Overview of TiDB Disaster Recovery Solutions
This document introduces the disaster recovery (DR) solutions provided by TiDB. The organization of this document is as follows:
- Describes the basic concepts in DR.
- Introduces the architecture of TiDB, TiCDC, and Backup & Restore (BR).
- Describes the DR solutions provided by TiDB.
- Compares these DR solutions.
Basic concepts
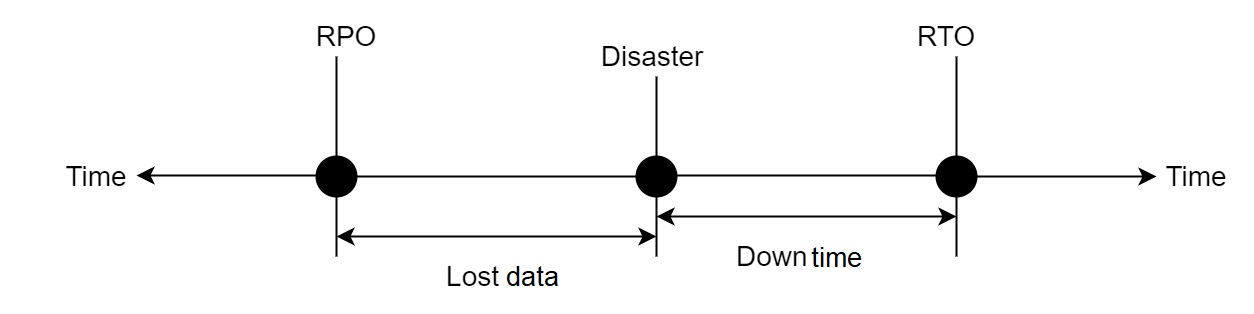
- RTO (Recovery Time Objective): The time required for the system to recover from a disaster.
- RPO (Recovery Point Objective): The maximum amount of data loss that the business can tolerate in a disaster.
The following figure illustrates these two concepts:
- Error tolerance objective: Because a disaster can affect different regions. In this document, the term error tolerance objective is used to describe the maximum range of a disaster that the system can tolerate.
- Region: This document focuses on regional DR and "region" mentioned here refers to a geographical area or city.
Component architecture
Before introducing specific DR solutions, this section introduces the architecture of TiDB components from the perspective of DR, including TiDB, TiCDC, and BR.
TiDB
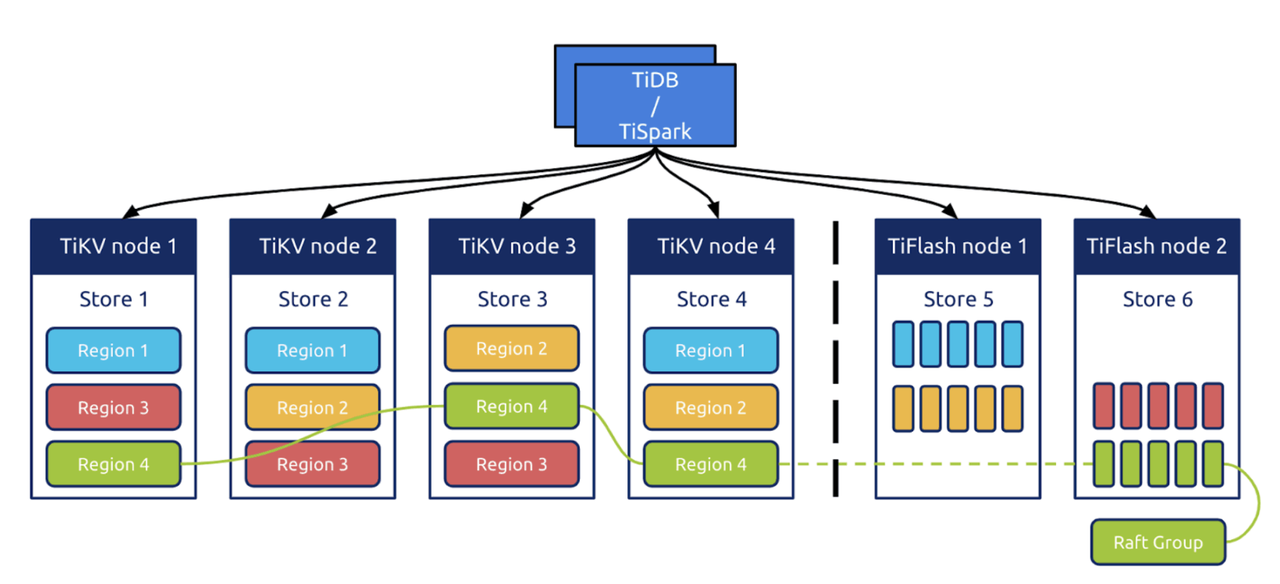
TiDB is designed with an architecture of separated computing and storage:
- TiDB is the SQL computing layer of the system.
