BR Use Cases
BR is a tool for distributed backup and restoration of the TiDB cluster data.
This document describes how to run BR in the following use cases:
- Back up a single table to a network disk (recommended in production environment)
- Restore data from a network disk (recommended in production environment)
- Back up a single table to a local disk (recommended in testing environment)
- Restore data from a local disk (recommended in testing environment)
This document aims to help you achieve the following goals:
- Back up and restore data using a network disk or local disk correctly.
- Get the status of a backup or restoration operation through monitoring metrics.
- Learn how to tune performance during the operation.
- Troubleshoot the possible anomalies during the backup operation.
Audience
You are expected to have a basic understanding of TiDB and TiKV.
Before reading on, make sure you have read BR Tool Overview, especially Usage Restrictions and Best Practices.
Prerequisites
This section introduces the recommended method of deploying TiDB, cluster versions, the hardware information of the TiKV cluster, and the cluster configuration for the use case demonstrations.
You can estimate the performance of your backup or restoration operation based on your own hardware and configuration.
Deployment method
It is recommended that you deploy the TiDB cluster using TiUP and get BR by downloading TiDB Toolkit.
Cluster versions
- TiDB: v4.0.2
- TiKV: v4.0.2
- PD: v4.0.2
- BR: v4.0.2
TiKV hardware information
- Operating system: CentOS Linux release 7.6.1810 (Core)
- CPU: 16-Core Common KVM processor
- RAM: 32GB
- Disk: 500G SSD * 2
- NIC: 10 Gigabit network card
Cluster configuration
BR directly sends commands to the TiKV cluster and are not dependent on the TiDB server, so you do not need to configure the TiDB server when using BR.
- TiKV: default configuration
- PD: default configuration
Use cases
This document describes the following use cases:
- Back up a single table to a network disk (recommended in production environment)
- Restore data from a network disk (recommended in production environment)
- Back up a single table to a local disk (recommended in testing environment)
- Restore data from a local disk (recommended in testing environment)
It is recommended that you use a network disk to back up and restore data. This spares you from collecting backup files and greatly improves the backup efficiency especially when the TiKV cluster is in a large scale.
Before the backup or restoration operations, you need to do some preparations:
Preparation for backup
