Prepare 语句执行计划缓存
TiDB 支持对 Prepare/Execute 请求的执行计划缓存。其中包括以下两种形式的预处理语句:
- 使用
COM_STMT_PREPARE和COM_STMT_EXECUTE的协议功能; - 执行
Prepare/ExecuteSQL 语句查询;
TiDB 优化器对这两类查询的处理是一样的:Prepare 时将参数化的 SQL 查询解析成 AST(抽象语法树),每次 Execute 时根据保存的 AST 和具体的参数值生成执行计划。
当开启执行计划缓存后,每条 Prepare 语句的第一次 Execute 会检查当前查询是否可以使用执行计划缓存,如果可以则将生成的执行计划放进一个由 LRU 链表构成的缓存中;在后续的 Execute 中,会先从缓存中获取执行计划,并检查是否可用,如果获取和检查成功则跳过生成执行计划这一步,否则重新生成执行计划并放入缓存中。
对于某些非 PREPARE 语句,TiDB 可以像 Prepare/Execute 语句一样支持执行计划缓存,详情请参考非 Prepare 语句执行计划缓存。
在当前版本中,当 Prepare 语句符合以下条件任何一条,查询或者计划不会被缓存:
SELECT、UPDATE、INSERT、DELETE、Union、Intersect、Except以外的 SQL 语句;- 访问临时表、包含生成列的表的查询,或使用静态模式(即
tidb_partition_prune_mode设置为static)访问分区表的查询; - 查询中包含非关联子查询,例如
SELECT * FROM t1 WHERE t1.a > (SELECT 1 FROM t2 WHERE t2.b < 1); - 执行计划中带有
PhysicalApply算子的关联子查询,例如SELECT * FROM t1 WHERE t1.a > (SELECT a FROM t2 WHERE t1.b > t2.b); - 包含
ignore_plan_cache或set_var这两个 Hint 的查询,例如SELECT /*+ ignore_plan_cache() */ * FROM t或SELECT /*+ set_var(max_execution_time=1) */ * FROM t; - 包含除
?外其他变量(即系统变量或用户自定义变量)的查询,例如select * from t where a>? and b>@x; - 查询包含无法被缓存函数。目前不能被缓存的函数有:
database()、current_user、current_role、user、connection_id、last_insert_id、row_count、version、like; LIMIT后面带有变量(例如LIMIT ?或LIMIT 10, ?)且变量值大于 10000 的执行计划不缓存;?直接在Order By后的查询,如Order By ?,此时?表示根据Order By后第几列排序,排序列不同的查询使用同一个计划可能导致错误结果,故不缓存;如果是普通表达式,如Order By a+?则会缓存;?紧跟在Group by后的查询,如Group By ?,此时?表示根据Group By后第几列聚合,聚合列不同的查询使用同一个计划可能导致错误结果,故不缓存;如果是普通表达式,如Group By a+?则会缓存;?出现在窗口函数Window Frame定义中的查询,如(partition by year order by sale rows ? preceding);如果?出现在窗口函数的其他位置,则会缓存;- 用参数进行
int和string比较的查询,如c_int >= ?或者c_int in (?, ?)等,其中?为字符串类型,如set @x='123';此时为了保证结果和 MySQL 兼容性,需要每次对参数进行调整,故不会缓存; - 会访问
TiFlash的计划不会被缓存; - 大部分情况下计划中含有
TableDual的计划将将不会被缓存,除非当前执行的Prepare语句不含参数,则对应的TableDual计划可以被缓存。 - 访问 TiDB 系统视图的查询,如
information_schema.columns。不建议使用Prepare/Execute语句访问系统视图。
TiDB 对 ? 的个数有限制,如果超过了 65535 个,则会报错 Prepared statement contains too many placeholders。
LRU 链表是设计成 session 级别的缓存,因为 Prepare/Execute 不能跨 session 执行。LRU 链表的每个元素是一个 key-value 对,value 是执行计划,key 由如下几部分组成:
- 执行
Execute时所在数据库的名字; Prepare语句的标识符,即紧跟在PREPARE关键字后的名字;- 当前的 schema 版本,每条执行成功的 DDL 语句会修改 schema 版本;
- 执行
Execute时的 SQL Mode; - 当前设置的时区,即系统变量
time_zone的值; - 系统变量
sql_select_limit的值;
key 中任何一项变动(如切换数据库、重命名 Prepare 语句、执行 DDL、修改 SQL Mode/time_zone 的值)、或 LRU 淘汰机制触发都会导致 Execute 时无法命中执行计划缓存。