- TiKV is the storage layer of the system, and is a row-based storage engine. Region is the basic unit for scheduling data in TiKV. A Region is a collection of sorted rows of data. The data in a Region is saved in at least three replicas, and data changes are replicated in the log layer through the Raft protocol.
- An optional component, TiFlash is a columnar storage engine that can be used to speed up analytical queries. Data is replicated from TiKV to TiFlash through the learner role in a Raft group.
TiDB stores three complete data replicas. Therefore, it is naturally capable of DR based on multiple replicas. At the same time, because TiDB uses Raft logs to replicate transaction logs, it can also provide DR based on transaction log replication.
TiCDC
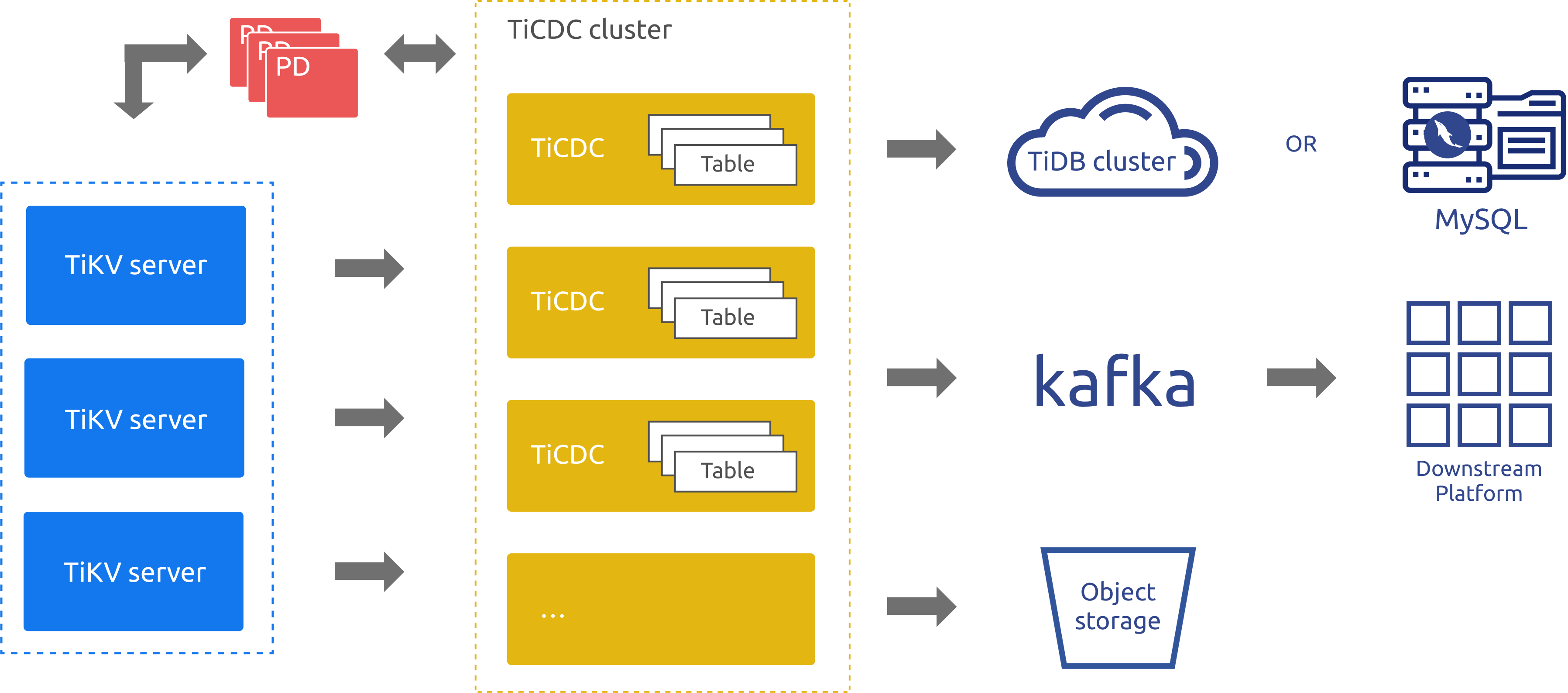
As an incremental data replication tool for TiDB, TiCDC is highly available through PD's etcd. TiCDC pulls data changes from TiKV nodes through multiple Capture processes, and then sorts and merges data changes internally. After that, TiCDC replicates data to multiple downstream systems by using multiple replication tasks. In the preceding architecture diagram:
- TiKV server: sends data changes in the upstream to TiCDC nodes. When TiCDC nodes find the change logs not continuous, they will actively request the TiKV server to provide change logs.
