向量搜索概述
向量搜索为文档、图片、音频和视频等多种数据类型提供了强大的语义相似性搜索解决方案。它允许开发者利用 MySQL 的专业知识,构建具备生成式 AI 能力的可扩展应用,简化高级搜索功能的集成。
概念
向量搜索是一种以数据语义为核心、提供相关性结果的搜索方法。
与传统的全文搜索依赖于精确关键字匹配和词频不同,向量搜索会将多种数据类型(如文本、图片或音频)转换为高维向量,并基于这些向量之间的相似性进行查询。这种搜索方法能够捕捉数据的语义含义和上下文信息,从而更准确地理解用户意图。
即使搜索词与数据库中的内容并不完全匹配,向量搜索也可以通过分析数据的语义,返回符合用户意图的结果。
例如,使用全文搜索查询 “a swimming animal” 只会返回包含这些精确关键字的结果。而向量搜索则可以返回其他游泳动物(如鱼或鸭子)的结果,即使这些结果中并不包含完全相同的关键字。
向量嵌入
向量嵌入(vector embedding),也称为 embedding,是一组数字序列,用于在高维空间中表示现实世界的对象。它能够捕捉非结构化数据(如文档、图片、音频和视频)的语义和上下文信息。
向量嵌入在机器学习中至关重要,是语义相似性搜索的基础。
TiDB 引入了专为优化向量嵌入存储与搜索设计的 向量数据类型 和 向量搜索索引,提升其在 AI 应用中的使用效率。你可以将向量嵌入存储在 TiDB 中,并通过这些数据类型执行向量搜索查询,查找最相关的数据。
嵌入模型
嵌入模型(embedding model)是一种将数据转换为 向量嵌入 的算法。
选择合适的嵌入模型对于确保语义搜索结果的准确性和相关性至关重要。对于非结构化文本数据,你可以在 Massive Text Embedding Benchmark (MTEB) Leaderboard 上查找表现优异的文本嵌入模型。
如需了解如何为你的特定数据类型生成向量嵌入,请参考集成教程或嵌入模型示例。
向量搜索的工作原理
在将原始数据转换为向量嵌入并存储到 TiDB 后,你的应用可以执行向量搜索查询,查找与用户查询在语义或上下文上最相关的数据。
TiDB 向量搜索通过使用 距离函数 计算给定向量与数据库中已存储向量之间的距离,从而识别出 top-k 最近邻(KNN)向量。与查询向量距离最近的向量,代表在语义上最相似的数据。
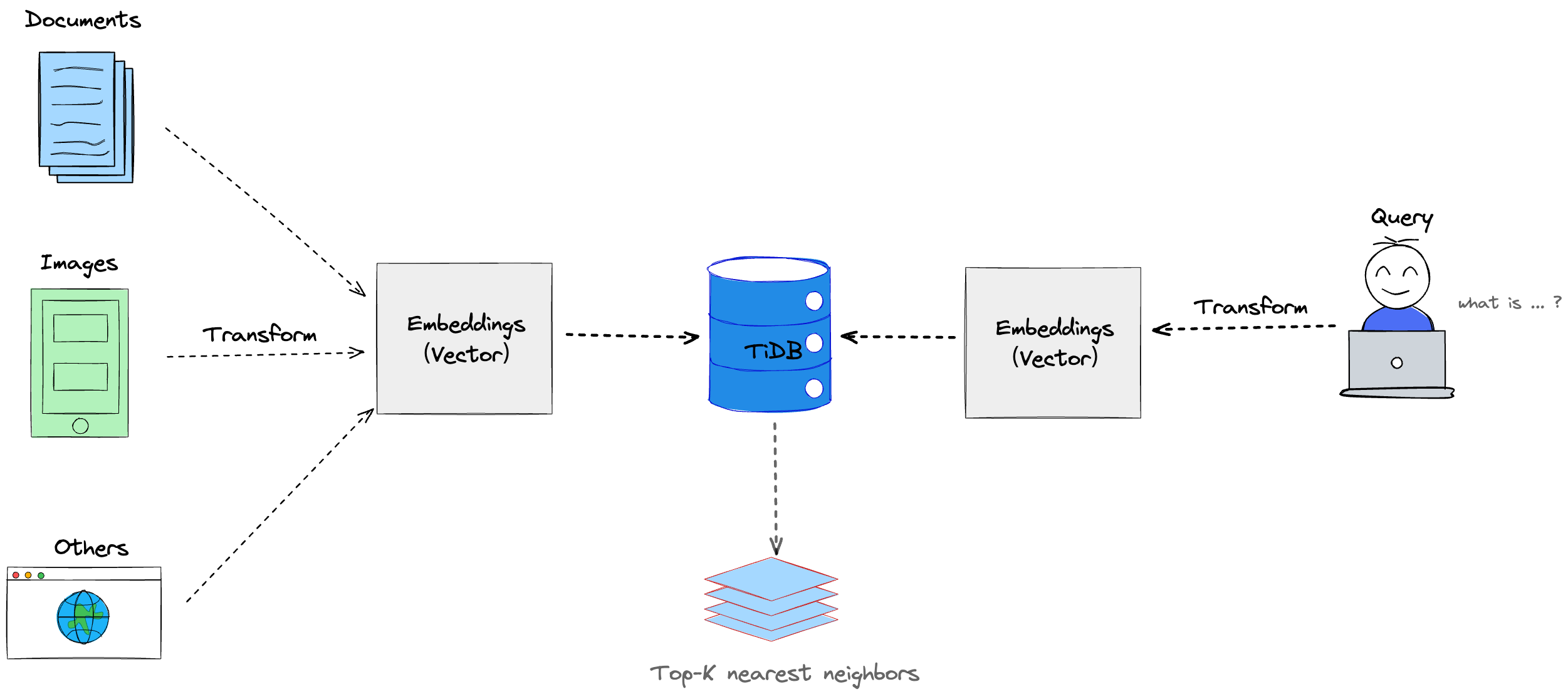
作为一款集成了向量搜索能力的关系型数据库,TiDB 允许你将数据及其对应的向量表示(即向量嵌入)一同存储在同一个数据库中。你可以选择以下任意一种存储方式:
- 在同一张表的不同列中存储数据及其对应的向量表示。
- 在不同的表中分别存储数据及其对应的向量表示。此时,搜索数据时需要使用
JOIN查询将表进行关联。
应用场景
检索增强生成(RAG)
检索增强生成(Retrieval-Augmented Generation,RAG)是一种旨在优化大语言模型(LLM)输出的架构。通过向量搜索,RAG 应用可以将向量嵌入存储在数据库中,并在 LLM 生成响应时搜索相关文档作为额外上下文,从而提升答案的质量和相关性。
语义搜索
语义搜索是一种基于查询语义返回结果的搜索技术,而不仅仅是关键字匹配。它通过嵌入理解不同语言和多种类型数据(如文本、图片和音频)的含义。向量搜索算法随后利用这些嵌入,查找最能满足用户查询需求的相关数据。
推荐引擎
推荐引擎是一种能够主动为用户推荐相关且个性化内容、产品或服务的系统。它通过创建表示用户行为和偏好的嵌入,帮助系统识别其他用户曾经互动或感兴趣的相似项目,从而提升推荐的相关性和吸引力。
另请参阅
如需开始使用 TiDB 向量搜索,请参阅以下文档: