备份自动调节 从 v5.4 版本开始引入
在 TiDB v5.4.0 之前,默认情况下,使用 BR 进行备份任务时使用的线程数量占总逻辑 CPU 数量的 75%。在没有限速的前提下,备份会消耗大量的集群资源,这会对在线集群的性能造成相当大的影响。虽然你可以通过调节线程池的大小的方式来减少备份对集群性能的影响,但观察负载、手动调节线程池大小也是一件繁琐的事情。
为了减少备份任务对在线集群的影响,从 TiDB v5.4.0 起,引入了自动调节功能,此功能默认开启。在集群资源占用率较高的情况下,备份功能可以通过该功能自动限制备份使用的资源,从而减少对集群的影响。
使用场景
如果你希望减少备份对集群的影响,那么,你可以开启自动调节功能。开启该功能后,备份功能会在不过度影响集群的前提下,以最快的速度进行数据备份。
或者,你也可以使用 TiKV 配置项 backup.num-threads 或参数 --ratelimit 进行备份限速。设置 --ratelimit 后,为了避免任务数过多导致限速失效,br 的 concurrency 参数会自动调整为 1。
使用方法
自动调节功能默认打开,无需额外配置。
如需开启备份自动调节功能,可以通过把 TiKV 配置项 backup.enable-auto-tune 设置为 true 的方式来完成。
TiKV 支持动态配置自动调节功能,因此,在开启或关闭该功能时,无需重启集群。你可以运行以下命令动态启动或停止备份自动调节功能:
tikv-ctl modify-tikv-config -n backup.enable-auto-tune -v <true|false>
在离线备份场景中,你也可以使用 tikv-ctl 把 backup.num-threads 修改为更大的数字,从而提升备份速度。
使用限制
自动调节是一个粗粒度的限流方案,它的优势在无需手动调节。但是,由于调节的粒度不够精确,该功能有可能无法彻底移除备份对集群的影响。
该功能的已知问题及其解决方案如下:
问题 1:对于以写负载为主的集群,自动调节可能会让工作负载和备份进入一种“正反馈循环”:备份会占用较多资源,导致工作负载使用的资源变少。此时,自动调节会误以为资源使用率下降,从而让备份运行得更加激进。在这种情况下,自动调节实际上失效。
解决方法:手动调节
backup.num-threads,限制处理备份的工作线程数量。具体原理如下:目前,备份过程会涉及大量的 SST 解码、编码、压缩、解压,而此过程会需要消耗大量的 CPU 资源。另外,以往的测试证明,备份过程中,用于备份的线程池的 CPU 利用率接近 100%。也就是说,备份任务会占用大量 CPU 资源。通过调整备份任务使用的线程数量,TiKV 可以控制备份任务使用的 CPU 核心数,从而减少其任务对集群性能的影响。
问题 2:对于存在热点的集群,产生热点的 TiKV 节点可能会被过度限流,从而拉慢备份的整体进度。
- 解决方法:消除热点节点,或者在热点节点上关闭自动调节(关闭此功能可能会导致集群性能降低)。
问题 3:对于流量抖动非常大的场景,由于自动调节每隔
auto-tune-refresh-interval(默认为一分钟)才会计算出新的限流,所以可能无法很好地应对流量抖动非常厉害的场景。- 解决方法:关闭自动调节。
实现原理
自动调节会通过调节备份时使用的工作线程池的大小,保证集群的 CPU 总体使用率不超过某个特定的值。
这个特性还有两个配置项未在 TiKV 文档中列出,仅在内部调试使用,正常备份时无需配置这两个参数。
backup.auto-tune-remain-threads:- 通过控制备份任务占用的资源,自动调节会保证该节点中至少有该数量的核心会保持空闲的状态。
- 默认值:
round(0.2 * vCPU)
backup.auto-tune-refresh-interval:- 每隔该值的时间段,自动调节会刷新统计信息并重新计算备份任务使用的 CPU 核心数的上限。
- 默认值:
1m
以下是一个使用自动调节功能的示例,其中 * 代表集群中被备份任务占用的 CPU,^ 代表其它任务占用的 CPU,- 代表空闲 CPU。
|--------| 系统总共有 8 颗逻辑 CPU。
|****----| 默认配置 `backup.num-threads` 为 `4`。请注意,在任何时候自动调节都不会让线程池大小大于 `backup.num-threads`。
|^^****--| 默认配置 `auto-tune-remain-threads` = round(8 * 0.2) = 2。自动调节会将备份任务的线程池大小调节至 `4`。
|^^^^**--| 由于集群的工作负载加重,自动调节将备份任务的线程池大小调节至 `2`。调节后,集群中仍有 2 个 CPU 核心数保持空闲。
在监控面板的“Backup CPU Utilization”中,可以看到自动限流目前选择的线程池的大小:
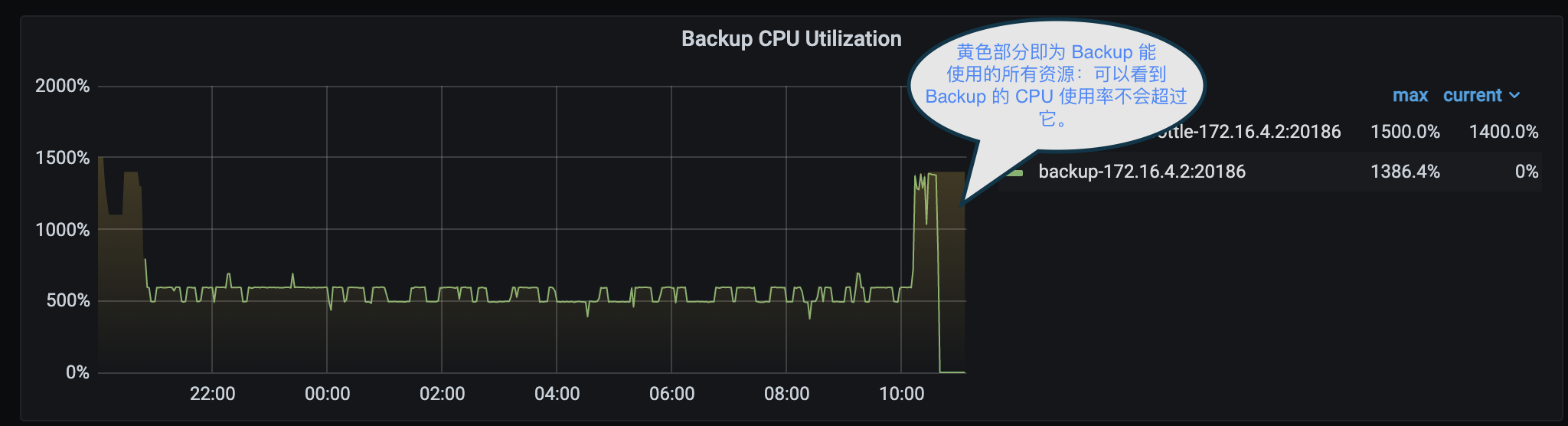
图片中,黄色半透明的填充部分为开启自动调节后备份任务可用的线程,即备份任务能使用的所有资源。从中可以看到备份任务的 CPU 使用率不会超过黄色部分。