OLTP 负载性能优化实践
TiDB 提供了完善的性能诊断和分析功能,例如 TiDB Dashboard 的 Top SQL 和 Continuous Profiling 功能,以及 TiDB Performance Overview 面板。
本文介绍如何综合利用这些功能,对同一个 OLTP 负载在七种不同运行场景下的性能表现进行分析和对比,并演示了具体的 OLTP 负载的优化过程,帮助你更快地对 TiDB 的性能进行分析和优化。
在这些场景中,通过使用不同的 JDBC 配置运行同一个应用程序,你可以观察应用和数据库之间不同的交互方式将如何影响系统整体的性能,从而更好地掌握开发 Java 应用使用 TiDB 的最佳实践。
负载环境
本文使用一个银行交易系统 OLTP 仿真模拟负载进行演示。以下为该负载的仿真环境配置:
- 负载应用程序的开发语言:JAVA
- 涉及业务的 SQL 语句:共 200 条,其中 90% 都是 SELECT 语句,属于典型的读密集 OLTP 场景。
- 涉及交易的表:共 60 张,存在修改操作类的表为 12 张,其余 48 张表只读。
- 应用程序使用的隔离级别:
read committed。 - TiDB 集群配置:3 个 TiDB 节点和 3 个 TiKV 节点,各节点分配 16 CPU。
- 客户端服务器配置:36 CPU。
场景 1:使用 Query 接口
应用配置
应用程序使用以下 JDBC 配置,通过 Query 接口连接数据库。
useServerPrepStmts=false
性能分析
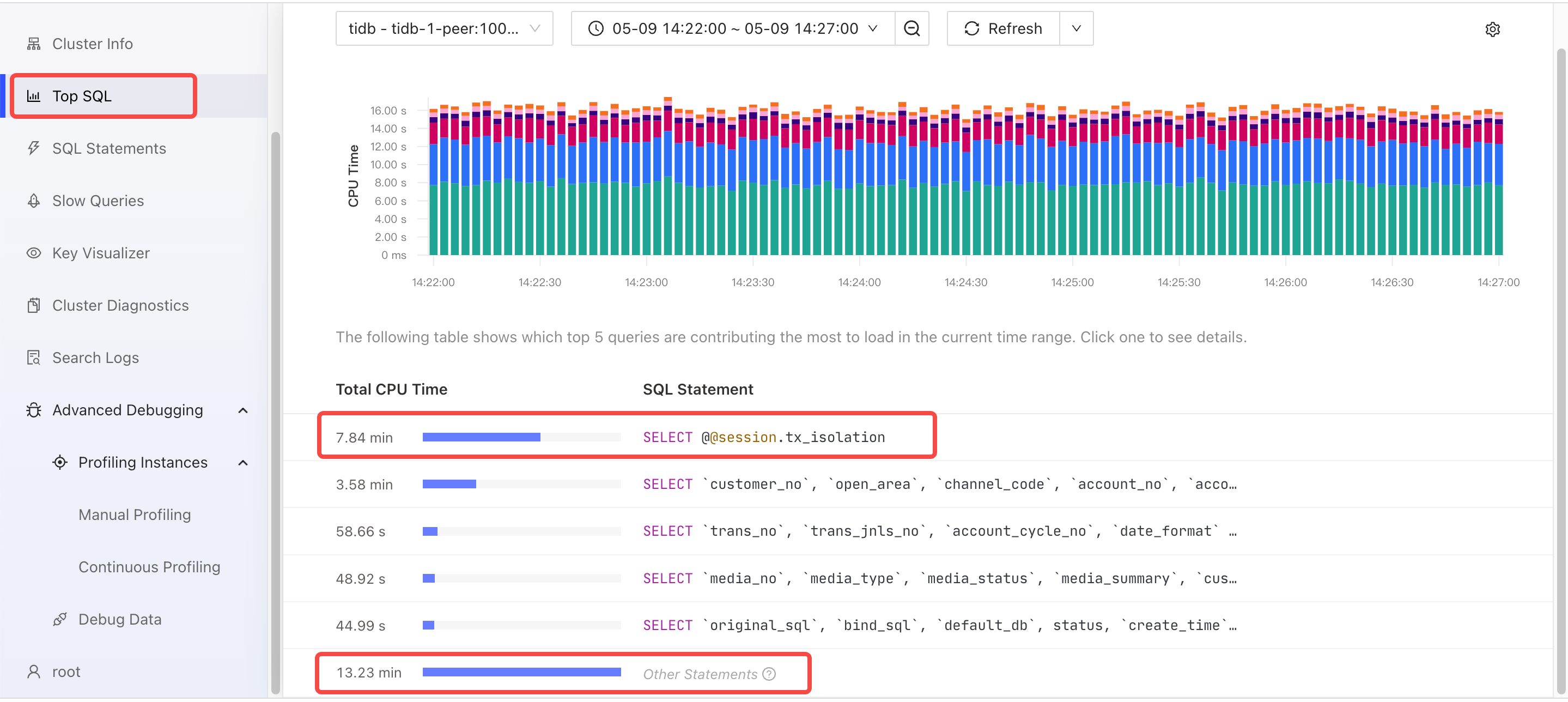
TiDB Dashboard
从以下 Dashboard 的 Top SQL 页面可以观察到,非业务 SQL 类型 SELECT @@session.tx_isolation 消耗的资源最多。虽然 TiDB 处理这类 SQL 语句的速度快,但由于执行次数最多导致总体 CPU 耗时最多。
观察以下 TiDB 的火焰图,可以发现,在 SQL 的执行过程中,Compile 和 Optimize 等函数的 CPU 消耗占比明显。因为应用使用了 Query 接口,TiDB 无法使用执行计划缓存,导致每个 SQL 都需要编译生成执行计划。
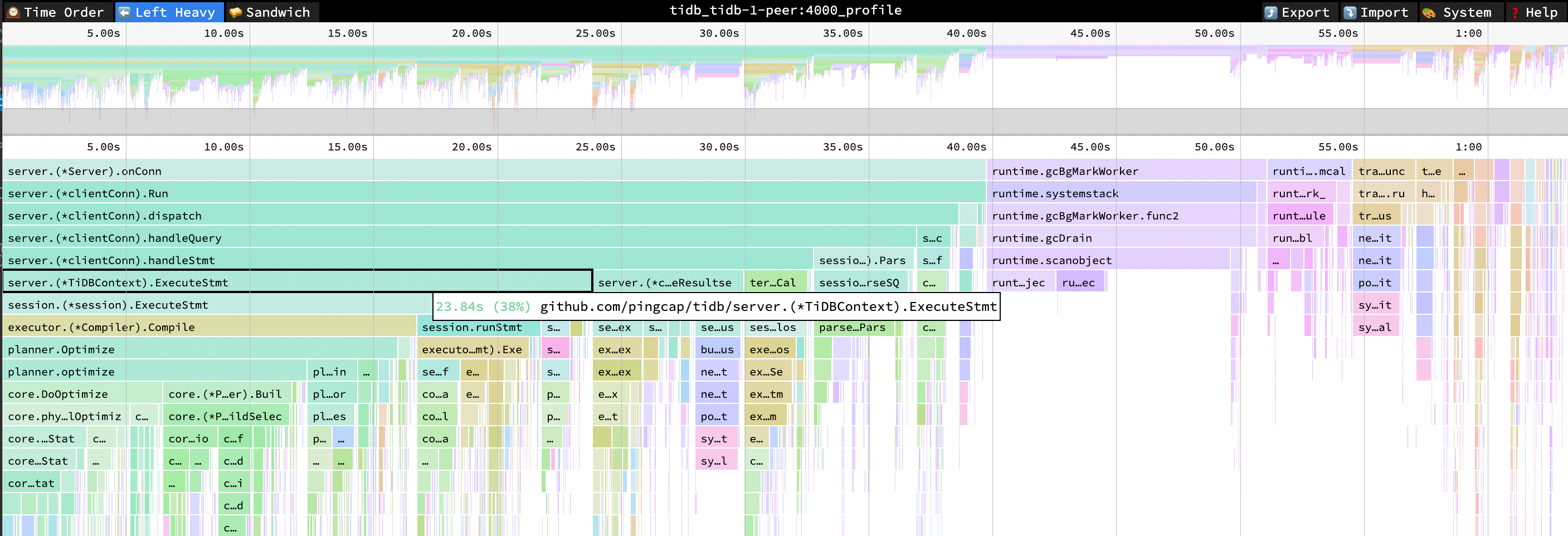
- ExecuteStmt cpu = 38% cpu time = 23.84s
- Compile cpu = 27% cpu time = 17.17s
- Optimize cpu = 26% cpu time = 16.41s
Performance Overview 面板
观察以下 Performance Overview 面板中数据库时间概览和 QPS 的数据:
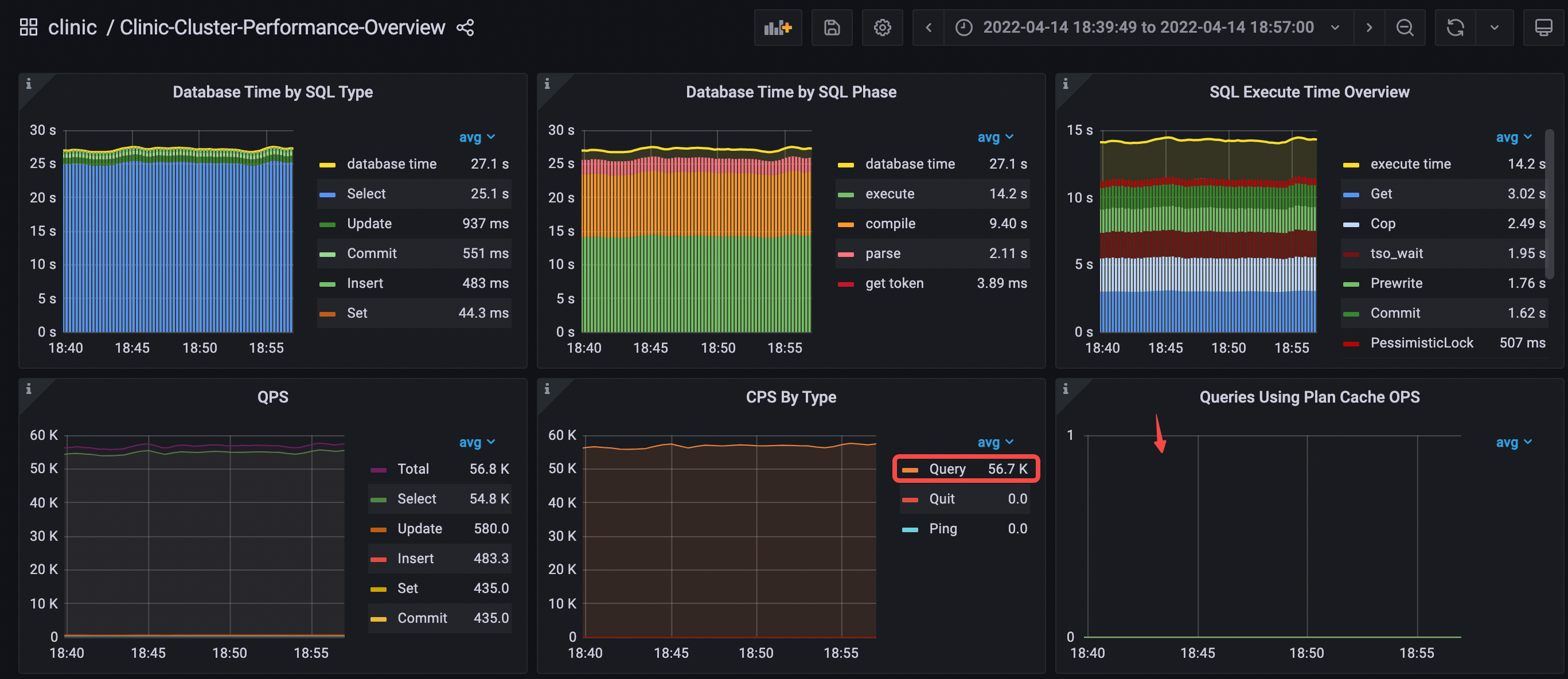
- Database Time by SQL Type 中 Select 语句耗时最多
- Database Time by SQL Phase 中 execute 和 compile 占比最多
- SQL Execute Time Overview 中占比最多的分别是 Get、Cop 和 tso wait
- CPS By Type 只有 query 这一种 command
- Queries Using Plan Cache OPS 没有数据,说明无法命中执行计划缓存
- execute 和 compile 的延迟在 query duration 中占比最高
- avg QPS = 56.8k
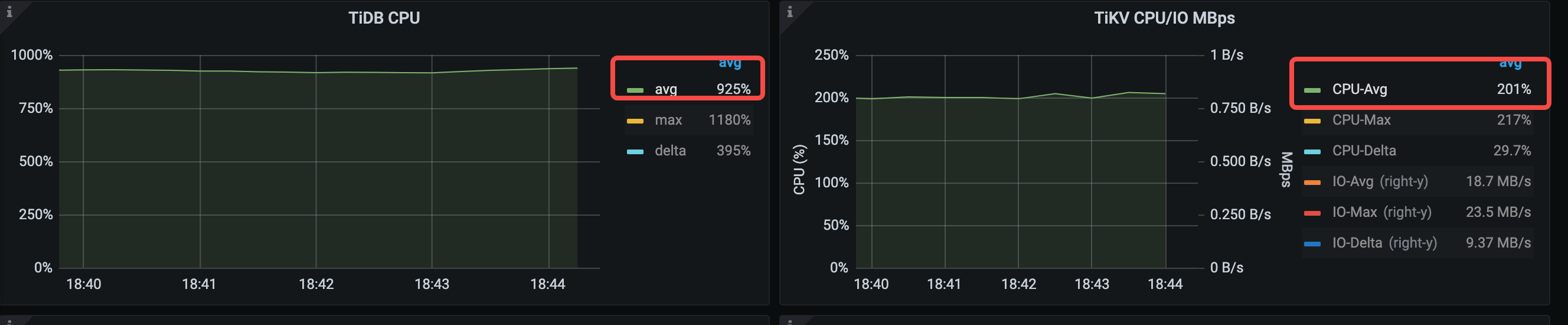
观察集群的资源消耗,TiDB CPU 的平均利用率为 925%,TiKV CPU 的平均利用率为 201%,TiKV IO 平均吞吐为 18.7 MB/s。TiDB 的资源消耗明显更高。
分析结论
需要屏蔽这些大量无用的非业务 SQL 语句。