- TiCDC: runs multiple Capture processes. Each Capture process pulls part of the KV change logs, and sorts the pulled data before replicating the changes to different downstream systems.
It can be seen from the preceding architecture diagram that, the architecture of TiCDC is similar to that of a transactional log replication system, but with better scalability and merits of logical data replication. Therefore, TiCDC is a good supplementation for TiDB in the DR scenario.
BR
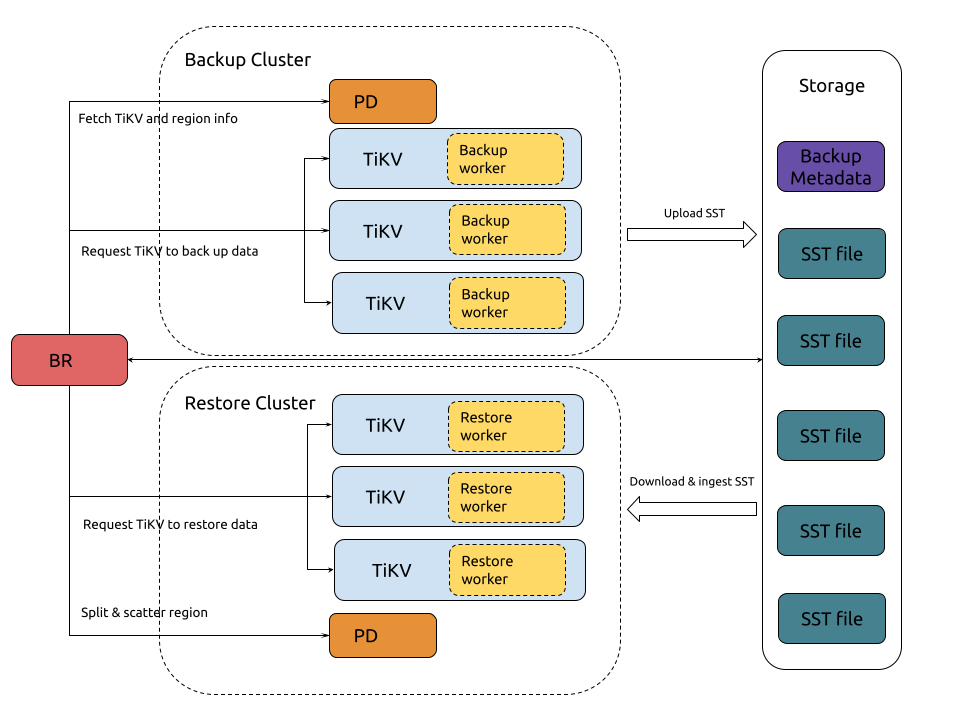
As a backup and restore tool for TiDB, BR can perform full snapshot backup based on a specific time point and continuous log backup of a TiDB cluster. When the TiDB cluster is completely unavailable, you can restore the backup files in a new cluster. BR is usually considered the last resort for data security.
