Bidirectional Replication
TiCDC supports bi-directional replication (BDR) among two TiDB clusters. Based on this feature, you can create a multi-active TiDB solution using TiCDC.
This section describes how to use bi-directional replication taking two TiDB clusters as an example.
Deploy bi-directional replication
TiCDC only replicates incremental data changes that occur after a specified timestamp to the downstream cluster. Before starting the bi-directional replication, you need to take the following steps:
(Optional) According to your needs, import the data of the two TiDB clusters into each other using the data export tool Dumpling and data import tool TiDB Lightning.
Deploy two TiCDC clusters between the two TiDB clusters. The cluster topology is as follows. The arrows in the diagram indicate the directions of data flow.
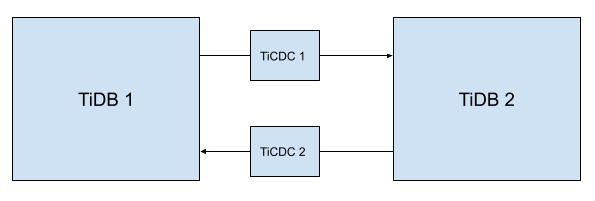
Specify the starting time point of data replication for the upstream and downstream clusters.
Check the time point of the upstream and downstream clusters. In the case of two TiDB clusters, make sure that data in the two clusters are consistent at certain time points. For example, the data of TiDB A at
ts=1and the data of TiDB B atts=2are consistent.When you create the changefeed, set the
--start-tsof the changefeed for the upstream cluster to the correspondingtso. That is, if the upstream cluster is TiDB A, set--start-ts=1; if the upstream cluster is TiDB B, set--start-ts=2.
In the configuration file specified by the
--configparameter, add the following configuration:# Whether to enable the bi-directional replication mode bdr-mode = true
After the configuration takes effect, the clusters can perform bi-directional replication.
DDL types
Starting from v7.6.0, to support DDL replication as much as possible in bi-directional replication, TiDB divides the DDLs that TiCDC originally supports into two types: replicable DDLs and non-replicable DDLs, according to the impact of DDLs on the business.
Replicable DDLs
Replicable DDLs are the DDLs that can be directly executed and replicated to other TiDB clusters in bi-directional replication.
Replicable DDLs include:
CREATE DATABASECREATE TABLEADD COLUMN: the column can benull, or hasnot nullanddefault valueat the same timeADD NON-UNIQUE INDEXDROP INDEXMODIFY COLUMN: you can only modify thedefault valueandcommentof the columnALTER COLUMN DEFAULT VALUEMODIFY TABLE COMMENTRENAME INDEXADD TABLE PARTITIONDROP PRIMARY KEYALTER TABLE INDEX VISIBILITYALTER TABLE TTLALTER TABLE REMOVE TTLCREATE VIEWDROP VIEW
Non-replicable DDLs
Non-replicable DDLs are the DDLs that have a great impact on the business, and might cause data inconsistency between clusters. Non-replicable DDLs cannot be directly replicated to other TiDB clusters in bi-directional replication through TiCDC. Non-replicable DDLs must be executed through specific operations.
Non-replicable DDLs include:
DROP DATABASEDROP TABLEADD COLUMN: the column isnot nulland does not have adefault valueDROP COLUMNADD UNIQUE INDEXTRUNCATE TABLEMODIFY COLUMN: you can modify the attributes of the column exceptdefault valueandcommentRENAME TABLEDROP PARTITIONTRUNCATE PARTITIONALTER TABLE CHARACTER SETALTER DATABASE CHARACTER SETRECOVER TABLEADD PRIMARY KEYREBASE AUTO IDEXCHANGE PARTITIONREORGANIZE PARTITION
DDL replication
To solve the problem of replicable DDLs and non-replicable DDLs, TiDB introduces the following BDR roles:
PRIMARY: you can execute replicable DDLs, but cannot execute non-replicable DDLs. Replicable DDLs will be replicated to the downstream by TiCDC.SECONDARY: you cannot execute replicable DDLs or non-replicable DDLs, but can execute the DDLs replicated by TiCDC.
When no BDR role is set, you can execute any DDL. But after you set bdr_mode=true on TiCDC, the executed DDL will not be replicated by TiCDC.
Replication scenarios of replicable DDLs
Choose a TiDB cluster and execute
ADMIN SET BDR ROLE PRIMARYto set it as the primary cluster.ADMIN SET BDR ROLE PRIMARY; Query OK, 0 rows affected Time: 0.003s ADMIN SHOW BDR ROLE; +----------+ | BDR_ROLE | +----------+ | primary | +----------+On other TiDB clusters, execute
ADMIN SET BDR ROLE SECONDARYto set them as the secondary clusters.Execute replicable DDLs on the primary cluster. The successfully executed DDLs will be replicated to the secondary clusters by TiCDC.
Replication scenarios of non-replicable DDLs
- Execute
ADMIN UNSET BDR ROLEon all TiDB clusters to unset the BDR role. - Stop writing data to the tables that need to execute DDLs in all clusters.
- Wait until all writes to the corresponding tables in all clusters are replicated to other clusters, and then manually execute all DDLs on each TiDB cluster.
- Wait until the DDLs are completed, and then resume writing data.
- Follow the steps in Replication scenarios of replicable DDLs to switch back to the replication scenario of replicable DDLs.
Stop bi-directional replication
After the application has stopped writing data, you can insert a special record into each cluster. By checking the two special records, you can make sure that data in two clusters are consistent.
After the check is completed, you can stop the changefeed to stop bi-directional replication, and execute ADMIN UNSET BDR ROLE on all TiDB clusters.
Limitations
Use BDR role only in the following scenarios:
1
PRIMARYcluster and nSECONDARYclusters (replication scenarios of replicable DDLs)n clusters that have no BDR roles (replication scenarios in which you can manually execute non-replicable DDLs on each cluster)
Usually do not use
AUTO_INCREMENTorAUTO_RANDOMto avoid data conflicts in the replicated tables. If you need to useAUTO_INCREMENTorAUTO_RANDOM, you can set differentauto_increment_incrementandauto_increment_offsetfor different clusters to ensure that different clusters can be assigned different primary keys. For example, if there are three TiDB clusters (A, B, and C) in bi-directional replication, you can set them as follows:In Cluster A, set
auto_increment_increment=3andauto_increment_offset=2000In Cluster B, set
auto_increment_increment=3andauto_increment_offset=2001In Cluster C, set
auto_increment_increment=3andauto_increment_offset=2002This way, A, B, and C will not conflict with each other in the implicitly assigned
AUTO_INCREMENTID andAUTO_RANDOMID. If you need to add a cluster in BDR mode, you need to temporarily stop writing data of the related application, set the appropriate values forauto_increment_incrementandauto_increment_offseton all clusters, and then resume writing data of the related application.
Bi-directional replication clusters cannot detect write conflicts, which might cause undefined behaviors. Therefore, you must ensure that there are no write conflicts from the application side.
Bi-directional replication supports more than two clusters, but does not support multiple clusters in cascading mode, that is, a cyclic replication like TiDB A -> TiDB B -> TiDB C -> TiDB A. In such a topology, if one cluster fails, the whole data replication will be affected. Therefore, to enable bi-directional replication among multiple clusters, you need to connect each cluster with every other clusters, for example,
TiDB A <-> TiDB B,TiDB B <-> TiDB C,TiDB C <-> TiDB A.