储介质。
Election。Election 周期性地调用 etcd 的 campaign 接口进行选举。
- 若该节点为 Leader,则启动 DM master 的其他组件,如 Scheduler、Pessimist、Optimist 等,各组件在启动时会读取 etcd 中保存的信息,实现相关任务的接续执行。
- 若该节点为 Follower,则不启动其他组件。
- 若该节点从 Leader 切换回 Follower,则会关闭其他组件。
Scheduler。负责注册及监听 DM worker 状态,安排分配 Source 以及 Task。
Pessimist 和 Optimist。DM master 实现对 DDL 进行悲观协调以及乐观协调的模块。
dmctl/WebUI 调用流程。dmctl 调用 DM master 的 gRPC 接口,WebUI 调用 DM master 的 HTTP 接口。
- 若非 Leader 节点,则进行 redirect 给 Leader 节点。
- 若 dmctl 和 WebUI 请求需要调用 DM worker 进行信息收集或者操作,则由 DM master 的 Scheduler 模块通过 gRPC 接口调用 DM worker。
DM master 与 DM worker 调用流程。DM worker 启动时会通过 gRPC 调用 DM master 来注册 worker 信息,DM master 主要调用 Scheduler 模块实现相关的逻辑。DM worker 在注册之后,会通过 etcd 实现 Keep-Alive。若 DM worker 发生故障,DM master 的 Scheduler 模块的监听会发现该 DM worker 出现故障,从而将该 DM worker 上的相关任务进行转移。
DM master 高可用机制
DM master 恢复服务
从 DM master 的架构可以看出,DM master 的高可用主要依赖内嵌的 etcd 实现。
若某一个 DM master 节点发生故障,DM master 的 Election 模块会通过 etcd 选举出新的 Leader 节点,新的 Leader 节点会启动 DM master 相关组件,且组件启动会读取保存于 etcd 中的信息,做到接续执行。
其他组件恢复访问
DM master 之外的组件(如 dmctl、DM worker)调用 DM master 接口,可采用传入多 endpoint 的方式,避免只配置单个 endpoint 时,该节点出现故障而无法访问的问题。
其他组件(当前指 WebUI)若遇到访问节点发生故障,在 DM master 集群恢复后,可以切换节点继续访问。若非访问节点发生故障,DM master 集群恢复后可以继续访问。
影响恢复的因素
DM master 集群的 Leader 出现节点故障之后,会由 Election 模块重新选举一个 Leader,此过程主要受到 etcd 性能影响。
新的 Leader 需要重新启动 Scheduler、Pessimist、Optimist 等模块,此过程主要需要读取保存于 etcd 中的各模块信息,实现接续执行。但此过程只是在内存中构建实例,耗时不大,因此,耗时主要取决于 etcd 集群的恢复时间。