Solutions introduction
DR solution based on primary and secondary clusters
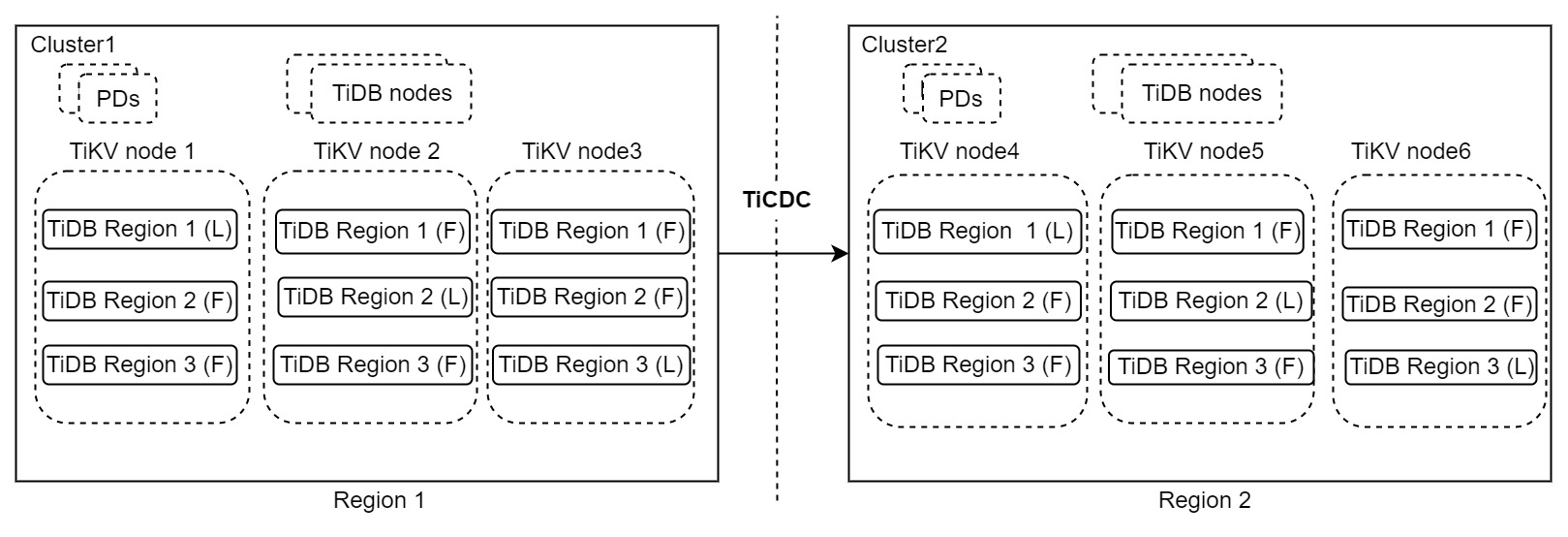
The preceding architecture contains two TiDB clusters, cluster 1 runs in region 1 and handles read and write requests. Cluster 2 runs in region 2 and works as the secondary cluster. When cluster 1 encounters a disaster, cluster 2 takes over services. Data changes are replicated between the two clusters using TiCDC. This architecture is also called the "1:1" DR solution.
This architecture is simple and highly available with region-level error tolerance objective, scalable write capability, second-level RPO, and minute-level RTO or even lower. If a production system does not require the RPO to be zero, this DR solution is recommended. For more information about this solution, see DR solution based on primary and secondary clusters.
