TiDB Computing
Based on the distributed storage provided by TiKV, TiDB builds the computing engine that combines great capability of transactional processing with that of data analysis. This document starts by introducing a data mapping algorithm that maps data from TiDB database tables to (Key, Value) key-value pairs in TiKV, then introduces how TiDB manages metadata, and finally illustrates the architecture of the TiDB SQL layer.
For the storage solution on which the computing layer is dependent, this document only introduces the row-based storage structure of TiKV. For OLAP services, TiDB introduces a column-based storage solution TiFlash as a TiKV extension.
Mapping table data to Key-Value
This section describes the scheme for mapping data to (Key, Value) key-value pairs in TiDB. Data to be mapped here includes the following two types:
- Data of each row in the table, hereinafter referred to as table data.
- Data of all indexes in the table, hereinafter referred to as index data.
Mapping of table data to Key-Value
In a relational database, a table might have many columns. To map the data of each column in a row to a (Key, Value) key-value pair, you need to consider how to construct the Key. First of all, in OLTP scenarios, there are many operations such as adding, deleting, changing, and searching for data on a single or multiple rows, which needs the database to read a row of data quickly. Therefore, each key should have a unique ID (either explicit or implicit) to make it quick to locate. Then, many OLAP queries require a full table scan. If you can encode the keys of all rows in a table into a range, the whole table can be efficiently scanned by range queries.
Based on the considerations above, the mapping of table data to Key-Value in TiDB is designed as follows:
- To ensure that data from the same table is kept together for easy searching, TiDB assigns a table ID to each table represented by
TableID. Table ID is an integer that is unique throughout the cluster. - TiDB assigns a row ID, represented by
RowID, to each row of data in the table. The row ID is also an integer, unique within the table. For row ID, TiDB has made a small optimization: if a table has an integer type primary key, TiDB uses the value of this primary key as the row ID.
Each row of data is encoded as a (Key, Value) key-value pair according to the following rule:
Key: tablePrefix{TableID}_recordPrefixSep{RowID}
Value: [col1, col2, col3, col4]
tablePrefix and recordPrefixSep are both special string constants used to distinguish other data in Key space. The exact values of the string constants are introduced in Summary of mapping relationships.
Mapping of indexed data to Key-Value
TiDB supports both primary keys and secondary indexes (both unique and non-unique indexes). Similar to the table data mapping scheme, TiDB assigns an index ID to each index of the table represented by IndexID.
For primary keys and unique indexes, it is needed to quickly locate the corresponding RowID based on the key-value pair, so such a key-value pair is encoded as follows.
Key: tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue
Value: RowID
For ordinary secondary indexes that do not need to satisfy the uniqueness constraint, a single key might correspond to multiple rows. It needs to query corresponding RowID according to the range of keys. Therefore, the key-value pair must be encoded according to the following rule:
Key: tablePrefix{TableID}_indexPrefixSep{IndexID}_indexedColumnsValue_{RowID}
Value: null
Summary of mapping relationships
tablePrefix, recordPrefixSep, and indexPrefixSep in all of the above encoding rules are string constants that are used to distinguish a KV from other data in the Key space, which are defined as follows:
tablePrefix = []byte{'t'}
recordPrefixSep = []byte{'r'}
indexPrefixSep = []byte{'i'}
Also note that in the above encoding schemes, no matter table data or index data key encoding scheme, all rows in a table have the same key prefix, and all data of an index also has the same prefix. Data with the same prefixes are thus arranged together in TiKV's key space. Therefore, by carefully designing the encoding scheme of the suffix part to ensure that the pre-encoding and post-encoding comparisons remain the same, the table data or index data can be stored in TiKV in an ordered manner. Using this encoding scheme, all row data in a table is arranged orderly by RowID in the TiKV's key space, and the data of a particular index is also arranged sequentially in the key space according to the specific value of the index data (indexedColumnsValue).
