Syncer 使用文档
Syncer 简介
Syncer 是一个数据导入工具,能方便地将 MySQL 的数据增量导入到 TiDB。
Syncer 包含在 tidb-enterprise-tools 安装包中,可在此下载。
Syncer 架构
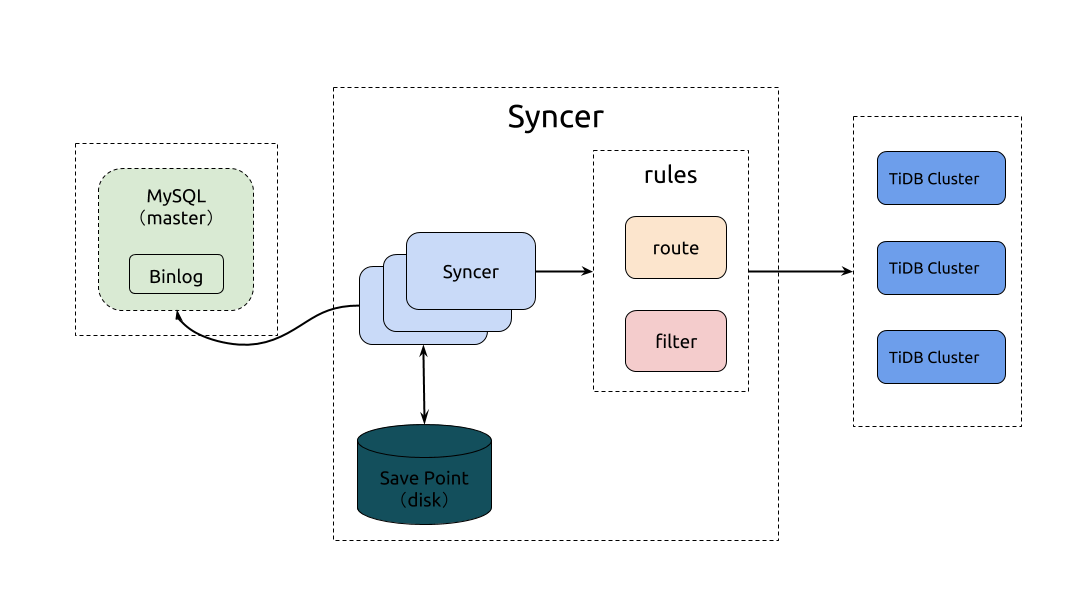
Syncer 部署位置
Syncer 可以部署在任一台可以连通对应的 MySQL 和 TiDB 集群的机器上,推荐部署在 TiDB 集群。
Syncer 增量导入数据示例
使用前请详细阅读 Syncer 同步前预检查。
设置同步开始的 position
设置 Syncer 的 meta 文件, 这里假设 meta 文件是 syncer.meta:
cat syncer.meta
binlog-name = "mysql-bin.000003"
binlog-pos = 930143241
binlog-gtid = "2bfabd22-fff7-11e6-97f7-f02fa73bcb01:1-23,61ccbb5d-c82d-11e6-ac2e-487b6bd31bf7:1-4"
启动 Syncer
Syncer 的命令行参数说明:
Usage of syncer:
-L string
日志等级: debug, info, warn, error, fatal (默认为 "info")
-V
输出 Syncer 版本;默认 false
-auto-fix-gtid
当 mysql master/slave 切换时,自动修复 gtid 信息;默认 false
-b int
batch 事务大小 (默认 100)
-c int
Syncer 处理 batch 线程数 (默认 16)
-config string
指定相应配置文件启动 Sycner 服务;如 `--config config.toml`
-enable-ansi-quotes
使用 ANSI_QUOTES sql_mode 来解析 SQL 语句
-enable-gtid
使用 gtid 模式启动 Syncer;默认 false,开启前需要上游 MySQL 开启 GTID 功能
-flavor string
上游数据库实例类型,目前支持 "mysql" 和 "mariadb"
-log-file string
指定日志文件目录;如 `--log-file ./syncer.log`
-log-rotate string
指定日志切割周期, hour/day (默认 "day")
-max-retry int
SQL 请求由于网络异常等原因出错时的最大重试次数(默认值为 100)
-meta string
指定 Syncer 上游 meta 信息文件 (默认与配置文件相同目录下 "syncer.meta")
-persistent-dir string
指定同步过程中历史 schema 结构的保存文件地址,如果设置为空,则不保存历史 schema 结构;如果不为空,则根据 binlog 里面包含的数据的 column 长度选择 schema 来还原 DML 语句
-safe-mode
指定是否开启 safe mode,让 Syncer 在任何情况下可重入
-server-id int
指定 MySQL slave sever-id (默认 101)
-status-addr string
指定 syncer metric 信息; 如 `--status-addr 127:0.0.1:10088`
-timezone string
目标数据库使用的时区,请使用 IANA 时区标识符,如 `Asia/Shanghai`
Syncer 的配置文件 config.toml:
log-level = "info"
log-file = "syncer.log"
log-rotate = "day"
server-id = 101
## meta 文件地址
meta = "./syncer.meta"
worker-count = 16
batch = 100
flavor = "mysql"
## Prometheus 可以通过该地址拉取 Syncer metrics,也是 Syncer 的 pprof 调试地址
status-addr = ":8271"
## 如果设置为 true,Syncer 遇到 DDL 语句时就会停止退出
stop-on-ddl = false
## SQL 请求由于网络异常等原因出错时的最大重试次数
max-retry = 100
## 指定目标数据库使用的时区,binlog 中所有 timestamp 字段会按照该时区进行转换,默认使用 Syncer 本地时区
# timezone = "Asia/Shanghai"
## 跳过 DDL 语句,格式为 **前缀完全匹配**,如:`DROP TABLE ABC` 至少需要填入 `DROP TABLE`
# skip-ddls = ["ALTER USER", "CREATE USER"]
## 在使用 route-rules 功能后,
## replicate-do-db & replicate-ignore-db 匹配合表之后 (target-schema & target-table) 数值
## 优先级关系: replicate-do-db --> replicate-do-table --> replicate-ignore-db --> replicate-ignore-table
## 指定要同步数据库名;支持正则匹配,表达式语句必须以 `~` 开始
#replicate-do-db = ["~^b.*","s1"]