场景 2:使用 maxPerformance 配置
应用配置
在场景 1 中的 JDBC 连接串的基础上,新增一个参数 useConfigs=maxPerformance。这个参数可以用来屏蔽 JDBC 向数据库发送的一些查询设置类的 SQL 语句(例如 select @@session.transaction_read_only),完整配置如下:
useServerPrepStmts=false&useConfigs=maxPerformance
性能分析
TiDB Dashboard
在 Dashboard 的 Top SQL 页面,可以看到原本占比最多的 SELECT @@session.tx_isolation 已消失。
观察以下 TiDB 的火焰图,可以发现 SQL 语句执行中 Compile 和 Optimize 等函数 CPU 消耗占比高:
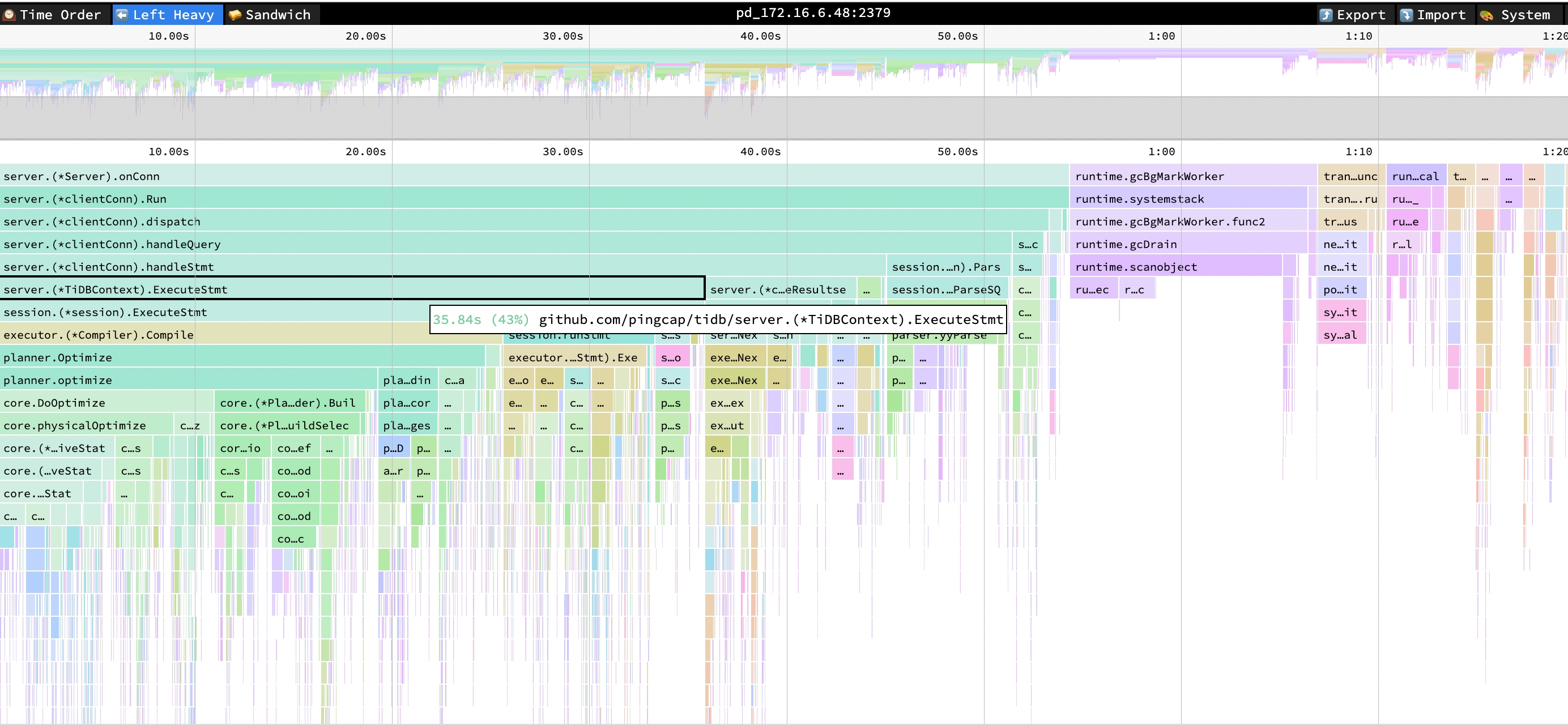
- ExecuteStmt cpu = 43% cpu time =35.84s
- Compile cpu = 31% cpu time =25.61s
- Optimize cpu = 30% cpu time = 24.74s
Performance Overview 面板
数据库时间概览和 QPS 的数据如下:
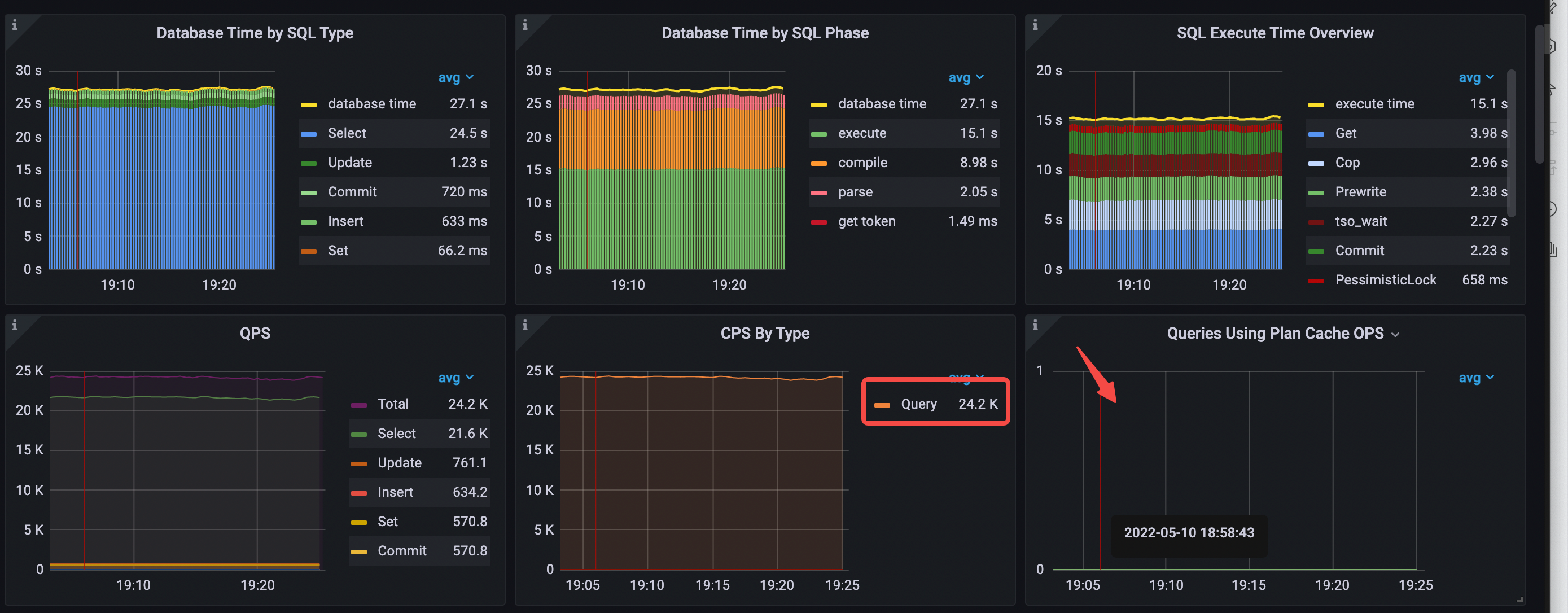
- Database Time by SQL Type 中 select 语句耗时最多
- Database Time by SQL Phase 中 execute 和 compile 占比最多
- SQL Execute Time Overview 中占比最多的分别是 Get、Cop、Prewrite 和 tso_wait
- execute 和 compile 的延迟在 db time 中占比最高
- CPS By Type 只有 query 这一种 command
- avg QPS = 24.2k (56.3k->24.2k)
- 无法命中 plan cache
从场景 1 到场景 2,TiDB CPU 平均利用率从 925% 下降到 874%,TiKV CPU 平均利用率从 201% 上升到 250% 左右。

关键延迟指标变化如下:
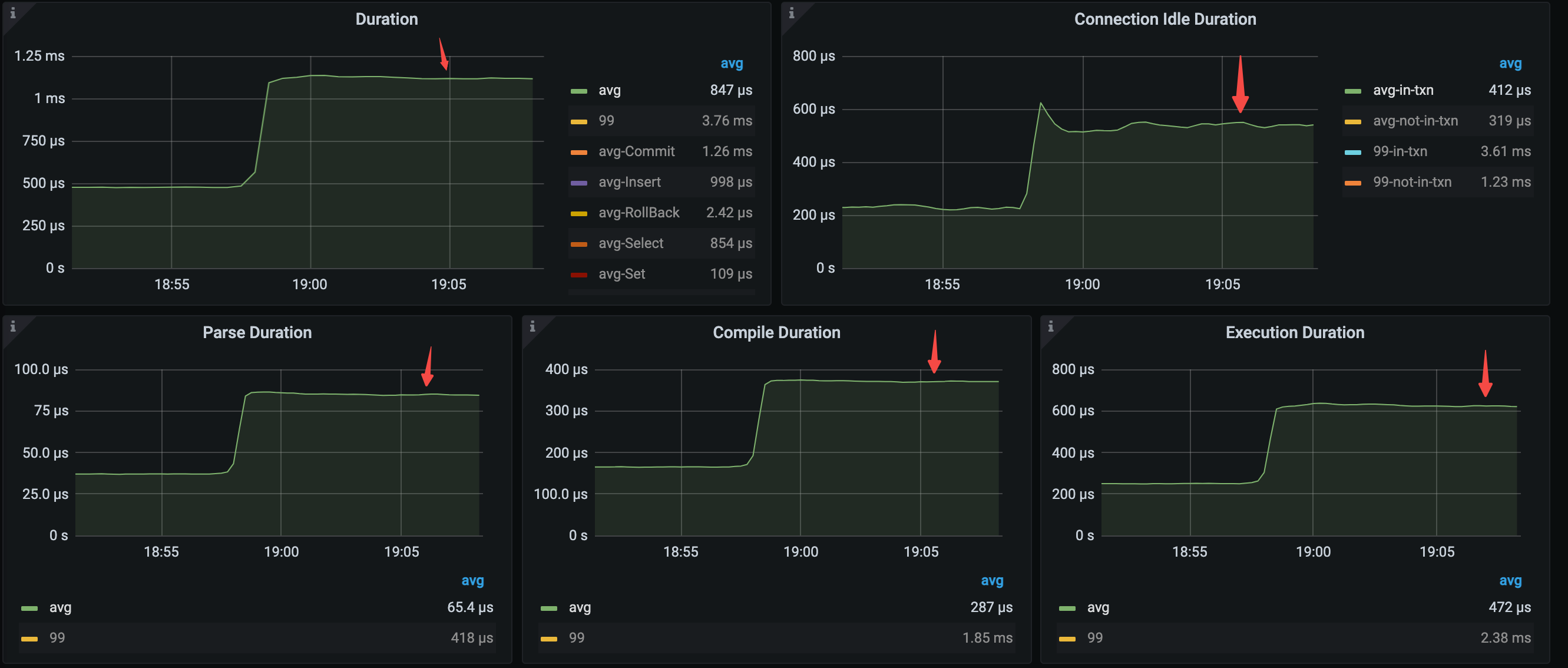
- avg query duration = 1.12ms (479μs->1.12ms)
- avg parse duration = 84.7μs (37.2μs->84.7μs)
- avg compile duration = 370μs (166μs->370μs)
- avg execution duration = 626μs (251μs->626μs)
分析结论
和场景 1 相比,场景 2 的 QPS 有明显的下降,平均 query duration 和 parse、compile 以及 execute duration 有明显的上升。这是因为场景 1 中类似 select @@session.transaction_read_only 这样执行次数多且处理时间快的 SQL 语句拉低了性能平均值,场景 2 屏蔽这类语句后只剩下纯业务 SQL,从而带来了 duration 平均值的上升。
当应用使用 query 接口时,TiDB 无法使用执行计划缓存,编译执行计划消耗高。此时,建议使用 Prepared Statement 预编译接口,利用 TiDB 的执行计划缓存来降低 compile 带来的 TiDB CPU 消耗,降低延迟。
场景 3:使用 Prepared Statement 接口,未开启执行计划缓存
应用配置
应用程序使用以下连接配置,和场景 2 对比,JDBC 的 useServerPrepStmts 参数值修改为 true,表示启用了预编译语句的接口。
