代价模型
TiDB 在进行物理优化时会使用代价模型来进行索引选择和算子选择,如下图所示:
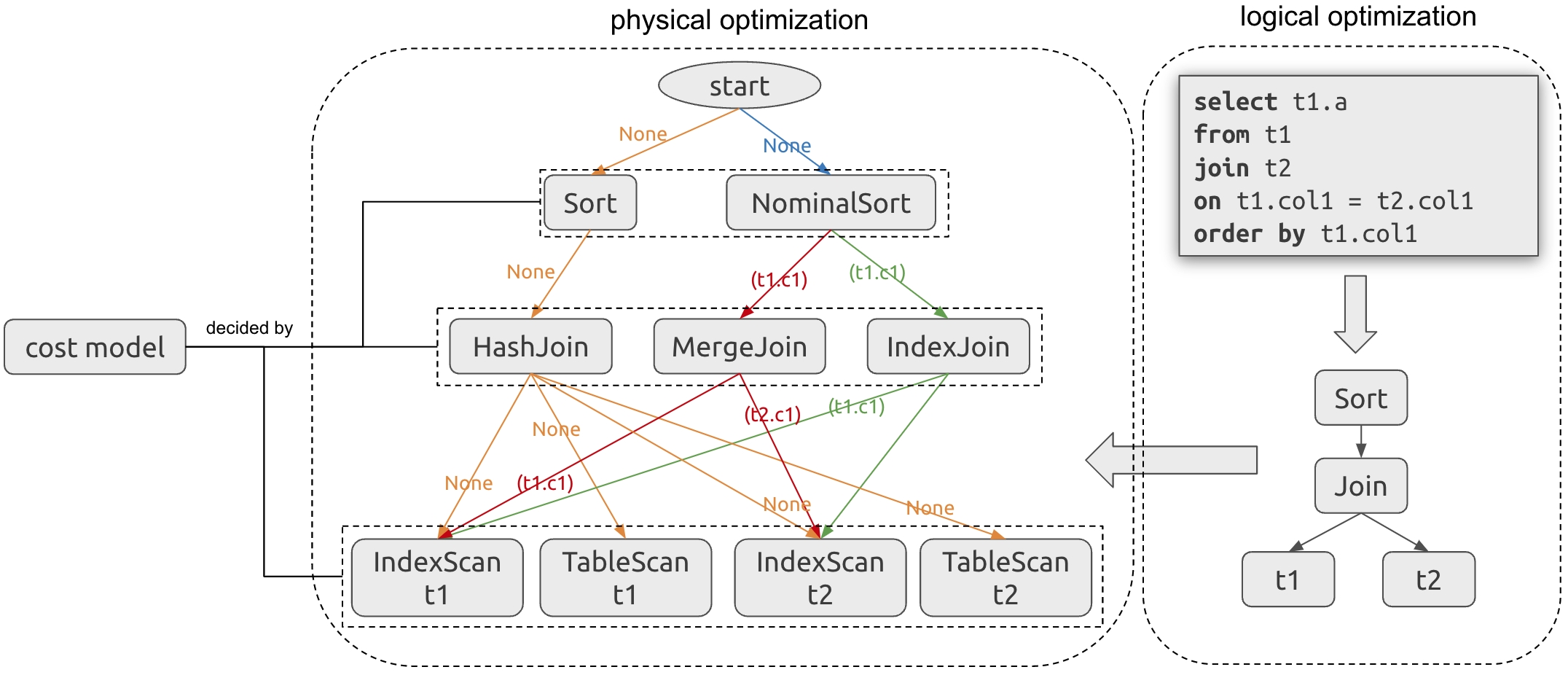
TiDB 会计算每个索引的访问代价和计划中每个物理算子的执行代价(如 HashJoin、IndexJoin 等),选择代价最低的计划。
下面是一个简化的例子,用来解释代价模型的原理,比如有这样一张表:
mysql> SHOW CREATE TABLE t;
+-------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| t | CREATE TABLE `t` (
`a` int DEFAULT NULL,
`b` int DEFAULT NULL,
`c` int DEFAULT NULL,
KEY `b` (`b`),
KEY `c` (`c`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin |
+-------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
在处理查询 SELECT * FROM t WHERE b < 100 and c < 100 时,假设 TiDB 对 b < 100 和 c < 100 的行数估计分别为 20 和 500,INT 类型索引行宽为 8,则 TiDB 会分别计算两个索引的代价:
- 索引
b的扫描代价 =b < 100的行数 * 索引b的行宽 = 20 * 8 = 160 - 索引
c的扫描代价 =c < 100的行数 * 索引c的行宽 = 500 * 8 = 4000
由于扫描 b 的代价更低,因此 TiDB 会选择 b 索引。
上述是一个简化后的例子,只是用于做原理解释,实际 TiDB 的代价模型会更加复杂。
Cost Model Version 2
TiDB v6.2.0 引入了新的代价模型 Cost Model Version 2。
Cost Model Version 2 对代价公式进行了更精确的回归校准,调整了部分代价公式,比此前版本的代价公式更加准确。
你可以通过设置变量 tidb_cost_model_version 来控制代价模型的版本。