DML Replication Mechanism in Data Migration
This document introduces how the core processing unit Sync in DM processes DML statements read from the data source or relay log. This document introduces the complete processing flow of DML events in DM, including the logic of binlog reading, filtering, routing, transformation, optimization, and execution. This document also explains the DML optimization logic and DML execution logic in detail.
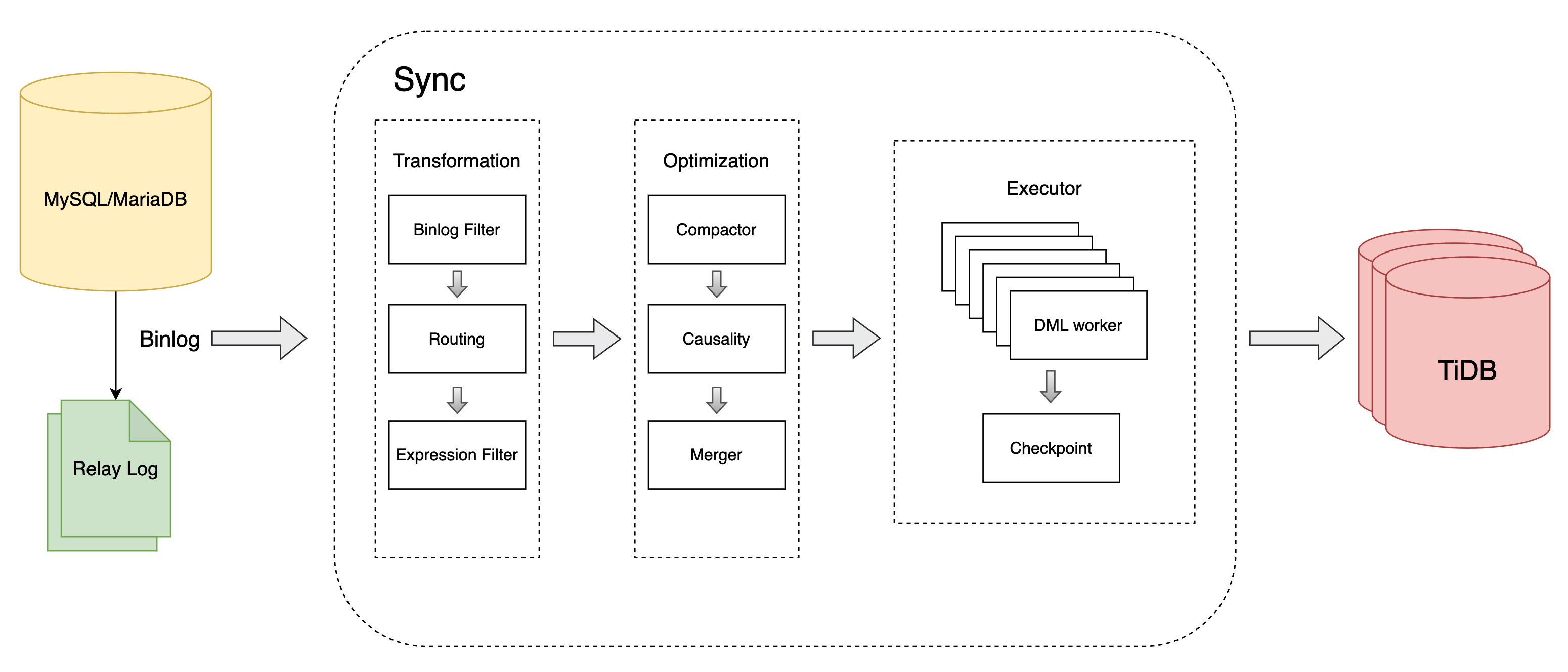
DML processing flow
The Sync unit processes DML statements as follows:
Read the binlog event from the MySQL, MariaDB, or relay log.
Transform the binlog event read from the data source:
- Binlog filter: filter binlog events according to binlog expressions, configured by
filters. - Table routing: transform the "database/table" name according to the "database/table" routing rule, configured by
routes. - Expression filter: filter binlog events according to SQL expressions, configured by
expression-filter.
- Binlog filter: filter binlog events according to binlog expressions, configured by
Optimize the DML execution plan:
- Compactor: merge multiple operations on the same record (with the same primary key) into one operation. This feature is enabled by
syncer.compact. - Causality: perform conflict detection on different records (with different primary keys) to improve the concurrency of replication.
- Merger: merge multiple binlog events into one DML statement, enabled by
syncer.multiple-rows.
- Compactor: merge multiple operations on the same record (with the same primary key) into one operation. This feature is enabled by
Execute the DML to the downstream.
Periodically save the binlog position or GTID to the checkpoint.
DML optimization logic
The Sync unit implements the DML optimization logic through three steps: Compactor, Causality, and Merger.
Compactor
According to the binlog records of the upstream, DM captures the changes of the records and replicates them to the downstream. When the upstream makes multiple changes to the same record (INSERT/UPDATE/DELETE) in a short period of time, DM can compress multiple changes into one change through Compactor to reduce the pressure on the downstream and improve the throughput. For example:
INSERT + UPDATE => INSERT
INSERT + DELETE => DELETE
UPDATE + UPDATE => UPDATE
UPDATE + DELETE => DELETE
DELETE + INSERT => UPDATE
The Compactor feature is disabled by default. To enable it, you can set syncer.compact to true in the sync configuration module of the replication task, as shown below:
syncers: # The configuration parameters of the sync processing unit
global: # Configuration name
... # Other configurations are omitted
compact: true
Causality
The sequential replication model of MySQL binlog requires that binlog events be replicated in the order of binlog. This replication model cannot meet the requirements of high QPS and low replication latency. In addition, because not all operations involved in binlog have conflicts, sequential replication is not necessary in those cases.
DM recognizes the binlog that needs to be executed sequentially through conflict detection, and ensures that these binlog are executed sequentially while maximizing the concurrency of other binlog. This helps improve the performance of binlog replication.
Causality adopts an algorithm similar to the union-find algorithm to classify each DML and group DMLs that are related to each other.
Merger
According to the MySQL binlog protocol, each binlog corresponds to a change operation of one row of data. Through Merger, DM can merge multiple binlogs into one DML and execute it to the downstream, reducing the network interaction. For example:
INSERT tb(a,b) VALUES(1,1);
+ INSERT tb(a,b) VALUES(2,2);
= INSERT tb(a,b) VALUES(1,1),(2,2);
UPDATE tb SET a=1, b=1 WHERE a=1;
+ UPDATE tb SET a=2, b=2 WHERE a=2;
= INSERT tb(a,b) VALUES(1,1),(2,2) ON DUPLICATE UPDATE a=VALUES(a), b=VALUES(b)
DELETE tb WHERE a=1
+ DELETE tb WHERE a=2
= DELETE tb WHERE (a) IN (1),(2);
The Merger feature is disabled by default. To enable it, you can set syncer.multiple-rows to true in the sync configuration module of the replication task, as shown below:
syncers: # The configuration parameters of the sync processing unit
global: # Configuration name
... # Other configurations are omitted
multiple-rows: true
DML execution logic
After the Sync unit optimizes the DML, it performs the execution logic.
DML generation
DM has an embedded schema tracker that records the schema information of the upstream and downstream:
- When DM receives a DDL statement, DM updates the table schema of the internal schema tracker.
- When DM receives a DML statement, DM generates the corresponding DML according to the table schema of the schema tracker.
The logic of generating DML is as follows:
- The Sync unit records the initial table structure of the upstream:
- When starting a full and incremental task, Sync uses the table structure exported during the upstream full data migration as the initial table structure of the upstream.
- When starting an incremental task, because MySQL binlog does not record the table structure information, Sync uses the table structure of the corresponding table in the downstream as the initial table structure of the upstream.
- The user's upstream and downstream table structures might be inconsistent, for example, the downstream might have additional columns than the upstream, or the upstream and downstream primary keys are inconsistent. Therefore, to ensure the correctness of data replication, DM records the primary key and unique key information of the corresponding table in the downstream.
- DM generates DML:
- Use the the upstream table structure recorded in the schema tracker to generate the column names of the DML statement.
- Use the column values recorded in the binlog to generate the column values of the DML statement.
- Use the downstream primary key or unique key recorded in the schema tracker to generate the
WHEREcondition of the DML statement. When the table structure has no unique key, DM uses all the column values recorded in the binlog as theWHEREcondition.
Worker count
Causality can divide binlog into multiple groups through conflict detection and execute them concurrently to the downstream. DM controls the concurrency by setting worker-count. When the CPU usage of the downstream TiDB is not high, increasing the concurrency can effectively improve the throughput of data replication.
You can modify the number of threads that concurrently migrate DML by modifying the syncer.worker-count configuration item.
Batch
DM batches multiple DMLs into a single transaction and executes it to the downstream. When a DML worker receives a DML, it adds the DML to the cache. When the number of DMLs in the cache reaches the preset threshold, or the DML worker does not receive DML for a long time, the DML worker executes the DMLs in the cache to the downstream.
You can modify the number of DMLs contained in a transaction by modifying the syncer.batch configuration item.
checkpoint
The operation of executing DML and updating checkpoint is not atomic.
In DM, checkpoint is updated every 30 seconds by default. Because there are multiple DML worker processes, the checkpoint process calculates the binlog position of the earliest replication progress of all DML workers, and uses this position as the current replication checkpoint. All binlogs earlier than this position are guaranteed to be successfully executed to the downstream.
Notes
Transaction consistency
DM replicates data at the row level and does not guarantee transaction consistency. In DM, an upstream transaction is split into multiple rows and distributed to different DML workers for concurrent execution. Therefore, when the DM replication task reports an error and pauses, or when the user manually pauses the task, the downstream might be in an intermediate state. That is, the DML statements in an upstream transaction might be partially replicated to the downstream, which might cause the downstream to be in an inconsistent state.
To ensure that the downstream is in a consistent state when the task is paused as much as possible, starting from DM v5.3.0, DM waits for 10 seconds before pausing the task to ensure that all transactions from the upstream are replicated to the downstream. However, if a transaction is not replicated to the downstream within 10 seconds, the downstream might still be in an inconsistent state.
Safe mode
The operation of DML execution and checkpoint update is not atomic, and the operation of checkpoint update and writing data to the downstream is also not atomic. When DM exits abnormally, the checkpoint might only record a recovery point before the exit time. Therefore, when the task is restarted, DM might write the same data multiple times, which means that DM actually provides the "at least once processing" logic, and the same data might be processed more than once.
To make sure the data is reentrant, DM enters the safe mode when it restarts from an abnormal exit.
When the safe mode is enabled, to make sure that data can be processed multiple times, DM performs the following conversions:
- Rewrite the
INSERTstatement of the upstream to theREPLACEstatement. - Rewrite the
UPDATEstatement of the upstream to theDELETE+REPLACEstatement.
Exactly-once processing
Currently, DM only guarantees eventual consistency and does not support "exactly-once processing" and "keeping the original order of transactions".