In TiDB v4.0.8 and later versions, the BR tool already supports the self-adaptive Garbage Collection (GC). It automatically registers backupTS (the latest PD timestamp by default) to PD's safePoint to ensure that TiDB's GC Safe Point does not move forward during the backup, thus avoiding manually setting GC configurations.
For the detailed usage of the br backup command, refer to Use BR Command-line for Backup and Restoration.
In TiDB v4.0.7 and earlier versions, you need to manually configure GC before and after the BR backup through the following steps:
Before executing the
br backupcommand, check the value of thetikv_gc_life_timeconfiguration item, and adjust the value appropriately in the MySQL client to make sure that GC does not run during the backup operation.SELECT * FROM mysql.tidb WHERE VARIABLE_NAME = 'tikv_gc_life_time'; UPDATE mysql.tidb SET VARIABLE_VALUE = '720h' WHERE VARIABLE_NAME = 'tikv_gc_life_time';After the backup operation, set the parameter back to the original value.
UPDATE mysql.tidb SET VARIABLE_VALUE = '10m' WHERE VARIABLE_NAME = 'tikv_gc_life_time';
Preparation for restoration
Before executing the br restore command, check the new cluster to make sure that the table in the cluster does not have a duplicate name.
Back up a single table to a network disk (recommended in production environment)
Use the br backup command to back up the single table data --db batchmark --table order_line to the specified path local:///br_data in the network disk.
Backup prerequisites
- Preparation for backup
- Configure a high-performance SSD hard disk host as the NFS server to store data, and all BR nodes, TiKV nodes, and TiFlash nodes as NFS clients. Mount the same path (for example,
/br_data) to the NFS server for NFS clients to access the server. - The total transfer rate between the NFS server and all NFS clients must reach at least
the number of TiKV instances * 150MB/s. Otherwise the network I/O might become the performance bottleneck.
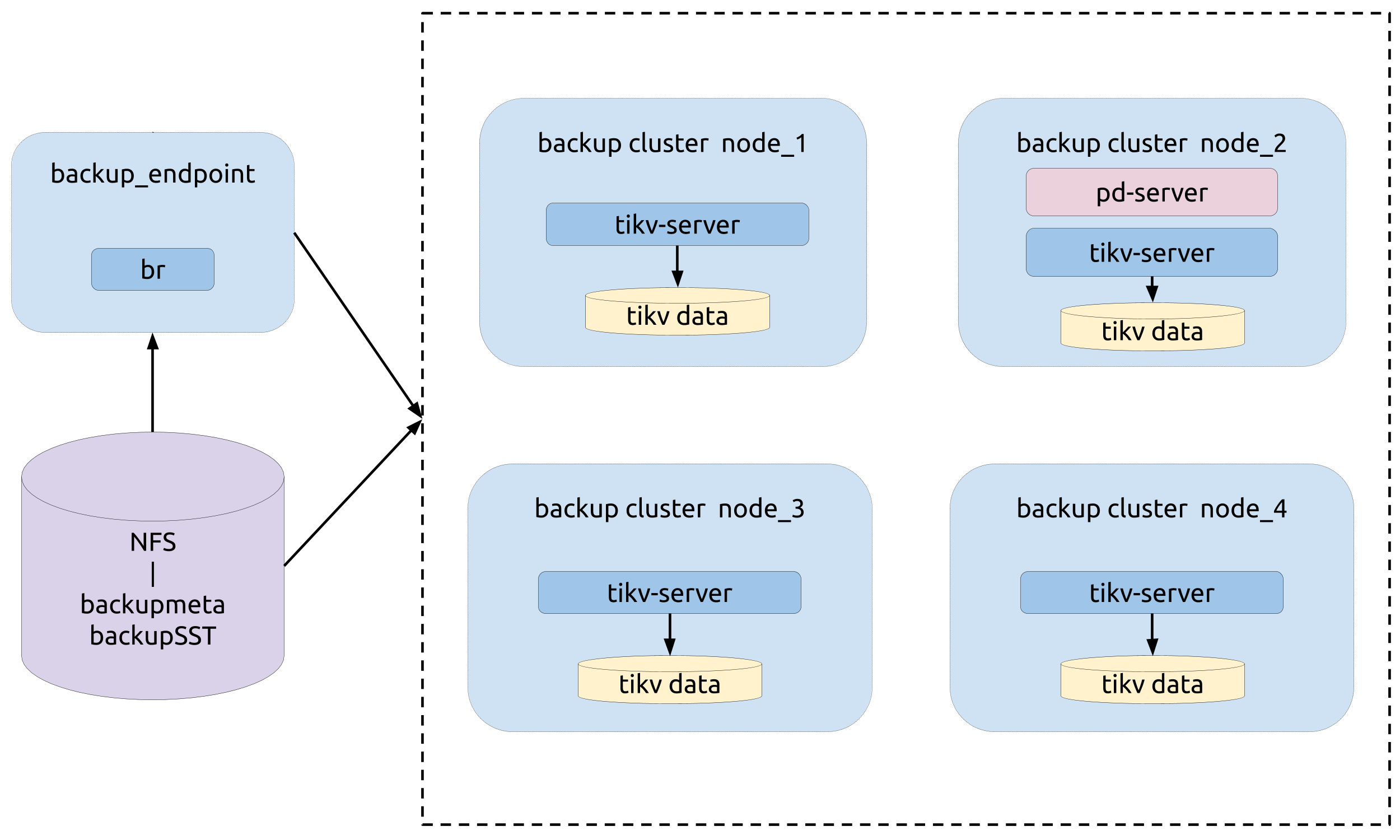
Topology
The following diagram shows the typology of BR:
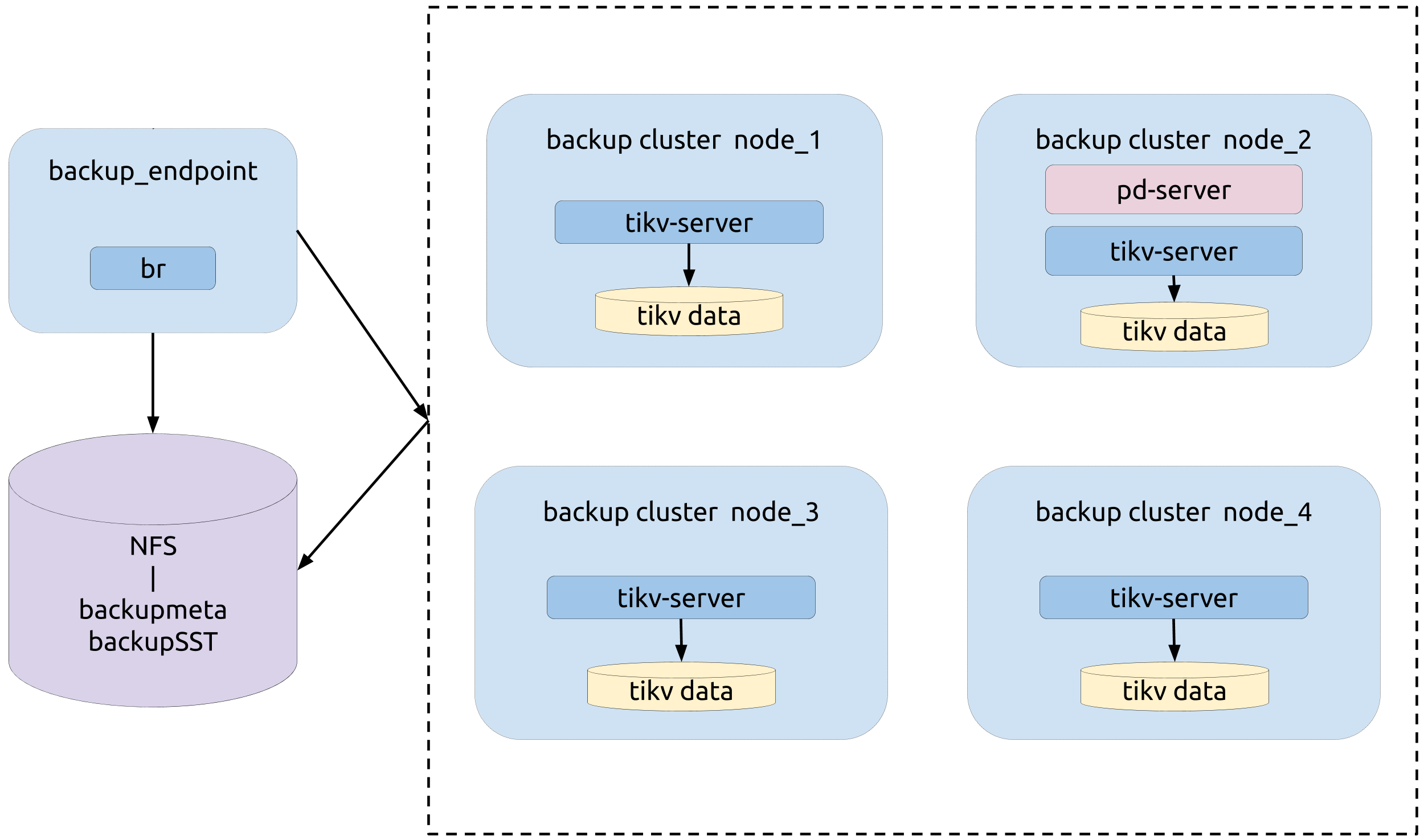
Backup operation
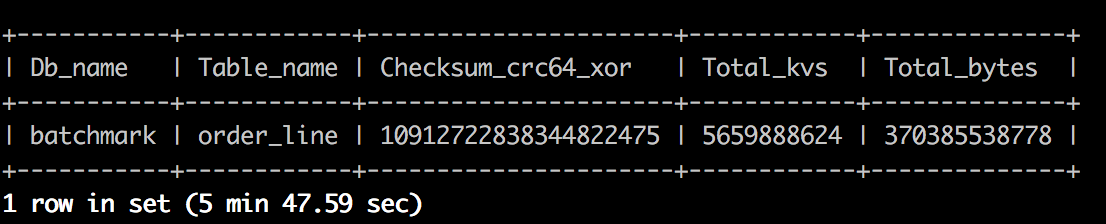
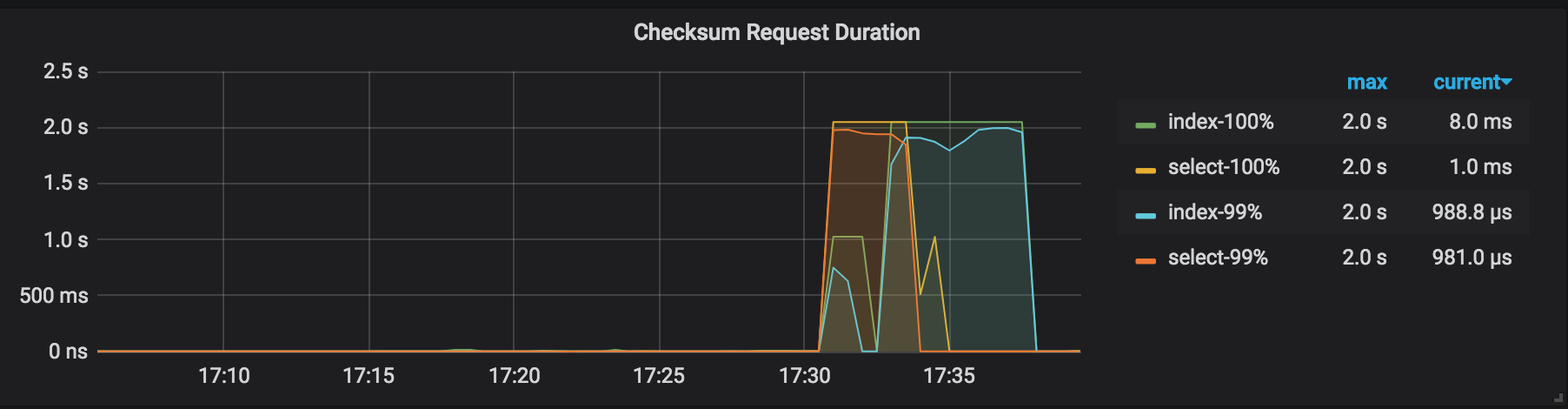
Before the backup operation, execute the admin checksum table order_line command to get the statistical information of the table to be backed up (--db batchmark --table order_line). The following image shows an example of this information:
Execute the br backup command:
bin/br backup table \
--db batchmark \
--table order_line \
-s local:///br_data \
--pd ${PD_ADDR}:2379 \
--log-file backup-nfs.log
Monitoring metrics for the backup
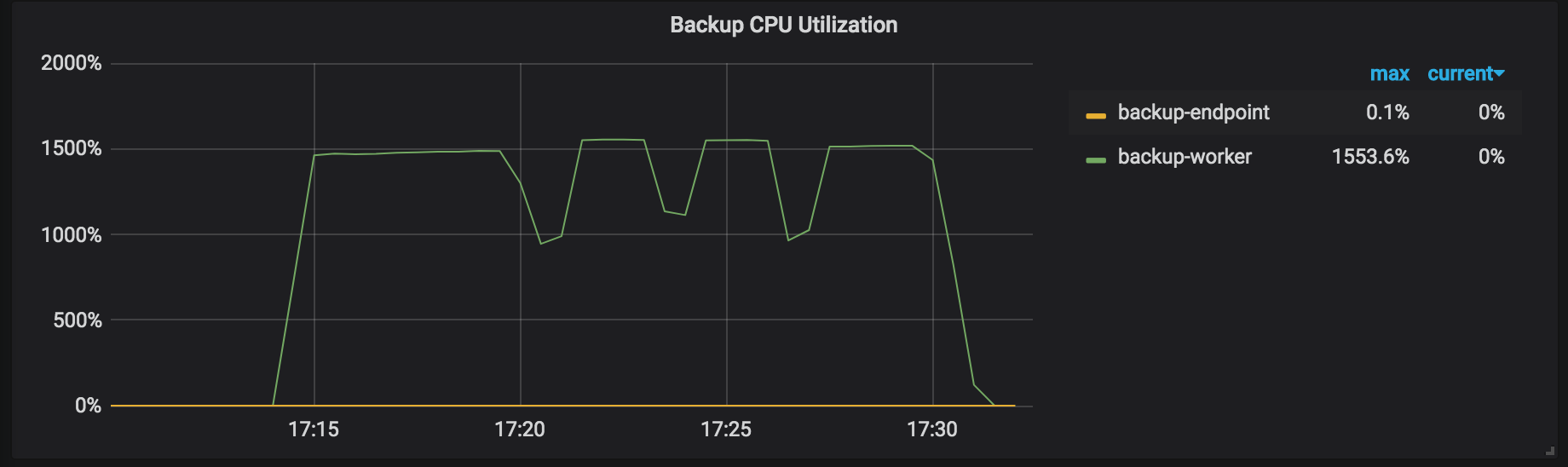
During the backup process, pay attention to the following metrics on the monitoring panels to get the status of the backup process.