useServerPrepStmts=true&useConfigs=maxPerformance"
性能分析
TiDB Dashboard
观察以下 TiDB 的火焰图,可以发现启用 Prepared Statement 接口之后,CompileExecutePreparedStmt 和 Optimize 的 CPU 占比依然明显。
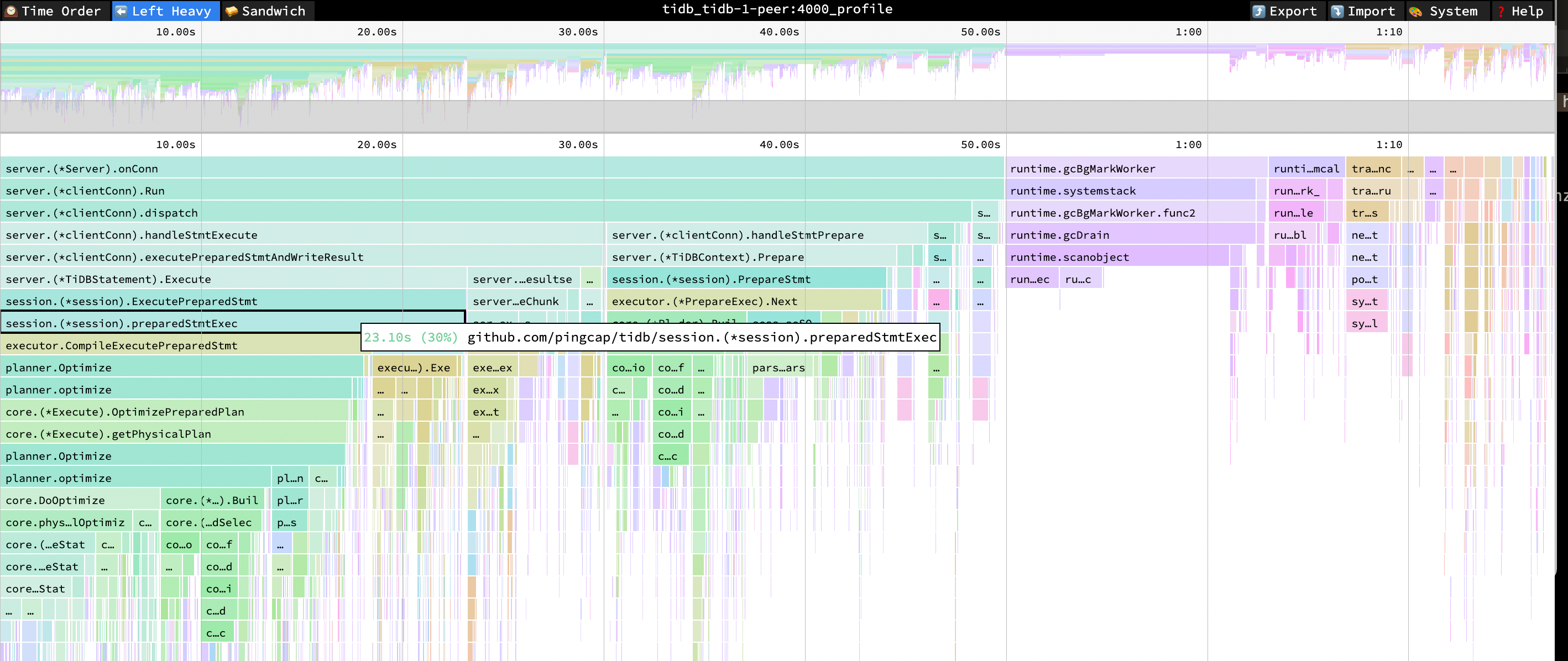
- ExecutePreparedStmt cpu = 31% cpu time = 23.10s
- preparedStmtExec cpu = 30% cpu time = 22.92s
- CompileExecutePreparedStmt cpu = 24% cpu time = 17.83s
- Optimize cpu = 23% cpu time = 17.29s
Performance Overview 面板
使用 Prepared Statement 接口之后,数据库时间概览和 QPS 的数据如下:
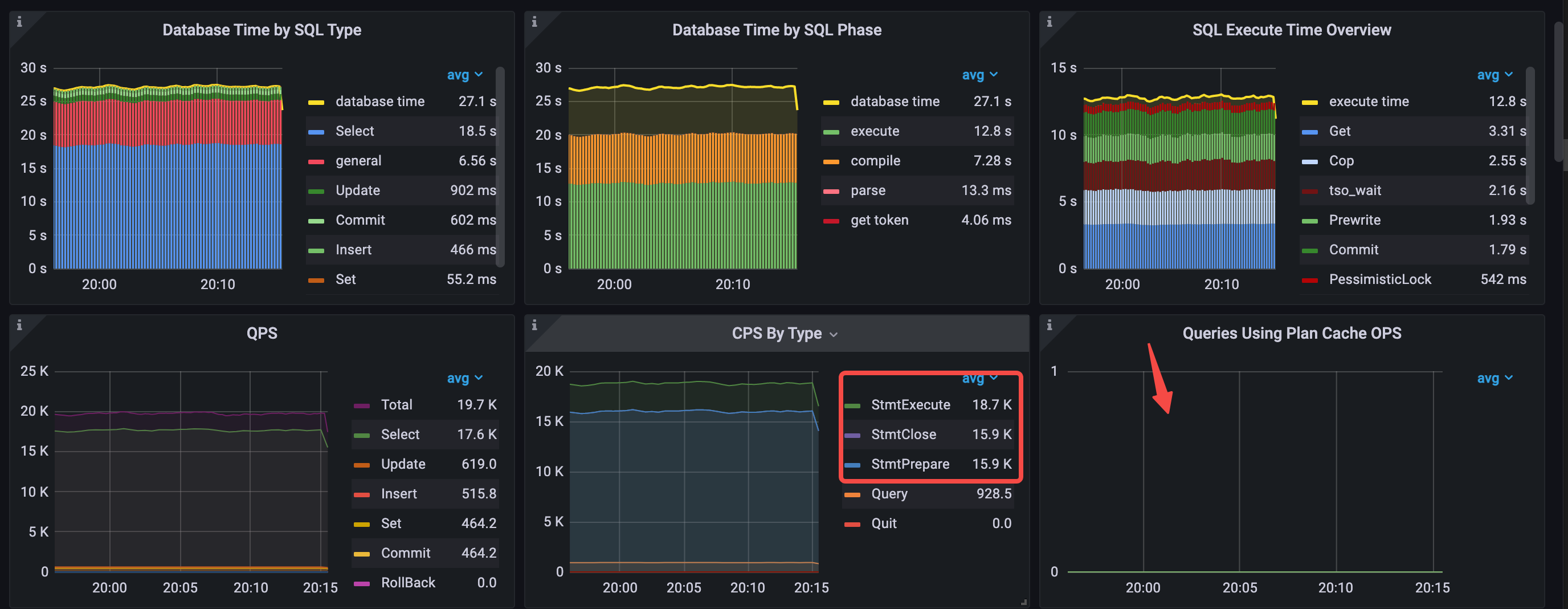
QPS 从 24.4k 下降到 19.7k,从 CPS By Type 面板可以看到应用程序使用了三种 Prepared 命令。Database Time Overview 出现了 general 的语句类型(包含了 StmtPrepare 和 StmtClose 等命令的执行耗时),占比排名第二。这说明,即使使用了 Prepared Statement 接口,执行计划缓存也没有命中,原因在于 TiDB 内部处理 StmtClose 命令时,会清理修改语句的执行计划缓存。
- Database Time by SQL Type 中 select 语句耗时最多,其次是 general 语句
- Database Time by SQL Phase 中 execute 和 compile 占比最多
- SQL Execute Time Overview 中占比最多的分别是 Get、Cop、Prewrite 和 tso_wait
- CPS By Type 变成 3 种 command:StmtPrepare、StmtExecute、StmtClose
- avg QPS = 19.7k (24.4k->19.7k)
- 无法命中 plan cache
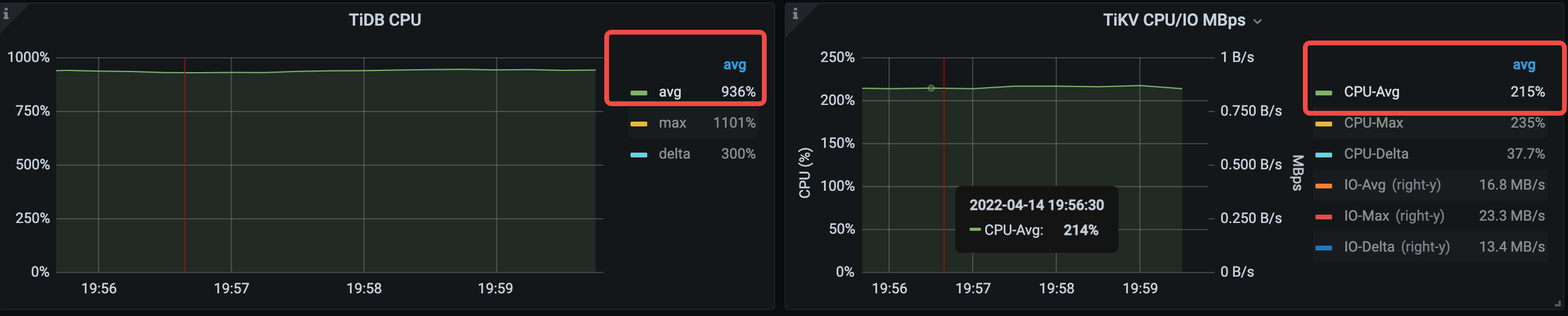
TiDB CPU 平均利用率从 874% 上升到 936%
主要延迟数据如下:
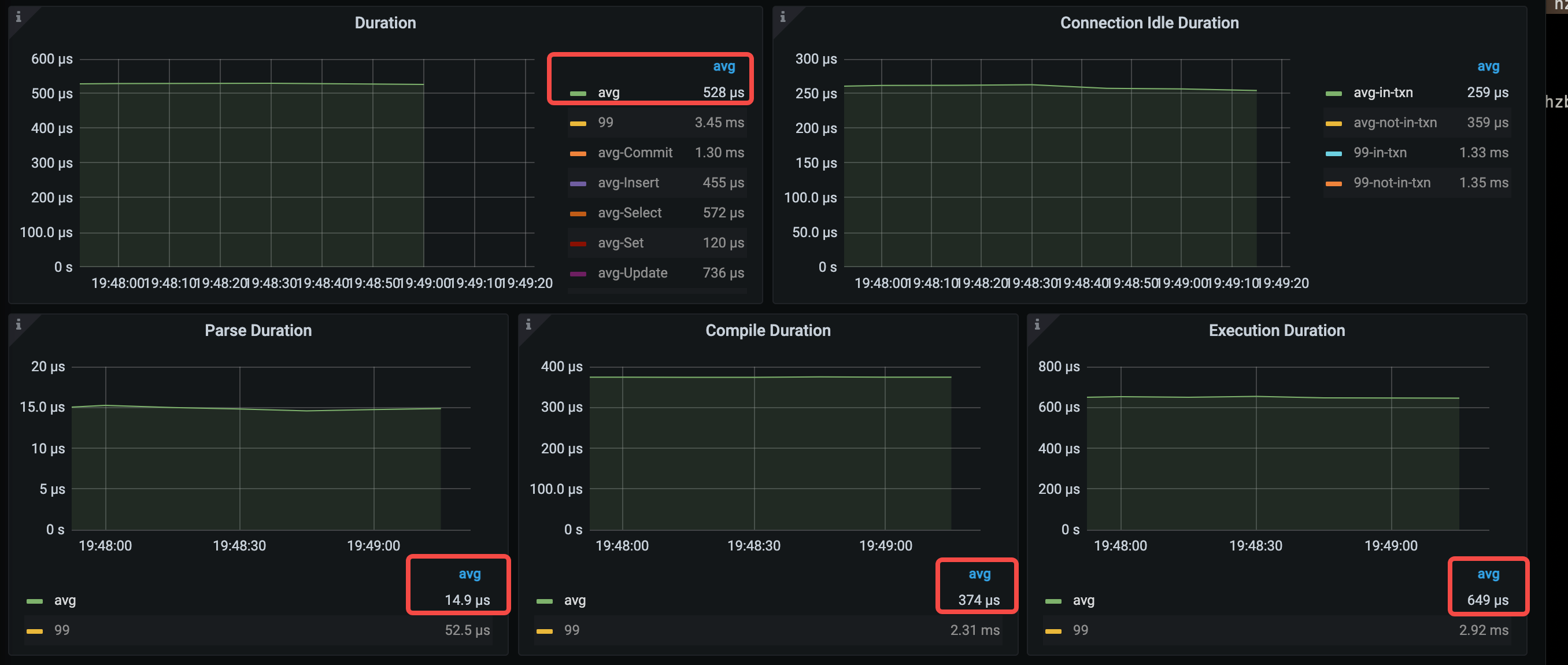
- avg query duration = 528μs (1.12ms->528μs)
- avg parse duration = 14.9μs (84.7μs->14.9μs)
- avg compile duration = 374μs (370μs->374μs)
- avg execution duration = 649μs (626μs->649μs)
分析结论
和场景 2 不同的是,场景 3 启用了 prepare 预编译接口但是仍然无法命中缓存。此外,场景 2 的 CPS By Type 只有 query 这一种 command 类型,场景 3 多了 3 种 command 类型(StmtPrepare、StmtExecute、StmtClose)。与场景 2 相比,相当于多了两次网络往返的延迟。
- QPS 的降低原因分析:从 CPS By Type 面板可以看到,场景 2 只有 query 这一种 command 类型,但场景 3 新增了 3 种 command 类型,即 StmtPrepare、StmtExecute 和 StmtClose。其中,StmtExecute 和 query 为常规类型 command,会被 QPS 统计,而 StmtPrepare 和 StmtClose 为非常规类型 command,不会被 QPS 统计,所以 QPS 降低了。非常规类型 command 的 StmtPrepare 和 StmtClose 被统计在 general SQL 类型中,因此可以看到 database overview 中多了 general 的时间,且占比在 database time 的四分之一以上。