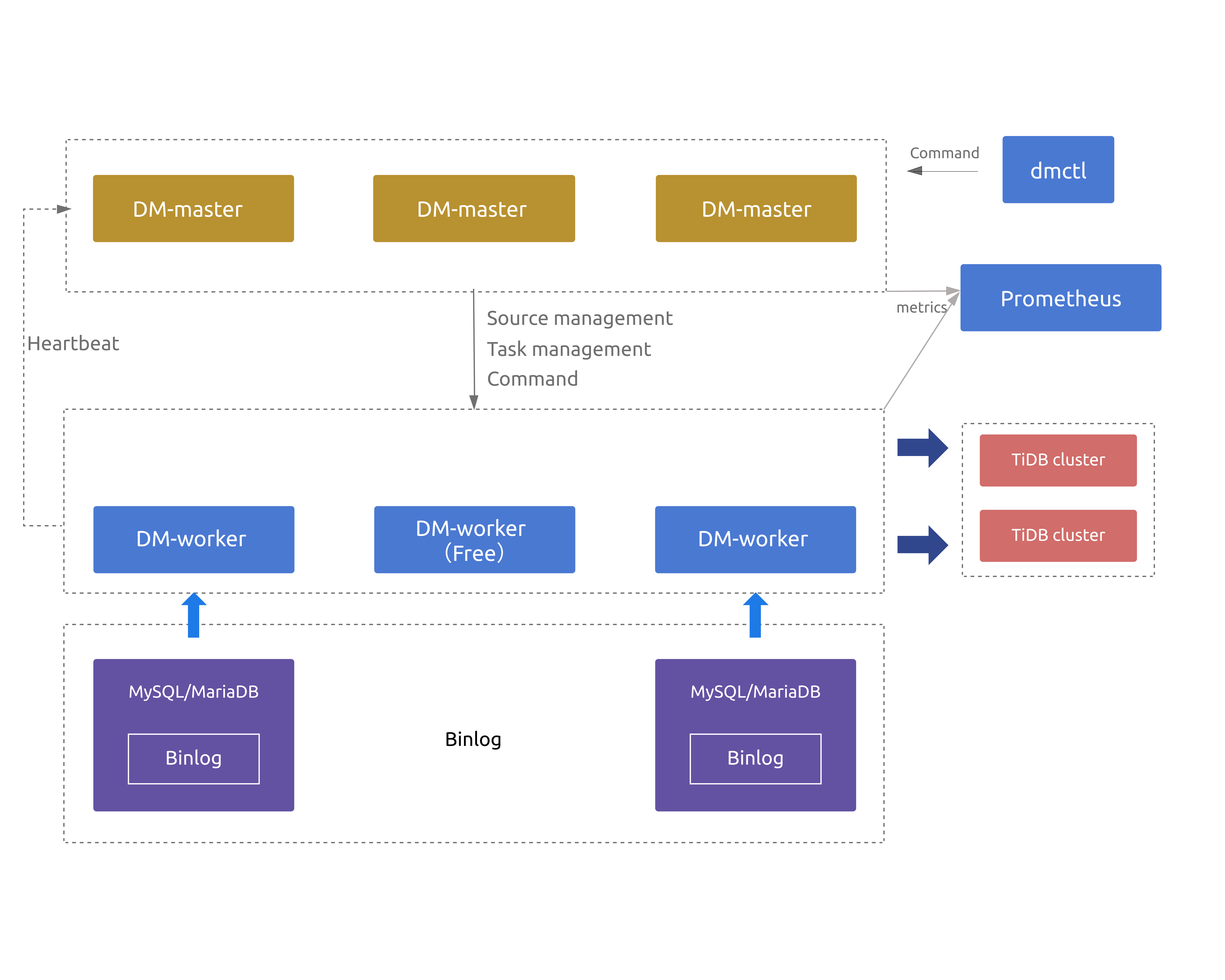
DM worker 高可用机制
当部署的 DM worker 节点数超过上游 MySQL/MariaDB 节点数时,超出上游节点数的相关 DM worker 节点默认将处于空闲 (Free) 状态。若某个 DM worker 节点下线或与 DM master 发生网络中断,DM worker 向 DM master 发送的 keepalive 心跳将中断,此时 DM master 会自动把与原 DM worker 节点相关的数据迁移任务调度到其他空闲的 DM worker 节点上并继续运行。
DM worker 高可用架构如下所示:
任务调度策略
在了解调度策略前,你需要熟悉以下概念:
- source:上游数据库源实例,例如一个 MySQL 实例。
- task:数据迁移任务,负责将一个或多个 source 同步到单个下游数据库。
- subtask:数据迁移子任务,单个子任务负责将一个上游数据库同步到一个下游数据库,子任务的集合组成了 task。
- bound:DM worker 与 source 的绑定关系,一个 DM worker 在同一时间仅能处理一个 source 的迁移任务。当 DM worker 拉取某个 source 的 relay log 后,该 DM worker 将不能再处理其他 source 的迁移任务。
DM worker 负责的任务以上游源数据库(简称 source)为调度单位,即一个 DM worker 仅能服务一个 source。多个 task 可能需要同步同一个 source,此时该 source 所处 worker 将为每个 task 派生 subtask。
当 DM worker 向 DM master 发送心跳中断超过 TTL 后,DM master 会将该 DM worker 负责的 source 与对应 subtask 调度给没有绑定的 source 的 DM worker。调度的优先级从高到低为:
- 该 source 之前在该 DM worker 上存在未完成的全量导入任务。
- 该 source 上次由该 DM worker 处理且 DM worker 开启了该 source 的 relay log。
- 该 DM worker 开启了该 source 的 relay log。
- 该 source 上次由该 DM worker 处理。
- 任一空闲状态的 DM worker。
如果没有处于空闲状态的 DM worker,则该 source 的 subtasks 将被暂时挂起,直到原先的 DM worker 恢复或者新的 DM worker 节点加入。当 DM master 收到 DM worker 的重新上线心跳或是新的 DM worker 节点的心跳信息时,DM master 会按照上述优先级顺序,寻找处于未绑定 DM worker 的 source 进行绑定。
特殊任务调度
通常情况下,DM master 只会为 source 试图绑定处于未绑定状态的 DM worker。但仅有一种情况存在例外,即 source 在某个 DM worker 存在未完成的全量导入任务。