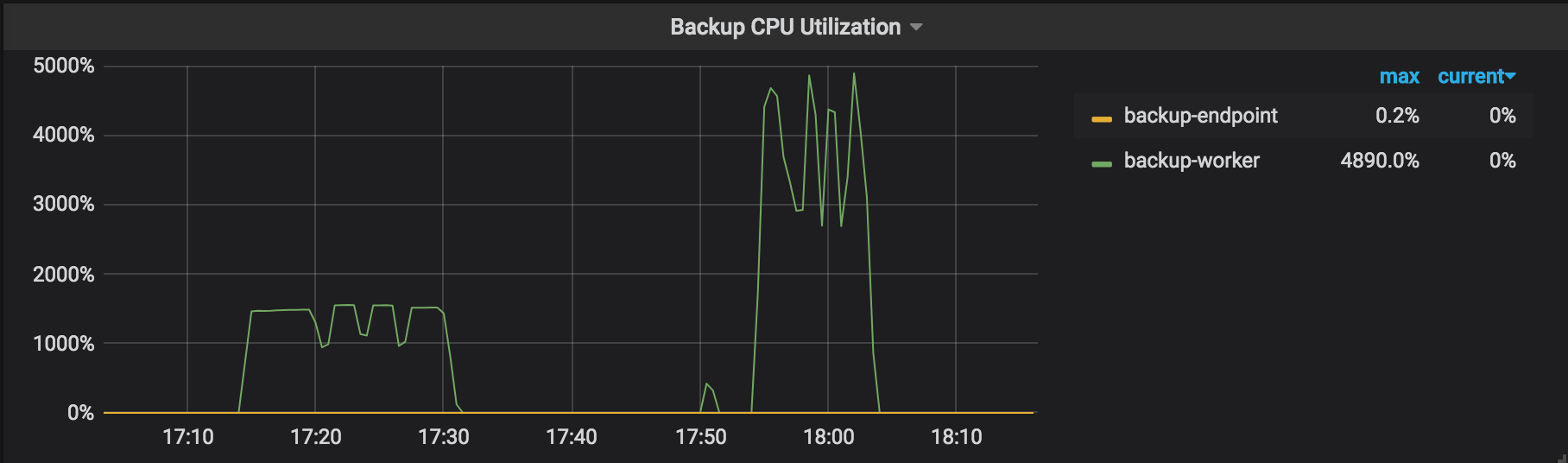
Backup CPU Utilization: the CPU usage rate of each working TiKV node in the backup operation (for example, backup-worker and backup-endpoint).
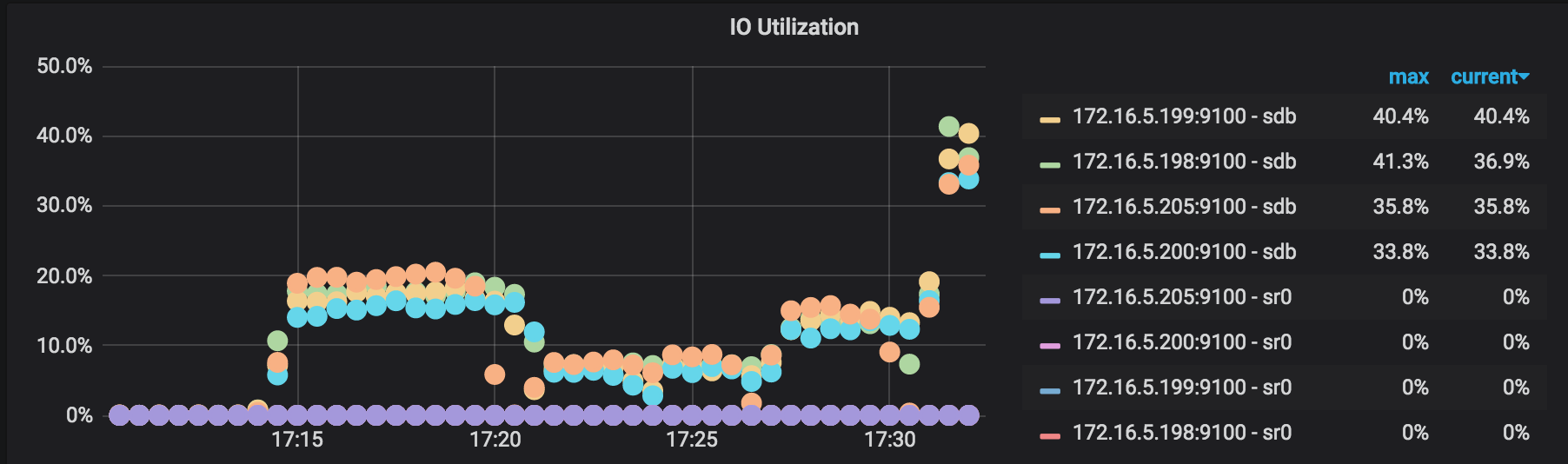
IO Utilization: the I/O usage rate of each working TiKV node in the backup operation.
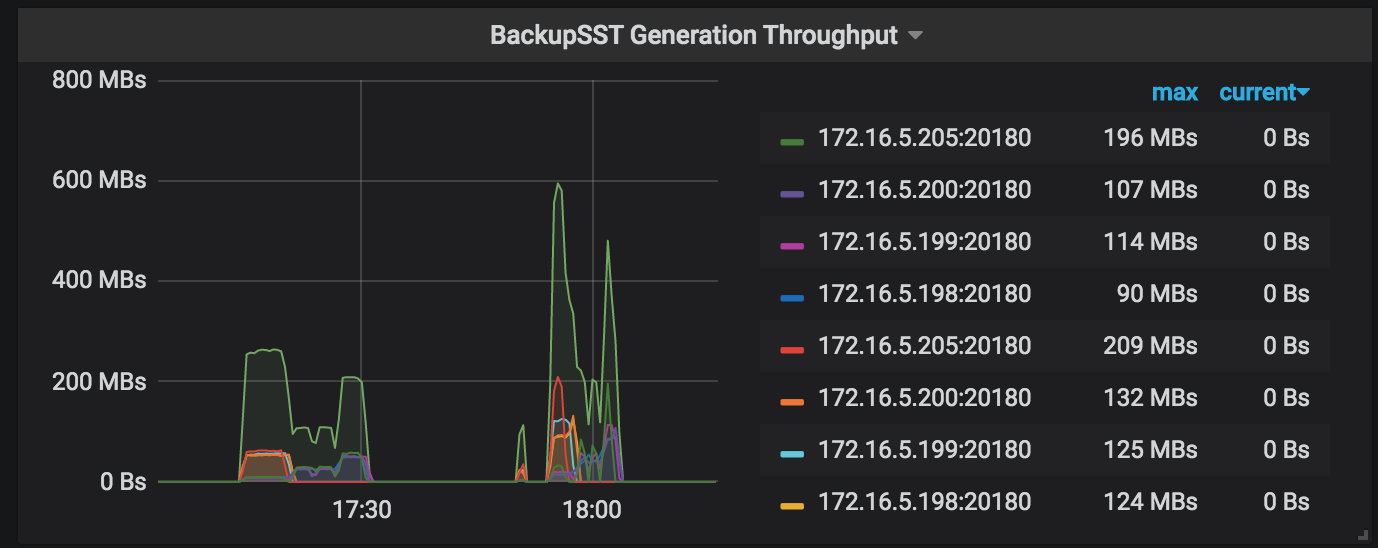
BackupSST Generation Throughput: the backupSST generation throughput of each working TiKV node in the backup operation, which is normally around 150MB/s.
