TiCDC 新架构
从 TiCDC v8.5.4-release.1 版本起,TiCDC 引入新架构,显著提升了实时数据复制的性能、可扩展性与稳定性,同时降低了资源成本。
新架构在完全兼容 TiCDC 老架构的配置项、使用方式和 API 的基础上,对 TiCDC 核心组件与数据处理流程进行了重构与优化,具有以下优势:
- 更高的单节点性能:单节点可支持最多 50 万张表的同步任务,宽表场景下单节点同步流量最高可达 190 MiB/s。
- 更强的扩展能力:集群同步能力接近线性扩展,单集群可扩展至超过 100 个节点,支持超 1 万个 Changefeed;单个 Changefeed 可支持百万级表的同步任务。
- 更高的稳定性:在高流量、频繁 DDL 操作及集群扩缩容等场景下,Changefeed 的延迟更低且更加稳定。通过资源隔离和优先级调度,减少了多个 Changefeed 任务之间的相互干扰。
- 更低的资源成本:通过改进资源利用率,减少冗余开销。在典型场景下,CPU 和内存等资源的使用量降低高达 50%。
架构设计
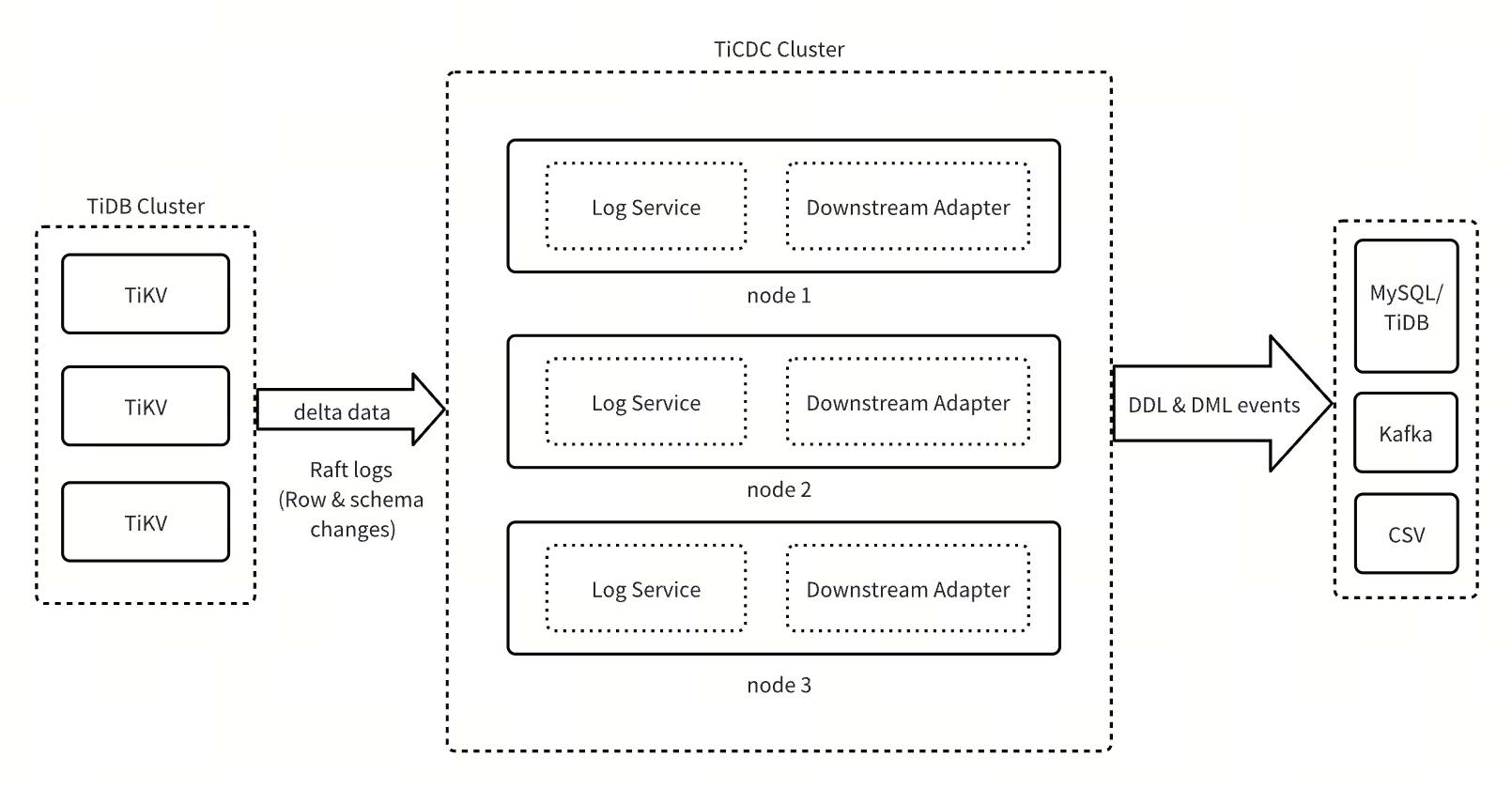
TiCDC 新架构由 Log Service 和 Downstream Adapter 两大核心组件构成。
- Log Service:作为核心数据服务层,Log Service 负责实时拉取上游 TiDB 集群的行变更和 DDL 变更等信息,并将变更数据临时存储在本地磁盘上。此外,它还负责响应 Downstream Adapter 的数据请求,定时将 DML 和 DDL 数据合并排序并推送至 Downstream Adapter。
- Downstream Adapter:作为下游数据同步适配层,Downstream Adapter 负责处理用户发起的 Changefeed 运维操作,调度生成相关同步任务,从 Log Service 获取数据并同步至下游系统。
TiCDC 新架构通过将整体架构拆分成有状态和无状态的两部分,显著提升了系统的可扩展性、可靠性和灵活性。Log Service 作为有状态组件,专注于数据的获取、排序和存储,通过与 Changefeed 业务逻辑的解耦,实现了数据在多个 Changefeed 间的共享,有效提高了资源利用率,降低了系统开销。Downstream Adapter 作为无状态组件,采用轻量级调度机制,支持任务在不同实例间的快速迁移,并根据负载变化灵活调整同步任务的拆分与合并,确保在各种场景下都能实现低延迟的数据同步。
新老架构对比
新架构旨在解决系统规模持续扩展过程中常见的性能瓶颈、稳定性不足及扩展性受限等核心问题。相较于老架构,新架构在以下关键维度实现了显著优化:
| 特性 | TiCDC 老架构 | TiCDC 新架构 |
|---|---|---|
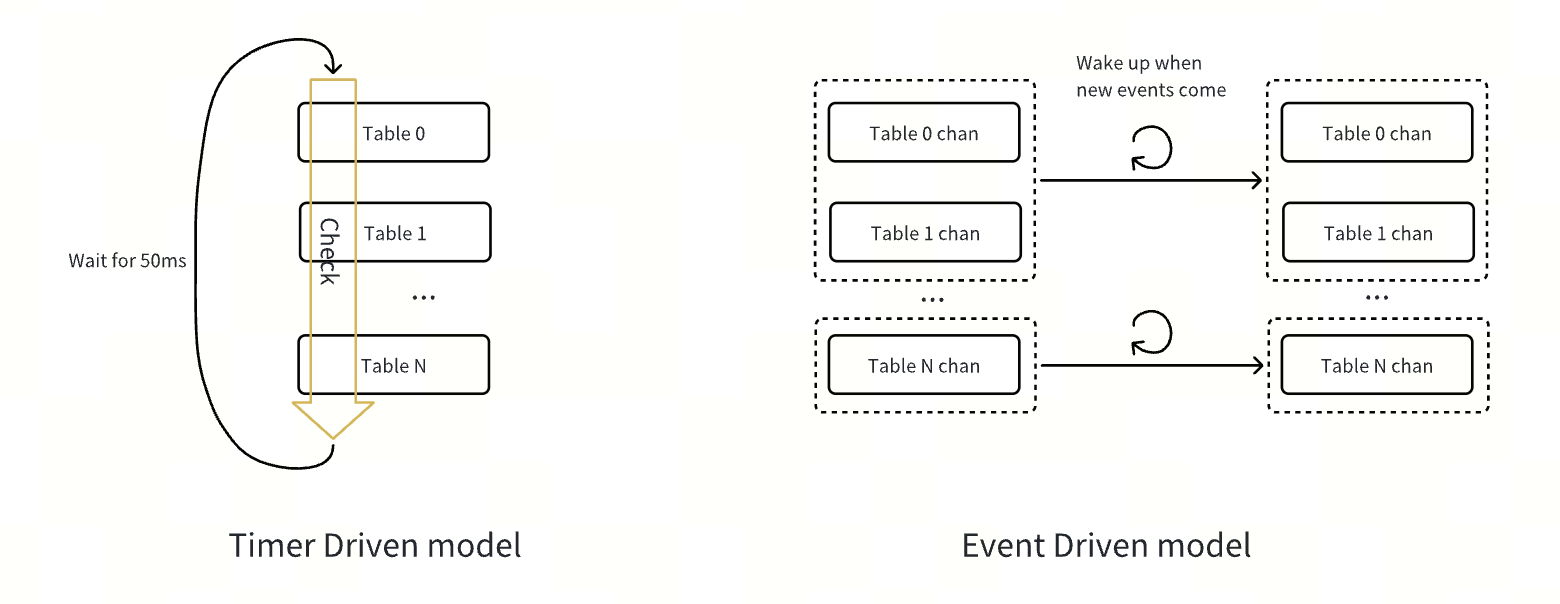
| 处理逻辑驱动方式 | Timer Driven(定时器驱动) | Event Driven(事件驱动) |