采取这样的调度策略的原因如下:在 on-premises 环境中,DM worker 全量导出阶段导出的数据均保留在本地盘,大部分时候全量导入任务必须要在对应的 DM worker 才能正确进行,否则需要重新导出一遍数据,会增加大量不必要开销。
假设以下场景:
- worker1 绑定 source1,subtask 处于 dump 阶段;
- worker2 绑定 source2,subtask 处于 sync 阶段;
- worker3 空闲;
当 worker1 发生故障下线后,DM master 扫描所有 worker,并判断 worker2 上是否存在 source1 未完成的全量迁移;
- 若存在。解绑 source2 ,worker2 绑定 source1,worker3 绑定 source2;
- 若不存在。worker2 绑定 source2 无变化,worker3 绑定 source1。
DM worker 重新上线也与上述流程基本一致,如果寻找到符合条件的 source,会进行换绑,并为 source 先前绑定的 DM worker 尝试重新绑定新的 source。
常见问题
当 DM worker 恢复后,source 是否会再迁回来
在两种情况下 source 将再迁回恢复的旧 DM worker:
- 旧 DM worker 之前连接的 source 在下线期间没有被调度到其他 DM worker (例如没有空闲 Worker);
- source 之前在旧 DM worker 上有未完成的 load 阶段任务,且 source 在新 DM worker 上仍处于 dump 阶段。
假如 DM worker 恢复后,原 source 没有如预期自动迁回,如何手动干预
这种情况下,你可以使用 transfer source 功能,将 source 重新绑定到该 DM worker。
DM worker 与 DM master 保持心跳的超时时间及配置
在 DM v2.0.1 及之前版本,DM worker 的超时时间为 10 秒,在 DM v2.0.2 及之后版本中,超时时间为 60s。该值可以通过修改 DM worker 的 keepalive-ttl 配置,单位为秒。
在 DM v2.0.2 及更新版本中,DM worker 为 source 开启 relay-log 后,其超时时间将变为 1800 秒。该值可以通过修改 DM worker 的 relay-keepalive-ttl 配置,单位为秒。
DM 集群跨区域高可用
由上文可知,DM master 的高可用依赖于 etcd 实现,而 etcd 高可用需要超过半数节点存活。若仅考虑最大服务可用性,建议在部署时选择奇数(≥3)个 Region/AZ。在每个 Region/AZ 至少部署 1 个 DM master,以避免单个 Region/AZ 故障导致 DM 集群无法服务。
由于单个 worker 仅能服务一个 source,因此每个 Region/AZ 还需要部署足够数量的空闲 worker,以便当某个 Region/AZ 故障时,空闲 worker 足以容纳该 Region/AZ 的所有 source。