## 指定 **忽略** 同步数据库;支持正则匹配,表达式语句必须以 `~` 开始
#replicate-ignore-db = ["~^b.*","s1"]
# skip-dmls 支持跳过 DML binlog events,type 字段的值可为:'insert','update' 和 'delete'
# 跳过 foo.bar 表的所有 delete 语句
# [[skip-dmls]]
# db-name = "foo"
# tbl-name = "bar"
# type = "delete"
#
# 跳过所有表的 delete 语句
# [[skip-dmls]]
# type = "delete"
#
# 跳过 foo.* 表的 delete 语句
# [[skip-dmls]]
# db-name = "foo"
# type = "delete"
## 指定要同步的 db.table 表
## db-name 与 tbl-name 不支持 `db-name ="dbname,dbname2"` 格式
#[[replicate-do-table]]
#db-name ="dbname"
#tbl-name = "table-name"
#[[replicate-do-table]]
#db-name ="dbname1"
#tbl-name = "table-name1"
## 指定要同步的 db.table 表;支持正则匹配,表达式语句必须以 `~` 开始
#[[replicate-do-table]]
#db-name ="test"
#tbl-name = "~^a.*"
## 指定 **忽略** 同步数据库
## db-name & tbl-name 不支持 `db-name ="dbname,dbname2"` 语句格式
#[[replicate-ignore-table]]
#db-name = "your_db"
#tbl-name = "your_table"
## 指定要 **忽略** 同步数据库名;支持正则匹配,表达式语句必须以 `~` 开始
#[[replicate-ignore-table]]
#db-name ="test"
#tbl-name = "~^a.*"
# sharding 同步规则,采用 wildcharacter
# 1. 星号字符 (*) 可以匹配零个或者多个字符,
# 例子, doc* 匹配 doc 和 document, 但是和 dodo 不匹配;
# 星号只能放在 pattern 结尾,并且一个 pattern 中只能有一个
# 2. 问号字符 (?) 匹配任一一个字符
#[[route-rules]]
#pattern-schema = "route_*"
#pattern-table = "abc_*"
#target-schema = "route"
#target-table = "abc"
#[[route-rules]]
#pattern-schema = "route_*"
#pattern-table = "xyz_*"
#target-schema = "route"
#target-table = "xyz"
[from]
host = "127.0.0.1"
user = "root"
password = ""
port = 3306
[to]
host = "127.0.0.1"
user = "root"
password = ""
port = 4000
启动 Syncer:
./bin/syncer -config config.toml
2016/10/27 15:22:01 binlogsyncer.go:226: [info] begin to sync binlog from position (mysql-bin.000003, 1280)
2016/10/27 15:22:01 binlogsyncer.go:130: [info] register slave for master server 127.0.0.1:3306
2016/10/27 15:22:01 binlogsyncer.go:552: [info] rotate to (mysql-bin.000003, 1280)
2016/10/27 15:22:01 syncer.go:549: [info] rotate binlog to (mysql-bin.000003, 1280)
在 MySQL 中插入新的数据
INSERT INTO t1 VALUES (4, 4), (5, 5);
登录到 TiDB 查看:
mysql -h127.0.0.1 -P4000 -uroot -p
select * from t1;
+----+------+
| id | age |
