TiFlash Pipeline Model 执行模型
本文介绍 TiFlash 新的执行模型 Pipeline Model。
从 v7.2.0 起,TiFlash 支持新的执行模型 Pipeline Model。你可以通过修改变量 tidb_enable_tiflash_pipeline_model 来控制是否启用 TiFlash Pipeline Model。
Pipeline Model 主要借鉴了 Morsel-Driven Parallelism: A NUMA-Aware Query Evaluation Framework for the Many-Core Age 这篇论文,提供了一个精细的任务调度模型,有别于传统的线程调度模型,减少了操作系统申请和调度线程的开销以及提供精细的调度机制。
启用和禁用 TiFlash Pipeline Model
你可以使用系统变量 tidb_enable_tiflash_pipeline_model 来开启或禁用 TiFlash Pipeline Model。该变量可以在 Session 级别和 Global 级别生效。默认情况下,tidb_enable_tiflash_pipeline_model=OFF,即关闭 TiFlash Pipeline Model。你可以通过以下语句来查看对应的变量信息:
SHOW VARIABLES LIKE 'tidb_enable_tiflash_pipeline_model';
+------------------------------------+-------+
| Variable_name | Value |
+------------------------------------+-------+
| tidb_enable_tiflash_pipeline_model | OFF |
+------------------------------------+-------+
SHOW GLOBAL VARIABLES LIKE 'tidb_enable_tiflash_pipeline_model';
+------------------------------------+-------+
| Variable_name | Value |
+------------------------------------+-------+
| tidb_enable_tiflash_pipeline_model | OFF |
+------------------------------------+-------+
变量 tidb_enable_tiflash_pipeline_model 支持 session 级别和 global 级别的修改。
如果需要在当前 session 中开启 TiFlash Pipeline Model,可以通过以下语句设置:
SET SESSION tidb_enable_tiflash_pipeline_model=ON;如果需要在 global 级别开启 TiFlash Pipeline Model,可以通过以下语句设置:
SET GLOBAL tidb_enable_tiflash_pipeline_model=ON;设置 global 级别后,新建的会话中 session 和 global 级别的