成功从缓存中获取到执行计划后,TiDB 会先检查执行计划是否依然合法,如果当前 Execute 在显式事务里执行,并且引用的表在事务前序语句中被修改,而缓存的执行计划对该表访问不包含 UnionScan 算子,则它不能被执行。
在通过合法性检测后,会根据当前最新参数值,对执行计划的扫描范围做相应调整,再用它执行获取数据。
关于执行计划缓存和查询性能有几点值得注意:
- 不管计划是否已经被缓存,都会受到 SQL Binding 的影响。对于没有被缓存的计划,即在第一次执行
Execute时,会受到已有 SQL Binding 的影响;而对于已经缓存的计划,如果有新的 SQL Binding 被创建产生,则原有已经被缓存的计划会失效。 - 已经被缓存的计划不会受到统计信息更新、优化规则和表达式下推黑名单更新的影响,仍然会使用已经保存在缓存中的计划。
- 重启 TiDB 实例时(如不停机滚动升级 TiDB 集群),
Prepare信息会丢失,此时执行execute stmt ...可能会遇到Prepared Statement not found的错误,此时需要再执行一次prepare stmt ...。 - 考虑到不同
Execute的参数会不同,执行计划缓存为了保证适配性会禁止一些和具体参数值密切相关的激进查询优化手段,导致对特定的一些参数值,查询计划可能不是最优。比如查询的过滤条件为where a > ? and a < ?,第一次Execute时参数分别为 2 和 1,考虑到这两个参数下次执行时可能会是 1 和 2,优化器不会生成对当前参数最优的TableDual执行计划。 - 如果不考虑缓存失效和淘汰,一份执行计划缓存会对应各种不同的参数取值,理论上也会导致某些取值下执行计划非最优。比如查询过滤条件为
where a < ?,假如第一次执行Execute时用的参数值为 1,此时优化器生成最优的IndexScan执行计划放入缓存,在后续执行Execute时参数变为 10000,此时TableScan可能才是更优执行计划,但由于执行计划缓存,执行时还是会使用先前生成的IndexScan。因此执行计划缓存更适用于查询较为简单(查询编译耗时占比较高)且执行计划较为固定的业务场景。
自 v6.1.0 起,执行计划缓存功能默认打开,可以通过变量 tidb_enable_prepared_plan_cache 启用或关闭这项功能。
在开启了执行计划缓存功能后,可以通过 SESSION 级别的系统变量 last_plan_from_cache 查看上一条 Execute 语句是否使用了缓存的执行计划,例如:
MySQL [test]> create table t(a int);
Query OK, 0 rows affected (0.00 sec)
MySQL [test]> prepare stmt from 'select * from t where a = ?';
Query OK, 0 rows affected (0.00 sec)
MySQL [test]> set @a = 1;
Query OK, 0 rows affected (0.00 sec)
-- 第一次 execute 生成执行计划放入缓存
MySQL [test]> execute stmt using @a;
Empty set (0.00 sec)
MySQL [test]> select @@last_plan_from_cache;
+------------------------+
| @@last_plan_from_cache |
+------------------------+
| 0 |
+------------------------+
1 row in set (0.00 sec)
-- 第二次 execute 命中缓存
MySQL [test]> execute stmt using @a;
Empty set (0.00 sec)
MySQL [test]> select @@last_plan_from_cache;
+------------------------+
| @@last_plan_from_cache |
+------------------------+
| 1 |
+------------------------+
1 row in set (0.00 sec)
如果发现某一组 Prepare/Execute 由于执行计划缓存导致了非预期行为,可以通过 SQL Hint ignore_plan_cache() 让该组语句不使用缓存。还是用上述的 stmt 为例:
MySQL [test]> prepare stmt from 'select /*+ ignore_plan_cache() */ * from t where a = ?';
Query OK, 0 rows affected (0.00 sec)
MySQL [test]> set @a = 1;
Query OK, 0 rows affected (0.00 sec)
MySQL [test]> execute stmt using @a;
Empty set (0.00 sec)
MySQL [test]> select @@last_plan_from_cache;
+------------------------+
| @@last_plan_from_cache |
+------------------------+
| 0 |
+------------------------+
1 row in set (0.00 sec)
