基于主备集群的容灾方案
使用主、备数据库进行容灾是一种常用的容灾方式。在这种方案下,系统有一个主用集群和一个备用集群。主集群用于处理用户的请求,备集群负责备份主集群的数据。当主集群发生故障时,系统可以切换到备集群,使用备份的数据继续提供服务。这样,系统就可以在发生故障的情况下继续正常运行,避免因为故障而导致的服务中断。
主备集群容灾方案具有如下优势:
- 高可用性:主、备集群的架构可以有效提高系统的可用性,使得系统在遇到故障时能够快速恢复。
- 快速切换:在主集群发生故障的情况下,系统可以快速切换到备用集群,继续提供服务。
- 数据一致性:备用集群会近实时备份主集群的数据,因此,在故障发生后切换到备集群时,数据基本是最新的。
本文包含以下主要内容:
- 构建主备集群
- 从主集群复制数据至备集群
- 监控集群
- 容灾切换
同时,本文还介绍了如何在备用集群上进行业务查询,以及如何在主备集群间进行双向同步。
基于 TiCDC 构建 TiDB 主备集群
架构概览
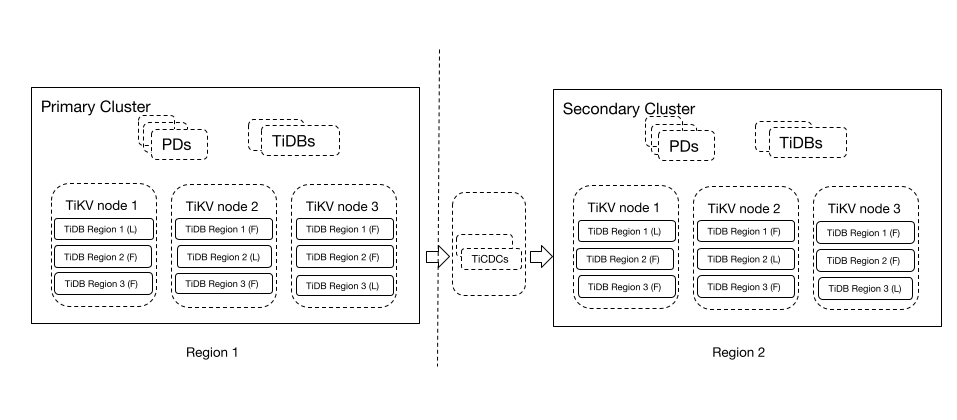
上述架构包含两个 TiDB 集群:Primary Cluster 和 Secondary Cluster。
- Primary Cluster:主用集群,运行在区域 1 (Region 1),三副本,用于处理读写业务。
- Secondary Cluster:备用集群,运行在区域 2 (Region 2),通过 TiCDC 从 Primary Cluster 同步数据。
这种容灾架构简洁易用,可以容忍区域级别的故障,既可以保证主用集群的写入性能不会下降,还可以在备用集群处理一些延迟不敏感的只读业务。该方案的 Recovery Point Objective (RPO) 在秒级别,Recovery Time Objective (RTO) 可以达到分钟级别甚至更低。这个方案适用于重要的生产系统。
搭建主备集群
本文将 TiDB 主集群和备用集群分别部署在两个不同的区域(区域 1 和区域 2)。由于主备集群之间存在一定的网络延迟,TiCDC 与 TiDB 备用集群应部署在一起,以实现最好的数据同步性能。在本教程示例中,每台服务器部署一个组件节点,具体的部署拓扑如下:
关于服务器配置信息,可以参考如下文档:
部署 TiDB 主集群和备用集群的详细过程,可以参考部署 TiDB 集群。
部署 TiCDC 组件需要注意的是,Secondary Cluster 和 TiCDC 需要在一起部署和管理,并且它们之间的网络需要能够连通。
如果需要在已有的 Primary Cluster 上部署 TiCDC,请参考部署 TiCDC 组件。
如果部署全新的 Primary Cluster 和 TiCDC 组件,则可以使用以下 TiUP 部署模版,并按照需要修改配置参数:
global: user: "tidb" ssh_port: 22 deploy_dir: "/tidb-deploy" data_dir: "/tidb-data" server_configs: {} pd_servers: - host: 10.0.1.1 - host: 10.0.1.2 - host: 10.0.1.3 tidb_servers: - host: 10.0.1.4 - host: 10.0.1.5 tikv_servers: - host: 10.0.1.6 - host: 10.0.1.7 - host: 10.0.1.8 monitoring_servers: - host: 10.0.1.9 grafana_servers: - host: 10.0.1.9 alertmanager_servers: - host: 10.0.1.9 cdc_servers: - host: 10.1.1.9 gc-ttl: 86400 data_dir: "/cdc-data" ticdc_cluster_id: "DR_TiCDC" - host: 10.1.1.10 gc-ttl: 86400 data_dir: "/cdc-data" ticdc_cluster_id: "DR_TiCDC"
从主集群复制数据到备用集群
搭建好 TiDB 主集群和备用集群之后,需要先将主集群的数据迁移到备用集群,然后创建同步任务从主集群复制实时变更数据到备用集群。
选择外部存储
