TiDB 快照备份与恢复功能架构
本文以使用 BR 工具进行备份与恢复为例,介绍 TiDB 集群快照数据备份和恢复的架构设计与流程。
架构设计
快照数据备份和恢复的架构如下:
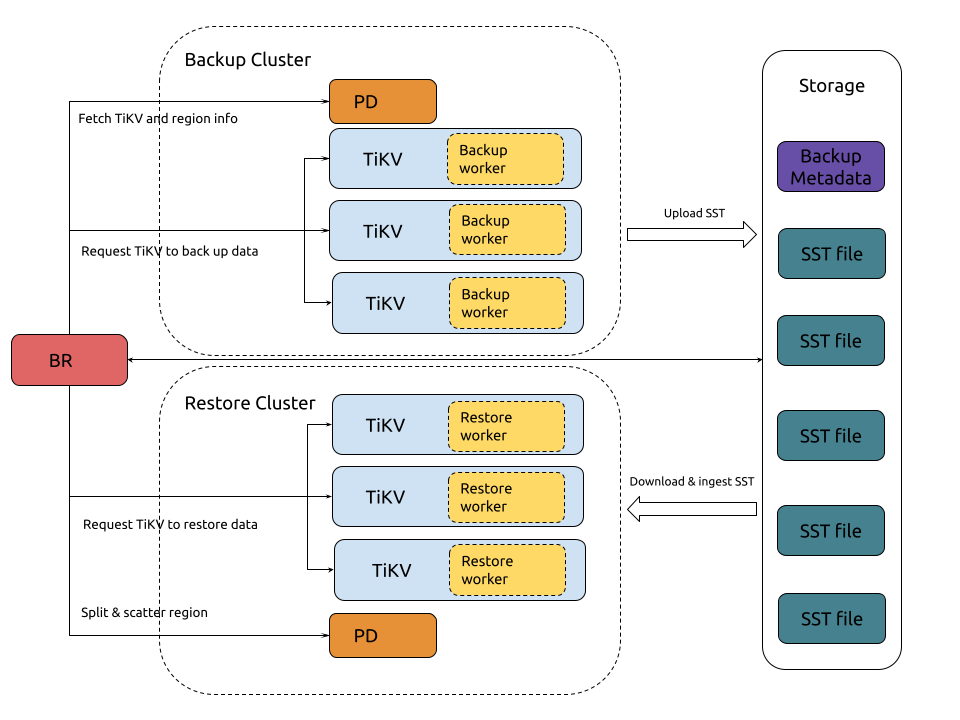
备份流程
集群快照数据备份的流程如下:
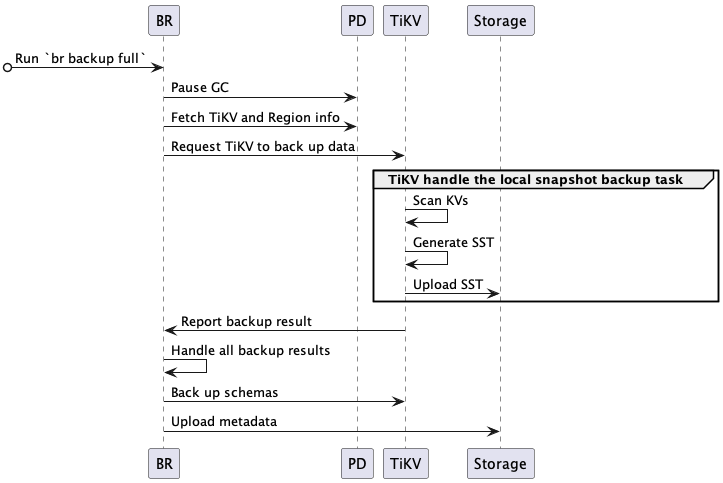
完整的备份交互流程描述如下:
BR 接收备份命令
br backup full。- 获得备份快照点 (backup ts) 和备份存储地址。
BR 调度备份数据。
- Pause GC:配置 TiDB GC,防止要备份的数据被 TiDB GC 机制回收。
- Fetch TiKV and Region info:访问 PD,获取所有 TiKV 节点访问地址以及数据的 Region 分布信息。
- Request TiKV to back up data:创建备份请求,发送给 TiKV 节点,备份请求包含 backup ts、需要备份的 region、备份存储地址。
TiKV 接受备份请求,初始化 backup worker。
TiKV 备份数据。
- Scan KVs:backup worker 从 Region (only leader) 读取 backup ts 对应的数据。
- Generate SST:backup worker 将读取到的数据保存到 SST 文件,存储在内存中。
- Upload SST:backup worker 上传 SST 文件到备份存储中。
BR 从各个 TiKV 获取备份结果。
- 如果局部数据因为 Region 变动而备份失败,比如 TiKV 节点故障,BR 将重试这些数据的备份。
- 如果任意数据被判断为不可重试的备份失败,则备份任务失败。
- 全部数据备份成功后,则在最后完成元信息备份。
BR 备份元信息。
- Back up schemas:备份 table schema,同时计算 table data checksum。
- Upload metadata:生成 backup metadata,并上传到备份存储。backup metadata 包含 backup ts、表和对应的备份文件、data checksum 和 file checksum 等信息。
恢复流程
恢复集群快照备份数据的流程如下:
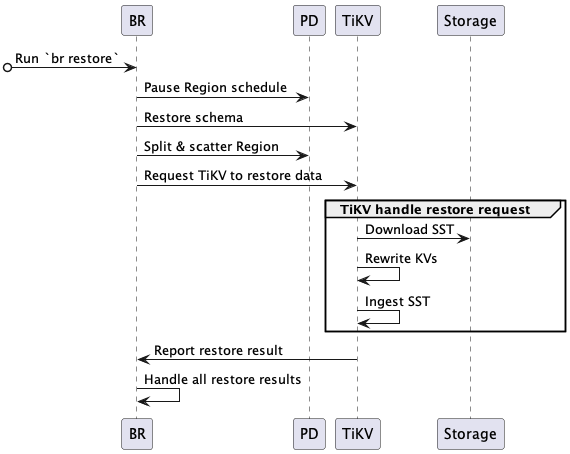
完整的恢复交互流程描述如下:
BR 接收恢复命令
br restore。- 获得快照备份数据存储地址、要恢复的 database 或 table。
- 检查要恢复的 table 是否存在及是否符合要求。
BR 调度恢复数据。
- Pause Region schedule:请求 PD 在恢复期间关闭自动 Region schedule。
- Restore schema:读取备份数据的 schema、恢复的 database 和 table(注意新建表的 table ID 与备份数据可能不一样)。
- Split & scatter Region:BR 基于备份数据信息,请求 PD 分配 Region (split Region),并调度 Region 均匀分布到存储节点上 (scatter Region)。每个 Region 都有明确的数据范围 [start key, end key)。
- Request TiKV to restore data:根据 PD 分配的 Region 结果,发送恢复请求到对应的 TiKV 节点,恢复请求包含要恢复的备份数据及 rewrite 规则。
TiKV 接受恢复请求,初始化 restore worker。
- restore worker 计算恢复数据需要读取的备份数据。
TiKV 恢复数据。
- Download SST:restore worker 从备份存储中下载相应的备份数据到本地。
- Rewrite KVs:restore worker 根据新建表 table ID,对备份数据 kv 进行重写,即将原有的 kv 编码中的 table ID 替换为新创建的 table ID。对 index ID,restore worker 也进行相同处理。
- Ingest SST:restore worker 将处理好的 SST 文件 ingest 到 RocksDB 中。