+----+------+
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
| 4 | 4 |
| 5 | 5 |
+----+------+
Syncer 每隔 30s 会输出当前的同步统计,如下所示:
2017/06/08 01:18:51 syncer.go:934: [info] [syncer]total events = 15, total tps = 130, recent tps = 4,
master-binlog = (ON.000001, 11992), master-binlog-gtid=53ea0ed1-9bf8-11e6-8bea-64006a897c73:1-74,
syncer-binlog = (ON.000001, 2504), syncer-binlog-gtid = 53ea0ed1-9bf8-11e6-8bea-64006a897c73:1-17
2017/06/08 01:19:21 syncer.go:934: [info] [syncer]total events = 15, total tps = 191, recent tps = 2,
master-binlog = (ON.000001, 11992), master-binlog-gtid=53ea0ed1-9bf8-11e6-8bea-64006a897c73:1-74,
syncer-binlog = (ON.000001, 2504), syncer-binlog-gtid = 53ea0ed1-9bf8-11e6-8bea-64006a897c73:1-35
由上述示例可见,使用 Syncer 可以自动将 MySQL 的更新同步到 TiDB。
Syncer 配置说明
指定数据库同步
本部分将通过实际案例描述 Syncer 同步数据库参数的优先级关系。
- 如果使用 route-rules 规则,参考 Sharding 同步支持
- 优先级:replicate-do-db --> replicate-do-table --> replicate-ignore-db --> replicate-ignore-table
# 指定同步 ops 数据库
# 指定同步以 ti 开头的数据库
replicate-do-db = ["ops","~^ti.*"]
# china 数据库下有 guangzhou / shanghai / beijing 等多张表,只同步 shanghai 与 beijing 表。
# 指定同步 china 数据库下 shanghai 表
[[replicate-do-table]]
db-name ="china"
tbl-name = "shanghai"
# 指定同步 china 数据库下 beijing 表
[[replicate-do-table]]
db-name ="china"
tbl-name = "beijing"
# ops 数据库下有 ops_user / ops_admin / weekly 等数据表,只需要同步 ops_user 表。
# 因 replicate-do-db 优先级比 replicate-do-table 高,所以此处设置只同步 ops_user 表无效,实际工作会同步 ops 整个数据库
[[replicate-do-table]]
db-name ="ops"
tbl-name = "ops_user"
# history 数据下有 2017_01 2017_02 ... 2017_12 / 2016_01 2016_02 ... 2016_12 等多张表,只需要同步 2017 年的数据表
[[replicate-do-table]]
db-name ="history"
tbl-name = "~^2017_.*"
# 忽略同步 ops 与 fault 数据库
# 忽略同步以 www 开头的数据库
## 因 replicate-do-db 优先级比 replicate-ignore-db 高,所以此处忽略同步 ops 不生效。
replicate-ignore-db = ["ops","fault","~^www"]
# fault 数据库下有 faults / user_feedback / ticket 等数据表
# 忽略同步 user_feedback 数据表
# 因 replicate-ignore-db 优先级比 replicate-ignore-table 高,所以此处设置只忽略同步 user_feedback 表无效,实际工作会忽略同步 fault 整个数据库
[[replicate-ignore-table]]
db-name = "fault"
tbl-name = "user_feedback"
# order 数据下有 2017_01 2017_02 ... 2017_12 / 2016_01 2016_02 ... 2016_12 等多张表,忽略 2016 年的数据表
[[replicate-ignore-table]]
db-name ="order"
tbl-name = "~^2016_.*"
Sharding 同步支持