- 平均 query duration 明显降低原因分析:场景 3 新增了 StmtPrepare 和 StmtClose 这两种 command 类型,TiDB 内部处理时,query duration 也会单独计算,这两类命令处理速度很快,所以平均 query duration 明显被拉低。
虽然场景 3 使用了 Prepare 预编译接口但是因为出现了 StmtClose 导致缓存失效,很多应用框架也会在 execute 后调用 close 方法来防止内存泄漏。从 v6.0.0 版本开始,你可以设置全局变量 tidb_ignore_prepared_cache_close_stmt=on;。设置后,即使应用调用了 StmtClose 方法,TiDB 也不会清除缓存的执行计划,使得下一次的 SQL 执行能重用现有的执行计划,避免重复编译执行计划。
场景 4:使用 Prepared Statement 接口,开启执行计划缓存
应用配置
应用配置保持不变。设置以下参数,解决即使应用触发 StmtClose 导致无法命中缓存的问题。
- 设置 TiDB 全局变量
set global tidb_ignore_prepared_cache_close_stmt=on;(TiDB v6.0.0 起正式使用,默认关闭) - 设置 TiDB 配置项
prepared-plan-cache: {enabled: true}开启 plan cache 功能
性能分析
TiDB Dashboard
观察 TiDB 的 CPU 火焰图,可以看到 CompileExecutePreparedStmt 和 Optimize 没有明显的 CPU 消耗。Prepare 命令的 CPU 占比 25%,包含了 PlanBuilder 和 parseSQL 等 Prepare 解析相关的函数。
PreparseStmt cpu = 25% cpu time = 12.75s
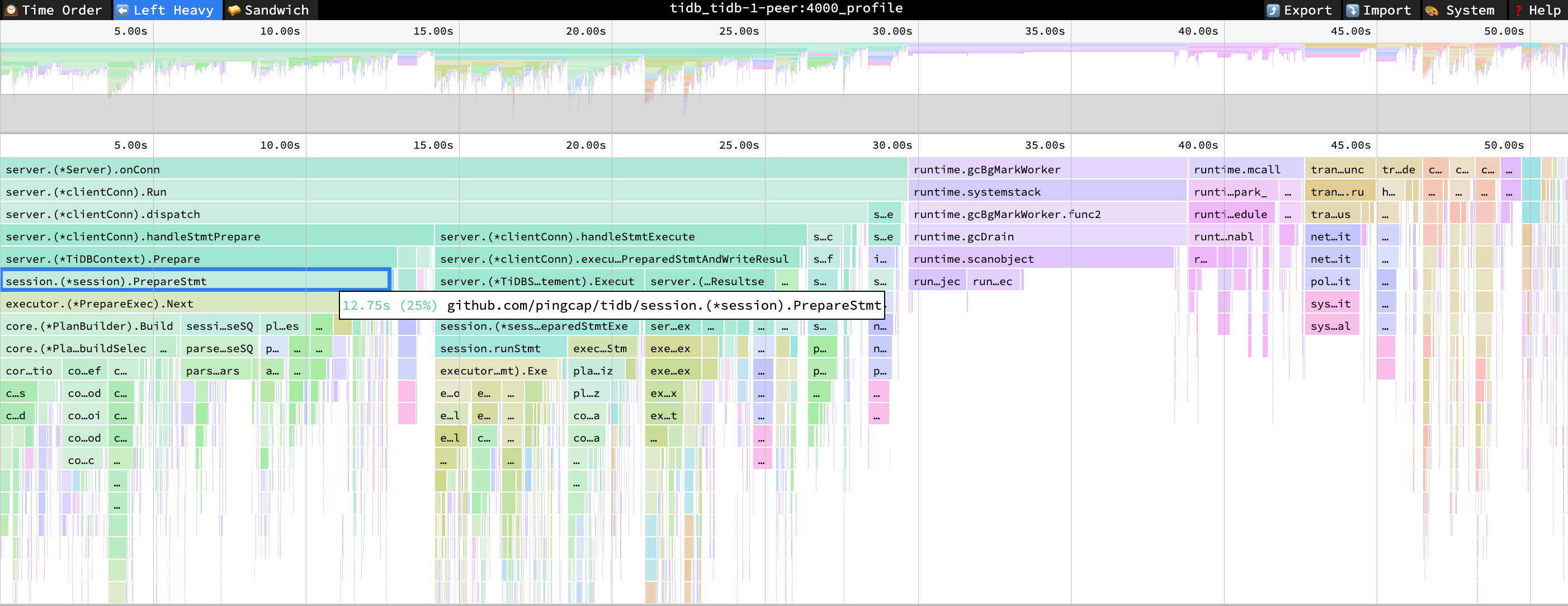
Performance Overview 面板
在 Performance Overview 面板种,最显著的变化来自于 Compile 阶段的占比,从场景 3 每秒消耗 8.95 秒降低为 1.18 秒。执行计划缓存的命中次数大致等于 StmtExecute 次数。在 QPS 上升的前提下,每秒 Select 语句消耗的数据库时间降低了,general 类型的语句消耗时间变长。
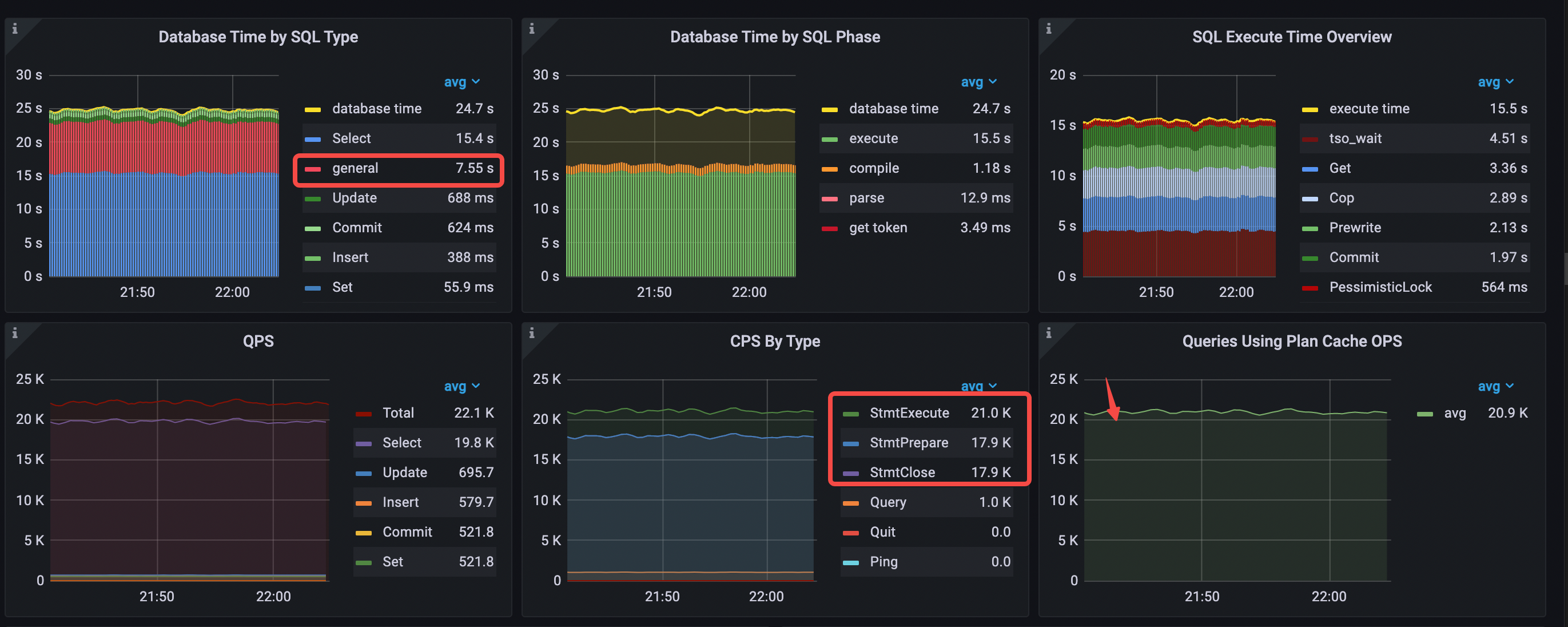
- Database Time by SQL Type 中 select 语句耗时最多
- Database Time by SQL Phase 中 execute 占比最多
- SQL Execute Time Overview 中占比最多的分别是 tso wait、Get 和 Cop
- 命中 plan cache,Queries Using Plan Cache OPS 大致等于 StmtExecute 每秒的次数
- CPS By Type 仍然是 3 种 command
- general time 相比场景 3 变长,因为 QPS 上升了
- avg QPS = 22.1k (19.7k->22.1k)
TiDB CPU 平均利用率从 936% 下降到 827%。
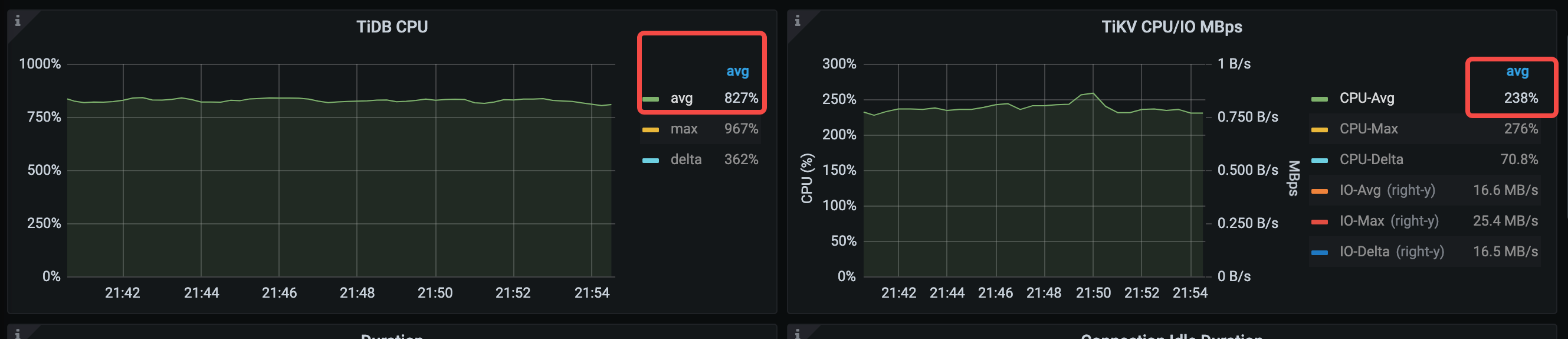
Compile 平均时间显著下降,从 374 us 下降到 53.3 us,因为 QPS 的上升,平均 execute 时间有所上升。