- Report restore result:restore worker 返回恢复结果给 BR。
BR 从各个 TiKV 获取恢复结果。
- 如果局部数据恢复因为
RegionNotFound或EpochNotMatch等原因失败,比如 TiKV 节点故障,BR 重试恢复这些数据。 - 如果存在备份数据不可重试的恢复失败,则恢复任务失败。
- 全部备份都恢复成功后,则整个恢复任务成功。
- 如果局部数据恢复因为
详细的快照数据备份恢与恢复流程设计,可以参考备份恢复设计方案。
备份文件
文件类型
快照备份会产生如下类型文件:
SST文件:存储 TiKV 备份下来的数据信息。单个SST文件大小等于 TiKV Region 的大小。backupmeta文件:存储本次备份的元信息,包括备份文件数、备份文件的 Key 区间、备份文件大小和备份文件 Hash (sha256) 值。backup.lock文件:用于防止多次备份到同一目录。
SST 文件的命名格式
当备份数据到 Google Cloud Storage 或 Azure Blob Storage 时,SST 文件以 storeID_regionID_regionEpoch_keyHash_timestamp_cf 的格式命名。格式名的解释如下:
storeID:TiKV 节点编号regionID:Region 编号regionEpoch:Region 版本号keyHash:Range startKey 的 Hash (sha256) 值,确保唯一性timestamp:TiKV 节点生成 SST 文件名时刻的 Unix 时间戳cf:RocksDB 的 ColumnFamily(只备份 cf 为default或write的数据)
当备份数据到 Amazon S3 或网络盘上时,SST 文件以 regionID_regionEpoch_keyHash_timestamp_cf 的格式命名。
regionID:Region 编号regionEpoch:Region 版本号keyHash:Range startKey 的 Hash (sha256) 值,确保唯一性timestamp:TiKV 节点生成 SST 文件名时刻的 Unix 时间戳cf:RocksDB 的 ColumnFamily(只备份 cf 为default或write的数据)
SST 文件存储格式
- 关于 SST 文件存储格式,可以参考 RocksDB SST table 介绍。
- 关于 SST 文件中存储的备份数据编码格式,可以参考 TiDB 表数据与 Key-Value 的映射关系。
备份文件目录结构
将数据备份到 Google Cloud Storage 或 Azure Blob Storage 上时,SST 文件、backupmeta 文件和 backup.lock 文件在同一目录下。目录结构如下:
.
└── 20220621
├── backupmeta
|—— backup.lock
├── {storeID}-{regionID}-{regionEpoch}-{keyHash}-{timestamp}-{cf}.sst
├── {storeID}-{regionID}-{regionEpoch}-{keyHash}-{timestamp}-{cf}.sst
└── {storeID}-{regionID}-{regionEpoch}-{keyHash}-{timestamp}-{cf}.sst
将数据备份到 Amazon S3 或网络盘上时,SST 文件会根据 storeID 划分子目录。目录结构如下:
.
└── 20220621
├── backupmeta
|—— backup.lock
├── store1
│ └── {regionID}-{regionEpoch}-{keyHash}-{timestamp}-{cf}.sst
├── store100
│ └── {regionID}-{regionEpoch}-{keyHash}-{timestamp}-{cf}.sst
├── store2
│ └── {regionID}-{regionEpoch}-{keyHash}-{timestamp}-{cf}.sst
├── store3
├── store4
└── store5