tidb_enable_tiflash_pipeline_model都将默认启用新值。
如需关闭 TiFlash Pipeline Model,可以通过以下语句设置:
SET SESSION tidb_enable_tiflash_pipeline_model=OFF;
SET GLOBAL tidb_enable_tiflash_pipeline_model=OFF;
设计实现
TiFlash 原有执行模型 Stream Model 是线程调度执行模型,每一个查询会独立申请若干条线程协同执行。
线程调度模型存在两个缺陷:
在高并发场景下,过多的线程会引起较多上下文切换,导致较高的线程调度代价。
线程调度模型无法精准计量查询的资源使用量以及做细粒度的资源管控。
在新的执行模型 Pipeline Model 中进行了以下优化:
查询会被划分为多个 pipeline 并依次执行。在每个 pipeline 中,数据块会被尽可能保留在缓存中,从而实现更好的时间局部性,从而提高整个执行过程的效率。
为了摆脱操作系统原生的线程调度模型,实现更加精细的调度机制,每个 pipeline 会被实例化成若干个 task,使用 task 调度模型,同时使用固定线程池,减少了操作系统申请和调度线程的开销。
TiFlash Pipeline Model 的架构如下:
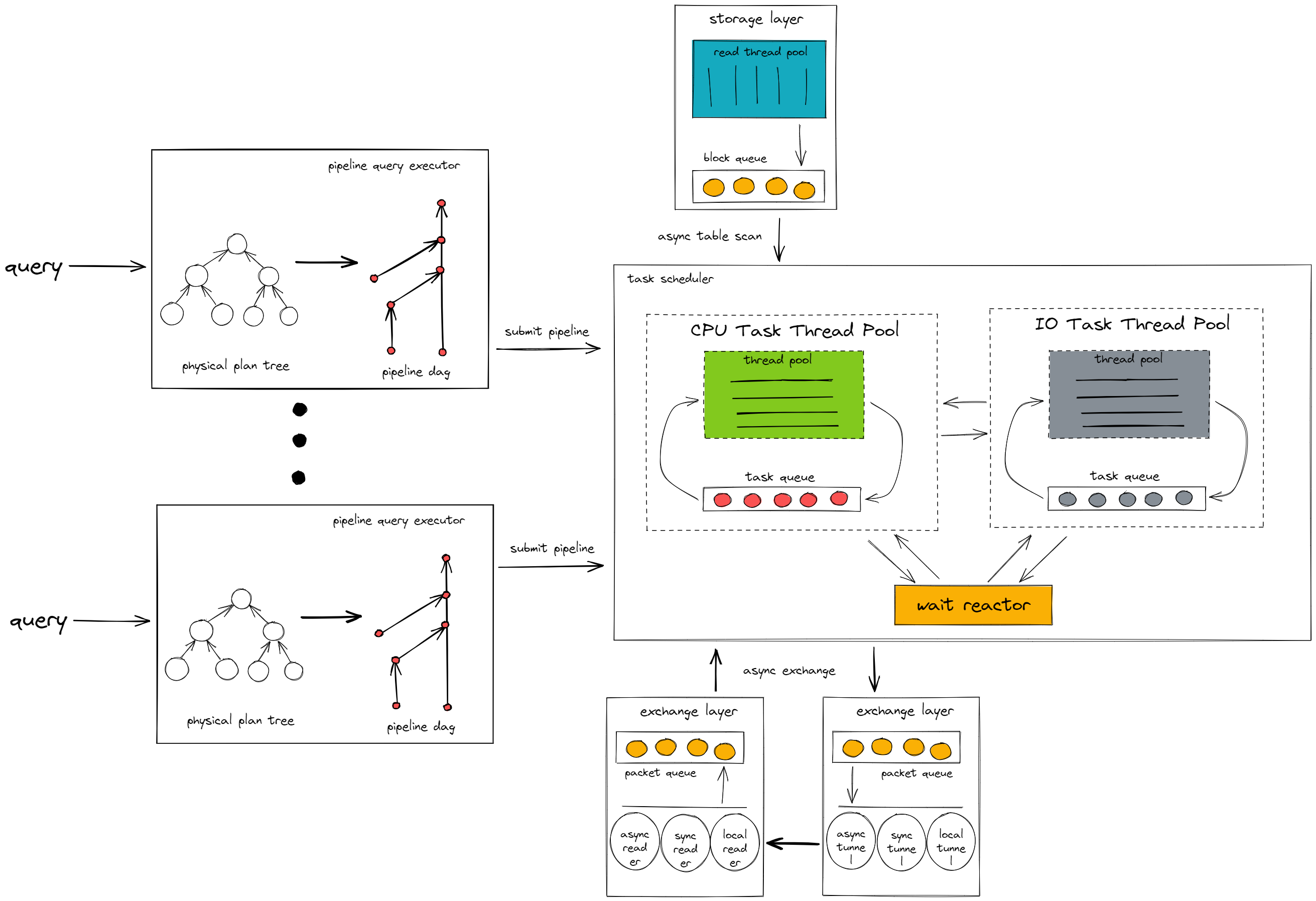
如上图所示,Pipeline Model 中有两个主要组成部分:Pipeline Query Executor 和 Task Scheduler。
Pipeline Query Executor
负责将从 TiDB 节点发过来的查询请求转换为 pipeline dag。
它会找到查询中的 pipeline breaker 算子,以 pipeline breaker 为边界将查询切分成若干个 pipeline,根据 pipeline 之间的依赖关系,将 pipeline 组装成一个有向无环图。
pipeline breaker 用于指代存在停顿/阻塞逻辑的算子,这一类算子会持续接收上游算子传来的数据块,直到所有数据块都被接收后,才会将处理结果返回给下游算子。这类算子会破坏数据处理流水线,所以被称为 pipeline breaker。pipeline breaker 的代表有 Aggregation,它会将上游算子的数据都写入到哈希表后,才对哈希表中的数据做计算返回给下游算子。
在查询被转换为 pipeline dag 后,Pipeline Query Executor 会按照依赖关系依次执行每个 pipeline。pipeline 会根据查询并发度被实例化成若干个 task 提交给 Task Scheduler 执行。
Task Scheduler
负责执行由 Pipeline Query Executor 提交过来的 task。task 会根据执行的逻辑的不同,在 Task Scheduler 里的不同组件中动态切换执行。
CPU Task Thread Pool
执行 task 中 CPU 密集型的计算逻辑,比如数据过滤、函数计算等。
IO Task Thread Pool
执行 task 中 IO 密集型的计算逻辑,比如计算中间结果落盘等。
Wait Reactor
执行 task 中的等待逻辑,比如等待网络层将数据包传输给计算层等。