Overview 面板重要监控指标详解
使用 TiUP 部署 TiDB 集群时,一键部署监控系统 (Prometheus & Grafana),监控架构参见 TiDB 监控框架概述。
目前 Grafana Dashboard 整体分为 PD、TiDB、TiKV、Node_exporter、Overview、Performance_overview 等。
对于日常运维,我们单独挑选出重要的 Metrics 放在 Overview 页面,方便日常运维人员观察集群组件 (PD, TiDB, TiKV) 使用状态以及集群使用状态。
以下为 Overview Dashboard 监控说明:
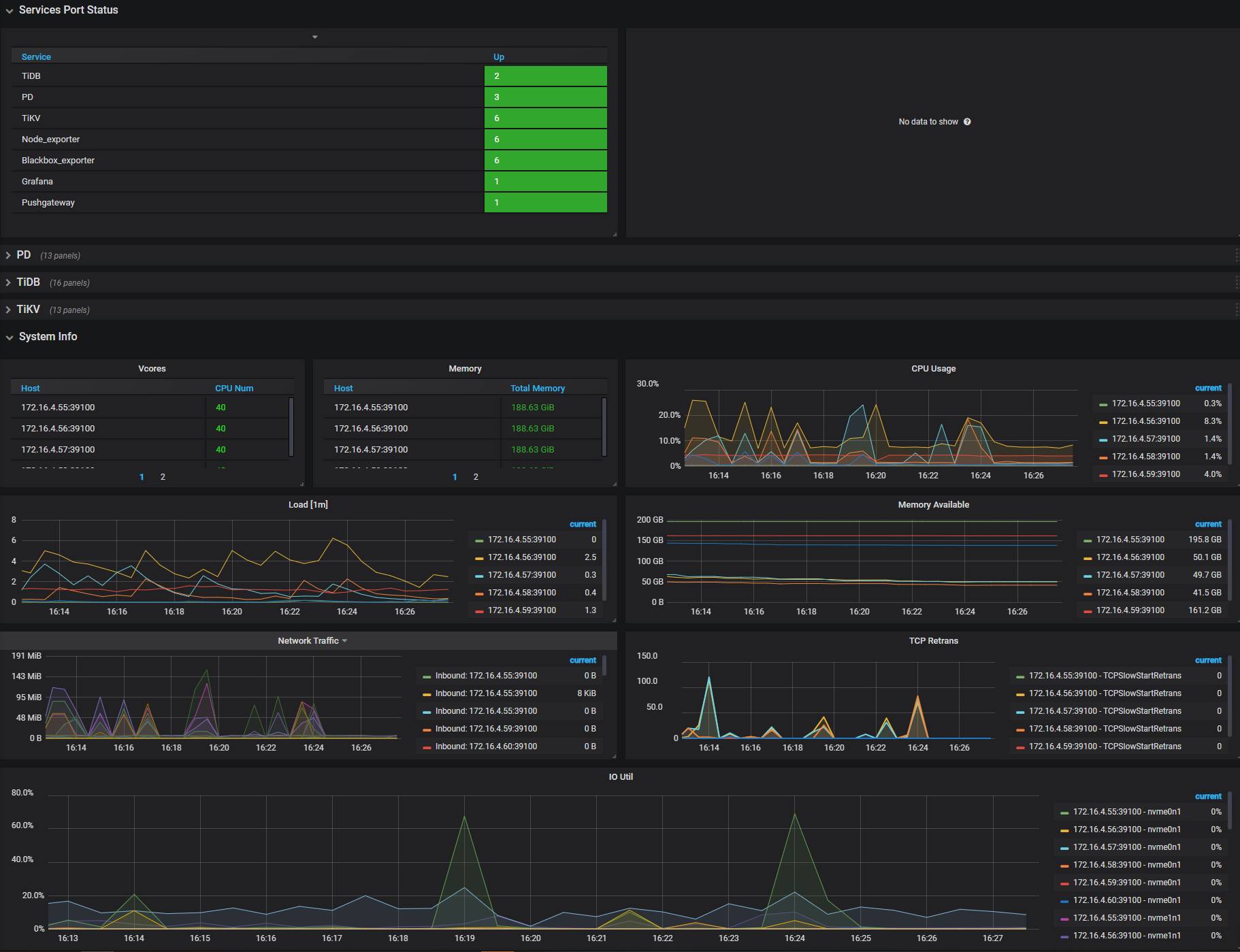
Services Port Status
- Services Up:各服务在线节点数量
PD
- PD role:当前 PD 的角色
- Storage capacity:TiDB 集群总可用数据库空间大小
- Current storage size:TiDB 集群目前已用数据库空间大小,TiKV 多副本的空间占用也会包含在内
- Normal stores:处于正常状态的节点数目
- Abnormal stores:处于异常状态的节点数目,正常情况应当为 0
- Number of Regions:当前集群的 Region 总量,请注意 Region 数量与副本数无关
- 99% completed_cmds_duration_seconds:单位时间内,99% 的 pd-server 请求执行时间小于监控曲线的值,一般 <= 5ms
- Handle_requests_duration_seconds:PD 发送请求的网络耗时
- Region health:每个 Region 的状态,通常情况下,pending 的 peer 应该少于 100,miss 的 peer 不能一直大于 0
- Hot write Region's leader distribution:每个 TiKV 实例上是写入热点的 leader 的数量
- Hot read Region's leader distribution:每个 TiKV 实例上是读取热点的 leader 的数量
- Region heartbeat report:TiKV 向 PD 发送的心跳个数
- 99% Region heartbeat latency:99% 的情况下,心跳的延迟
TiDB
- Statement OPS:不同类型 SQL 语句每秒执行的数量。按
SELECT、INSERT、UPDATE等来统计 - Duration:执行的时间
- 客户端网络请求发送到 TiDB,到 TiDB 执行结束后返回给客户端的时间。一般情况下,客户端请求都是以 SQL 语句的形式发送,但也可以包含
COM_PING、COM_SLEEP、COM_STMT_FETCH、COM_SEND_LONG_DATA之类的命令执行的时间 - 由于 TiDB 支持 Multi-Query,因此,可以接受客户端一次性发送的多条 SQL 语句,如:
select 1; select 1; select 1;。此时,统计的执行时间是所有 SQL 执行完之后的总时间
- 客户端网络请求发送到 TiDB,到 TiDB 执行结束后返回给客户端的时间。一般情况下,客户端请求都是以 SQL 语句的形式发送,但也可以包含
- CPS By Instance:每个 TiDB 实例上的命令统计。按照命令和执行结果成功或失败来统计