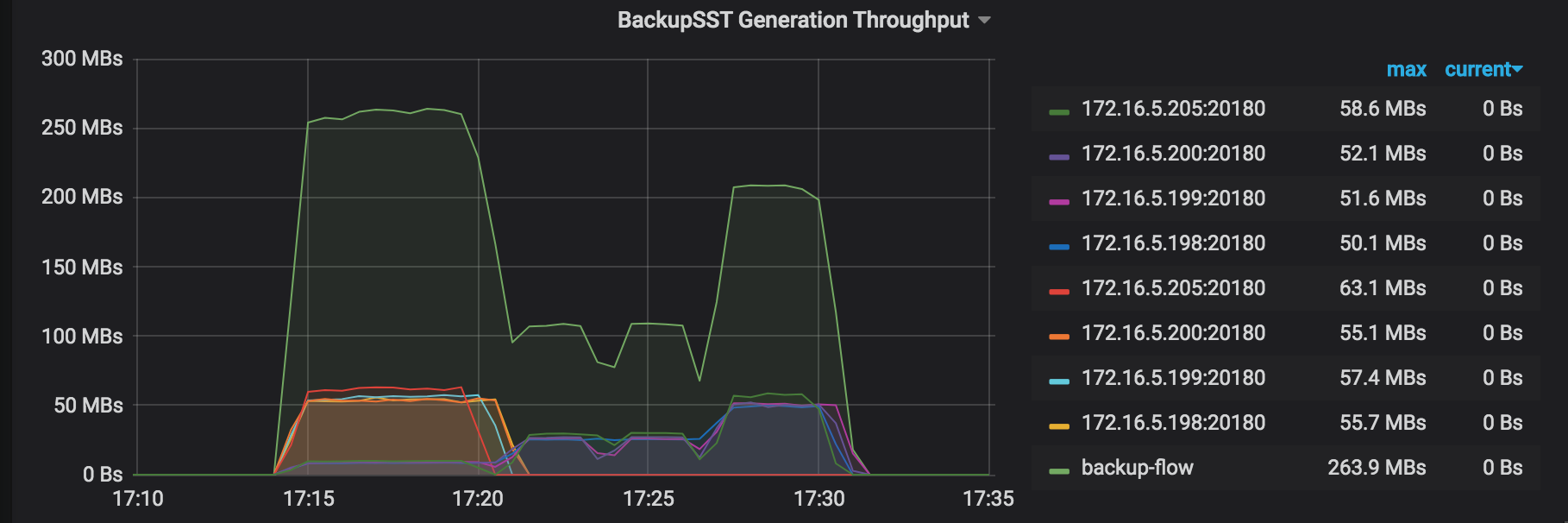
One Backup Range Duration: the duration of backing up a range, which is the total time cost of scanning KVs and storing the range as the backupSST file.
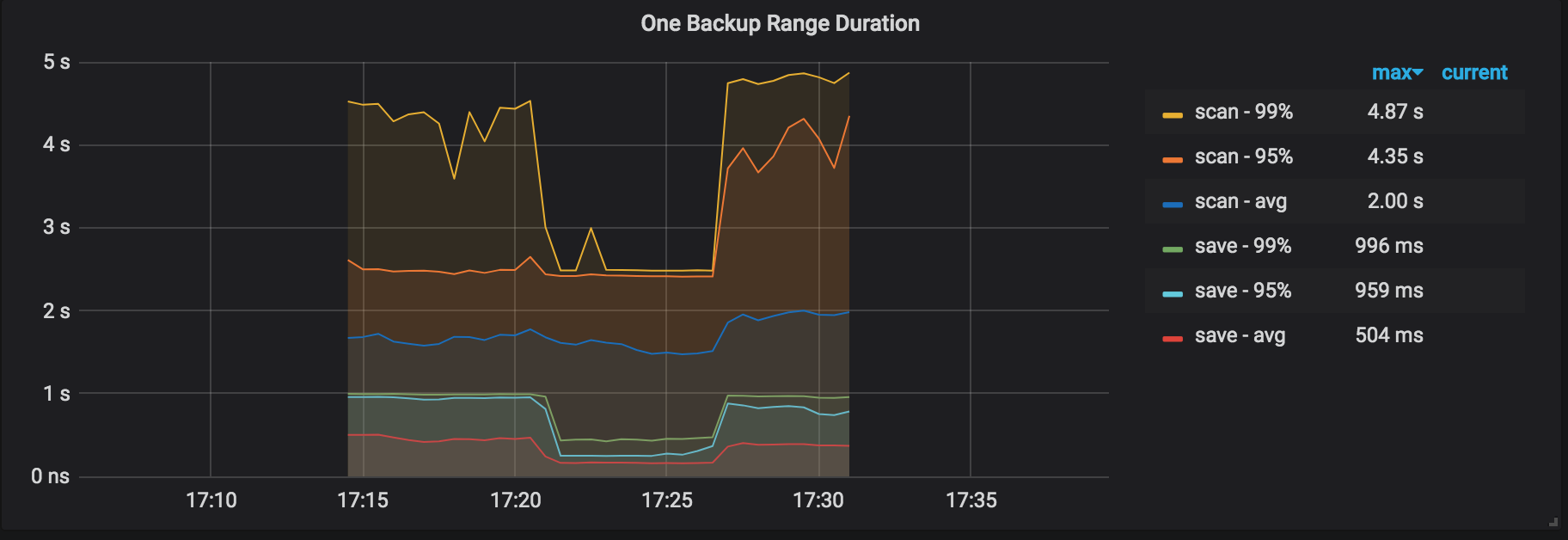
One Backup Subtask Duration: the duration of each sub-task into which a backup task is divided.
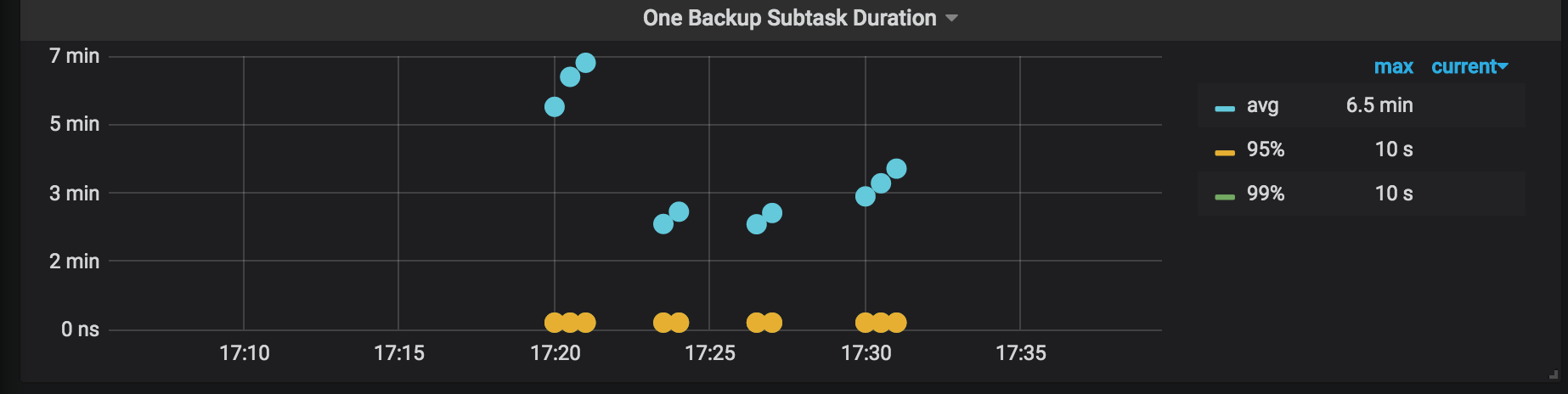
Backup Errors: the errors occurred during the backup process. No error occurs in normal situations. Even if a few errors occur, the backup operation has the retry mechanism which might increase the backup time but does not affect the operation correctness.
Checksum Request Duration: the duration of the admin checksum request in the backup cluster.
Backup results explanation
When finishing the backup, BR outputs the backup summary to the console.
Before executing the backup command, a path in which the log is stored has been specified. You can get the statistical information of the backup operation from this log. Search "summary" in this log, you can see the following information:
["Full backup Success summary:
total backup ranges: 2,
total success: 2,
total failed: 0,
total take(Full backup time): 31.802912166s,
total take(real time): 49.799662427s,
total size(MB): 5997.49,
avg speed(MB/s): 188.58,
total kv: 120000000"]
["backup checksum"=17.907153678s]
["backup fast checksum"=349.333µs]
["backup total regions"=43]
[BackupTS=422618409346269185]
[Size=826765915]
The above log includes the following information:
- Backup duration:
total take(Full backup time): 31.802912166s - Total runtime of the application:
total take(real time): 49.799662427s - Backup data size:
total size(MB): 5997.49 - Backup throughput:
avg speed(MB/s): 188.58 - Number of backed-up KV pairs:
total kv: 120000000 - Backup checksum duration:
["backup checksum"=17.907153678s] - Total duration of calculating the checksum, KV pairs, and bytes of each table:
["backup fast checksum"=349.333µs] - Total number of backup Regions:
["backup total regions"=43] - The actual size of the backup data in the disk after compression:
[Size=826765915] - Snapshot timestamp of the backup data:
[BackupTS=422618409346269185]
From the above information, the throughput of a single TiKV instance can be calculated: avg speed(MB/s)/tikv_count = 62.86.