根据配置文件的 route-rules,支持将分库分表的数据导入到同一个库同一个表中,但是在开始前需要检查分库分表规则,如下:
- 是否可以利用 route-rules 的语义规则表示
- 分表中是否包含唯一递增主键,或者合并后是否包含数据上有冲突的唯一索引或者主键
暂时对 DDL 支持不完善。
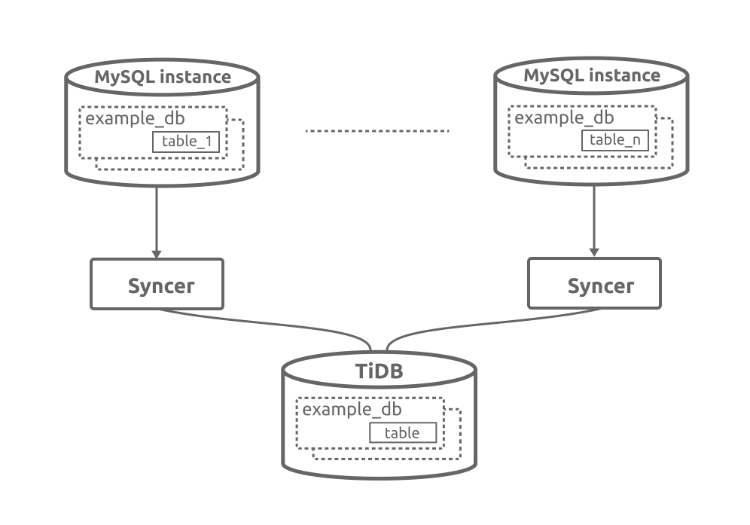
分库分表同步示例
- 只需在所有 MySQL 实例下面,启动 Syncer, 并设置 route-rules。
replicate-do-db&replicate-ignore-db与 route-rules 同时使用场景下,replicate-do-db&replicate-ignore-db需要指定 route-rules 中target-schema&target-table的内容。
# 场景如下:
# 数据库A 下有 order_2016 / history_2016 等多个数据库
# 数据库B 下有 order_2017 / history_2017 等多个数据库
# 指定同步数据库A order_2016 数据库,数据表如下 2016_01 2016_02 ... 2016_12
# 指定同步数据库B order_2017 数据库,数据表如下 2017_01 2017_02 ... 2017_12
# 表内使用 order_id 作为主键,数据之间主键不冲突
# 忽略同步 history_2016 与 history_2017 数据库
# 目标库需要为 order ,目标数据表为 order_2017 / order_2016
# Syncer 获取到上游数据后,发现 route-rules 规则启用,先做合库合表操作,再进行 do-db & do-table 判定
## 此处需要设置 target-schema & target-table 判定需要同步的数据库
[[replicate-do-table]]
db-name ="order"
tbl-name = "order_2016"
[[replicate-do-table]]
db-name ="order"
tbl-name = "order_2017"
[[route-rules]]
pattern-schema = "order_2016"
pattern-table = "2016_??"
target-schema = "order"
target-table = "order_2016"
[[route-rules]]
pattern-schema = "order_2017"
pattern-table = "2017_??"
target-schema = "order"
target-table = "order_2017"
Syncer 同步前检查
检查数据库版本。
使用
select @@version;命令检查数据库版本。目前,Syncer 只支持以下版本:- 5.5 < MySQL 版本 < 8.0
- MariaDB 版本 >= 10.1.2(更早版本的 binlog 部分字段类型格式与 MySQL 不一致)
检查源库
server-id。可通过以下命令查看
server-id:show global variables like 'server_id';+---------------+-------+ | Variable_name | Value | +---------------+-------+ | server_id | 1 | +---------------+-------+ 1 row in set (0.01 sec)- 结果为空或者为 0,Syncer 无法同步数据。
- Syncer
server-id与 MySQLserver-id不能相同,且必须在 MySQL cluster 中唯一。
检查 Binlog 相关参数。
检查 MySQL 是否开启了 binlog。
使用如下命令确认是否开启了 binlog:
show global variables like 'log_bin';+--------------------+---------+ | Variable_name | Value | +--------------------+---------+ | log_bin | ON | +--------------------+---------+ 1 row in set (0.00 sec)如果结果是
log_bin=OFF,则需要开启 binlog,开启方式请参考官方文档。binlog 格式必须为
ROW,且参数binlog_row_image必须设置为FULL,可使用如下命令查看参数设置:select variable_name, variable_value from information_schema.global_variables where variable_name in ('binlog_format','binlog_row_image');+------------------+----------------+ | variable_name | variable_value | +------------------+----------------+ | BINLOG_FORMAT | ROW | | BINLOG_ROW_IMAGE | FULL | +------------------+----------------+ 2 rows in set (0.001 sec)- 如果以上设置出现错误,则需要修改磁盘上的配置文件,然后重启 MySQL。