MySQL [test]> execute stmt using @a;
Empty set (0.00 sec)
MySQL [test]> select @@last_plan_from_cache;
+------------------------+
| @@last_plan_from_cache |
+------------------------+
| 0 |
+------------------------+
1 row in set (0.00 sec)
诊断 Prepared Plan Cache
通过 SHOW WARNINGS 诊断
对于无法进行缓存的查询或计划,可通过 SHOW WARNINGS 语句查看查询或计划是否被缓存。如果未被缓存,则可在结果中查看无法被缓存的原因。示例如下:
mysql> PREPARE st FROM 'SELECT * FROM t WHERE a > (SELECT MAX(a) FROM t)'; -- 该查询包含子查询,因此无法被缓存
Query OK, 0 rows affected, 1 warning (0.01 sec)
mysql> SHOW WARNINGS; -- 查看查询计划无法被缓存的原因
+---------+------+-----------------------------------------------+
| Level | Code | Message |
+---------+------+-----------------------------------------------+
| Warning | 1105 | skip plan-cache: sub-queries are un-cacheable |
+---------+------+-----------------------------------------------+
1 row in set (0.00 sec)
mysql> PREPARE st FROM 'SELECT * FROM t WHERE a<?';
Query OK, 0 rows affected (0.00 sec)
mysql> SET @a='1';
Query OK, 0 rows affected (0.00 sec)
mysql> EXECUTE st USING @a; -- 该优化中进行了非 INT 类型到 INT 类型的转换,产生的执行计划可能随着参数变化而存在风险,因此 TiDB 不缓存该计划
Empty set, 1 warning (0.01 sec)
mysql> SHOW WARNINGS;
+---------+------+----------------------------------------------+
| Level | Code | Message |
+---------+------+----------------------------------------------+
| Warning | 1105 | skip plan-cache: '1' may be converted to INT |
+---------+------+----------------------------------------------+
1 row in set (0.00 sec)
通过 Statements Summary 诊断
在 Statements Summary 表中包含有 plan_cache_unqualified 和 plan_cache_unqualified_last_reason 两个字段,分别表示对应查询无法使用 Plan Cache 的次数和原因,可以通过这两个字段来进行诊断:
mysql> SELECT digest_text, plan_cache_unqualified, plan_cache_unqualified_last_reason FROM information_schema.statements_summary WHERE plan_cache_unqualified > 0 ORDER BY plan_cache_unqualified DESC
LIMIT 10;
+---------------------------------+------------------------+----------------------------------------+
| digest_text | plan_cache_unqualified | plan_cache_unqualified_last_reason |
+---------------------------------+------------------------+----------------------------------------+
| select * from `t` where `a` < ? | 10 | '1' may be converted to INT |
| select * from `t` order by ? | 4 | query has 'order by ?' is un-cacheable |
| select database ( ) from `t` | 2 | query has 'database()' is un-cacheable |
...