DR solution based on multiple replicas in a single cluster
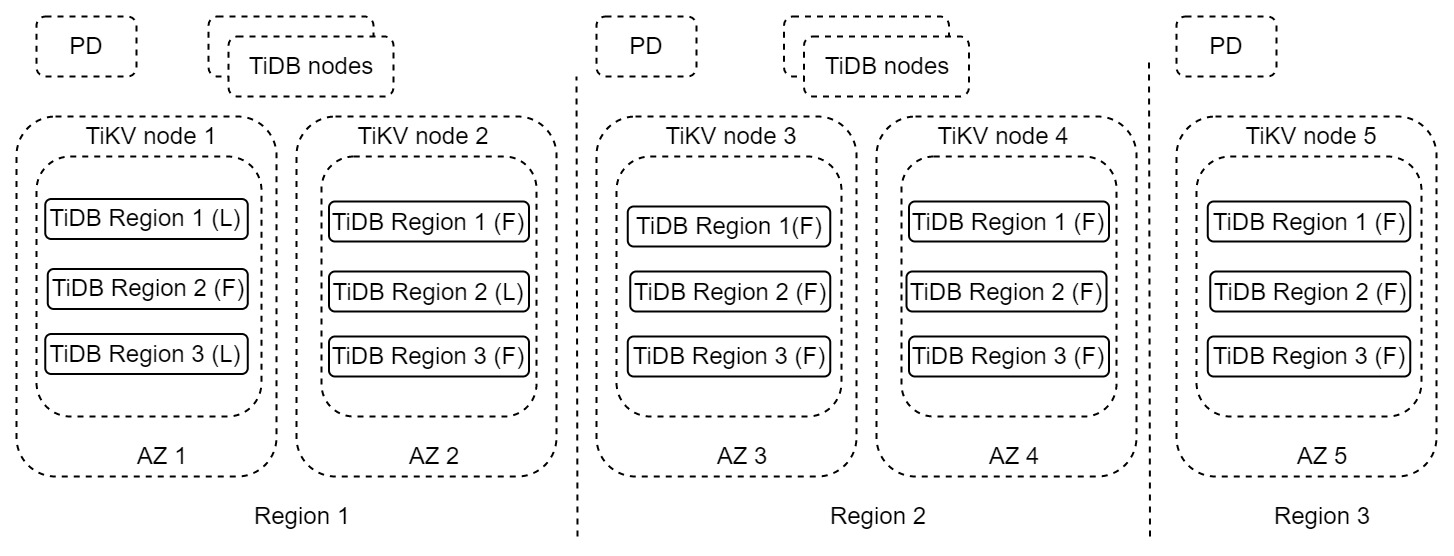
In the preceding architecture, each region has two complete data replicas located in different available zones (AZs). The entire cluster is across three regions. Region 1 is the primary region that handles read and write requests. When region 1 is completely unavailable due to a disaster, region 2 can be used as a DR region. Region 3 is a replica used to meet the majority protocol. This architecture is also called the "2-2-1" solution.
This solution provides region-level error tolerance, scalable write capability, zero RPO, and minute-level RTO or even lower. If a production system requires zero RPO, it is recommended to use this DR solution. For more information about this solution, see DR solution based on multiple replicas in a single cluster.
DR solution based on TiCDC and multiple replicas
The preceding two solutions provide regional DR. However, they fail to work if multiple regions are unavailable at the same time. If your system is very important and requires error tolerance objective to cover multiple regions, you need to combine these two solutions.
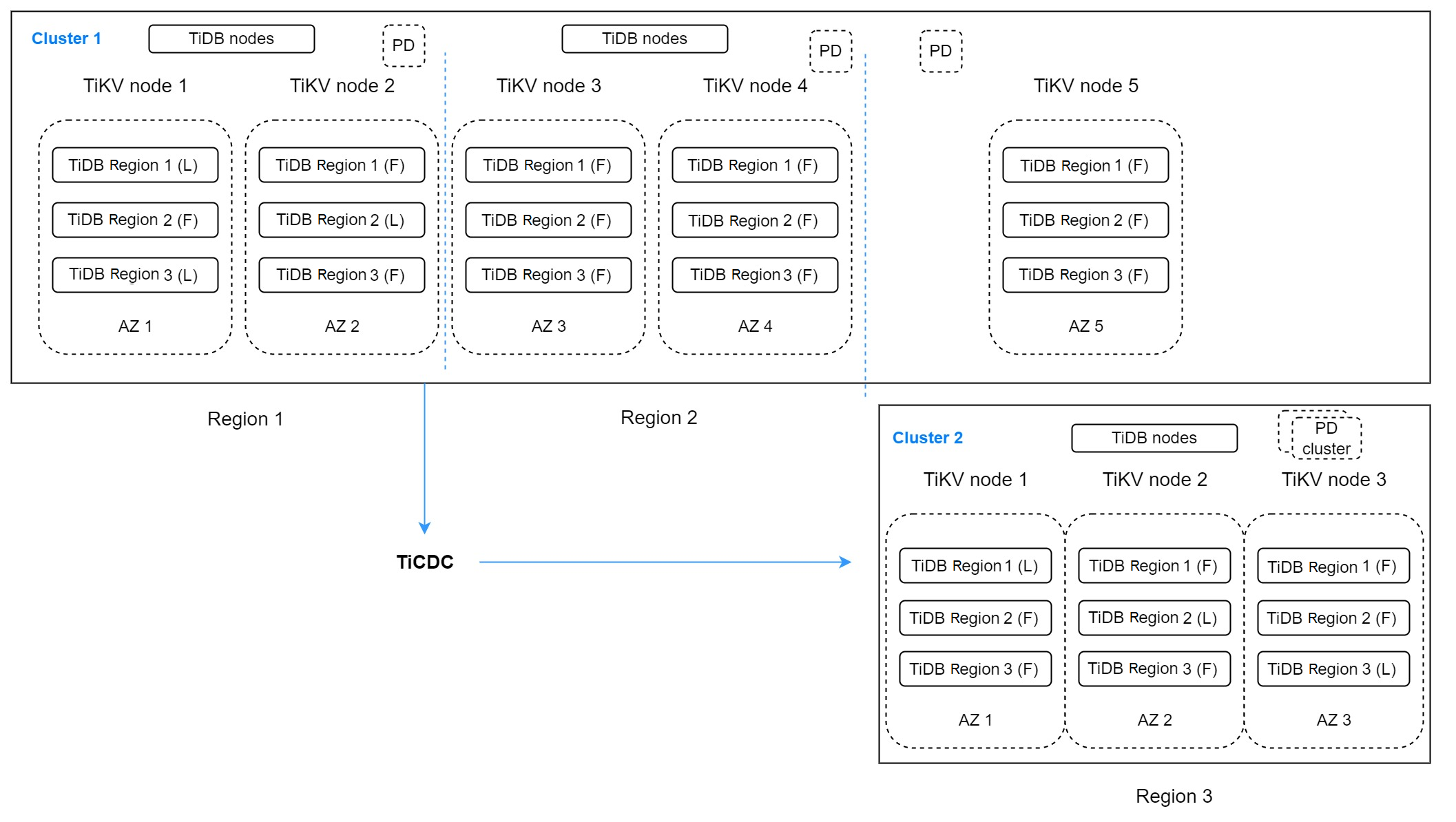
In the preceding architecture, there are two TiDB clusters. Cluster 1 has five replicas that span three regions. Region 1 contains two replicas that work as the primary region and handle write requests. Region 2 has two replicas that work as the DR region for region 1. This region provides read services that are not sensitive to latency. Located in Region 3, the last replica is used for voting.
As the DR cluster for region 1 and region 2, cluster 2 runs in region 3 and contains three replicas. TiCDC replicates data from cluster 1. This architecture looks complicated but it can increase the error tolerance objective to multiple regions. If the RPO is not required to be zero when multiple regions are unavailable at the same time, this architecture is a good choice. This architecture is also called the "2-2-1:1" solution.
