TiDB Lightning Overview
TiDB Lightning is a tool used for fast full import of large amounts of data into a TiDB cluster. You can download TiDB Lightning from here.
Currently, TiDB Lightning can mainly be used in the following two scenarios:
- Importing large amounts of new data quickly
- Restore all backup data
Currently, TiDB Lightning supports:
- The data source of the Dumpling, CSV or Amazon Aurora Parquet exported formats.
- Reading data from a local disk or from the Amazon S3 storage. For details, see External Storages.
TiDB Lightning architecture
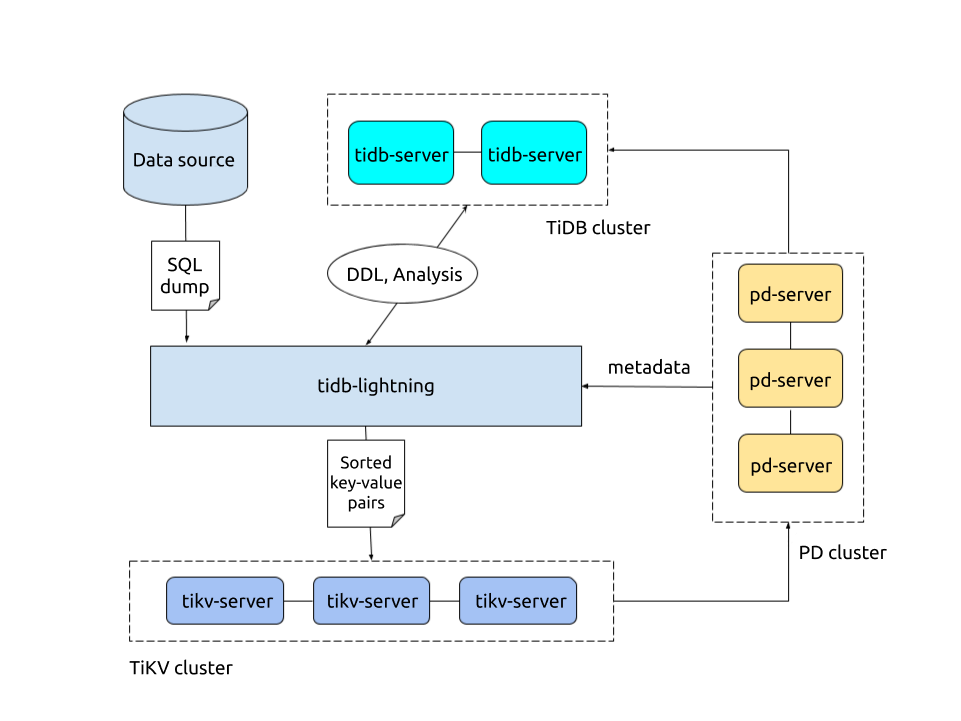
The complete import process is as follows:
Before importing,
tidb-lightningswitches the TiKV cluster to "import mode", which optimizes the cluster for writing and disables automatic compaction.tidb-lightningcreates the skeleton of all tables from the data source.Each table is split into multiple continuous batches, so that data from a huge table (200 GB+) can be imported incrementally and concurrently.
For each batch,
tidb-lightningcreates an engine file to store KV pairs.tidb-lightningthen reads the data source in parallel, transforms each row into KV pairs according to the TiDB rules, and writes these KV pairs into the local files for temporary storage.Once a complete engine file is written,
tidb-lightningdivides and schedules these data and imports them into the target TiKV cluster.There are two kinds of engine files: data engines and index engines, each corresponding to two kinds of KV pairs: the row data and secondary indices. Normally, the row data are entirely sorted in the data source, while the secondary indices are out of order. Because of this, the data engines are uploaded as soon as a batch is completed, while the index engines are imported only after all batches of the entire table are encoded.
After all engines associated to a table are imported,
tidb-lightningperforms a checksum comparison between the local data source and those calculated from the cluster, to ensure there is no data corruption in the process; tells TiDB toANALYZEall imported tables, to prepare for optimal query planning; and adjusts theAUTO_INCREMENTvalue so future insertions will not cause conflict.The auto-increment ID of a table is computed by the estimated upper bound of the number of rows, which is proportional to the total file size of the data files of the table. Therefore, the final auto-increment ID is often much larger than the actual number of rows. This is expected since in TiDB auto-increment is not necessarily allocated sequentially.
Finally,
tidb-lightningswitches the TiKV cluster back to "normal mode", so the cluster resumes normal services.
If the target cluster of data import is v3.x or earlier versions, you need to use the Importer-backend to import data. In this mode, tidb-lightning sends the parsed KV pairs to tikv-importer via gRPC and tikv-importer imports the data.
TiDB Lightning also supports using TiDB-backend for data import. In this mode, tidb-lightning transforms data into INSERT SQL statements and directly executes them on the target cluster. See TiDB Lightning Backends for details.
Restrictions
If you use TiDB Lightning together with TiFlash:
No matter a table has TiFlash replica(s) or not, you can import data to that table using TiDB Lightning. Note that this might slow the TiDB Lightning procedure, which depends on the NIC bandwidth on the lightning host, the CPU and disk load of the TiFlash node, and the number of TiFlash replicas.