- 将配置的更改持久化存储在磁盘上很重要,这样在 MySQL 重启之后才能显示相应更改。
- 由于现有的连接会保留全局变量原先的值,所以不可以使用
SET语句动态修改这些设置。
检查用户权限。
全量导出的 Mydumper 需要的用户权限。
- Mydumper 导出数据至少拥有以下权限:
select, reload。 - Mydumper 操作对象为 RDS 时,可以添加
--no-locks参数,避免申请reload权限。
- Mydumper 导出数据至少拥有以下权限:
增量同步 Syncer 需要的上游 MySQL/MariaDB 用户权限。
需要上游 MySQL 同步账号至少赋予以下权限:
select, replication slave, replication client下游 TiDB 需要的权限
权限 作用域 SELECT Tables INSERT Tables UPDATE Tables DELETE Tables CREATE Databases,tables DROP Databases, tables ALTER Tables INDEX Tables 为所同步的数据库或者表,执行下面的 GRANT 语句:
GRANT SELECT,INSERT,UPDATE,DELETE,CREATE,DROP,ALTER,INDEX ON db.table TO 'your_user'@'your_wildcard_of_host';
检查 SQL mode。
必须确认上下游的 SQL mode 一致;如果不一致,则会出现数据同步的错误。
show variables like '%sql_mode%';+---------------+-----------------------------------------------------------------------------------+ | Variable_name | Value | +---------------+-----------------------------------------------------------------------------------+ | sql_mode | ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION | +---------------+-----------------------------------------------------------------------------------+ 1 row in set (0.01 sec)检查字符集。
TiDB 和 MySQL 的字符集的兼容性不同,详见 TiDB 支持的字符集。
检查同步的表是否都有主键或者唯一索引。
如果表没有主键或唯一索引,就没法实现幂等,并且此时在下游更新每条数据时都是扫全表,可能导致同步速度变慢,所以建议同步的表都加上主键。
监控方案
Syncer 使用开源时序数据库 Prometheus 作为监控和性能指标信息存储方案,使用 Grafana 作为可视化组件进行展示,配合 AlertManager 来实现报警。其方案如下图所示:
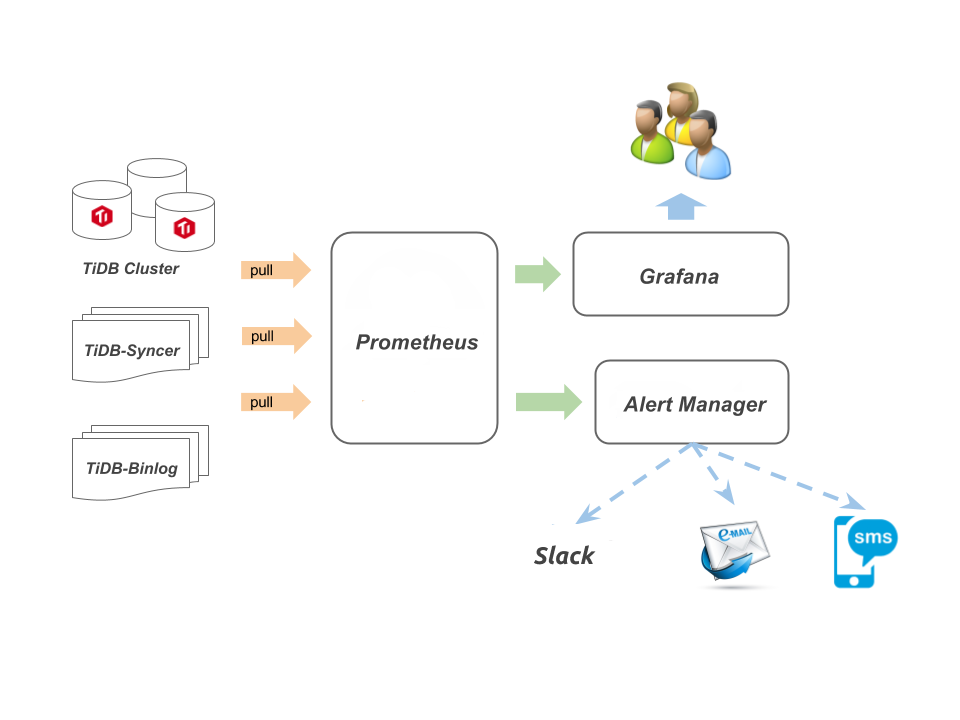
配置 Syncer 监控与告警
Syncer 对外提供 metric 接口,需要 Prometheus 主动获取数据。配置 Syncer 监控与告警的操作步骤如下:
在 Prometheus 中添加 Syncer job 信息,将以下内容刷新到 Prometheus 配置文件,重启 Prometheus 后生效。
- job_name: 'syncer_ops' // 任务名字,区分数据上报 static_configs: - targets: ['10.1.1.4:10086'] // Syncer 监听地址与端口,通知 Prometheus 获取 Syncer 的监控数据。配置 Prometheus 告警,将以下内容刷新到
alert.rule配置文件,重启 Prometheus 后生效。# syncer ALERT syncer_status IF syncer_binlog_file{node='master'} - ON(instance, job) syncer_binlog_file{node='syncer'} > 1 FOR 1m LABELS {channels="alerts", env="test-cluster"} ANNOTATIONS { summary = "syncer status error", description="alert: syncer_binlog_file{node='master'} - ON(instance, job) syncer_binlog_file{node='syncer'} > 1 instance: {{ $labels.instance }} values: {{ $value }}", }