Of course, if the error tolerance objective is multiple regions and RPO must be zero, you can also consider creating a cluster with at least nine replicas spanning five regions. This architecture is also called the "2-2-2-2-1" solution.
DR solution based on BR

In this architecture, TiDB cluster 1 is deployed in region 1. BR regularly backs up the data of cluster 1 to region 2, and continuously backs up the data change logs of this cluster to region 2 as well. When region 1 encounters a disaster and cluster 1 cannot be recovered, you can use the backup data and data change logs to restore a new cluster (cluster 2) in region 2 to provide services.
The DR solution based on BR provides an RPO lower than 5 minutes and an RTO that varies with the size of the data to be restored. For BR v6.5.0, you can refer to Performance and impact of snapshot restore and Performance and impact of PITR to learn about the restore speed. Usually, the feature of backup across regions is considered the last resort of data security and also a must-have solution for most systems. For more information about this solution, see DR solution based on BR.
Meanwhile, starting from v6.5.0, BR supports restoring a TiDB cluster from EBS volume snapshots. If your cluster is running on Kubernetes and you want to restore the cluster as fast as possible without affecting the cluster, you can use this feature to reduce the RTO of your system.
Other DR solutions
Besides the preceding DR solutions, if zero RPO is a must in the same-city dual-center scenario, you can also use the DR-AUTO sync solution. For more information, see Two Data Centers in One City Deployment.
Solution comparison
This section compares the DR solutions mentioned in this document, based on which you can select an appropriate DR solution to satisfy your business needs.