- Failed Query OPM:每个 TiDB 实例上,每秒钟执行 SQL 语句发生错误按照错误类型的统计(例如语法错误、主键冲突等)。包含了错误所属的模块和错误码
- Connection count:每个 TiDB 的连接数
- Memory Usage:每个 TiDB 实例的内存使用统计,分为进程占用内存和 Golang 在堆上申请的内存
- Transaction OPS:每秒事务执行数量统计
- Transaction Duration:事务执行的时间
- KV Cmd OPS:KV 命令执行数量统计
- KV Cmd Duration 99:KV 命令执行的时间
- PD TSO OPS:TiDB 每秒向 PD 发送获取 TSO 的 gRPC 请求的数量 (cmd) 和实际的 TSO 请求数量 (request);每个 gRPC 请求包含一批 TSO 请求
- PD TSO Wait Duration:TiDB 等待从 PD 获取 TS 的时间
- TiClient Region Error OPS:TiKV 返回 Region 相关错误信息的数量
- Lock Resolve OPS:TiDB 清理锁操作的数量。当 TiDB 的读写请求遇到锁时,会尝试进行锁清理
- Load Schema Duration:TiDB 从 TiKV 获取 Schema 的时间
- KV Backoff OPS:TiKV 返回错误信息的数量
TiKV
- leader:各个 TiKV 节点上 Leader 的数量分布
- region:各个 TiKV 节点上 Region 的数量分布
- CPU:各个 TiKV 节点的 CPU 使用率
- Memory:各个 TiKV 节点的内存使用量
- store size:每个 TiKV 实例的使用的存储空间的大小
- cf size:每个列族的大小
- channel full:每个 TiKV 实例上 channel full 错误的数量,正常情况下应当为 0
- server report failures:每个 TiKV 实例上报错的消息个数,正常情况下应当为 0
- scheduler pending commands:每个 TiKV 实例上 pending 命令的个数
- coprocessor executor count:TiKV 每秒收到的 coprocessor 操作数量,按照 coprocessor 类型统计
- coprocessor request duration:处理 coprocessor 读请求所花费的时间
- raft store CPU:raftstore 线程的 CPU 使用率,线程数量默认为 2(通过
raftstore.store-pool-size配置)。如果单个线程使用率超过 80%,说明使用率很高 - Coprocessor CPU:coprocessor 线程的 CPU 使用率
System Info
- Vcores:CPU 核心数量
- Memory:内存总大小
- CPU Usage:CPU 使用率,最大为 100%
- Load [1m]:1 分钟的负载情况
- Memory Available:剩余内存大小
- Network Traffic:网卡流量统计
- TCP Retrans:TCP 重传数量统计
- IO Util:磁盘使用率,最高为 100%,一般到 80% - 90% 就需要考虑加节点
图例