管理迁移表的表结构
本文介绍如何使用 dmctl 组件来管理通过 DM 迁移的表在 DM 内部的表结构。
原理介绍
在使用 DM 迁移数据表时,DM 对于表结构主要包含以下相关处理。
对于全量导出与导入,DM 直接导出当前时刻上游的表结构到 SQL 格式的文件中,并将该表结构直接应用到下游。
对于增量复制,在整个数据链路中则包含以下几类可能相同或不同的表结构。
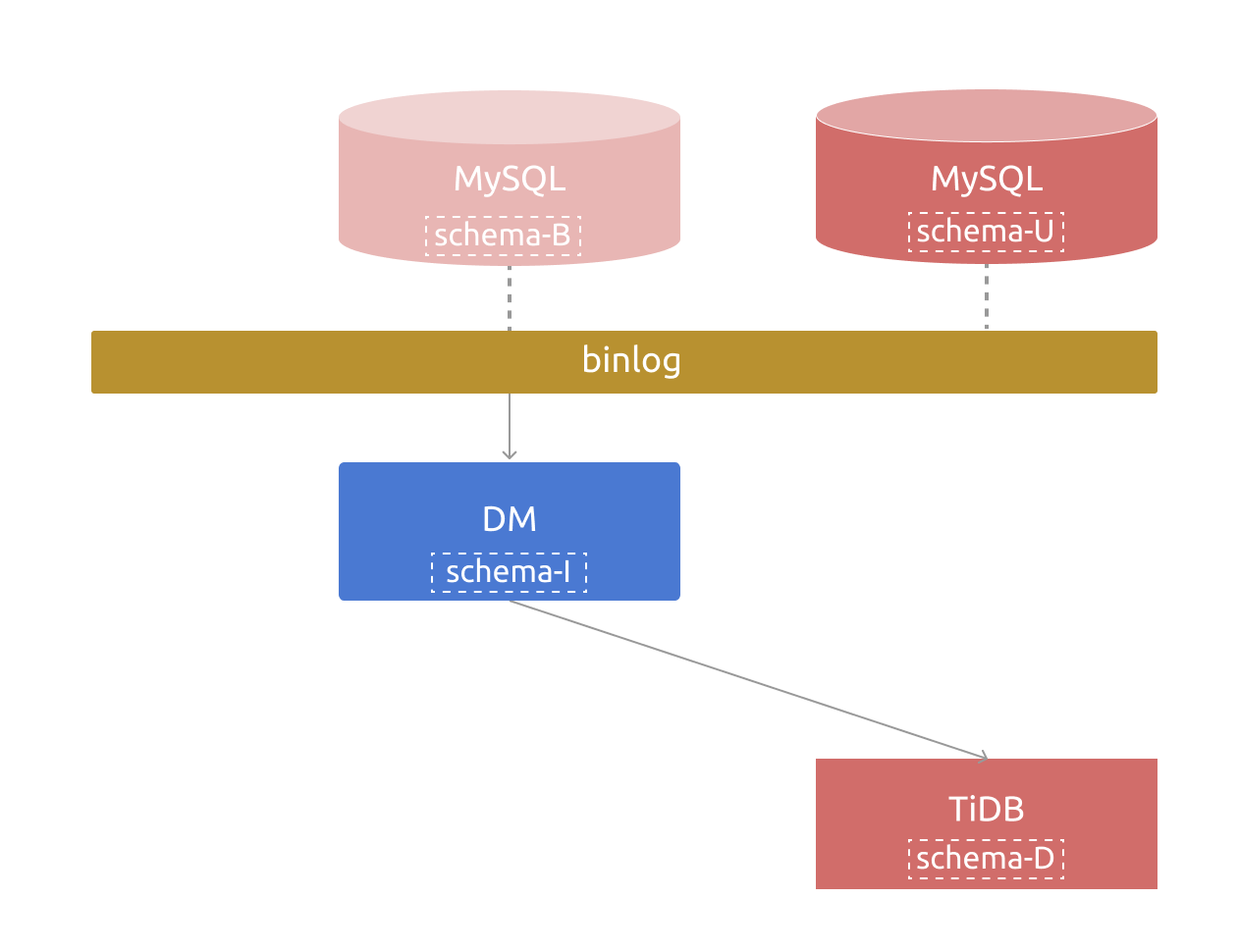
- 上游当前时刻的表结构(记为
schema-U)。 - 当前 DM 正在消费的 binlog event 的表结构(记为
schema-B,其对应于上游某个历史时刻的表结构)。 - DM 内部(schema tracker 组件)当前维护的表结构(记为
schema-I)。 - 下游 TiDB 集群中的表结构(记为
schema-D)。
在大多数情况下,以上 4 类表结构一致。
当上游执行 DDL 变更表结构后,schema-U 即会发生变更;DM 通过将该 DDL 应用于内部的 schema tracker 组件及下游 TiDB,会先后更新 schema-I、schema-D 以与 schema-U 保持一致,因而随后能正常消费 binlog 中在 DDL 之后对应表结构为 schema-B 的 binlog event。即当 DDL 被复制成功后,仍能保持 schema-U、schema-B、schema-I 及 schema-D 的一致。
但在开启乐观 shard DDL 支持 的数据迁移过程中,下游合并表的 schema-D 可能与部分分表对应的 schema-B 及 schema-I 并不一致,但 DM 仍保持 schema-I 与 schema-B 的一致以确保能正常解析 DML 对应的 binlog event。
此外,在其他一些场景下(如:下游比上游多部分列),schema-D 也可能会与 schema-B 及 schema-I 并不一致。
为了支持以上的特殊场景及处理其他可能的由于 schema 不匹配导致的迁移中断等问题,DM 提供了 operate-schema 命令来获取、修改、删除 DM 内部维护的表结构 schema-I。
命令介绍
help operate-schema
`get`/`set`/`remove` the schema for an upstream table.
Usage:
dmctl operate-schema <operate-type> <-s source ...> <task-name | task-file> <-d database> <-t table> [schema-file] [--flush] [--sync] [flags]
Flags:
-d, --database string database name of the table
--flush flush the table info and checkpoint immediately
-h, --help help for operate-schema
--sync sync the table info to master to resolve shard ddl lock, only for optimistic mode now
-t, --table string table name
Global Flags:
-s, --source strings MySQL Source ID.
参数解释
operate-type:- 必选
- 指定对于 schema 的操作类型,可以为
get、set或remove
