同城多数据中心部署 TiDB
作为 NewSQL 数据库,TiDB 兼顾了传统关系型数据库的优秀特性、NoSQL 数据库可扩展性以及跨数据中心场景下的高可用。本文档旨在介绍同城多数据中心部署 TiDB 方案。
了解 Raft 协议
Raft 是一种分布式一致性算法,在 TiDB 集群的多种组件中,PD 和 TiKV 都通过 Raft 实现了数据的容灾。Raft 的灾难恢复能力通过如下机制实现:
- Raft 成员的本质是日志复制和状态机。Raft 成员之间通过复制日志来实现数据同步;Raft 成员在不同条件下切换自己的成员状态,其目标是选出 leader 以提供对外服务。
- Raft 是一个表决系统,它遵循多数派协议,在一个 Raft Group 中,某成员获得大多数投票,它的成员状态就会转变为 leader。也就是说,当一个 Raft Group 还保有大多数节点 (majority) 时,它就能够选出 leader 以提供对外服务。
遵循 Raft 可靠性的特点,放到现实场景中:
- 想克服任意 1 台服务器 (host) 的故障,应至少提供 3 台服务器。
- 想克服任意 1 个机柜 (rack) 的故障,应至少提供 3 个机柜。
- 想克服任意 1 个数据中心(dc,又称机房)的故障,应至少提供 3 个数据中心。
- 想应对任意 1 个城市的灾难场景,应至少规划 3 个城市用于部署。
可见,原生 Raft 协议对于偶数副本的支持并不是很友好,考虑跨城网络延迟影响,或许同城三数据中心是最适合部署 Raft 的高可用及容灾方案。
同城三数据中心方案
同城三数据中心方案,即同城存有三个机房部署 TiDB 集群,同城三数据中心间的数据同步通过集群自身内部(Raft 协议)完成。同城三数据中心可同时对外进行读写服务,任意中心发生故障不影响数据一致性。
简易架构图
集群 TiDB、TiKV 和 PD 组件分别分布在 3 个不同的数据中心,这是最常规且高可用性最高的方案。
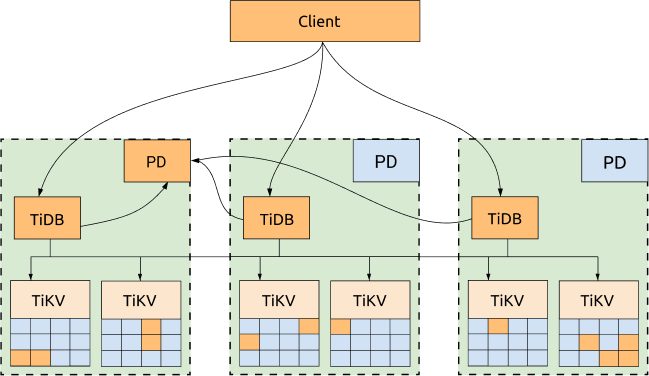
优点:
- 所有数据的副本分布在三个数据中心,具备高可用和容灾能力
- 任何一个数据中心失效后,不会产生任何数据丢失 (RPO = 0)
- 任何一个数据中心失效后,其他两个数据中心会自动发起 leader election,并在合理长的时间内(通常情况 20s 以内)自动恢复服务

缺点:
性能受网络延迟影响。具体影响如下:
- 对于写入的场景,所有写入的数据需要同步复制到至少 2 个数据中心,由于 TiDB 写入过程使用两阶段提交,故写入延迟至少需要 2 倍数据中心间的延迟。
- 对于读请求来说,如果数据 leader 与发起读取的 TiDB 节点不在同一个数据中心,也会受网络延迟影响。
- TiDB 中的每个事务都需要向 PD leader 获取 TSO,当 TiDB 与 PD leader 不在同一个数据中心时,它上面运行的事务也会因此受网络延迟影响,每个有写入的事务会获取两次 TSO。
架构优化图
如果不需要每个数据中心同时对外提供服务,可以将业务流量全部派发到一个数据中心,并通过调度策略把 Region leader 和 PD leader 都迁移到同一个数据中心。这样一来,不管是从 PD 获取 TSO,还是读取 Region,都不会受数据中心间网络的影响。当该数据中心失效后,PD leader 和 Region leader 会自动在其它数据中心选出,只需要把业务流量转移至其他存活的数据中心即可。
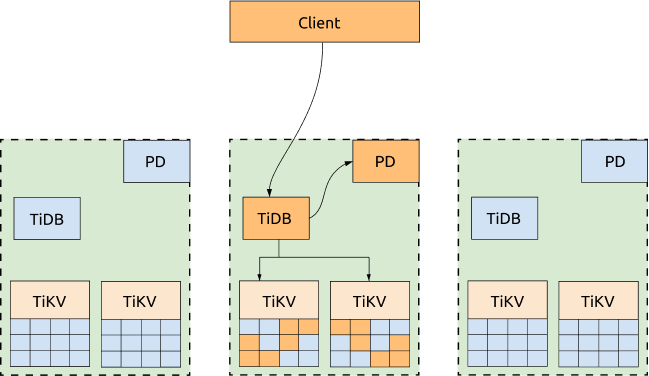
优点:
集群 TSO 获取能力以及读取性能有所提升。具体调度策略设置模板参照如下:
-- 其他机房统一驱逐 leader 到业务流量机房
config set label-property reject-leader LabelName labelValue
-- 迁移 PD leader 并设置优先级
member leader transfer pdName1
member leader_priority pdName1 5
member leader_priority pdName2 4
member leader_priority pdName3 3
缺点:
- 写入场景仍受数据中心网络延迟影响,这是因为遵循 Raft 多数派协议,所有写入的数据需要同步复制到至少 2 个数据中心
- TiDB Server 数据中心级别单点
- 业务流量纯走单数据中心,性能受限于单数据中心网络带宽压力
- TSO 获取能力以及读取性能受限于业务流量数据中心集群 PD、TiKV 组件是否正常,否则仍受跨数据中心网络交互影响
样例部署图
样例拓扑架构
下面假设某城存有 IDC1、IDC2、IDC3 三机房,机房 IDC 中存有两套机架,每个机架存有三台服务器,不考虑混布以及单台机器多实例部署下,同城三数据中心架构集群(3 副本)部署参考如下:
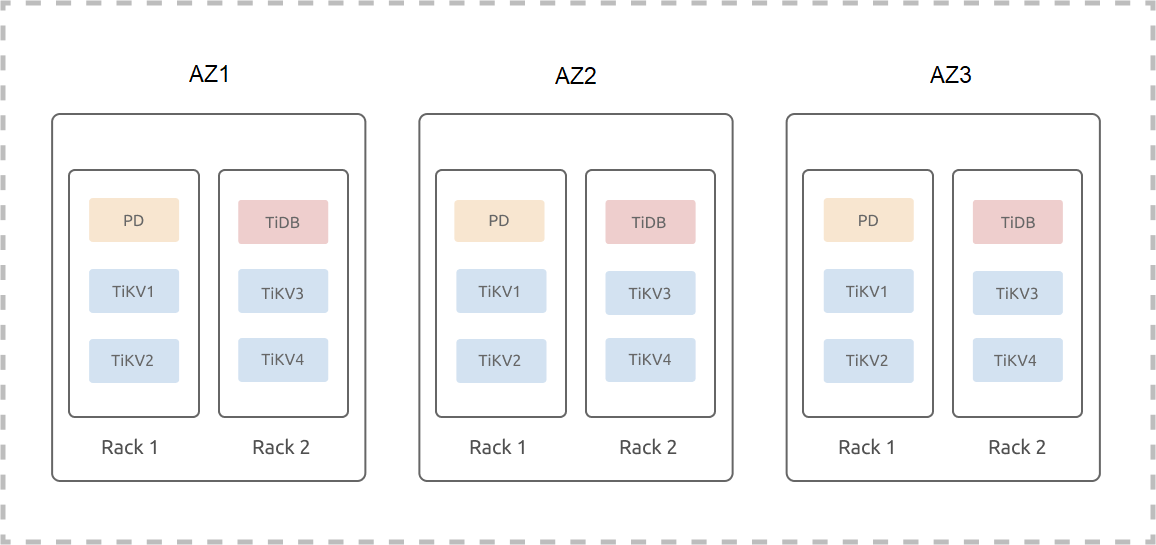
TiKV Labels 简介
TiKV 是一个 Multi-Raft 系统,其数据按 Region(默认 96M)切分,每个 Region 的 3 个副本构成了一个 Raft Group。假设一个 3 副本 TiDB 集群,由于 Region 的副本数与 TiKV 实例数量无关,则一个 Region 的 3 个副本只会被调度到其中 3 个 TiKV 实例上,也就是说即使集群扩容 N 个 TiKV 实例,其本质仍是一个 3 副本集群。
由于 3 副本的 Raft Group 只能容忍 1 副本故障,当集群被扩容到 N 个 TiKV 实例时,这个集群依然只能容忍一个 TiKV 实例的故障。2 个 TiKV 实例的故障可能会导致某些 Region 丢失多个副本,整个集群的数据也不再完整,访问到这些 Region 上的数据的 SQL 请求将会失败。而 N 个 TiKV 实例中同时有两个发生故障的概率是远远高于 3 个 TiKV 中同时有两个发生故障的概率的,也就是说 Multi-Raft 系统集群扩容 TiKV 实例越多,其可用性是逐渐降低的。
正因为 Multi-Raft TiKV 系统局限性,Labels 标签应运而出,其主要用于描述 TiKV 的位置信息。Label 信息随着部署或滚动更新操作刷新到 TiKV 的启动配置文件中,启动后的 TiKV 会将自己最新的 Label 信息上报给 PD,PD 根据用户登记的 Label 名称(也就是 Label 元信息),结合 TiKV 的拓扑进行 Region 副本的最优调度,从而提高系统可用性。
TiKV Labels 样例规划
针对 TiKV Labels 标签,你需要根据已有的物理资源、容灾能力容忍度等方面进行设计与规划,进而提升系统的可用性和容灾能力。并根据已规划的拓扑架构,在集群初始化配置文件中进行配置(此处省略其他非重点项):
server_configs:
pd:
replication.location-labels: ["zone","dc","rack","host"]
tikv_servers:
- host: 10.63.10.30
config:
server.labels: { zone: "z1", dc: "d1", rack: "r1", host: "30" }
- host: 10.63.10.31
config:
server.labels: { zone: "z1", dc: "d1", rack: "r1", host: "31" }
- host: 10.63.10.32
config:
server.labels: { zone: "z1", dc: "d1", rack: "r2", host: "32" }
- host: 10.63.10.33
config:
server.labels: { zone: "z1", dc: "d1", rack: "r2", host: "33" }
- host: 10.63.10.34
config:
server.labels: { zone: "z2", dc: "d1", rack: "r1", host: "34" }
- host: 10.63.10.35
config:
server.labels: { zone: "z2", dc: "d1", rack: "r1", host: "35" }
- host: 10.63.10.36
config:
server.labels: { zone: "z2", dc: "d1", rack: "r2", host: "36" }
- host: 10.63.10.37
config:
server.labels: { zone: "z2", dc: "d1", rack: "r2", host: "37" }
- host: 10.63.10.38
config:
server.labels: { zone: "z3", dc: "d1", rack: "r1", host: "38" }
- host: 10.63.10.39
config:
server.labels: { zone: "z3", dc: "d1", rack: "r1", host: "39" }
- host: 10.63.10.40
config:
server.labels: { zone: "z3", dc: "d1", rack: "r2", host: "40" }
- host: 10.63.10.41
config:
server.labels: { zone: "z3", dc: "d1", rack: "r2", host: "41" }
本例中,zone 表示逻辑可用区层级,用于控制副本的隔离(当前集群 3 副本)。
不直接采用 dc,rack,host 三层 Label 结构的原因是考虑到将来可能发生 dc(数据中心)的扩容,假设新扩容的 dc 编号是 d2,d3,d4,则只需在对应可用区下扩容 dc;rack 扩容只需在对应 dc 下扩容即可。
如果直接采用 dc,rack,host 三层 Label 结构,那么扩容 dc 操作可能需重打 Label,TiKV 数据整体需要 Rebalance。
高可用和容灾分析
同城多数据中心方案提供的保障是,任意一个数据中心故障时,集群能自动恢复服务,不需要人工介入,并能保证数据一致性。注意,各种调度策略都是用于帮助性能优化的,当发生故障时,调度机制总是第一优先考虑可用性而不是性能。