日常巡检
TiDB 作为分布式数据库,对比单机数据库机制更加复杂,其自带的监控项也很丰富。为了更便捷地运维 TiDB,本文介绍了运维 TiDB 集群需要常关注的关键性能指标。
TiDB Dashboard 关键指标
从 4.0 版本开始,TiDB 提供了一个新的 TiDB Dashboard 运维管理工具,集成在 PD 组件上,默认地址为 http://${pd-ip}:${pd_port}/dashboard。
使用 TiDB Dashboard,简化了对 TiDB 数据库的运维,可在一个界面查看整个分布式数据库集群的运行状况。下面举例说明。
实例面板
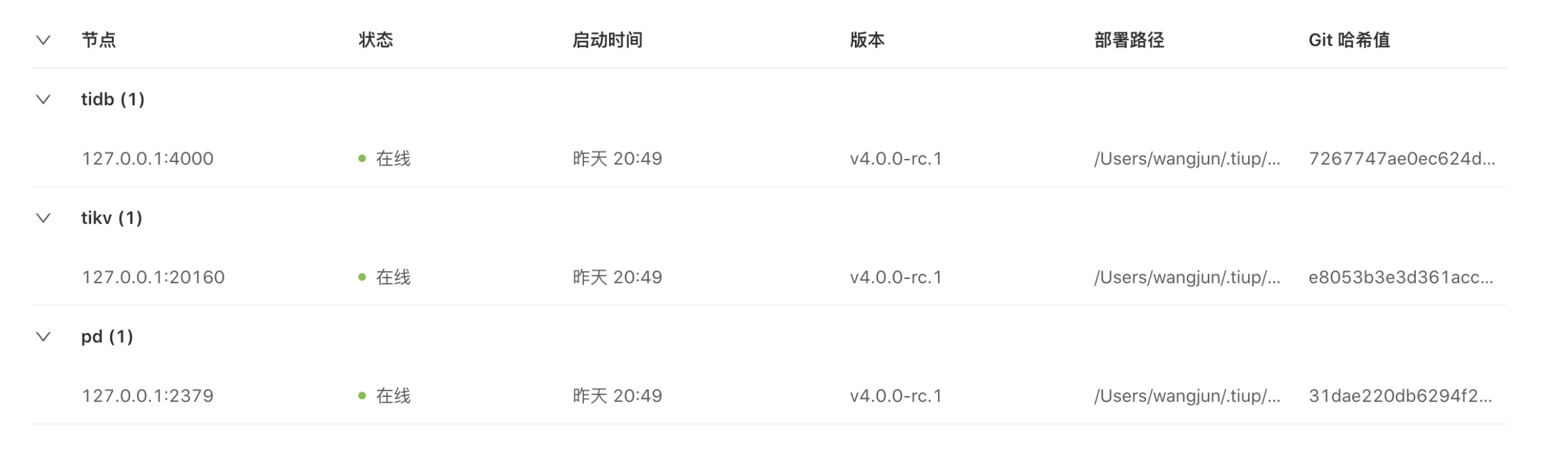
以上实例面板的各指标说明如下:
- 状态:用于查看实例状态是否正常,如果在线可忽略此项。
- 启动时间:是关键指标。如果有发现启动时间有变动,那么需要排查组件重启的原因。