+---------------------------------+------------------------+----------------------------------------+
10 row in set (0.01 sec)
Prepared Plan Cache 的内存管理
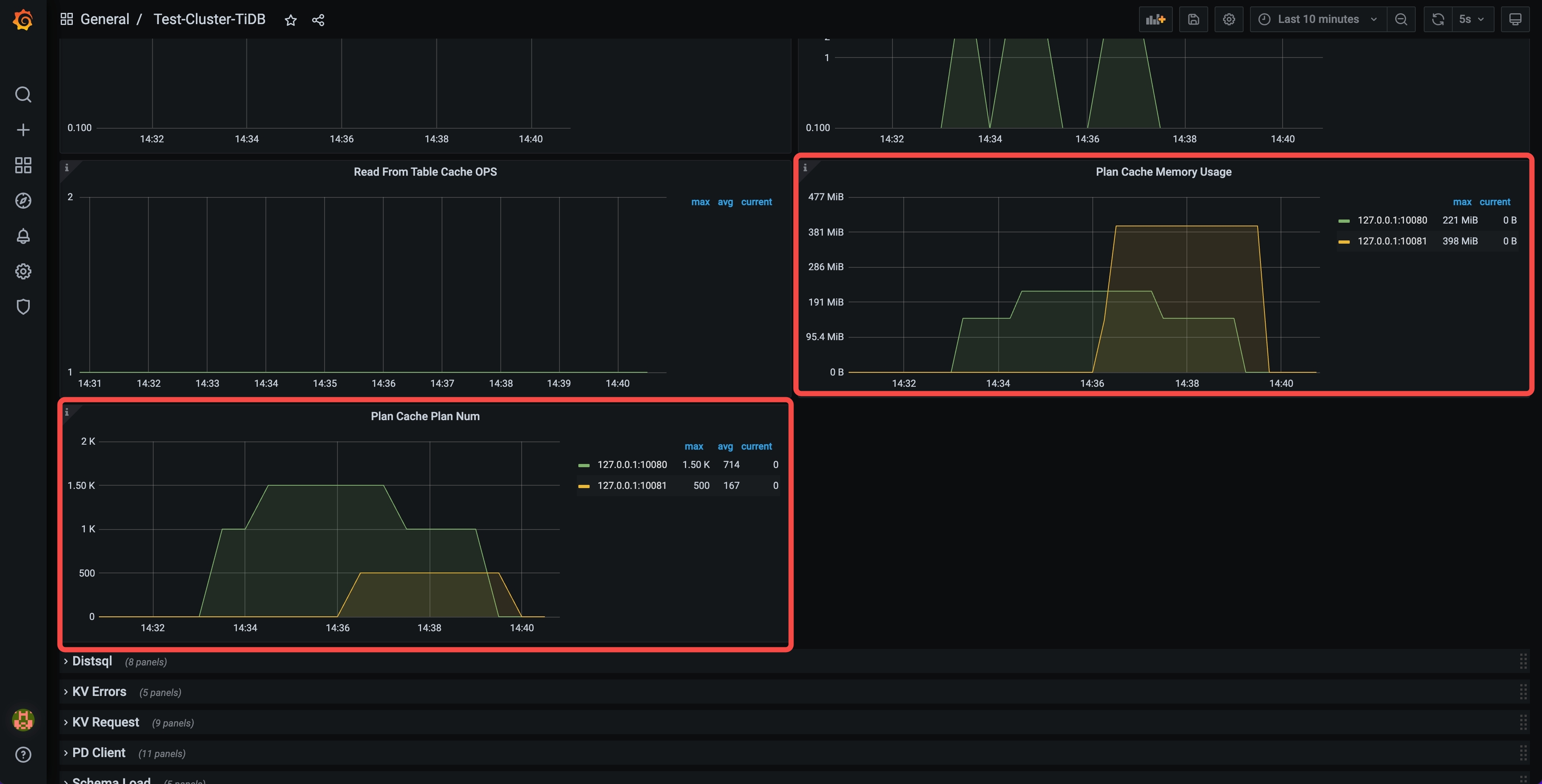
使用 Prepared Plan Cache 会有一定的内存开销,可以通过 Grafana 中的 Plan Cache Memory Usage 监控查看每台 TiDB 实例上所有 SESSION 所缓存的计划占用的总内存。
对于每台 TiDB 实例上所缓存的执行计划总数量,可以通过 Grafana 中的 Plan Cache Plan Num 监控查看。
Grafana 中 Plan Cache Memory Usage 和 Plan Cache Plan Num 监控如下图所示:
从 v7.1.0 开始,你可以通过变量 tidb_session_plan_cache_size 来设置每个 SESSION 最多缓存的计划数量。针对不同的环境,推荐的设置如下,你可以结合监控进行调整:
- TiDB Server 实例内存阈值 <= 64 GiB 时,
tidb_session_plan_cache_size = 50 - TiDB Server 实例内存阈值 > 64 GiB 时,
tidb_session_plan_cache_size = 100
从 v7.1.0 开始,你可以通过变量 tidb_plan_cache_max_plan_size 来设置可以缓存的计划的最大大小,默认为 2 MB。超过该值的执行计划将不会被缓存到 Plan Cache 中。
当 TiDB Server 的内存余量小于一定阈值时,会触发 Plan Cache 的内存保护机制,此时会对一些缓存的计划进行逐出。
目前该阈值由变量 tidb_prepared_plan_cache_memory_guard_ratio 控制,默认为 0.1,即 10%,也就是当剩余内存不足 10%(使用内存超过 90%)时,会触发此机制。
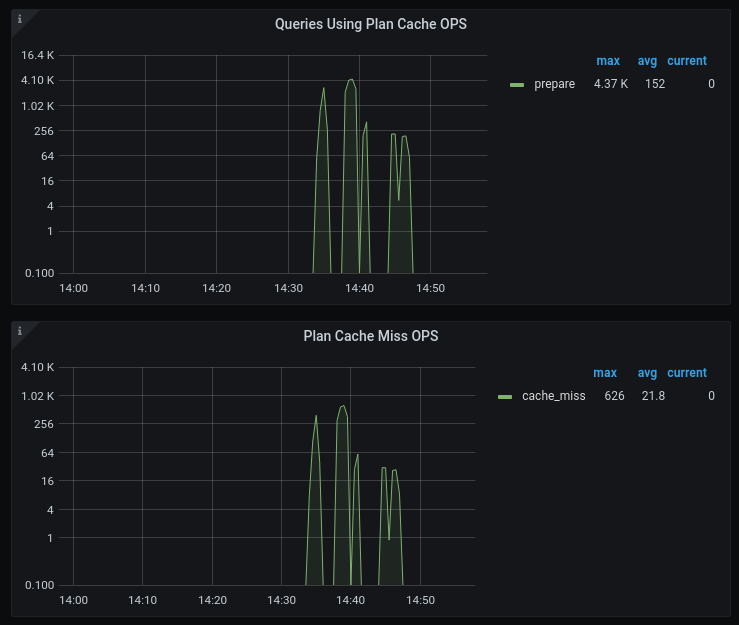
由于内存限制,Plan Cache 可能出现 Cache Miss 的情况,可以通过 Grafana 中的 Plan Cache Miss OPS 监控查看。
手动清空计划缓存
通过执行 ADMIN FLUSH [SESSION | INSTANCE] PLAN_CACHE 语句,你可以手动清空计划缓存。