-s:- 必选
- 指定操作将应用到的 MySQL 源
task-name | task-file:- 必选
- 指定任务名称或任务文件路径
-d:- 必选
- 指定数据表所属的上游数据库名
-t:- 必选
- 指定数据表对应的上游表名
schema-file:set操作时必选,其他操作不需指定- 将被设置的表结构文件,文件内容应为一个合法的
CREATE TABLE语句
--flush:- 可选
- 同时将表结构写入 checkpoint,从而在任务重启后加载到该表结构
- 默认值为
true
--sync:- 可选
- 仅在乐观协调 DDL 出错时使用。使用该表结构更新乐观协调元数据中的表结构
使用示例
获取表结构
假设要获取 db_single 任务对应于 mysql-replica-01 MySQL 源的 `db_single`.`t1` 表的表结构,则执行如下命令:
operate-schema get -s mysql-replica-01 task_single -d db_single -t t1
{
"result": true,
"msg": "",
"sources": [
{
"result": true,
"msg": "CREATE TABLE `t1` ( `c1` int(11) NOT NULL, `c2` int(11) DEFAULT NULL, PRIMARY KEY (`c1`)) ENGINE=InnoDB DEFAULT CHARSET=latin1 COLLATE=latin1_bin",
"source": "mysql-replica-01",
"worker": "127.0.0.1:8262"
}
]
}
设置表结构
假设要设置 db_single 任务对应于 mysql-replica-01 MySQL 源的 `db_single`.`t1` 表的表结构为
CREATE TABLE `t1` (
`c1` int(11) NOT NULL,
`c2` bigint(11) DEFAULT NULL,
PRIMARY KEY (`c1`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1 COLLATE=latin1_bin
则将上述 CREATE TABLE 语句保存为文件(如 db_single.t1-schema.sql)后执行如下命令:
operate-schema set -s mysql-replica-01 task_single -d db_single -t t1 db_single.t1-schema.sql
{
"result": true,
"msg": "",
"sources": [
{
"result": true,
"msg": "",
"source": "mysql-replica-01",
"worker": "127.0.0.1:8262"
}
]
}
删除表结构
假设要删除 db_single 任务对应于 mysql-replica-01 MySQL 源的 `db_single`.`t1` 表的表结构,则执行如下命令:
operate-schema remove -s mysql-replica-01 task_single -d db_single -t t1
{
"result": true,
"msg": "",
"sources": [
{
"result": true,
"msg": "",
"source": "mysql-replica-01",
"worker": "127.0.0.1:8262"
}
]
}