数据迁移和实时变更数据复制都需要使用外部存储。推荐使用 Amazon S3 作为存储系统。如果 TiDB 集群部署在自建机房中,则推荐以下方式:
- 搭建 MinIO 作为备份存储系统,使用 S3 协议将数据备份到 MinIO 中。
- 挂载 NFS 盘(如 NAS)到 br、TiKV 和 TiCDC 实例节点,使用 POSIX 文件系统接口将备份数据写入对应的 NFS 目录中。
下面以 MinIO 为示例,仅供参考。注意需要在区域 1 或者区域 2 中准备独立的服务器部署 MinIO。
wget https://dl.min.io/server/minio/release/linux-amd64/minio
chmod +x minio
# 配置访问 MinIO 的 access-key 和 access-secret-id
export HOST_IP='10.0.1.10' # 替换为实际部署 MinIO 的机器 IP 地址
export MINIO_ROOT_USER='minio'
export MINIO_ROOT_PASSWORD='miniostorage'
# 创建 TiCDC redo log 和 backup 数据保存的目录,其中 redo、backup 为 bucket 名字
mkdir -p data/redo
mkdir -p data/backup
# 启动 MinIO,暴露端口在 6060
nohup ./minio server ./data --address :6060 &
上述命令启动了一个单节点的 MinIO server 模拟 S3 服务,相关参数为:
endpoint:http://10.0.1.10:6060/access-key:miniosecret-access-key:miniostoragebucket:redo/backup
其访问链接为:
s3://backup?access-key=minio&secret-access-key=miniostorage&endpoint=http://10.0.1.10:6060&force-path-style=true
数据迁移
在 TiDB 主备集群之间使用 TiDB 备份恢复功能 BR 进行数据迁移。
关闭垃圾回收机制 (GC)。为了保证增量迁移过程中新写入的数据不丢失,在开始备份之前,需要关闭上游集群的 GC 机制,以确保系统不再清理历史数据。
执行如下命令关闭 GC:
SET GLOBAL tidb_gc_enable=FALSE;查询
tidb_gc_enable的取值,以确认 GC 是否已关闭:SELECT @@global.tidb_gc_enable;输出结果为
0表明 GC 已关闭:+-------------------------+ | @@global.tidb_gc_enable | +-------------------------+ | 0 | +-------------------------+ 1 row in set (0.00 sec)备份数据。在 TiDB 主集群中执行
BACKUP语句备份数据:BACKUP DATABASE * TO '`s3://backup?access-key=minio&secret-access-key=miniostorage&endpoint=http://10.0.1.10:6060&force-path-style=true`';+----------------------+----------+--------------------+---------------------+---------------------+ | Destination | Size | BackupTS | Queue Time | Execution Time | +----------------------+----------+--------------------+---------------------+---------------------+ | s3://backup | 10315858 | 431434047157698561 | 2022-02-25 19:57:59 | 2022-02-25 19:57:59 | +----------------------+----------+--------------------+---------------------+---------------------+ 1 row in set (2.11 sec)备份语句提交成功后,TiDB 会返回关于备份数据的元信息,这里需要重点关注