| 任务触发机制 | 定时器触发的大循环,每隔 50 ms 检查任务,处理性能有限 | 由事件驱动,包括 DML、DDL 变更及 Changefeed 操作,队列中的事件会被尽快处理,无需等待 50 ms 的固定间隔,从而减少了额外的延迟 |
| 任务调度方式 | 每个 Changefeed 运行一个主循环,轮询检查任务 | 事件被放入队列后,由多个线程并发消费处理 |
| 任务处理效率 | 每个任务需要经过多个周期,存在性能瓶颈 | 事件可以立即处理,无需等待固定间隔,减少延迟 |
| 资源消耗 | 频繁检查不活跃表,浪费 CPU 资源 | 消费线程仅处理队列中的事件,无需检查不活跃任务 |
| 复杂度 | O(n),表数量增多时性能下降 | O(1),不受表数量影响,效率更高 |
| CPU 利用率 | 每个 Changefeed 只能利用一个逻辑 CPU | 能充分利用多核 CPU 的并行处理能力 |
| 扩展能力 | 受限于 CPU 数量,扩展性差 | 通过多线程消费和事件队列,可扩展性强 |
| Changefeed 干扰问题 | 中央控制节点 (Owner) 会造成 Changefeed 之间的干扰 | 事件驱动模式避免了 Changefeed 之间的干扰 |
新老架构选择
如果你的业务满足以下任一条件,建议从 TiCDC 老架构切换至TiCDC 新架构,以获得更优的性能与稳定性:
- 增量扫描存在性能瓶颈:增量扫描任务长时间无法完成,导致同步延迟持续上升。
- 超高流量场景:Changefeed 总体流量超过 700 MiB/s。
- MySQL Sink 中存在超高流量写入的单表:目标表结构满足有且仅有一个主键或非空唯一键。
- 海量表同步场景:同步的表数量超过 10 万张。
- 高频 DDL 操作引发延迟:频繁执行 DDL 语句导致同步延迟显著上升。
新功能介绍
新架构支持为所有类型的 Sink 启用表级任务拆分。你可以通过在 Changefeed 配置中设置 scheduler.enable-table-across-nodes = true 来启用该功能。
启用后,TiCDC 会自动将满足以下任一条件的表拆分并分发到多个节点并行执行同步,从而提升同步效率与资源利用率:
- 表的 Region 数超过配置的阈值(默认
10000,可通过scheduler.region-threshold调整)。 - 表的写入流量超过配置的阈值(默认未开启,可通过
scheduler.write-key-threshold设置)。
兼容性说明
DDL 进度表
在 TiCDC 的老架构中,DDL 的同步是完全串行进行的,因此同步进度仅需通过 Changefeed 的 CheckpointTs 来标识。然而,在新架构中,为了提高 DDL 同步效率,TiCDC 会尽可能并行同步不同表的 DDL 变更。为了在下游 MySQL 兼容数据库中准确记录各表的 DDL 同步进度,TiCDC 新架构会在下游数据库中创建一张名为 tidb_cdc.ddl_ts_v1 的表,专门用于存储 Changefeed 的 DDL 同步进度信息。
DDL 同步行为变更
TiCDC 老架构不支持同步互换表名的 DDL(例如