Example of Key-Value mapping relationship
This section shows a simple example for you to understand the Key-Value mapping relationship of TiDB. Suppose the following table exists in TiDB.
CREATE TABLE User (
ID int,
Name varchar(20),
Role varchar(20),
Age int,
PRIMARY KEY (ID),
KEY idxAge (Age)
);
Suppose there are 3 rows of data in the table.
1, "TiDB", "SQL Layer", 10
2, "TiKV", "KV Engine", 20
3, "PD", "Manager", 30
Each row of data is mapped to a (Key, Value) key-value pair, and the table has an int type primary key, so the value of RowID is the value of this primary key. Suppose the table's TableID is 10, and then its table data stored on TiKV is:
t10_r1 --> ["TiDB", "SQL Layer", 10]
t10_r2 --> ["TiKV", "KV Engine", 20]
t10_r3 --> ["PD", " Manager", 30]
In addition to the primary key, the table has a non-unique ordinary secondary index, idxAge. Suppose the IndexID is 1, and then its index data stored on TiKV is:
t10_i1_10_1 --> null
t10_i1_20_2 --> null
t10_i1_30_3 --> null
The above example shows the mapping rule from a relational model to a Key-Value model in TiDB, and the consideration behind this mapping scheme.
Metadata management
Each database and table in TiDB has metadata that indicates its definition and various attributes. This information also needs to be persisted, and TiDB stores this information in TiKV as well.
Each database or table is assigned a unique ID. As the unique identifier, when table data is encoded to Key-Value, this ID is encoded in the Key with the m_ prefix. This constructs a key-value pair with the serialized metadata stored in it.
In addition, TiDB also uses a dedicated (Key, Value) key-value pair to store the latest version number of structure information of all tables. This key-value pair is global, and its version number is increased by 1 each time the state of the DDL operation changes. TiDB stores this key-value pair persistently in the PD server with the key of /tidb/ddl/global_schema_version, and Value is the version number value of the int64 type. Meanwhile, because TiDB applies schema changes online, it keeps a background thread that constantly checks whether the version number of the table structure information stored in the PD server changes. This thread also ensures that the changes of version can be obtained within a certain period of time.
SQL layer overview
TiDB's SQL layer, TiDB Server, translates SQL statements into Key-Value operations, forwards the operations to TiKV, the distributed Key-Value storage layer, assembles the results returned by TiKV, and finally returns the query results to the client.
The nodes at this layer are stateless. These nodes themselves do not store data and are completely equivalent.
SQL computing
The simplest solution to SQL computing is the mapping of table data to Key-Value as described in the previous section, which maps SQL queries to KV queries, acquires the corresponding data through the KV interface, and performs various computations.
For example, to execute the select count(*) from user where name = "TiDB" SQL statement, TiDB needs to read all data in the table, then checks whether the name field is TiDB, and if so, returns this row. The process is as follows:
- Construct the Key Range: all
RowIDin a table are in[0, MaxInt64)range. According to the row dataKeyencoding rule, using0andMaxInt64can construct a[StartKey, EndKey)range that is left-closed and right-open. - Scan Key Range: read the data in TiKV according to the key range constructed above.
- Filter data: for each row of data read, calculate the
name = "TiDB"expression. If the result istrue, return to this row. If not, skip this row. - Calculate
Count(*): for each row that meets the requirements, add up to the result ofCount(*).