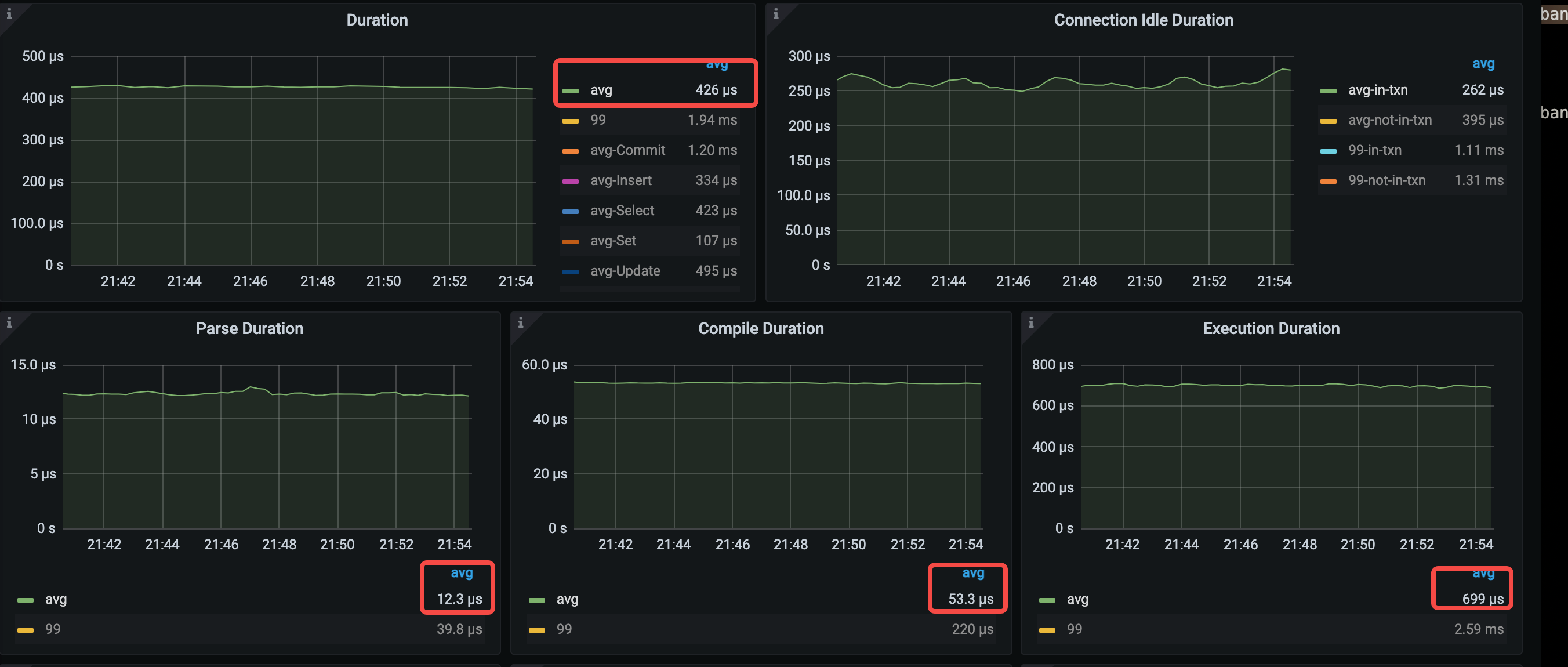
- avg query duration = 426μs (528μs->426μs)
- avg parse duration = 12.3μs (14.8μs->12.3μs)
- avg compile duration = 53.3μs (374μs->53.3μs)
- avg execution duration = 699μs (649μs->699us)
分析结论
和场景 3 相比,场景 4 同样存在 3 种 command 类型,不同的是场景 4 可以命中执行计划缓存,所以大大降低了 compile duration,同时降低了 query duration,并且提升了 QPS。
因为 StmtPrepare 和 StmtClose 两种命令消耗的数据库时间明显,并且增加了应用程序每执行一条 SQL 语句需要跟 TiDB 交互的次数。下一个场景将通过 JDBC 配置优化掉这两种命令。
场景 5:客户端缓存 prepared 对象
应用配置
和场景 4 相比,新增 3 个 JDBC 参数配置 cachePrepStmts=true&prepStmtCacheSize=1000&prepStmtCacheSqlLimit=20480,解释如下:
cachePrepStmts = true:在客户端缓存 prepared statement 对象,消除 StmtPrepare 和 StmtClose 调用。prepStmtCacheSize:需要配置为大于 0 的值prepStmtCacheSqlLimit:需要设置为大于 SQL 文本的长度
完整的 JDBC 参数配置如下:
useServerPrepStmts=true&cachePrepStmts=true&prepStmtCacheSize=1000&prepStmtCacheSqlLimit=20480&useConfigs=maxPerformance
性能分析
TiDB Dashboard
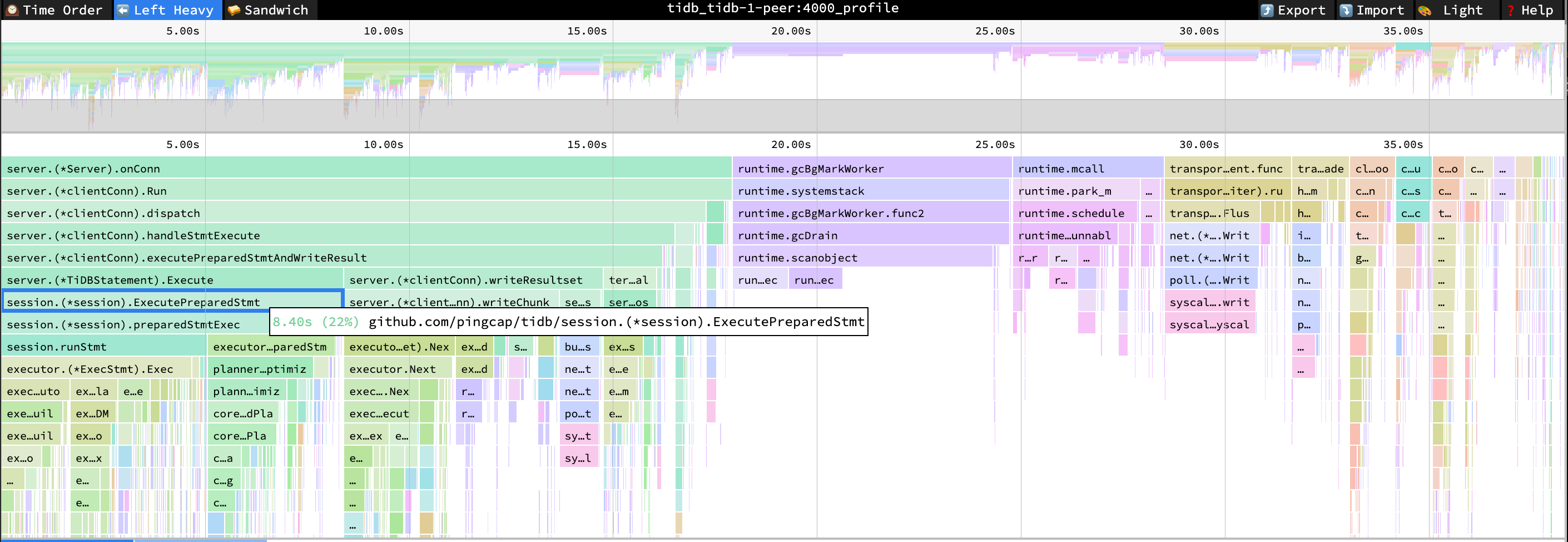
观察以下 TiDB 的火焰图,可以发现 Prepare 命令的高 CPU 消耗未再出现。
- ExecutePreparedStmt cpu = 22% cpu time = 8.4s
Performance Overview 面板
在 Performance Overview 面板中,最显著的变化是,CPS By Type 面板中三种 Stmt command 类型变成了一种,Database Time by SQL Type 面板中的 general 语句类型消失了,QPS 面板中 QPS 上升到了 30.9k。
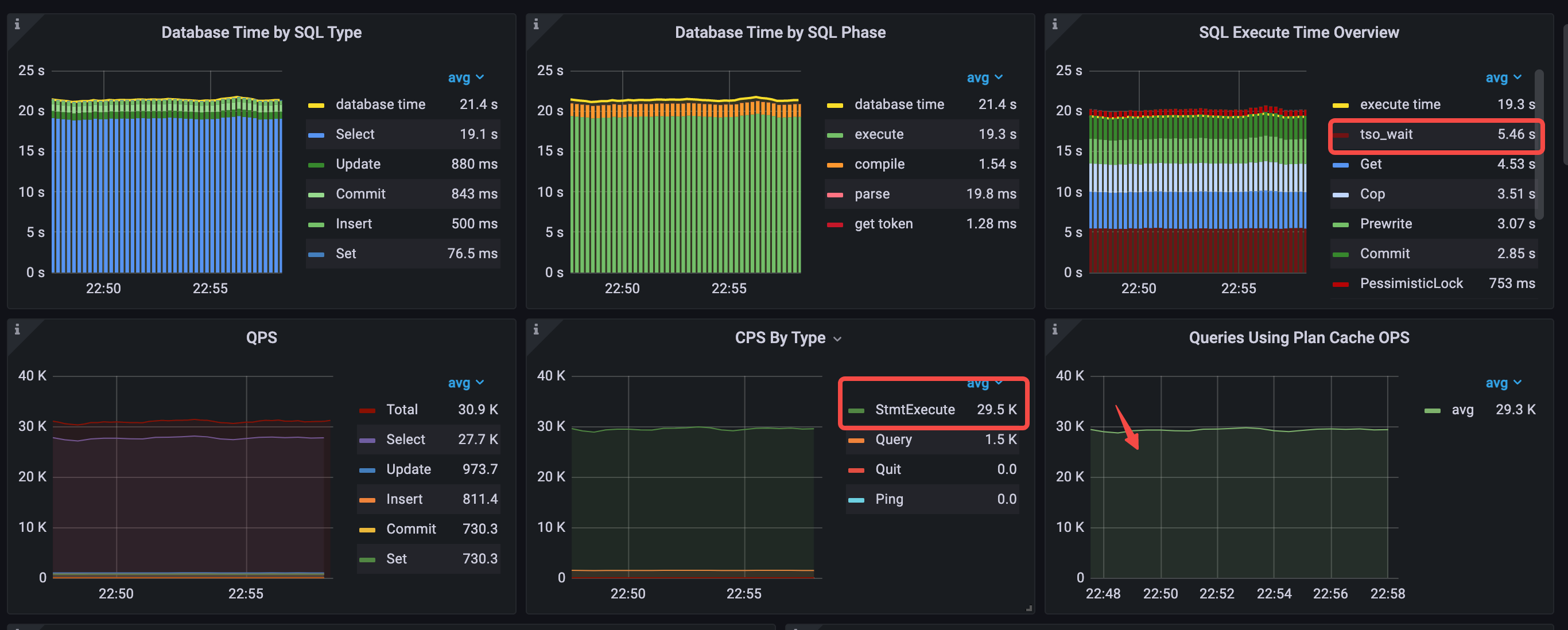
- Database Time by SQL Type 中 select 语句耗时最多,general 语句类型消失了
- Database Time by SQL Phase 中主要为 execute
- SQL Execute Time Overview 中占比最多的分别是 tso wait、Get 和 Cop
- 命中 plan cache,Queries Using Plan Cache OPS 大致等于 StmtExecute 每秒的次数
- CPS By Type 只有一种 command,即 StmtExecute
- avg QPS = 30.9k (22.1k->30.9k)
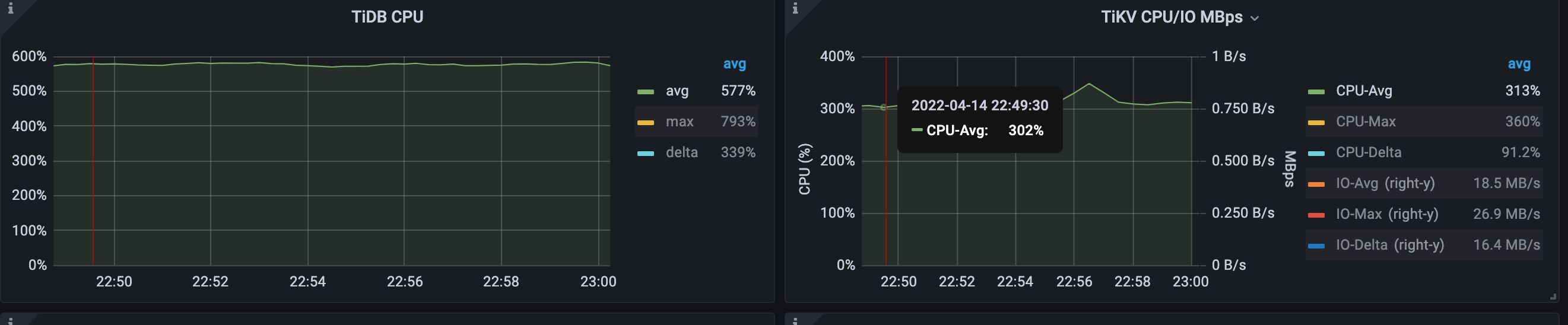
TiDB CPU 平均利用率从 827% 下降到 577%,随着 QPS 的上升,TiKV CPU 平均利用率上升为 313%。
关键的延迟指标如下:
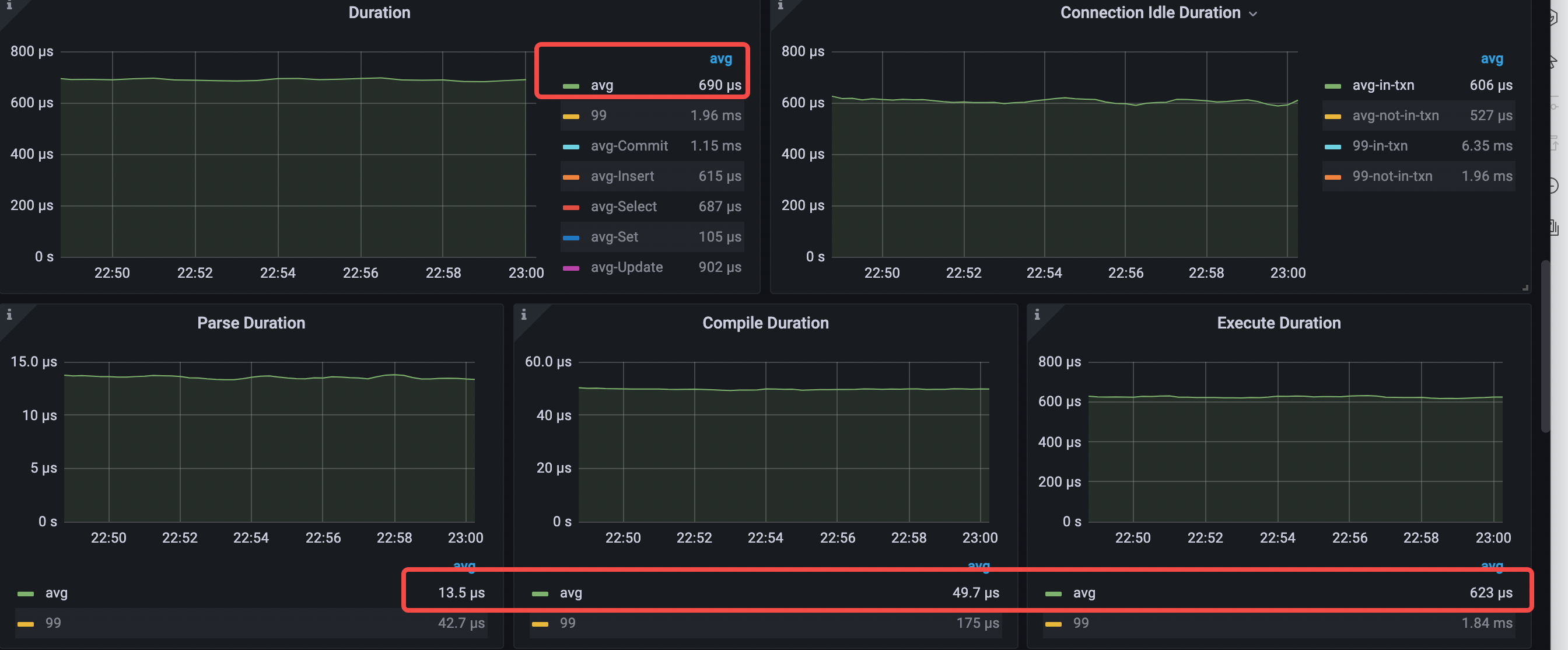
- avg query duration = 690μs (426->690μs)
