集群间双向同步
本文档介绍如何将一个 TiDB 集群的数据双向同步到另一个 TiDB 集群、双向同步的实现原理、如何开启双向同步、以及如何同步 DDL 操作。
使用场景
当用户需要在两个 TiDB 集群之间双向同步数据时,可使用 TiDB Binlog 进行操作。例如要将集群 A 的数据同步到集群 B,而且要将集群 B 的数据同步到集群 A。
使用场景示例图如下:
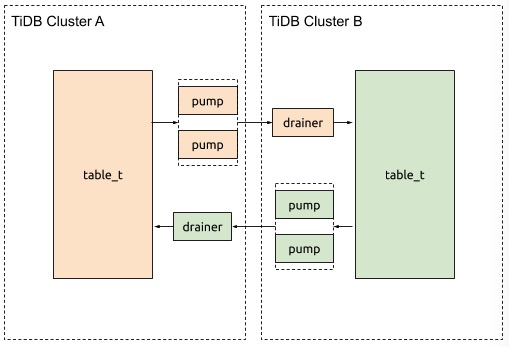
实现原理
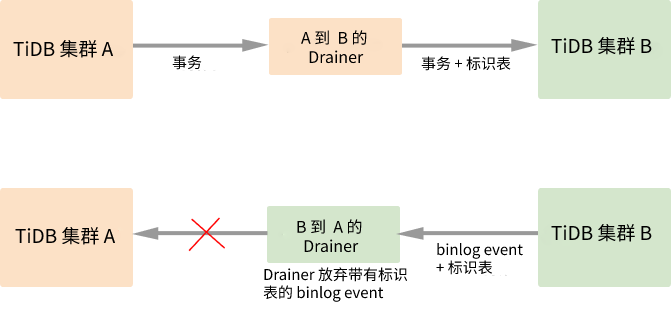
在 A 和 B 两个集群间开启双向同步,则写入集群 A 的数据会同步到集群 B 中,然后这部分数据又会继续同步到集群 A,这样就会出现无限循环同步的情况。如上图所示,在同步数据的过程中 Drainer 对 binlog 加上标记,通过过滤掉有标记的 binlog 来避免循环同步。详细的实现流程如下:
- 为两个集群分别启动 TiDB Binlog 同步程序。
- 待同步的事务经过 A 的 Drainer 时,Drainer 为事务加入
_drainer_repl_mark标识表,并在表中写入本次 DML event 更新,将事务同步至集群 B。 - 集群 B 向集群 A 返回带有
_drainer_repl_mark标识表的 binlog event。集群 B 的 Drainer 在解析该 binlog event 时发现带有 DML event 的标识表,放弃同步该 binlog event 到集群 A。
将集群 B 中的数据同步到 集群 A 的流程与以上流程相同,两个集群可以互为上下游。
Drainer 与下游的每个连接可以使用一个 ID 以避免冲突。channel_id 用来表示进行双向同步的一个通道。A 和 B 两个集群进行双向同步的配置应使用相同的值。
当有添加或者删除列时,要同步到下游的数据可能会出现多列或者少列的情况。Drainer 通过添加配置来允许这种情况,会忽略多了的列值或者给少了的列写入默认值。
标识表
_drainer_repl_mark 标识表的结构如下:
CREATE TABLE `_drainer_repl_mark` (
`id` bigint(20) NOT NULL,
`channel_id` bigint(20) NOT NULL DEFAULT '0',
`val` bigint(20) DEFAULT '0',
`channel_info` varchar(64) DEFAULT NULL,
PRIMARY KEY (`id`,`channel_id`)
);
Drainer 使用如下 SQL 语句更新 _drainer_repl_mark 可保证数据改动,从而保证产生 binlog:
update drainer_repl_mark set val = val + 1 where id = ? && channel_id = ?;
同步 DDL
因为 Drainer 无法为 DDL 操作加入标识表,所以采用单向同步的方式来同步 DDL 操作。
比如集群 A 到集群 B 开启了 DDL 同步,则集群 B 到集群 A 会关闭 DDL 同步。即 DDL 操作全部在 A 上执行。
配置并开启双向同步
若要在集群 A 和集群 B 间进行双向同步,假设统一在集群 A 上执行 DDL。在集群 A 到集群 B 的同步路径上,向 Drainer 添加以下配置:
[syncer]
loopback-control = true
channel-id = 1 # 互相同步的两个集群配置相同的 ID。
sync-ddl = true # 需要同步 DDL 操作
[syncer.to]
# 1 表示 SyncFullColumn,2 表示 SyncPartialColumn。
# 若设为 SyncPartialColumn,Drainer 会允许下游表结构比当前要同步的数据多或者少列
# 并且去掉 SQL mode 的 STRICT_TRANS_TABLES,来允许少列的情况,并插入零值到下游。
sync-mode = 2
# 忽略 checkpoint 表。
[[syncer.ignore-table]]
db-name = "tidb_binlog"
tbl-name = "checkpoint"
在集群 B 到集群 A 的同步路径上,向 Drainer 添加以下配置:
[syncer]
loopback-control = true
channel-id = 1 # 互相同步的两个集群配置相同的 ID。
sync-ddl = false # 不需要同步 DDL 操作。
[syncer.to]
# 1 表示 SyncFullColumn,2 表示 SyncPartialColumn。
# 若设为 SyncPartialColumn,Drainer 会允许下游表结构比当前要同步的数据多或者少列
# 并且去掉 SQL mode 的 STRICT_TRANS_TABLES,来允许少列的情况,并插入零值到下游。
sync-mode = 2
# 忽略 checkpoint 表。
[[syncer.ignore-table]]
db-name = "tidb_binlog"
tbl-name = "checkpoint"