The entire process is illustrated as follows:
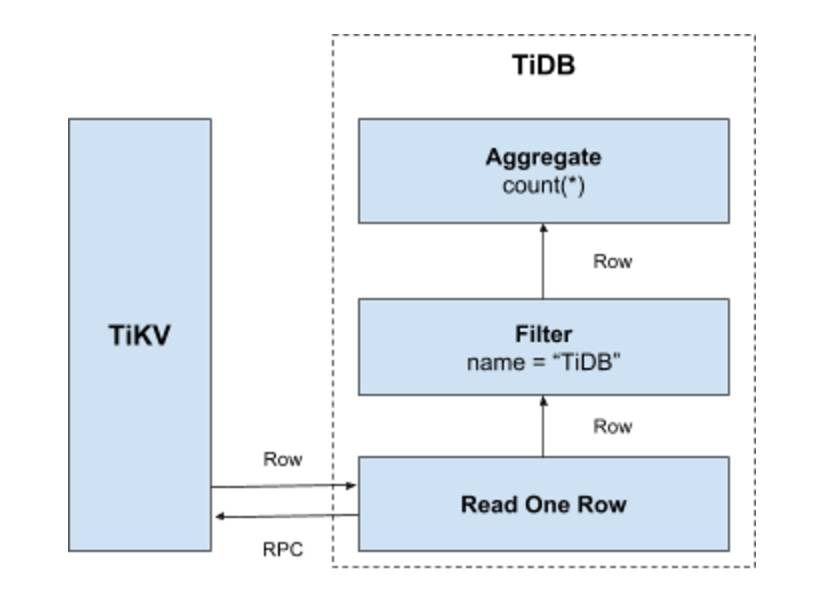
This solution is intuitive and feasible, but has some obvious problems in a distributed database scenario:
- As the data is being scanned, each row is read from TiKV via a KV operation with at least one RPC overhead, which can be very high if there is a large amount of data to be scanned.
- It is not applicable to all rows. Data that does not meet the conditions does not need to be read.
- From the returned result of this query, only the number of rows that match the requirements is needed, not the value of those rows.
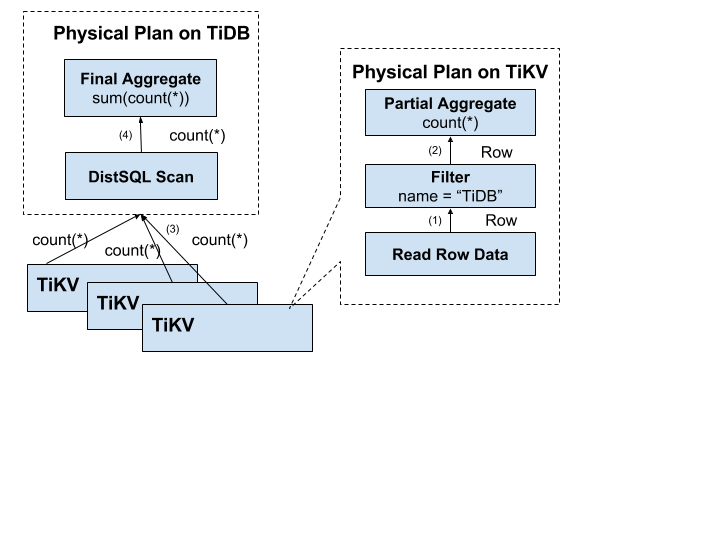
Distributed SQL operations
To solve the problems above, the computation should be as close to the storage node as possible to avoid a large number of RPC callings. First of all, the SQL predicate condition name = "TiDB" should be pushed down to the storage node for computation, so that only valid rows are returned, which avoids meaningless network transfers. Then, the aggregation function Count(*) can also be pushed down to the storage nodes for pre-aggregation, and each node only has to return a result of Count(*). The SQL layer will sum up the Count(*) results returned by each node.
The following image shows how data returns layer by layer:
Architecture of SQL layer
The previous sections introduce some functions of the SQL layer and I hope you have a basic understanding of how SQL statements are handled. In fact, TiDB's SQL layer is much more complicated, with many modules and layers. The following diagram lists the important modules and calling relationships:

The user's SQL request is sent to TiDB Server either directly or via Load Balancer. TiDB Server will parse MySQL Protocol Packet, get the content of requests, parse the SQL request syntactically and semantically, develop and optimize query plans, execute a query plan, get and process the data. All data is stored in the TiKV cluster, so in this process, TiDB Server needs to interact with TiKV and get the data. Finally, TiDB Server needs to return the query results to the user.