- avg parse duration = 13.5μs (12.3μs->13.5μs )
- avg compile duration = 49.7μs (53.3μs->49.7μs)
- avg execution duration = 623μs (699us->623μs)
- avg pd tso wait duration = 196μs (224μs->196μs)
- connection idle duration avg-in-txn = 608μs (250μs->608μs)
分析结论
- 和场景 4 相比,场景 5 的 CPS By Type 只有 StmtExecute 这一种 command,减少了两次的网络往返,系统总体 QPS 上升。
- 在 QPS 上升的情况下,从 parse duration、compile duration、execution duration 来看延迟降低了,但 query duration 反而上升了。这是因为,StmtPrepare 和 StmtClose 处理的速度非常快,消除这两种 command 类型之后,平均的 query duration 就会上升。
- Database Time by SQL Phase 中 execute 占比非常高接近于 database time,同时 SQL Execute Time Overview 中占比最多的是 tso wait,超过四分之一的 execute 时间是在等待 tso。
- 每秒的 tso wait 总时间为 5.46s。平均 tso wait 时间为 196 us,每秒的 tso cmd 次数为 28k,非常接近于 QPS 的 30.9k。因为在 TiDB 对于
read committed隔离级别的实现中,事务中的每个 SQL 语句都需要都到 PD 请求 tso。
TiDB v6.0 提供了 rc read,针对 read committed 隔离级别进行了减少 tso cmd 的优化。该功能由全局变量 set global tidb_rc_read_check_ts=on;控制。启用此变量后,TiDB 默认行为和 repeatable-read 隔离级别一致,只需要从 PD 获取 start-ts 和 commit-ts。事务中的语句先使用 start-ts 从 TiKV 读取数据。如果读到的数据小于 start-ts,则直接返回数据;如果读到大于 start-ts 的数据,则需要丢弃数据,并向 PD 请求 TSO 再进行重试。后续语句的 for update ts 使用最新的 PD TSO。
场景 6:开启 tidb_rc_read_check_ts 变量降低 TSO 请求
应用配置
应用配置不变,和场景 5 不同的是,设置 set global tidb_rc_read_check_ts=on;,减少 TSO 请求。
性能分析
TiDB Dashboard
TiDB 的 CPU 火焰图没有明显变化。
- ExecutePreparedStmt cpu = 22% cpu time = 8.4s
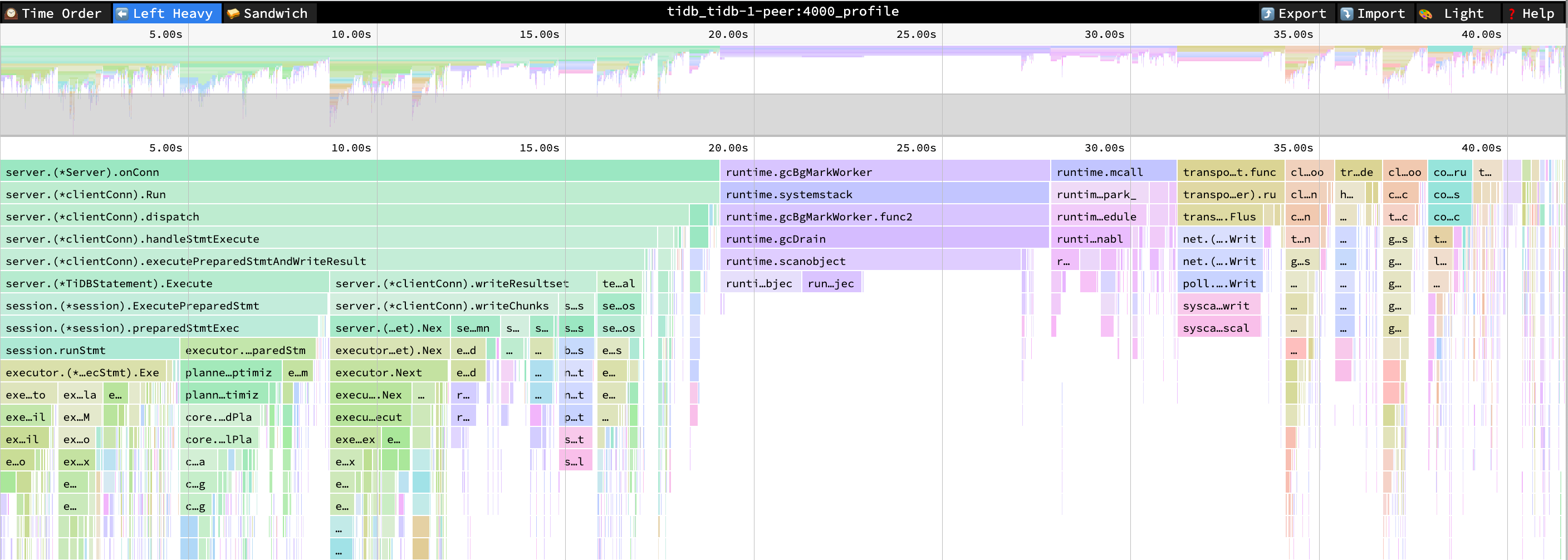
Performance Overview 面板
使用 RC read 之后,QPS 从 30.9k 上升到 34.9k,每秒消耗的 tso wait 时间从 5.46 s 下降到 456 ms。
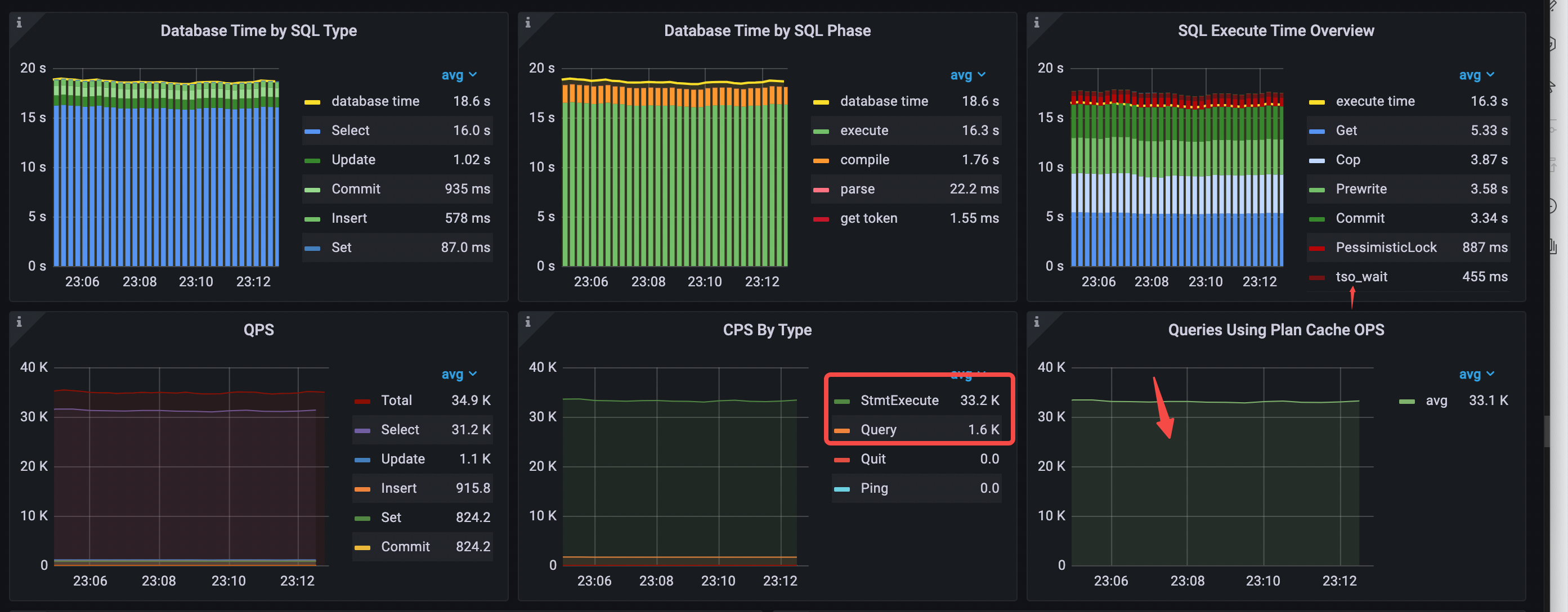
- Database Time by SQL Type 中 select 语句耗时最多
- Database Time by SQL Phase 中 execute 占比最高
- SQL Execute Time Overview 中占比最多的分别是 Get、Cop 和 Prewrite
- 命中 plan cache,Queries Using Plan Cache OPS 大致等于 StmtExecute 每秒的次数