- 版本、部署路径、Git 哈希值:通过查看这三个指标可以避免有部署路径和版本不一致或者错误的情况。
主机面板

通过主机面板可以查看 CPU、内存、磁盘使用率。当任何资源的使用率超过 80% 时,推荐扩容对应组件。
SQL 分析面板
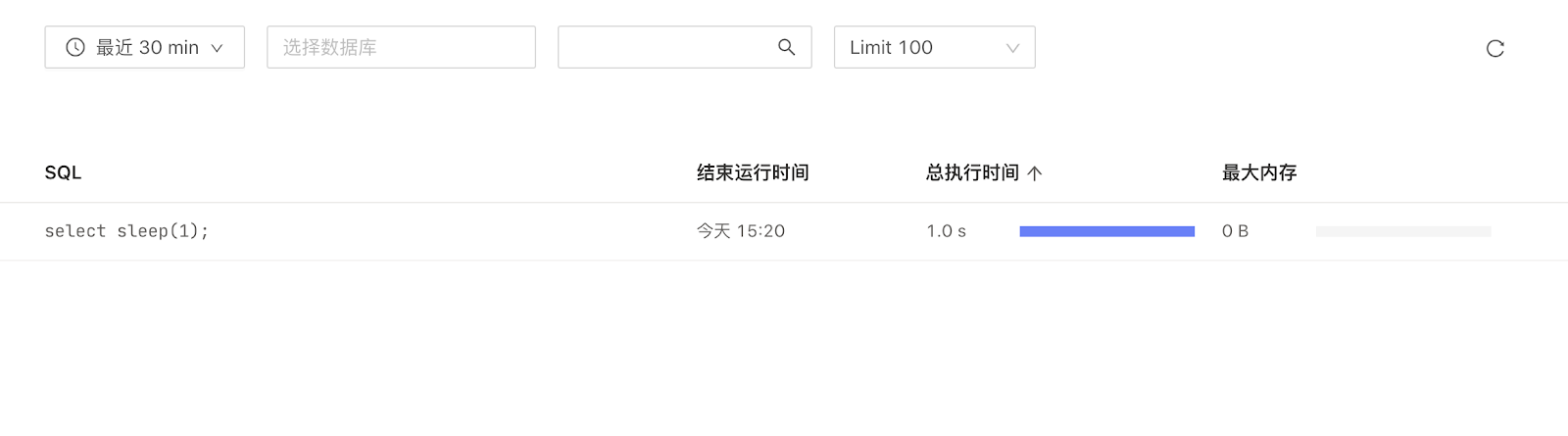
通过 SQL 分析面板可以分析对集群影响较大的慢 SQL,然后进行对应的 SQL 优化。
Region 信息面板
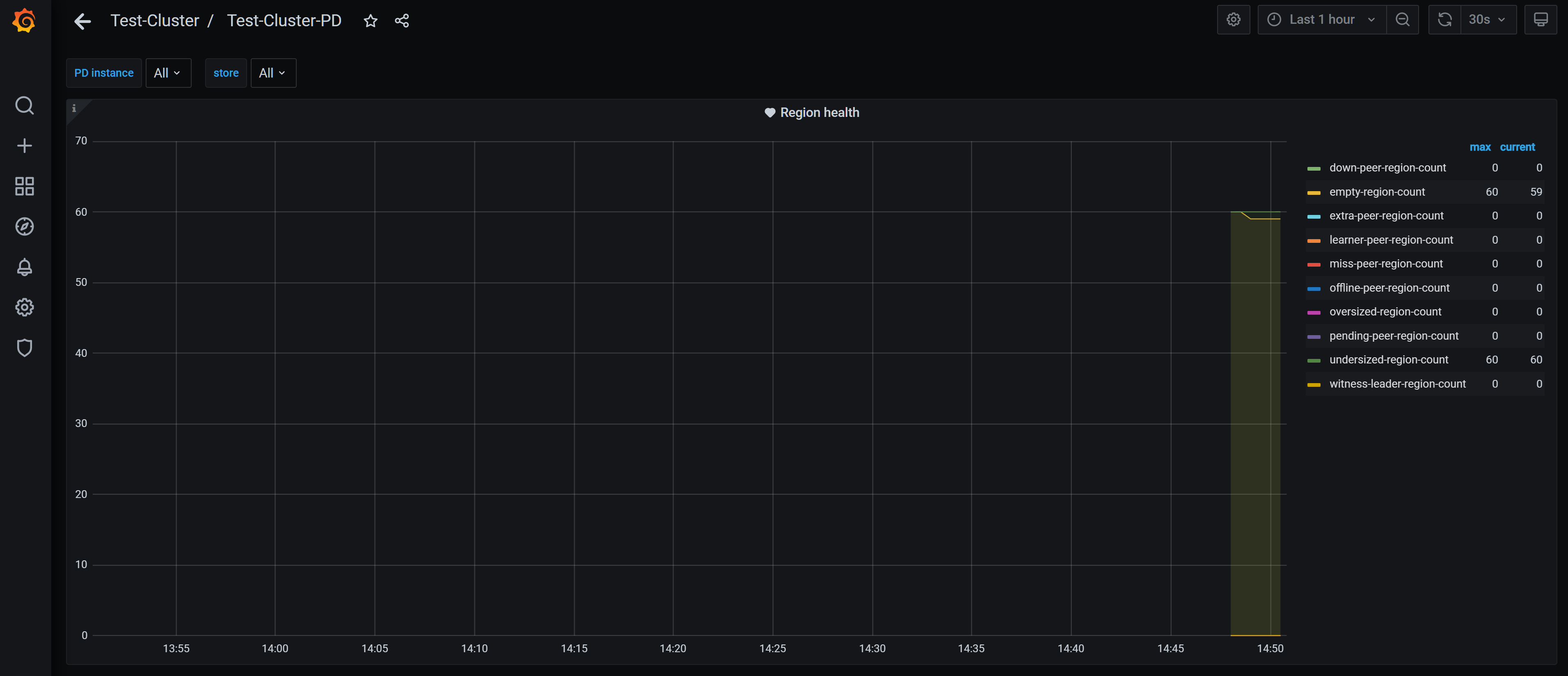
以上 Region 信息面板说明如下:
down-peer-region-count:Raft leader 上报有不响应 peer 的 Region 数量。empty-region-count:空 Region 的数量,大小小于 1 MiB。