Grafana 配置
进入 Grafana Web 界面(默认地址:
http://localhost:3000,默认账号: admin 密码: admin)导入 dashboard 配置文件
点击 Grafana Logo -> 点击 Dashboards -> 点击 Import -> 选择需要的 Dashboard 配置文件上传 -> 选择对应的 data source
Grafana Syncer metrics 说明
title: binlog events
- metrics:
rate(syncer_binlog_event_count[1m]) - info: 统计 Syncer 每秒已经收到的 binlog 个数
title: binlog event transform
- metrics:
histogram_quantile(0.8, sum(rate(syncer_binlog_event_bucket[1m])) by (le)) - info: Syncer 把 binlog 转换为 SQL 语句的耗时
title: transaction latency
- metrics:
histogram_quantile(0.95, sum(rate(syncer_txn_cost_in_second_bucket[1m])) by (le)) - info: Syncer 在下游 TiDB 执行 transaction 的耗时
title: transaction tps
- metrics:
rate(syncer_txn_cost_in_second_count[1m]) - info: Syncer 在下游 TiDB 每秒执行的 transaction 个数
title: binlog file gap
- metrics:
syncer_binlog_file{node="master"} - ON(instance, job) syncer_binlog_file{node="syncer"} - info: Syncer 已经同步到的 binlog position 的文件编号距离上游 MySQL 当前 binlog position 的文件编号的值;注意 MySQL 当前 binlog position 是定期查询,在一些情况下该 metrics 会出现负数的情况
title: binlog skipped events
- metrics:
rate(syncer_binlog_skipped_events_total[1m]) - info: Syncer 跳过的 binlog 的个数,你可以在配置文件中配置
skip-ddls和skip-dmls来跳过指定的 binlog
title: position of binlog position
- metrics:
syncer_binlog_pos{node="syncer"}andsyncer_binlog_pos{node="master"} - info: 需配合
file number of binlog position一起看。syncer_binlog_pos{node="master"}表示上游 MySQL 当前 binlog position 的 position 值,syncer_binlog_pos{node="syncer"}表示上游 Syncer 已经同步到的 binlog position 的 position 值
title: file number of binlog position
- metrics:
syncer_binlog_file{node="syncer"}andsyncer_binlog_file{node="master"} - info: 需要配置
position of binlog position一起看。syncer_binlog_file{node="master"}表示上游 MySQL 当前 binlog position 的文件编号,syncer_binlog_file{node="syncer"}表示上游 Syncer 已经同步到的 binlog 位置的文件编号
title: execution jobs
- metrics:
sum(rate(syncer_add_jobs_total[1m])) by (queueNo) - info: Syncer 把 binlog 转换成 SQL 语句后,将 SQL 语句以 jobs 的方式加到执行队列中,这个 metrics 表示已经加入执行队列的 jobs 总数
title: pending jobs
- metrics:
sum(rate(syncer_add_jobs_total[1m]) - rate(syncer_finished_jobs_total[1m])) by (queueNo) - info: 已经加入执行队列但是还没有执行的 jobs 数量