Performance tuning
If the resource usage of TiKV does not become an obvious bottleneck during the backup process (for example, in the Monitoring metrics for the backup, the highest CPU usage rate of backup-worker is around 1500% and the overall I/O usage rate is below 30%), you can try to increase the value of --concurrency (4 by default) to tune the performance. But this performance tuning method is not suitable for the use cases of many small tables. See the following example:
bin/br backup table \
--db batchmark \
--table order_line \
-s local:///br_data/ \
--pd ${PD_ADDR}:2379 \
--log-file backup-nfs.log \
--concurrency 16
The tuned performance results are as follows (with the same data size):
- Backup duration:
total take(s)reduced from986.43to535.53 - Backup throughput:
avg speed(MB/s)increased from358.09to659.59 - Throughput of a single TiKV instance:
avg speed(MB/s)/tikv_countincreased from89to164.89
Restore data from a network disk (recommended in production environment)
Use the br restore command to restore the complete backup data to an offline cluster. Currently, BR does not support restoring data to an online cluster.
Restoration prerequisites
Topology
The following diagram shows the typology of BR:
Restoration operation
Before the restoration, refer to Preparation for restoration for the preparation.
Execute the br restore command:
bin/br restore table --db batchmark --table order_line -s local:///br_data --pd 172.16.5.198:2379 --log-file restore-nfs.log
Monitoring metrics for the restoration
During the restoration process, pay attention to the following metrics on the monitoring panels to get the status of the restoration process.
CPU Utilization: the CPU usage rate of each working TiKV node in the restoration operation.
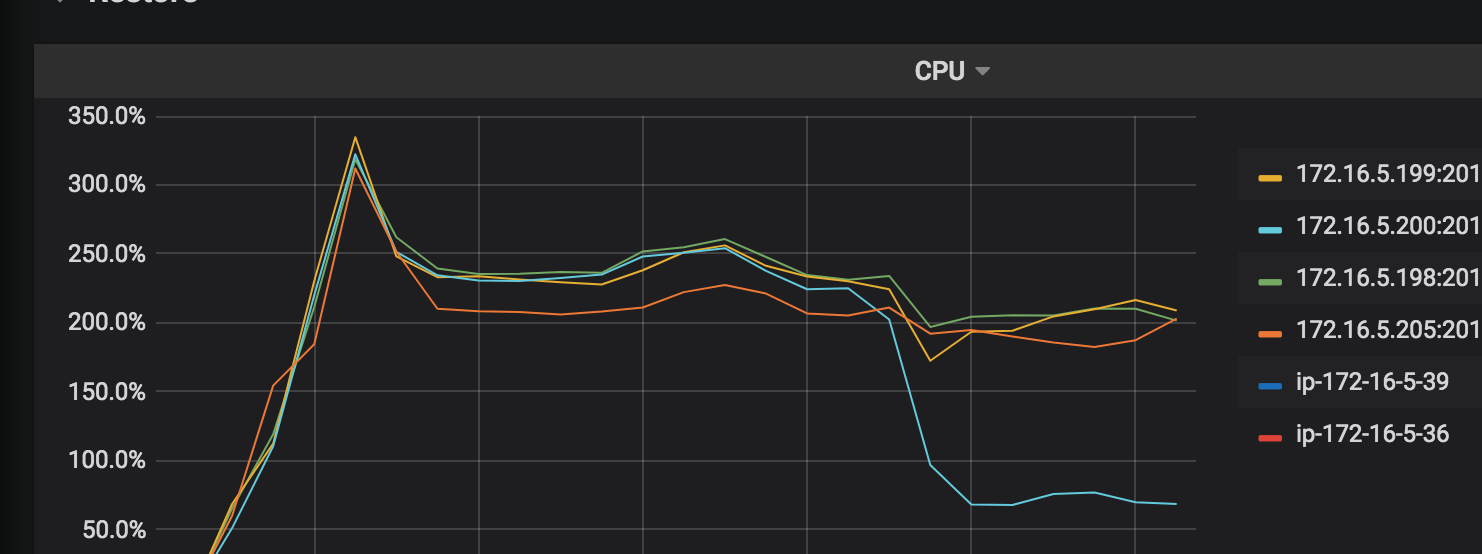
IO Utilization: the I/O usage rate of each working TiKV node in the restoration operation.
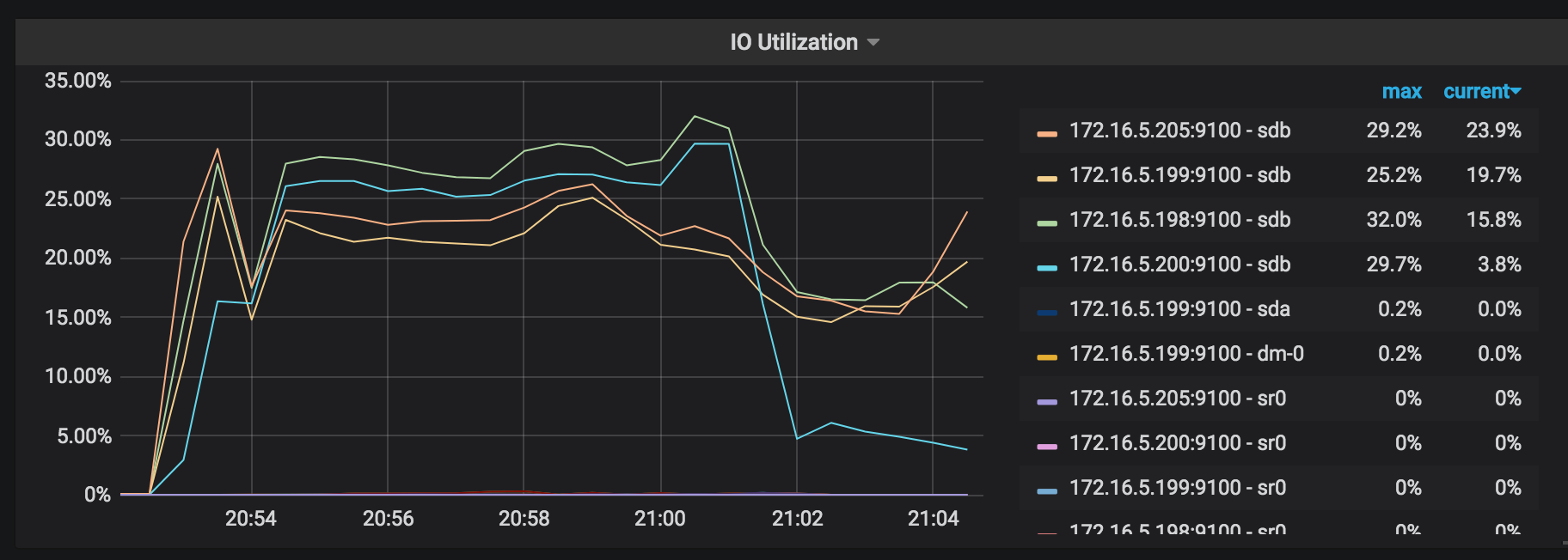
Region: the Region distribution. The more even Regions are distributed, the better the restoration resources are used.