RENAME TABLE a TO c, b TO a, c TO b;),TiCDC 新架构已支持此类 DDL 的同步。TiCDC 新架构统一并简化了 Rename DDL 的过滤规则。
在 TiCDC 老架构中,过滤逻辑如下
- 单表 Rename:仅要求旧表名符合过滤规则即可同步。
- 多表 Rename:必须所有旧表名和新表名均符合过滤规则,才会同步。
在新架构中,无论单表还是多表 Rename,只要语句中的旧表名符合过滤规则,该 DDL 即会被同步。
以下面的过滤规则为例:
[filter] rules = ['test.t*']- 在 TiCDC 老架构中:对于单表 Rename,如
RENAME TABLE test.t1 TO ignore.t1,因旧表名test.t1匹配规则,会被同步。对于多表 Rename,如RENAME TABLE test.t1 TO ignore.t1, test.t2 TO test.t22;,由于新表名ignore.t1不匹配规则,不会被同步。 - 在 TiCDC 新架构中:由于
RENAME TABLE test.t1 TO ignore.t1和RENAME TABLE test.t1 TO ignore.t1, test.t2 TO test.t22;中的旧表名均匹配规则,这两条 DDL 均会被同步。
- 在 TiCDC 老架构中:对于单表 Rename,如
使用限制
目前,TiCDC 新架构已完整实现旧架构的全部功能,但其中部分功能尚未经过全面的测试验证。为确保系统稳定性,暂不建议在核心生产环境中使用以下功能:
此外,TiCDC 新架构目前暂不支持将大事务拆分为多个批次同步至下游,因此在处理超大事务时仍存在 OOM 风险,请在使用前评估相关影响。
升级指南
TiCDC 新架构仅支持 v7.5.0 或者以上版本的 TiDB 集群,使用之前需要确保 TiDB 集群版本满足该要求。
你可以通过 TiUP 或 TiDB Operator 部署 TiCDC 新架构。
部署启用新架构 TiCDC 的全新 TiDB 集群
使用 TiUP 部署 v8.5.4 或者以上版本的全新 TiDB 集群时,可以同时部署启用新架构的 TiCDC 组件。你需要在 TiUP 启动 TiDB 集群时的配置文件中添加 TiCDC 组件相关配置,并设置 newarch: true 以启用新架构,以下是一个示例:
cdc_servers:
- host: 10.0.1.20
config:
newarch: true
- host: 10.0.1.21
config:
newarch: true
更多 TiCDC 部署信息,请参考使用 TiUP 部署包含 TiCDC 组件的全新 TiDB 集群。
使用 TiDB Operator 部署 v8.5.4 或者以上版本的全新 TiDB 集群时,可以同时部署启用新架构的 TiCDC 组件。你需要在集群配置文件中添加 TiCDC 组件配置,并设置 newarch = true 以启用新架构,以下是一个示例:
spec:
ticdc:
baseImage: pingcap/ticdc
version: v8.5.4
replicas: 3
config:
newarch = true
更多 TiCDC 部署信息,请参考全新部署 TiDB 集群同时部署 TiCDC。
在原有 TiDB 集群中部署启用新架构的 TiCDC 组件
以下为通过 TiUP 在原有 TiDB 集群中部署启用新架构的 TiCDC 组件的步骤:
如果你的 TiDB 集群中尚无 TiCDC 节点,参考扩容 TiCDC 节点在集群中扩容新的 TiCDC 节点,否则跳过该步骤。
如果你的 TiDB 集群为 v8.5.4 之前版本,需要按照以下方式手动下载 TiCDC 新架构离线包,并将下载的 TiCDC 二进制文件动态替换到你的 TiDB 集群,否则跳过该步骤。
离线包下载链接格式为
https://tiup-mirrors.pingcap.com/cdc-${version}-${os}-${arch}.tar.gz。其中,${version}为 TiCDC 版本号(版本号信息可参考 TiCDC 新架构版本发布列表),${os}为你的操作系统,${arch}为组件运行的平台(amd64或arm64)。例如,可以使用以下命令下载 Linux 系统 x86-64 架构的 TiCDC v8.5.4-release.1 的离线包:
wget https://tiup-mirrors.pingcap.com/cdc-v8.5.4-release.1-linux-amd64.tar.gz如果集群中已经有 Changefeed,请参考停止同步任务暂停所有的 Changefeed 同步任务。例如:
# cdc 默认服务端口为 8300 cdc cli changefeed pause --server=http://<ticdc-host>:8300 --changefeed-id <changefeed-name>使用
tiup cluster patch命令将下载的 TiCDC 二进制文件动态替换到你的 TiDB 集群中:tiup cluster patch <cluster-name> ./cdc-v8.5.4-release.1-linux-amd64.tar.gz -R cdc --overwrite通过
tiup cluster edit-config命令更新 TiCDC 配置以启用 TiCDC 新架构:tiup cluster edit-config <cluster-name>server_configs: cdc: newarch: true参考恢复同步任务恢复所有的 Changefeed 同步任务。
# cdc 默认服务端口为 8300 cdc cli changefeed resume --server=http://<ticdc-host>:8300 --changefeed-id <changefeed-name>
以下为通过 TiDB Operator 在原有 TiDB 集群中部署启用新架构的 TiCDC 组件的步骤:
如果现有 TiDB 集群中没有 TiCDC 组件,参考在现有 TiDB 集群上新增 TiCDC 组件在集群中添加新的 TiCDC 节点。操作时,只需在集群配置文件中将 TiCDC 的镜像版本指定为新架构版本即可。版本号信息可参考 TiCDC 新架构版本发布列表。
示例如下:
spec: ticdc: baseImage: pingcap/ticdc version: v8.5.4-release.1 replicas: 3 config: newarch = true如果现有 TiDB 集群中已有 TiCDC 组件,请按以下步骤操作:
如果集群中已经有 Changefeed,暂停所有的 Changefeed 同步任务。
kubectl exec -it ${pod_name} -n ${namespace} -- sh# 通过 TiDB Operator 部署的 TiCDC 服务器的默认端口为 8301 /cdc cli changefeed pause --server=http://127.0.0.1:8301 --changefeed-id <changefeed-name>修改集群配置文件中 TiCDC 组件的镜像版本为新架构版本。
kubectl edit tc ${cluster_name} -n ${namespace}spec: ticdc: baseImage: pingcap/ticdc version: v8.5.4-release.1 replicas: 3kubectl apply -f ${cluster_name} -n ${namespace}恢复所有的 Changefeed 同步任务。
kubectl exec -it ${pod_name} -n ${namespace} -- sh# 通过 TiDB Operator 部署的 TiCDC 服务器的默认端口为 8301 /cdc cli changefeed resume --server=http://127.0.0.1:8301 --changefeed-id <changefeed-name>
使用指南
在 TiCDC 新架构的节点部署完成后,即可使用相应的命令进行操作。新架构沿用了旧架构的 TiCDC 使用方式,因此无需额外学习新的命令,也无需修改旧架构中使用到的命令。
例如,要在新架构的 TiCDC 节点中创建同步任务,可执行以下命令:
cdc cli changefeed create --server=http://127.0.0.1:8300 --sink-uri="mysql://root:123456@127.0.0.1:3306/" --changefeed-id="simple-replication-task"
若需查询特定同步任务的信息,可执行:
cdc cli changefeed query -s --server=http://127.0.0.1:8300 --changefeed-id=simple-replication-task
更多命令的使用方法和细节,可以参考管理 Changefeed。
监控
TiCDC 新架构的监控面板为 TiCDC-New-Arch。对于 v8.5.4 及以上版本的 TiDB 集群,该监控面板已在集群部署或升级时自动集成到 Grafana 中,无需手动操作。如果你的集群版本低于 v8.5.4,需手动导入 TiCDC 监控指标文件以启用监控。
导入步骤以及各监控指标的详细说明,请参考 TiCDC 新架构监控指标。