BackupTS,它意味着该时间点之前的数据会被备份。本文后续步骤中,使用BackupTS作为实时变更数据复制的起始时间点。恢复数据。在 TiDB 备用集群中执行
RESTORE语句恢复数据:RESTORE DATABASE * FROM '`s3://backup?access-key=minio&secret-access-key=miniostorage&endpoint=http://10.0.1.10:6060&force-path-style=true`';+----------------------+----------+----------+---------------------+---------------------+ | Destination | Size | BackupTS | Queue Time | Execution Time | +----------------------+----------+----------+---------------------+---------------------+ | s3://backup | 10315858 | 0 | 2022-02-25 20:03:59 | 2022-02-25 20:03:59 | +----------------------+----------+----------+---------------------+---------------------+ 1 row in set (41.85 sec)
复制实时变更数据
完成以上数据迁移的操作步骤后,从备份的 BackupTS 时间点开始同步主集群增量变更数据到备用集群。
创建 TiCDC 同步任务 Changefeed。
创建 Changefeed 配置文件并保存为
changefeed.toml。[consistent] # eventual consistency:使用 redo log,提供上游灾难情况下的最终一致性。 level = "eventual" # 单个 redo log 文件大小,单位 MiB,默认值 64,建议该值不超过 128。 max-log-size = 64 # 刷新或上传 redo log 至 S3 的间隔,单位毫秒,默认 1000,建议范围 500-2000。 flush-interval = 2000 # 存储 redo log 的地址 storage = "s3://redo?access-key=minio&secret-access-key=miniostorage&endpoint=http://10.0.1.10:6060&force-path-style=true"在主用集群中,执行以下命令创建从主用集群到备用集群的同步链路:
tiup cdc cli changefeed create --server=http://10.1.1.9:8300 --sink-uri="mysql://{username}:{password}@10.1.1.4:4000" --changefeed-id="dr-primary-to-secondary" --start-ts="431434047157698561" --config changefeed.toml更多关于 Changefeed 的配置,请参考 TiCDC Changefeed 配置参数。
查询 Changefeed 是否正常运行。使用
changefeed query命令可以查询特定同步任务(对应某个同步任务的信息和状态),指定--simple或-s参数会简化输出,提供基本的同步状态和 checkpoint 信息。不指定该参数会输出详细的任务配置、同步状态和同步表信息。tiup cdc cli changefeed query -s --server=http://10.1.1.9:8300 --changefeed-id="dr-primary-to-secondary"{ "state": "normal", "tso": 431434047157998561, # changefeed 已经同步到的时间点 "checkpoint": "2020-08-27 10:12:19.579", # TSO 对应的物理时间点 "error": null }重新开启 GC。
TiCDC 可以保证未同步的历史数据不会被回收。因此,创建完从主集群到备用集群的 Changefeed 之后,就可以执行如下命令恢复集群的垃圾回收功能。
执行如下命令打开 GC:
SET GLOBAL tidb_gc_enable=TRUE;查询
tidb_gc_enable的取值,判断 GC 是否已开启:SELECT @@global.tidb_gc_enable;结果输出
1表明 GC 已开启:+-------------------------+ | @@global.tidb_gc_enable | +-------------------------+ | 1 | +-------------------------+ 1 row in set (0.00 sec)
主备集群状态监控
TiDB 目前还没有提供 DR Dashboard,你可以通过以下 Dashboard 了解 TiDB 主备集群的状态,从而决定是否需要进行容灾切换:
容灾切换
本部分介绍容灾演练,遇到真正灾难时的主备切换,以及重建灾备集群的步骤。
计划中的主备切换
定期对非常重要的业务系统进行容灾演练,检验系统的可靠性是非常有必要的。下面是容灾演练推荐的操作步骤,因为没有考虑演练中业务写入是否为模拟、业务访问数据库是否使用 proxy 服务等,与实际的演练场景会有出入,请根据你的实际情况进行修改。
停止主集群上的业务写入。
业务写入完全停止后,查询 TiDB 集群当前最新的 TSO (
Position):BEGIN; SELECT TIDB_CURRENT_TSO(); ROLLBACK;Query OK, 0 rows affected (0.00 sec) +--------------------+ | TIDB_CURRENT_TSO() | +--------------------+ | 452654700157468673 | +--------------------+ 1 row in set (0.00 sec) Query OK, 0 rows affected (0.00 sec)轮询 Changefeed
dr-primary-to-secondary的同步位置时间点 TSO 直到满足TSO >= Position。tiup cdc cli changefeed query -s --server=http://10.1.1.9:8300 --changefeed-id="dr-primary-to-secondary" { "state": "normal", "tso": 438224029039198209, # Changefeed 已经同步到的时间点 "checkpoint": "2022-12-22 14:53:25.307", # TSO 对应的物理时间点 "error": null }停止 Changefeed
dr-primary-to-secondary。通过删除 Changefeed 的方式,暂停 Changefeeddr-primary-to-secondary:tiup cdc cli changefeed remove --server=http://10.1.1.9:8300 --changefeed-id="dr-primary-to-secondary"创建 Changefeed
dr-secondary-to-primary。不需要指定 Changefeedstart-ts参数,Changefeed 从当前时间开始同步即可。修改业务应用的数据库访问配置,并重启业务应用,使得业务访问备用集群。
检查业务状态是否正常。
容灾演练后,再重复一遍以上步骤,即可恢复原有的系统主备配置。
真正灾难中主备切换
当发生真正的灾难,比如主集群所在区域停电,主备集群的同步链路可能会突然中断,从而导致备用集群数据处于事务不一致的状态。
恢复备用集群到事务一致的状态。在区域 2 的任意 TiCDC 节点执行以下命令,以向备用集群重放 redo log,使备用集群达到最终一致性状态:
tiup cdc redo apply --storage "s3://redo?access-key=minio&secret-access-key=miniostorage&endpoint=http://10.0.1.10:6060&force-path-style=true" --tmp-dir /tmp/redo --sink-uri "mysql://{username}:{password}@10.1.1.4:4000"命令中参数描述如下:
--storage:指定 redo log 所在的 S3 位置--tmp-dir:为从 S3 下载 redo log 的缓存目录--sink-uri:指定备份集群的地址
修改业务应用的数据库访问配置,并重启业务应用,使得业务访问备用集群。
检查业务状态是否正常。
灾难后重建主备集群
当 TiDB 主集群所遭遇的灾难解决后,或者主集群暂时不能恢复,此时 TiDB 集群是脆弱的,只有一个备用集群临时作为新的主集群提供服务。为了维持系统的可靠性,需要重建灾备集群保护系统的可靠性。
目前,重建 TiDB 主备集群,通用的方案是重新部署一个新的集群,组成新的容灾主备集群。操作请参考:
- 搭建主备集群。
- 从主集群复制数据到备用集群。
- 完成以上操作步骤后,如果你希望新集群成为主集群,那么请参考主从切换。
在备用集群上进行业务查询
在主备集群容灾场景中,将备用集群作为只读集群来运行一些延迟不敏感的查询是常见的需求,TiDB 主备集群容灾方案也提供了这种功能。
创建 Changefeed 时,你只需要在 changefeed 配置文件中开启 Syncpoint 功能,Changefeed 就会定期 (sync-point-interval) 在备用集群中通过执行 SET GLOBAL tidb_external_ts = @@tidb_current_ts 设置已复制完成的一致性快照点。
当业务需要从备用集群查询数据的时候,在业务应用中设置 SET GLOBAL|SESSION tidb_enable_external_ts_read = ON; 就可以在备用集群上获得事务状态完成的数据。
# 从 v6.4.0 开始支持,使用 Syncpoint 功能需要同步任务拥有下游集群的 SYSTEM_VARIABLES_ADMIN 或者 SUPER 权限
enable-sync-point = true
# 记录主集群和备用集群一致快照点的时间间隔,它也代表能读到完整事务的最大延迟时间,比如在备用集群读取到主集群两分钟之前的事务数据
# 配置格式为 h m s,例如 "1h30m30s"。默认值为 10m,最小值为 30s
sync-point-interval = "10m"
# Syncpoint 功能在下游表中保存的数据的时长,超过这个时间的数据会被清理
# 配置格式为 h m s,例如 "24h30m30s"。默认值为 24h
sync-point-retention = "1h"
[consistent]
# eventual consistency: 使用 redo log,提供上游灾难情况下的最终一致性。
level = "eventual"
# 单个 redo log 文件大小,单位 MiB,默认值 64,建议该值不超过 128。
max-log-size = 64
# 刷新或上传 redo log 至 S3 的间隔,单位毫秒,默认 1000,建议范围 500-2000。
flush-interval = 2000
# 存储 redo log
storage = "s3://redo?access-key=minio&secret-access-key=miniostorage&endpoint=http://10.0.1.10:6060&force-path-style=true"
在主备集群之间进行双向复制
在主备集群容灾场景中,部分用户希望让两个区域的 TiDB 集群互为灾备集群:用户的业务流量按其区域属性写入对应的 TiDB 集群,同时两套 TiDB 集群备份对方集群的数据。
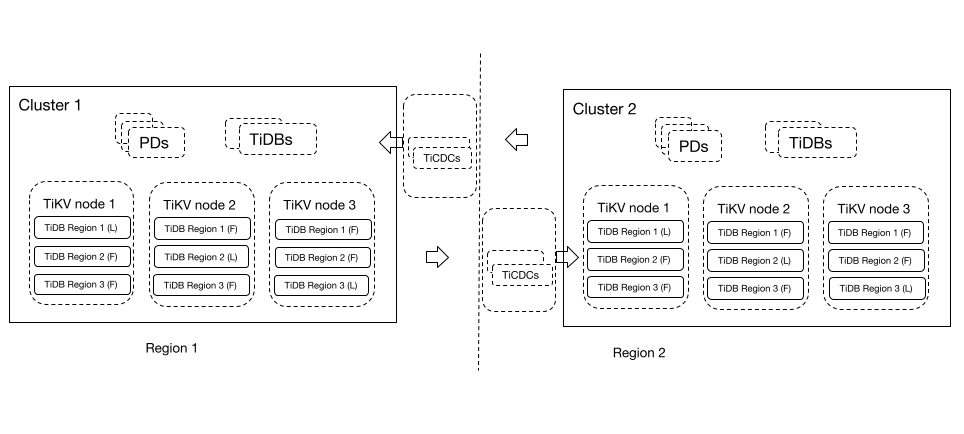
在双向复制容灾集群方案中,两个区域的 TiDB 集群互相备份对方的数据,使得它们可以在故障发生时互为灾备集群。这种方案既能满足安全性和可靠性的需求,同时也能保证数据库的写入性能。在计划中的主备切换场景中,不需要停止正在运行的 Changefeed 和启动新的 Changefeed 等操作,在运维上也更加简单。
搭建双向容灾复制集群的步骤,请参考教程 TiCDC 双向复制。
常见问题处理
以上任何步骤遇到问题,可以先通过 TiDB FAQ 查找问题的处理方法。如果问题仍不能解决,请尝试 TiDB 支持资源。