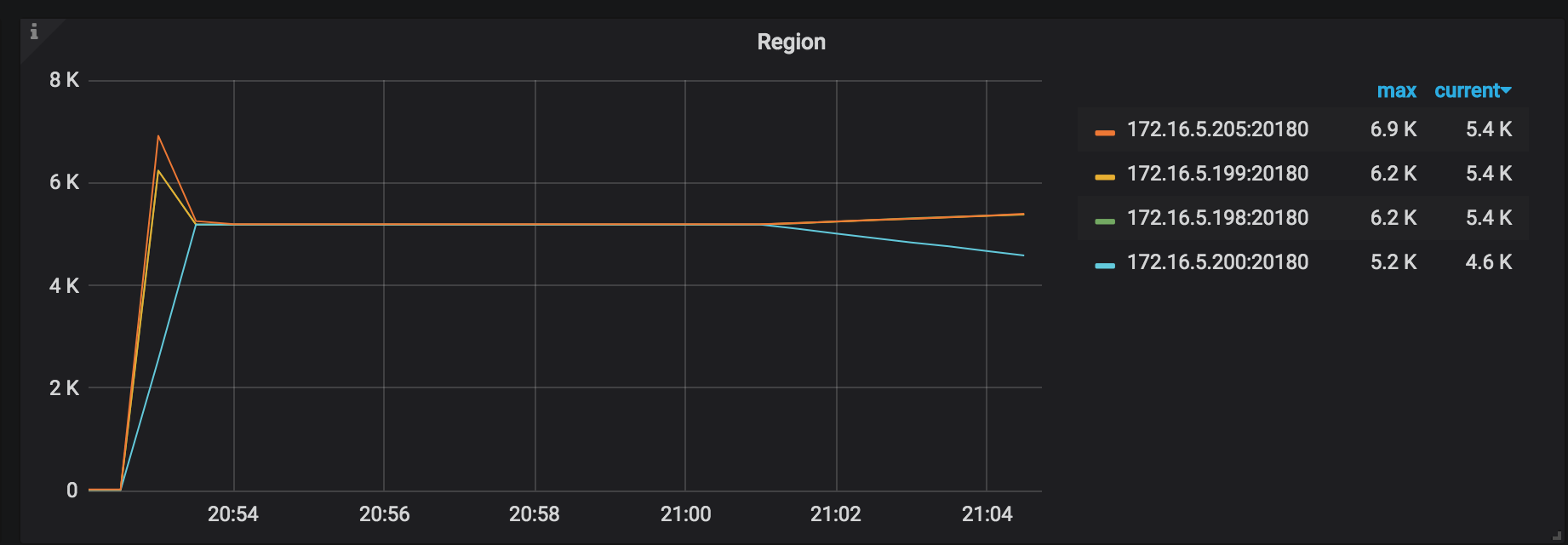
Process SST Duration: the delay of processing the SST files. When restoring a table, if tableID is changed, you need to rewrite tableID. Otherwise, tableID is renamed. Generally, the delay of rewriting is longer than that of renaming.
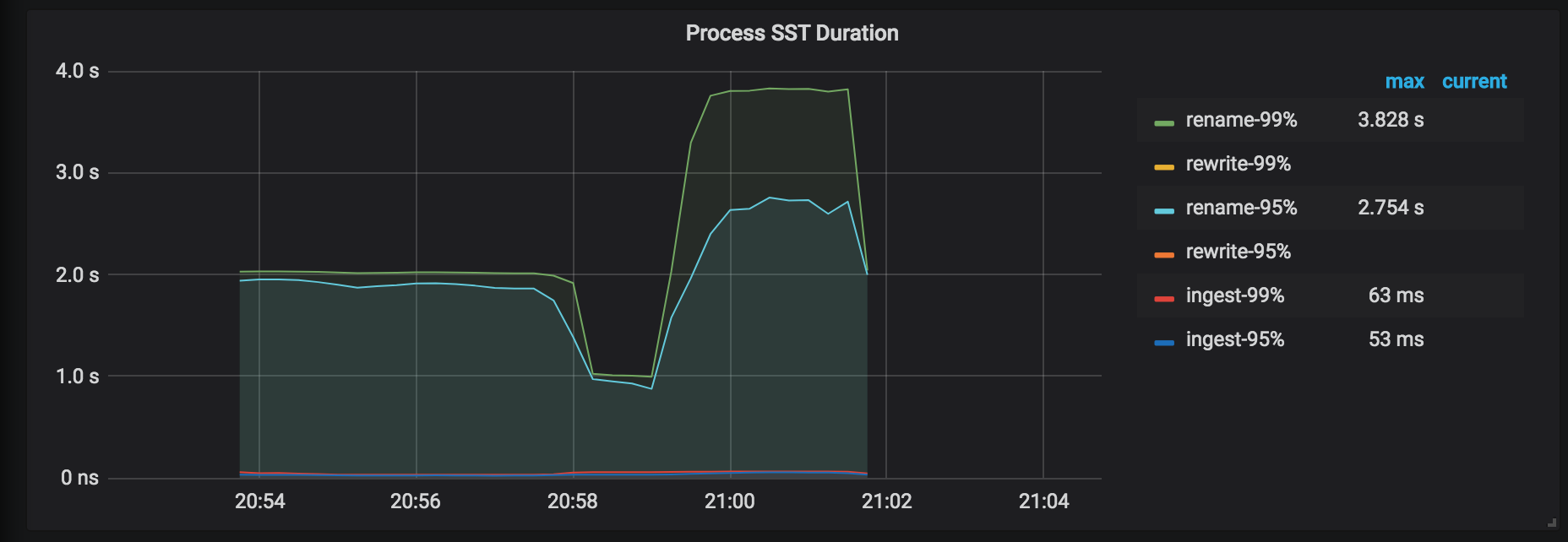
DownLoad SST Throughput: the throughput of downloading SST files from External Storage.
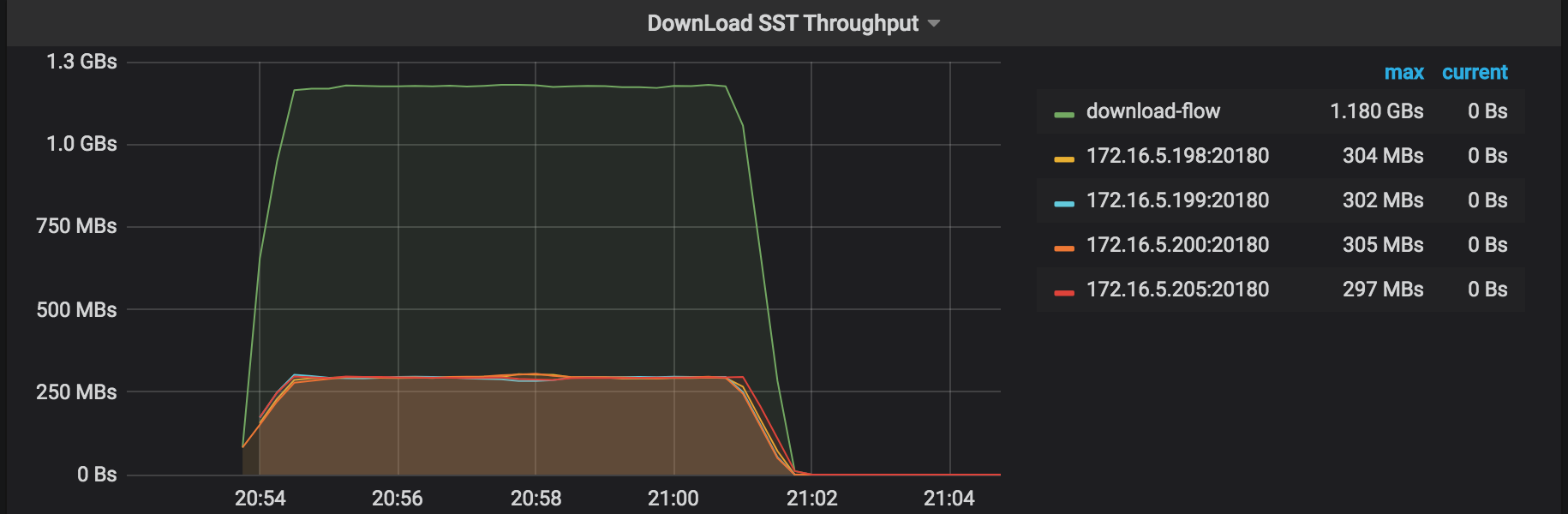
Restore Errors: the errors occurred during the restoration process.