一般是TRUNCATE TABLE/DROP TABLE语句导致。如果数量较多,可以考虑开启跨表 Region merge。extra-peer-region-count:多副本的 Region 数量,调度过程中会产生。learner-peer-region-count:含有 learner peer 的 Region 数量。learner peer 的来源可能是多个,例如 TiFlash 上的 learner peer,以及配置的 Placement Rules 包含 learner peer。miss-peer-region-count:缺副本的 Region 数量,不会一直大于 0。offline-peer-region-count:peer 下线过程中的 Region 数量。oversized-region-count:Region 大小大于region-max-size或region-max-keys的 Region 数量。pending-peer-region-count:Raft log 落后的 Region 数量。由于调度产生少量的 pending peer 是正常的,但是如果 pending peer 的数量持续(超过 30 分钟)很高,可能存在问题。undersized-region-count:Region 大小小于max-merge-region-size或max-merge-region-keys的 Region 数量。
这些指标显示较小的非零值一般是正常的。
KV Request Duration
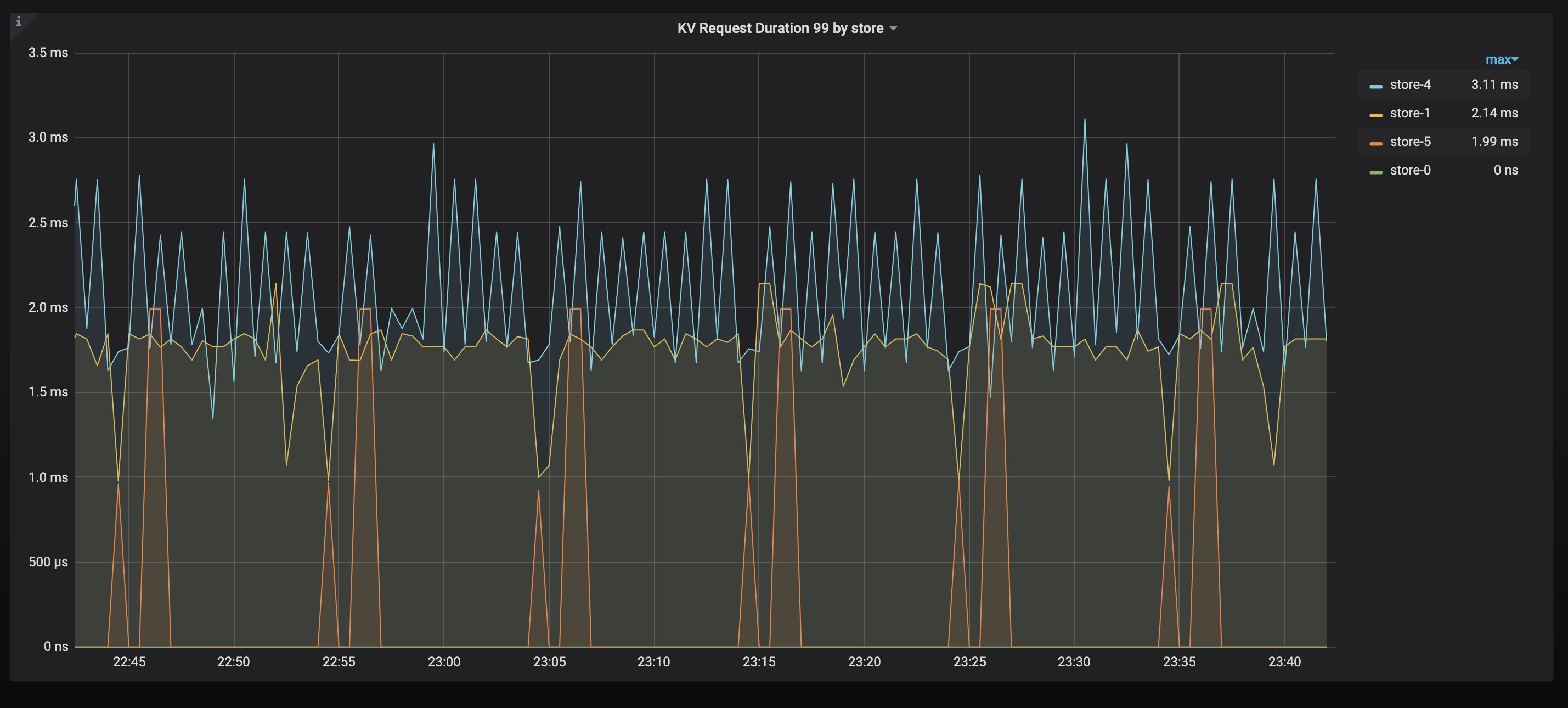
TiKV 当前 .99(百分位)的响应时间。如果发现有明显高的节点,可以排查是否有热点,或者相关节点性能较差。
PD TSO Wait Duration