- CPS By Type 只有一种 command
- avg QPS = 34.9k (30.9k->34.9k)
每秒 tso cmd 从 28.3k 下降到 2.7k。
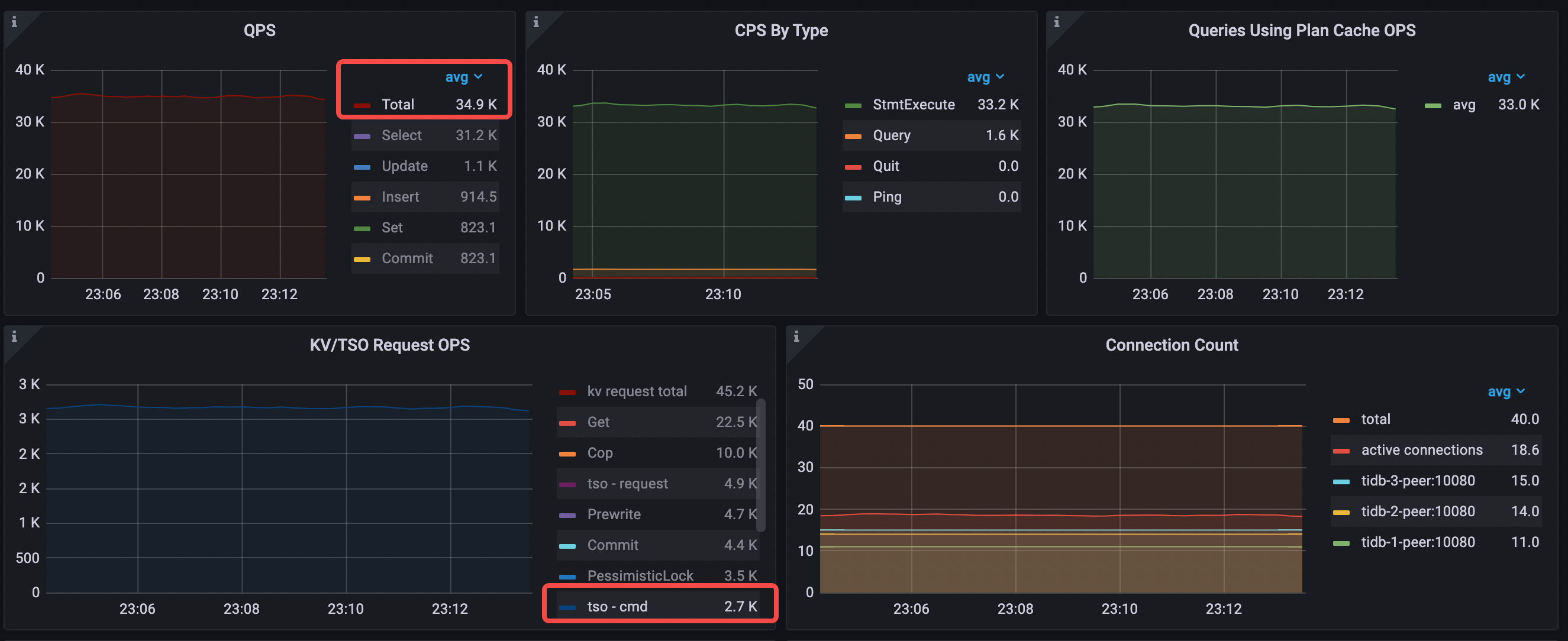
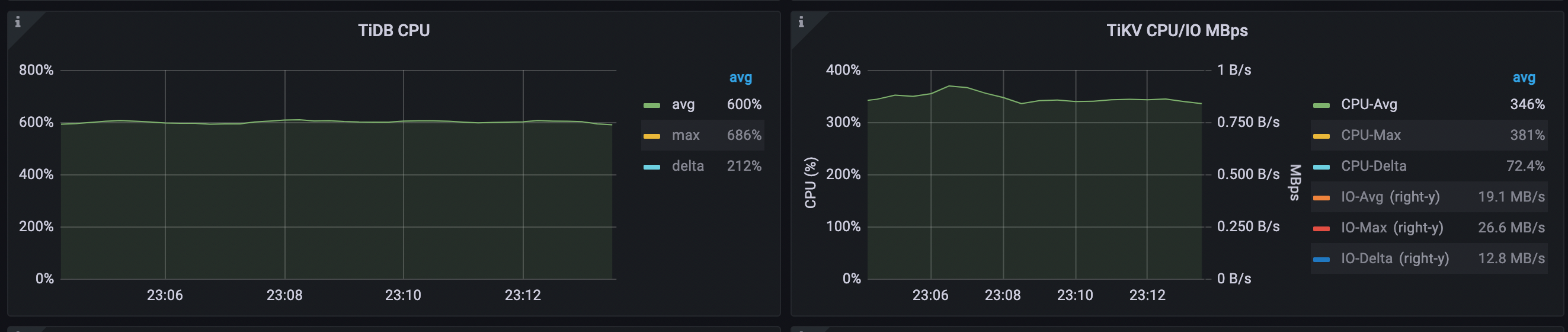
平均 TiDB CPU 上升为 603% (577%->603%)。
关键延迟指标如下:
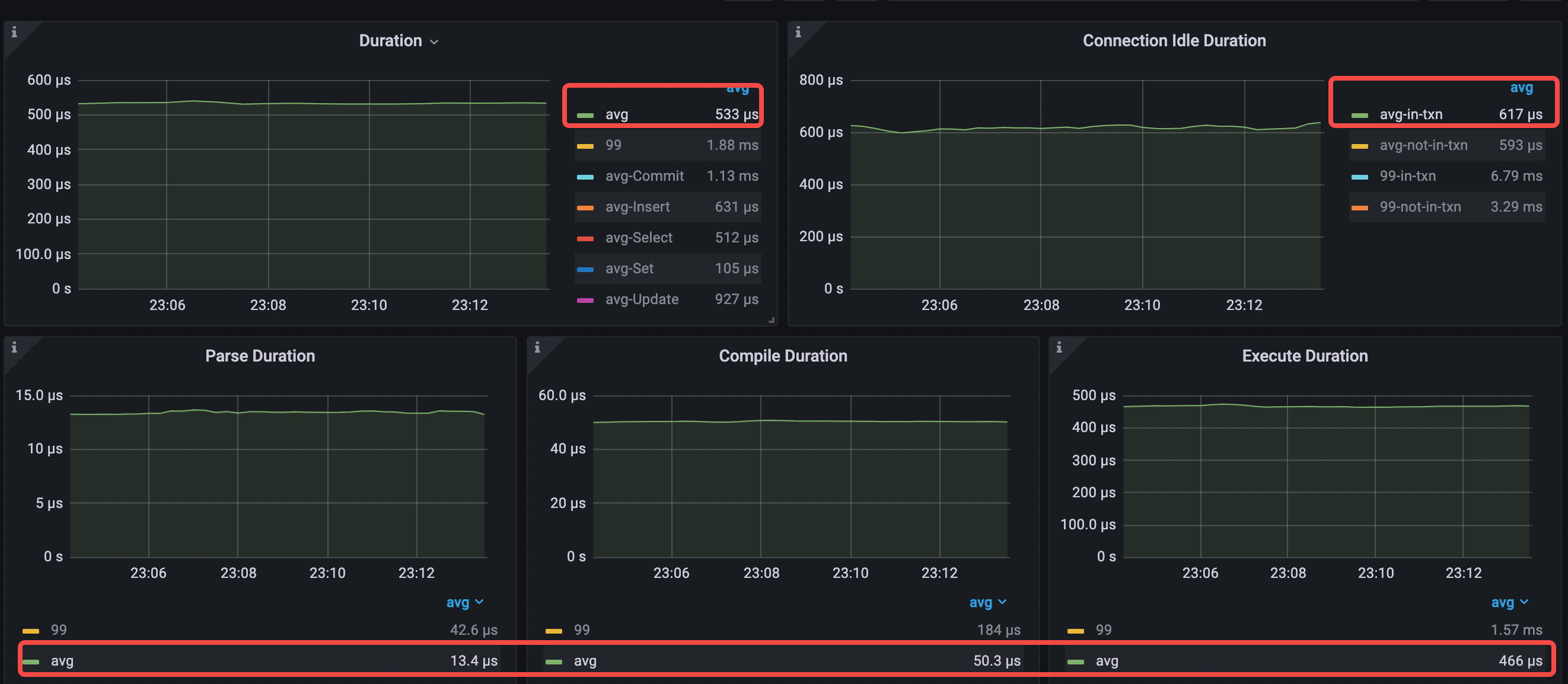
- avg query duration = 533μs (690μs->533μs)
- avg parse duration = 13.4μs (13.5μs->13.4μs )
- avg compile duration = 50.3μs (49.7μs->50.3μs)
- avg execution duration = 466μs (623μs->466μs)
- avg pd tso wait duration = 171μs (196μs->171μs)
分析结论
通过 set global tidb_rc_read_check_ts=on; 启用 RC Read 之后,RC Read 明显降低了 tso cmd 次数从而降低了 tso wait 以及平均 query duration,并且提升了 QPS。
当前数据库时间和延迟瓶颈都在 execute 阶段,而 execute 阶段占比最高的为 Get 和 Cop 读请求。这个负载中,大部分表是只读或者很少修改,可以使用 v6.0.0 的小表缓存功能,使用 TiDB 缓存这些小表的数据,降低 KV 读请求的等待时间和资源消耗。
场景 7:使用小表缓存
应用配置
应用配置不变,在场景 6 的基础上设置了对业务的只读表进行缓存 alter table t1 cache;。
性能分析
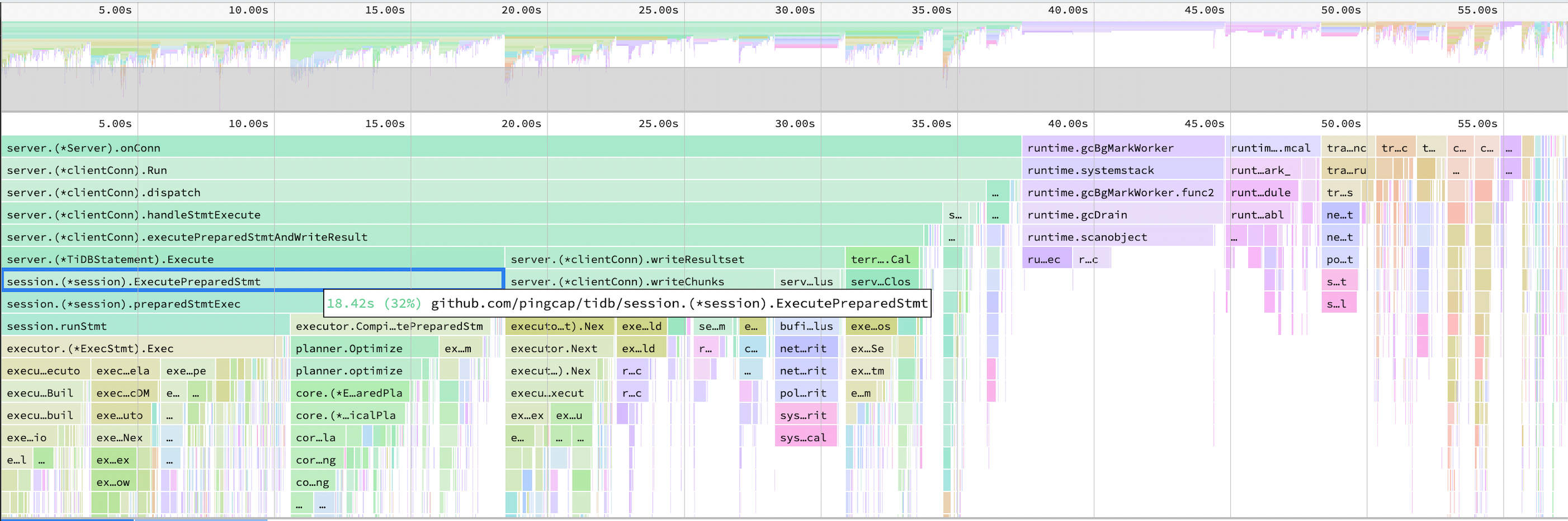
TiDB Dashboard
TiDB CPU 火焰图没有明显变化。
Performance Overview 面板
QPS 从 34.9k 上升到 40.9k,execute 时间中占比最高的 KV 请求类型变成了 Prewrite 和 Commit。Get 每秒的时间从 5.33 秒下降到 1.75 秒,Cop 每秒的时间从 3.87 下降到 1.09 秒。
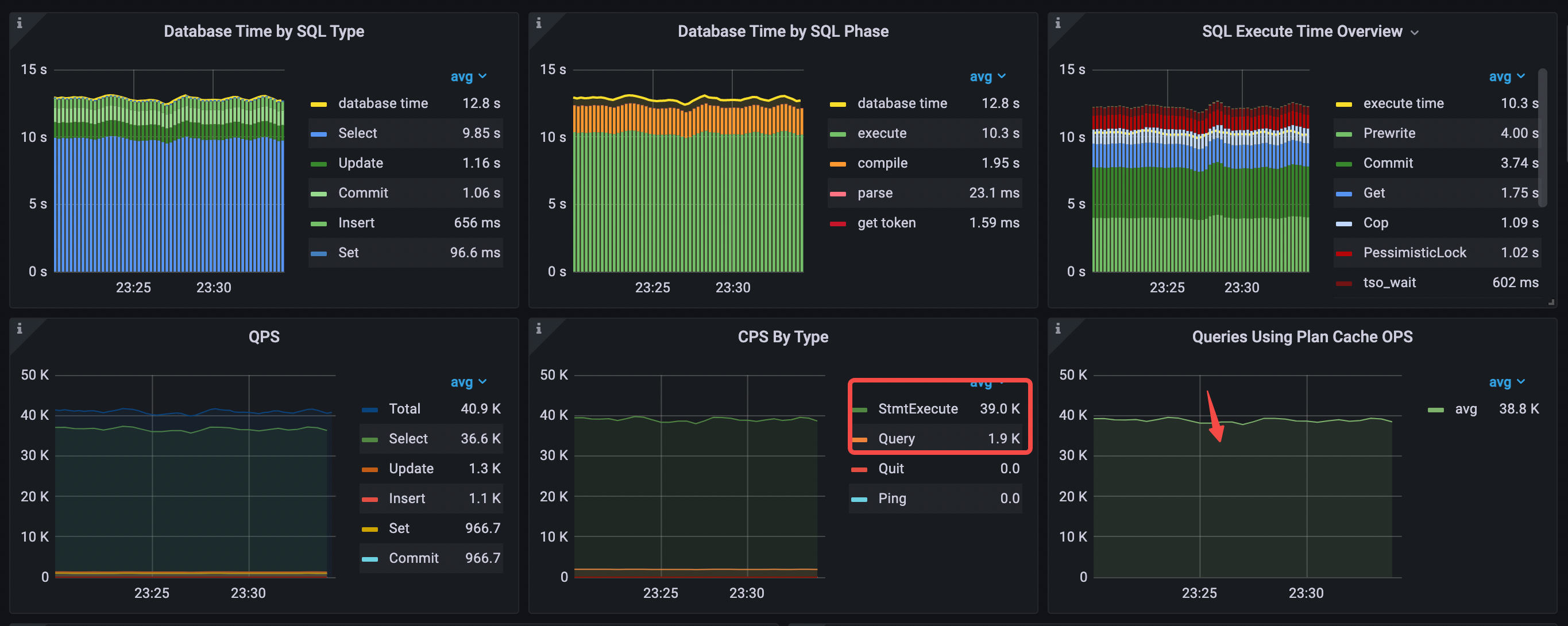
- Database Time by SQL Type 中 select 语句耗时最多
- Database Time by SQL Phase 中 execute 和 compile 占比最多
- SQL Execute Time Overview 中占比最多的分别是 Prewrite、Commit 和 Get
- 命中 plan cache,Queries Using Plan Cache OPS 大致等于 StmtExecute 每秒的次数
- CPS By Type 只有 1 种 command
- avg QPS = 40.9k (34.9k->40.9k)
TiDB CPU 平均利用率从 603% 下降到 478%,TiKV CPU 平均利用率从 346% 下降到 256%。

Query 平均延迟从 533 us 下降到 313 us。execute 平均延迟从 466 us 下降到 250 us。
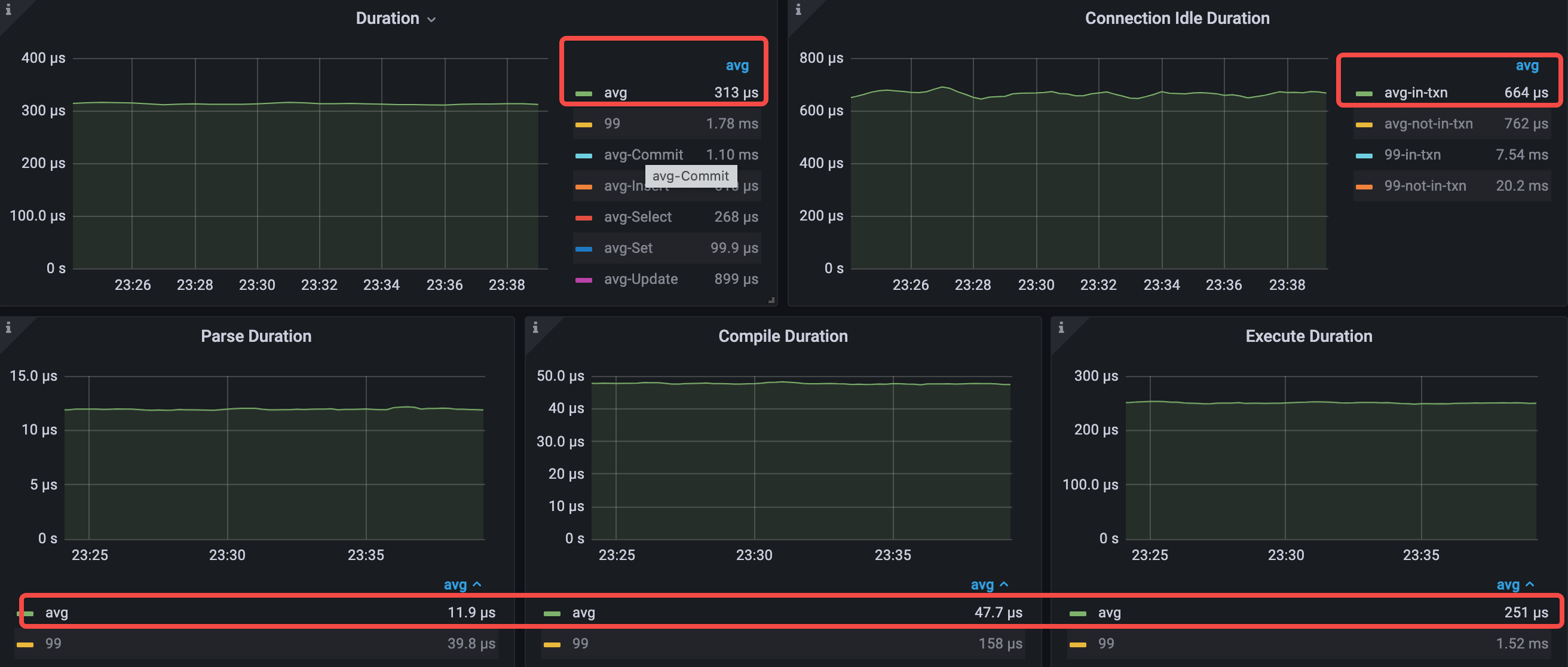
- avg query duration = 313μs (533μs->313μs)
- avg parse duration = 11.9μs (13.4μs->11.9μs)
- avg compile duration = 47.7μs (50.3μs->47.7μs)