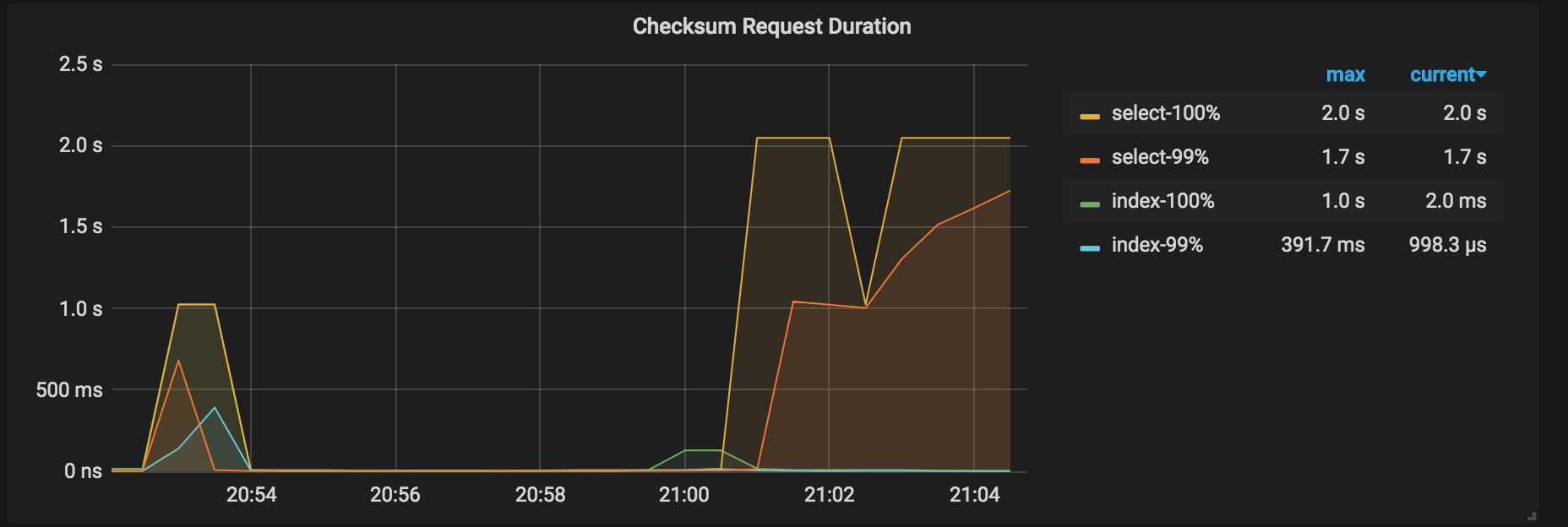
Checksum Request duration: the duration of the admin checksum request. This duration for the restoration is longer than that for the backup.
Restoration results explanation
Before executing the restoration command, a path in which the log is stored has been specified. You can get the statistical information of the restoration operation from this log. Search "summary" in this log, you can see the following information:
["Table Restore summary:
total restore tables: 1,
total success: 1,
total failed: 0,
total take(Full restore time): 17m1.001611365s,
total take(real time): 16m1.371611365s,
total kv: 5659888624,
total size(MB): 353227.18,
avg speed(MB/s): 367.42"]
["restore files"=9263]
["restore ranges"=6888]
["split region"=49.049182743s]
["restore checksum"=6m34.879439498s]
[Size=48693068713]
The above log includes the following information:
- Restore duration:
total take(Full restore time): 17m1.001611365s - Total runtime of the application:
total take(real time): 16m1.371611365s - Restore data size:
total size(MB): 353227.18 - Restore KV pair number:
total kv: 5659888624 - Restore throughput:
avg speed(MB/s): 367.42 Region Splitduration:take=49.049182743s- Restore checksum duration:
restore checksum=6m34.879439498s - The actual size of the restored data in the disk:
[Size=48693068713]
From the above information, the following items can be calculated:
- The throughput of a single TiKV instance:
avg speed(MB/s)/tikv_count=91.8 - The average restore speed of a single TiKV instance:
total size(MB)/(split time+restore time)/tikv_count=87.4
Performance tuning
If the resource usage of TiKV does not become an obvious bottleneck during the restore process, you can try to increase the value of --concurrency which is 128 by default. See the following example:
bin/br restore table --db batchmark --table order_line -s local:///br_data/ --pd 172.16.5.198:2379 --log-file restore-concurrency.log --concurrency 1024
The tuned performance results are as follows (with the same data size):
- Restore duration:
total take(s)reduced from961.37to443.49 - Restore throughput:
avg speed(MB/s)increased from367.42to796.47 - Throughput of a single TiKV instance:
avg speed(MB/s)/tikv_countincreased from91.8to199.1 - Average restore speed of a single TiKV instance:
total size(MB)/(split time+restore time)/tikv_countincreased from87.4to162.3
Back up a single table to a local disk (recommended in testing environment)
Use the br backup command to back up the single table --db batchmark --table order_line to the specified path local:///home/tidb/backup_local in the local disk.
Backup prerequisites
- Preparation for backup
- Each TiKV node has a separate disk to store the backupSST file.
- The
backup_endpointnode has a separate disk to store thebackupmetafile. - TiKV and the
backup_endpointnode must have the same directory for the backup (for example,/home/tidb/backup_local).
Topology
The following diagram shows the typology of BR:
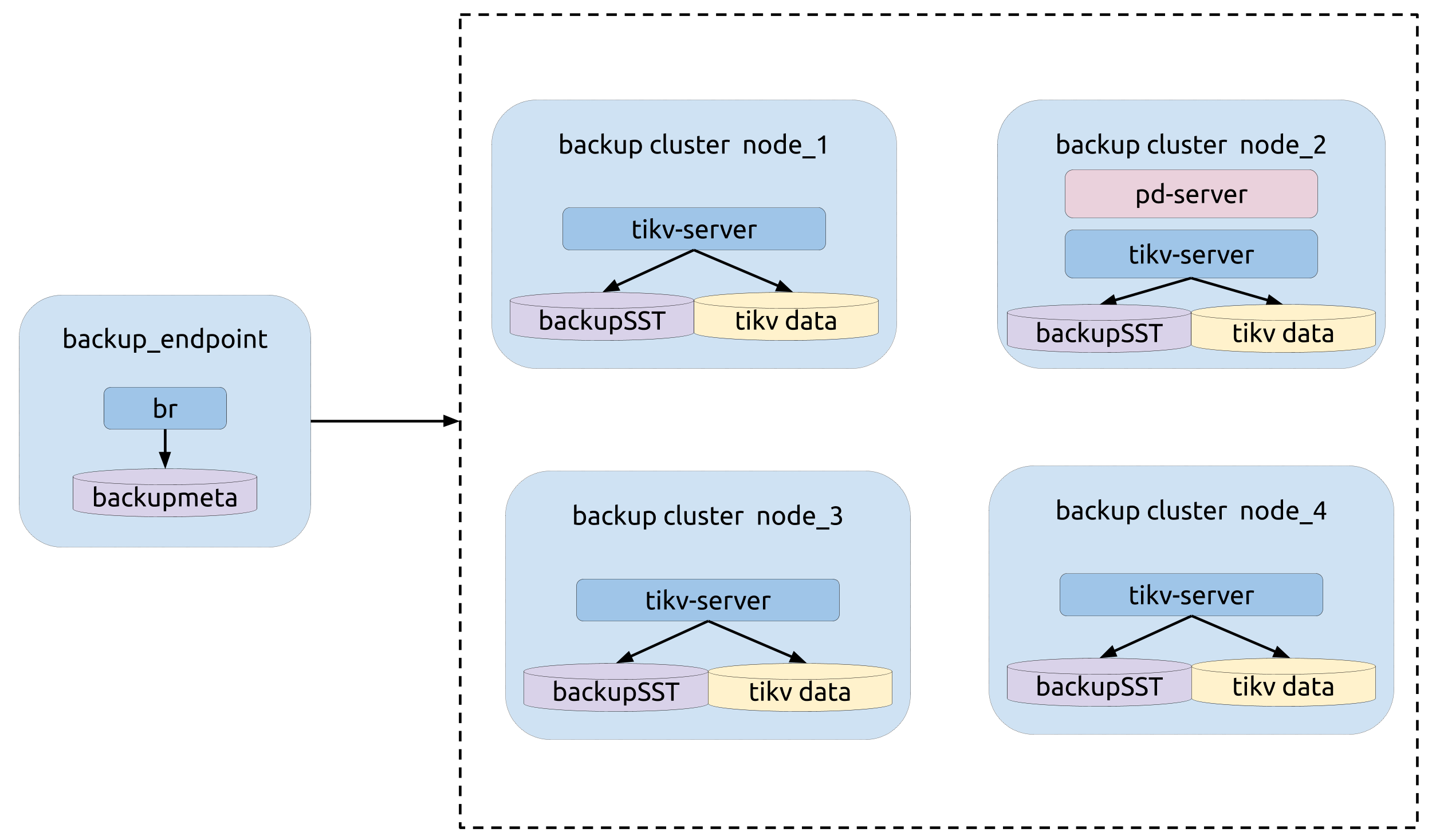
Backup operation
Before the backup operation, execute the admin checksum table order_line command to get the statistical information of the table to be backed up (--db batchmark --table order_line). The following image shows an example of this information:
Execute the br backup command:
bin/br backup table \
--db batchmark \
--table order_line \
-s local:///home/tidb/backup_local/ \
--pd ${PD_ADDR}:2379 \
--log-file backup_local.log
During the backup process, pay attention to the metrics on the monitoring panels to get the status of the backup process. See Monitoring metrics for the backup for details.