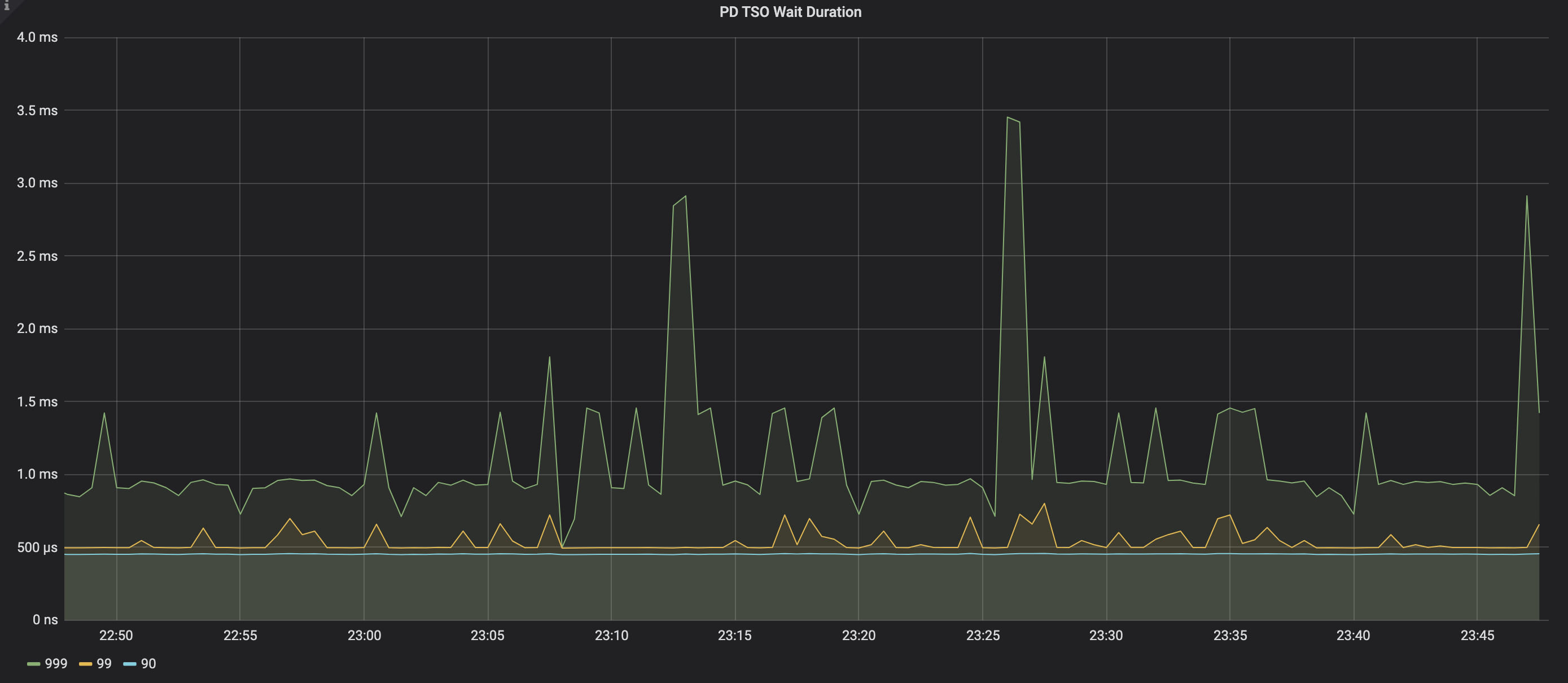
TiDB 从 PD 获取 TSO 的时间。如果相关响应时间较高,一般常见原因如下:
- TiDB 到 PD 的网络延迟较高,可以手动 Ping 一下网络延迟。
- TiDB 压力较高,导致获取较慢。
- PD 服务器压力较高,导致获取较慢。
Overview 面板
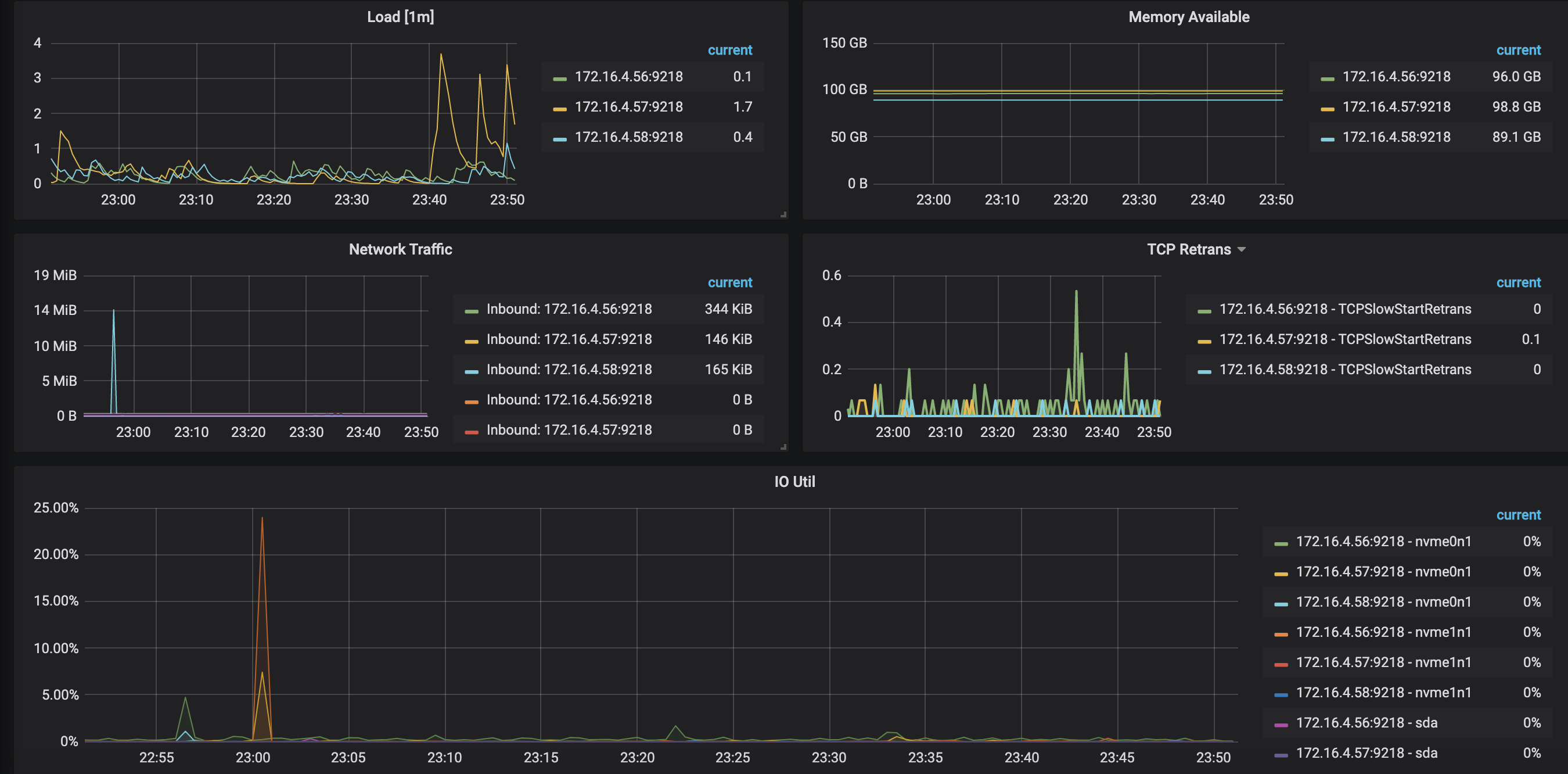
以上面板展示常见的负载、内存、网络、IO 监控。发现有瓶颈时,推荐扩容或者优化集群拓扑,优化 SQL、集群参数等。
异常监控面板
以上面板展示每个 TiDB 实例上,执行 SQL 语句发生的错误,并按照错误类型进行统计,例如语法错误、主键冲突等。
GC 状态面板
以上面板展示最后 GC(垃圾清理)的时间,观察 GC 是否正常。如果 GC 发生异常,可能会造成历史数据存留过多,影响访问效率。