- avg execution duration = 251μs (466μs->251μs)
分析结论
将所有只读表进行缓存后,可以看到,execute duration 下降非常明显,原因是所有只读表都缓存在 TiDB 中,不再需要到 TiKV 中查询数据,所以 query duration 下降,QPS 上升。
这个是比较乐观的结果,实际的业务中可能只读表的数据量较大无法全部在 TiDB 中进行缓存。另一个限制是,当前小表缓存的功能虽然支持写操作,但是写操作默认需要等 3 秒,确保所有 TiDB 节点的缓存失效,对于对延迟要求比较高的应用,可能暂时不太友好。
总结
以下表格展示了七个不同场景的性能表现:
| 指标 | 场景 1 | 场景 2 | 场景 3 | 场景 4 | 场景 5 | 场景 6 | 场景 7 | 对比场景 5 和场景 2 (%) | 对比场景 7 和场景 3(%) |
|---|---|---|---|---|---|---|---|---|---|
| query duration | 479μs | 1120μs | 528μs | 426μs | 690μs | 533μs | 313μs | -38% | -41% |
| QPS | 56.3k | 24.2k | 19.7k | 22.1k | 30.9k | 34.9k | 40.9k | +28% | +108% |
其中,场景 2 是应用程序使用 Query 接口的常见场景,场景 5 是应用程序使用 Prepared Statement 接口的理想场景。
- 对比场景 5 和场景 2,可以发现通过使用 Java 应用开发的最佳实践以及客户端缓存 Prepared Statement 对象,每条 SQL 只需要一次命令和数据库交互,就能命中执行计划缓存,从而使 Query 延迟下降了 38%,QPS 上升 28%,同时,TiDB CPU 平均利用率从 936% 下降到 577%。
- 对比场景 7 和场景 3,可以看到在场景 5 的基础上使用了 RC Read、小表缓存等 TiDB 最新的优化功能,延迟降低了 41%,QPS 提升了 108%,同时,TiDB CPU 平均利用率从 936% 下降到 478%。
通过对比各场景的性能表现,可以得出以下结论:
TiDB 的执行计划缓存对于 OLTP 发挥着至关重要的作用。而从 v6.0.0 开始引入的 RC Read 和小表缓存功能,在这个负载的深度优化中,也发挥了重要的作用。
TiDB 兼容 MySQL 协议的不同命令,最佳的性能表现来自于应用程序使用 Prepared Statement 接口,并设置以下 JDBC 连接参数:
useServerPrepStmts=true&cachePrepStmts=true&prepStmtCacheSize=1000&prepStmtCacheSqlLimit=20480&useConfigs=maxPerformance在性能分析和优化过程中,推荐使用 TiDB Dashboard (例如 Top SQL 功能和持续性能分析功能)和 Performance Overview 面板。
- Top SQL 功能允许你可视化地监控和探索数据库中各个 SQL 语句在执行过程中的 CPU 开销情况,从而对数据库性能问题进行优化和处理。
- 持续性能分析功能可以持续地收集 TiDB、TiKV、PD 各个实例的性能数据。应用程序使用不同接口跟 TiDB 交互时,TiDB 的 CPU 消耗有着巨大的差距。
- Performance Overview 面板提供了数据库时间的概览和 SQL 执行时间分解信息。借助这个面板,你可以进行基于数据库时间的性能分析和诊断,确定整个系统的性能瓶颈是否处于 TiDB 中。如果瓶颈在 TiDB 中,你可以通过数据库时间和延迟的分解,以及集群关键指标和资源使用情况,确认 TiDB 内部的性能瓶颈,并进行针对性的优化。
综合使用以上几个功能,你可以针对现实中的应用进行高效的性能分析和优化。