RocksDB 简介
RocksDB 是由 Facebook 基于 LevelDB 开发的一款提供键值存储与读写功能的 LSM-tree 架构引擎。用户写入的键值对会先写入磁盘上的 WAL (Write Ahead Log),然后再写入内存中的跳表(SkipList,这部分结构又被称作 MemTable)。LSM-tree 引擎由于将用户的随机修改(插入)转化为了对 WAL 文件的顺序写,因此具有比 B 树类存储引擎更高的写吞吐。
内存中的数据达到一定阈值后,会刷到磁盘上生成 SST 文件 (Sorted String Table),SST 又分为多层(默认至多 6 层),每一层的数据达到一定阈值后会挑选一部分 SST 合并到下一层,每一层的数据是上一层的 10 倍(因此 90% 的数据存储在最后一层)。
RocksDB 允许用户创建多个 ColumnFamily ,这些 ColumnFamily 各自拥有独立的内存跳表以及 SST 文件,但是共享同一个 WAL 文件,这样的好处是可以根据应用特点为不同的 ColumnFamily 选择不同的配置,但是又没有增加对 WAL 的写次数。
TiKV 架构
TiKV 的系统架构如下图所示:
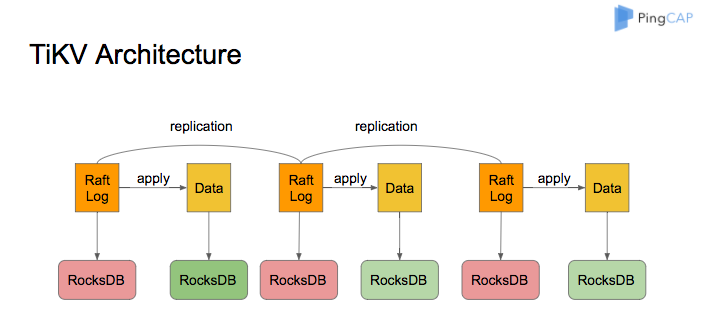
RocksDB 作为 TiKV 的核心存储引擎,用于存储 Raft 日志以及用户数据。每个 TiKV 实例中有两个 RocksDB 实例,一个用于存储 Raft 日志(通常被称为 raftdb),另一个用于存储用户数据以及 MVCC 信息(通常被称为 kvdb)。kvdb 中有四个 ColumnFamily:raft、lock、default 和 write:
- raft 列:用于存储各个 Region 的元信息。仅占极少量空间,用户可以不必关注。
- lock 列:用于存储悲观事务的悲观锁以及分布式事务的一阶段 Prewrite 锁。当用户的事务提交之后,lock cf 中对应的数据会很快删除掉,因此大部分情况下 lock cf 中的数据也很少(少于 1GB)。如果 lock cf 中的数据大量增加,说明有大量事务等待提交,系统出现了 bug 或者故障。
- write 列:用于存储用户真实的写入数据以及 MVCC 信息(该数据所属事务的开始时间以及提交时间)。当用户写入了一行数据时,如果该行数据长度小于 255 字节,那么会被存储 write 列中,否则的话该行数据会被存入到 default 列中。由于 TiDB 的非 unique 索引存储的 value 为空,unique 索引存储的 value 为主键索引,因此二级索引只会占用 writecf 的空间。
- default 列:用于存储超过 255 字节长度的数据。
RocksDB 的内存占用
为了提高读取性能以及减少对磁盘的读取,RocksDB 将存储在磁盘上的文件都按照一定大小切分成 block(默认是 64KB),读取 block 时先去内存中的 BlockCache 中查看该块数据是否存在,存在的话则可以直接从内存中读取而不必访问磁盘。
BlockCache 按照 LRU 算法淘汰低频访问的数据,TiKV 默认将系统总内存大小的 45% 用于 BlockCache,用户也可以自行修改 storage.block-cache.capacity 配置设置为合适的值,但是不建议超过系统总内存的 60%。
写入 RocksDB 中的数据会写入 MemTable,当一个 MemTable 的大小超过 128MB 时,会切换到一个新的 MemTable 来提供写入。TiKV 中一共有 2 个 RocksDB 实例,合计 4 个 ColumnFamily,每个 ColumnFamily 的单个 MemTable 大小限制是 128MB,最多允许 5 个 MemTable 存在,否则会阻塞前台写入,因此这部分占用的内存最多为 4 x 5 x 128MB = 2.5GB。这部分占用内存较少,不建议用户自行更改。
RocksDB 的空间占用
- 多版本:RocksDB 作为一个 LSM-tree 结构的键值存储引擎,MemTable 中的数据会首先被刷到 L0。L0 层的 SST 之间的范围可能存在重叠(因为文件顺序是按照生成的顺序排列),因此同一个 key 在 L0 中可能存在多个版本。当文件从 L0 合并到 L1 的时候,会按照一定大小(默认是 8MB)切割为多个文件,同一层的文件的范围互不重叠,所以 L1 及其以后的层每一层的 key 都只有一个版本。
- 空间放大:RocksDB 的每一层文件总大小都是上一层的 x 倍,在 TiKV 中这个配置默认是 10,因此 90% 的数据存储在最后一层,这也意味着 RocksDB 的空间放大不超过 1.11(L0 层的数据较少,可以忽略不计)。
- TiKV 的空间放大:TiKV 在 RocksDB 之上还有一层自己的 MVCC,当用户写入一个 key 的时候,实际上写入到 RocksDB 的是 key + commit_ts,也就是说,用户的更新和删除都是会写入新的 key 到 RocksDB。TiKV 每隔一段时间会删除旧版本的数据(通过 RocksDB 的 Delete 接口),因此可以认为用户存储在 TiKV 上的数据的实际空间放大为,1.11 加最近 10 分钟内写入的数据(假设 TiKV 回收旧版本数据足够及时)。详情见《TiDB in Action》。
RocksDB 后台线程与 Compact
RocksDB 中,将内存中的 MemTable 转化为磁盘上的 SST 文件,以及合并各个层级的 SST 文件等操作都是在后台线程池中执行的。后台线程池的默认大小是 8,当机器 CPU 数量小于等于 8 时,则后台线程池默认大小为 CPU 数量减一。通常来说,用户不需要更改这个配置。如果用户在一个机器上部署了多个 TiKV 实例,或者机器的读负载比较高而写负载比较低,那么可以适当调低 rocksdb/max-background-jobs 至 3 或者 4。
WriteStall
RocksDB 的 L0 与其他层不同,L0 的各个 SST 是按照生成顺序排列,各个 SST 之间的 key 范围存在重叠,因此查询的时候必须依次查询 L0 中的每一个 SST。为了不影响查询性能,当 L0 中的文件数量过多时,会触发 WriteStall 阻塞写入。
如果用户遇到了写延迟突然大幅度上涨,可以先查看 Grafana RocksDB KV 面板 WriteStall Reason 指标,如果是 L0 文件数量过多引起的 WriteStall,可以调整下面几个配置到 64,详细见 《TiDB in Action》。
rocksdb.defaultcf.level0-slowdown-writes-trigger
rocksdb.writecf.level0-slowdown-writes-trigger
rocksdb.lockcf.level0-slowdown-writes-trigger
rocksdb.defaultcf.level0-stop-writes-trigger
rocksdb.writecf.level0-stop-writes-trigger
rocksdb.lockcf.level0-stop-writes-trigger