Backup results explanation
Before executing the backup command, a path in which the log is stored has been specified. You can get the statistical information of the backup operation from this log. Search "summary" in this log, you can see the following information:
["Table backup summary: total backup ranges: 4, total success: 4, total failed: 0, total take(s): 551.31, total kv: 5659888624, total size(MB): 353227.18, avg speed(MB/s): 640.71"] ["backup total regions"=6795] ["backup checksum"=6m33.962719217s] ["backup fast checksum"=22.995552ms]
The information from the above log includes:
- Backup duration:
total take(s): 551.31 - Data size:
total size(MB): 353227.18 - Backup throughput:
avg speed(MB/s): 640.71 - Backup checksum duration:
take=6m33.962719217s
From the above information, the throughput of a single TiKV instance can be calculated: avg speed(MB/s)/tikv_count = 160.
Restore data from a local disk (recommended in testing environment)
Use the br restore command to restore the complete backup data to an offline cluster. Currently, BR does not support restoring data to an online cluster.
Restoration prerequisites
- Preparation for restoration
- The TiKV cluster and the backup data do not have a duplicate database or table. Currently, BR does not support table route.
- Each TiKV node has a separate disk to store the backupSST file.
- The
restore_endpointnode has a separate disk to store thebackupmetafile. - TiKV and the
restore_endpointnode must have the same directory for the restoration (for example,/home/tidb/backup_local/).
Before the restoration, follow these steps:
- Collect all backupSST files into the same directory.
- Copy the collected backupSST files to all TiKV nodes of the cluster.
- Copy the
backupmetafile to therestore endpointnode.
Topology
The following diagram shows the typology of BR:
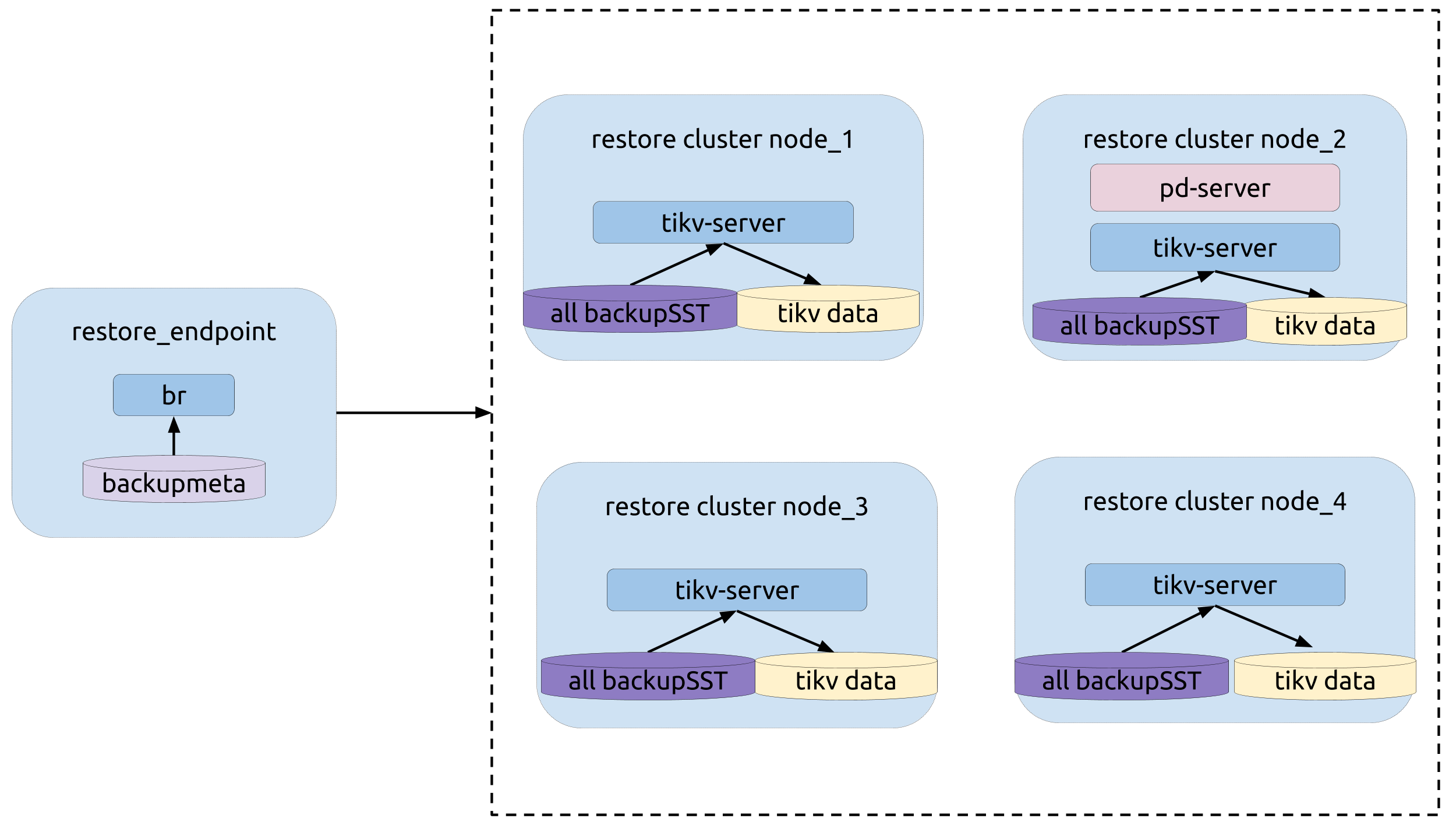
Restoration operation
Execute the br restore command:
bin/br restore table --db batchmark --table order_line -s local:///home/tidb/backup_local/ --pd 172.16.5.198:2379 --log-file restore_local.log
During the restoration process, pay attention to the metrics on the monitoring panels to get the status of the restoration process. See Monitoring metrics for the restoration for details.
Restoration results explanation
Before executing the restoration command, a path in which the log is stored has been specified. You can get the statistical information of the restoration operation from this log. Search "summary" in this log, you can see the following information:
["Table Restore summary: total restore tables: 1, total success: 1, total failed: 0, total take(s): 908.42, total kv: 5659888624, total size(MB): 353227.18, avg speed(MB/s): 388.84"] ["restore files"=9263] ["restore ranges"=6888] ["split region"=58.7885518s] ["restore checksum"=6m19.349067937s]
The above log includes the following information:
- Restoration duration:
total take(s): 908.42 - Data size:
total size(MB): 353227.18 - Restoration throughput:
avg speed(MB/s): 388.84 Region Splitduration:take=58.7885518s- Restoration checksum duration:
take=6m19.349067937s
From the above information, the following items can be calculated:
- The throughput of a single TiKV instance:
avg speed(MB/s)/tikv_count=97.2 - The average restoration speed of a single TiKV instance:
total size(MB)/(split time+restore time)/tikv_count=92.4
Error handling during backup
This section introduces the common errors occurred during the backup process.
key locked Error in the backup log
Error message in the log: log - ["backup occur kv error"][error="{\"KvError\":{\"locked\":
If a key is locked during the backup process, BR tries to resolve the lock. A small number of these errors do not affect the correctness of the backup.
Backup failure
Error message in the log: log - Error: msg:"Io(Custom { kind: AlreadyExists, error: \"[5_5359_42_123_default.sst] is already exists in /dir/backup_local/\" })"
If the backup operation fails and the above message occurs, perform one of the following operations and then start the backup operation again:
- Change the directory for the backup. For example, change
/dir/backup-2020-01-01/to/dir/backup_local/. - Delete the backup directory of all TiKV nodes and BR nodes.