该语句中的作用域 [SESSION | INSTANCE] 用于指定需要清空的缓存级别,可以为 SESSION 或 INSTANCE。如果不指定作用域,该语句默认清空 SESSION 级别的缓存。
下面是一个清空计划缓存的例子:
MySQL [test]> create table t (a int);
Query OK, 0 rows affected (0.00 sec)
MySQL [test]> prepare stmt from 'select * from t';
Query OK, 0 rows affected (0.00 sec)
MySQL [test]> execute stmt;
Empty set (0.00 sec)
MySQL [test]> execute stmt;
Empty set (0.00 sec)
MySQL [test]> select @@last_plan_from_cache; -- 选择计划缓存
+------------------------+
| @@last_plan_from_cache |
+------------------------+
| 1 |
+------------------------+
1 row in set (0.00 sec)
MySQL [test]> admin flush session plan_cache; -- 清空当前 session 的计划缓存
Query OK, 0 rows affected (0.00 sec)
MySQL [test]> execute stmt;
Empty set (0.00 sec)
MySQL [test]> select @@last_plan_from_cache; -- 由于缓存被清空,此时无法再次选中
+------------------------+
| @@last_plan_from_cache |
+------------------------+
| 0 |
+------------------------+
1 row in set (0.00 sec)
TiDB 暂不支持清空 GLOBAL 级别的计划缓存,即不支持一次性清空整个集群的计划缓存,使用时会报错:
MySQL [test]> admin flush global plan_cache;
ERROR 1105 (HY000): Do not support the 'admin flush global scope.'
忽略 COM_STMT_CLOSE 指令和 DEALLOCATE PREPARE 语句
为了减少每次执行 SQL 语句的语法分析,Prepared Statement 推荐的使用方式是,prepare 一次,然后 execute 多次,最后 deallocate prepare。例如:
MySQL [test]> prepare stmt from '...'; -- prepare 一次
MySQL [test]> execute stmt using ...; -- execute 一次
MySQL [test]> ...
MySQL [test]> execute stmt using ...; -- execute 多次
MySQL [test]> deallocate prepare stmt; -- 使用完成后释放
如果你习惯于在每次 execute 后都立即执行 deallocate prepare,如:
MySQL [test]> prepare stmt from '...'; -- 第一次 prepare
MySQL [test]> execute stmt using ...;
MySQL [test]> deallocate prepare stmt; -- 一次使用后立即释放
MySQL [test]> prepare stmt from '...'; -- 第二次 prepare
MySQL [test]> execute stmt using ...;
MySQL [test]> deallocate prepare stmt; -- 再次释放
这样的使用方式会让第一次执行得到的计划被立即清理,不能在第二次被复用。
为了兼容这样的使用方式,从 v6.0 起,TiDB 支持 tidb_ignore_prepared_cache_close_stmt 变量。打开该变量后,TiDB 会忽略关闭 Prepare Statement 的信号,解决上述问题,如:
mysql> set @@tidb_ignore_prepared_cache_close_stmt=1; -- 打开开关
Query OK, 0 rows affected (0.00 sec)
mysql> prepare stmt from 'select * from t'; -- 第一次 prepare
Query OK, 0 rows affected (0.00 sec)
mysql> execute stmt; -- 第一次 execute
Empty set (0.00 sec)
mysql> deallocate prepare stmt; -- 第一次 execute 后立即释放
Query OK, 0 rows affected (0.00 sec)
mysql> prepare stmt from 'select * from t'; -- 第二次 prepare
Query OK, 0 rows affected (0.00 sec)
mysql> execute stmt; -- 第二次 execute
Empty set (0.00 sec)
mysql> select @@last_plan_from_cache; -- 因为开关打开,第二次依旧能复用上一次的计划
+------------------------+
| @@last_plan_from_cache |
+------------------------+
| 1 |
+------------------------+
1 row in set (0.00 sec)
监控
在 Grafana 面板的 TiDB 页面,Executor 部分包含“Queries Using Plan Cache OPS”和“Plan Cache Miss OPS”两个图表,用以检查 TiDB 和应用是否正确配置,以便 SQL 执行计划缓存能正常工作。TiDB 页面的 Server 部分还提供了“Prepared Statement Count”图表,如果应用使用了预处理语句,这个图表会显示非零值。通过数值变化,可以判断 SQL 执行计划缓存是否正常工作。