TiCDC New Architecture
Starting from TiCDC v8.5.4-release.1, TiCDC introduces a new architecture that improves the performance, scalability, and stability of real-time data replication while reducing resource costs.
This new architecture redesigns TiCDC core components and optimizes its data processing workflows, while maintaining compatibility with the configuration, usage, and APIs of the classic TiCDC architecture. It offers the following advantages:
- Higher single-node performance: a single node can replicate up to 500,000 tables, achieving replication throughput of up to 190 MiB/s on a single node in wide table scenarios.
- Enhanced scalability: cluster replication capability scales almost linearly. A single cluster can expand to over 100 nodes, support more than 10,000 changefeeds, and replicate millions of tables within a single changefeed.
- Improved stability: changefeed latency is reduced and performance is more stable in scenarios with high traffic, frequent DDL operations, and cluster scaling events. Resource isolation and priority scheduling reduce interference between multiple changefeed tasks.
- Lower resource costs: with improved resource utilization and reduced redundancy, CPU and memory resource usage can decrease by up to 50% in typical scenarios.
Architectural design
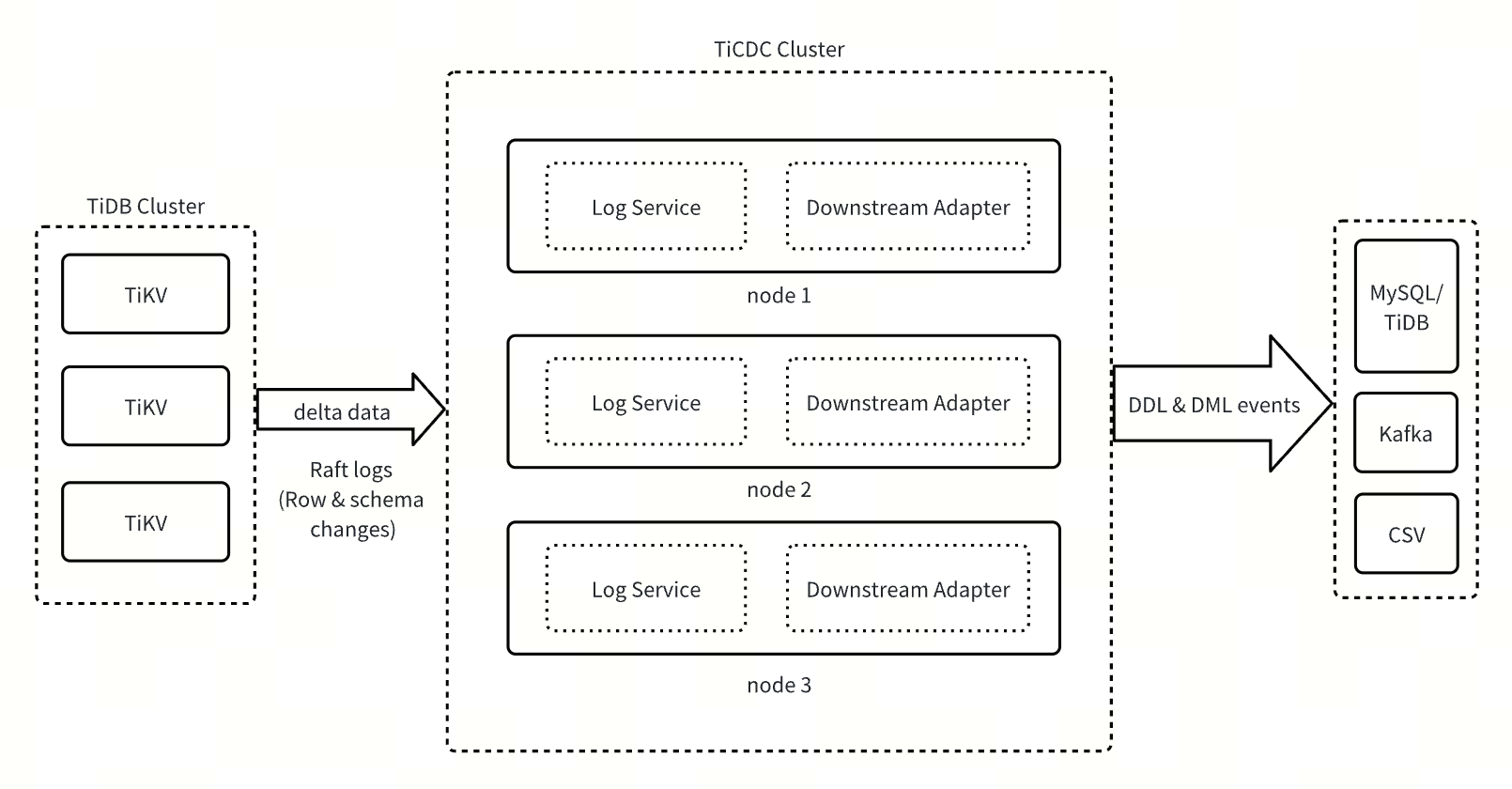
The TiCDC new architecture consists of two core components: Log Service and Downstream Adapter.
- Log Service: as the core data service layer, Log Service fetches information such as row changes and DDL events from the upstream TiDB cluster, and then temporarily stores the change data on local disks. It also responds to data requests from the Downstream Adapter, periodically merging and sorting DML and DDL data and pushing the sorted data to the Downstream Adapter.
- Downstream Adapter: as the downstream data replication adaptation layer, Downstream Adapter handles user-initiated changefeed operations. It schedules and generates related replication tasks, fetches data from the Log Service, and replicates the fetched data to downstream systems.
By separating the architecture into stateful and stateless components, the TiCDC new architecture significantly improves system scalability, reliability, and flexibility. Log Service, as the stateful component, focuses on data acquisition, sorting, and storage. Decoupling it from changefeed processing logic enables data sharing across multiple changefeeds, effectively improving resource utilization and reducing system overhead. Downstream Adapter, as the stateless component, uses a lightweight scheduling mechanism that allows quick migration of replication tasks between instances. It can dynamically adjust the splitting and merging of replication tasks based on workload changes, ensuring low-latency replication in various scenarios.
Comparison between the classic and new architectures
The new architecture is designed to address common issues during continuous system scaling, such as performance bottlenecks, insufficient stability, and limited scalability. Compared with the classic architecture, the new architecture achieves significant optimizations in the following key dimensions:
Choose between the classic and new architectures
If your workload meets any of the following conditions, it is recommended to switch from the classic TiCDC architecture to the new architecture for better performance and stability:
- Bottlenecks in incremental scan performance: incremental scan tasks take an excessively long time to complete, leading to continuously increasing replication latency.
- Ultra-high traffic scenarios: the total changefeed traffic exceeds 700 MiB/s.
- Single tables with high-throughput writes in MySQL sink: the target table has only one primary key or non-null unique key.
- Large-scale table replication: the number of tables to be replicated exceeds 100,000.
- Frequent DDL operations causing latency: frequent execution of DDL statements significantly increases replication latency.
New features
The new architecture supports table-level task splitting for all sinks. You can enable this feature by setting scheduler.enable-table-across-nodes = true in the changefeed configuration.
When this feature is enabled, TiCDC automatically splits and distributes tables across multiple nodes for parallel replication if those tables meet any of the following conditions. This improves replication efficiency and resource utilization:
- The table Region count exceeds the configured threshold (
10000by default, adjustable viascheduler.region-threshold). - The table write traffic exceeds the configured threshold (disabled by default, configurable via
scheduler.write-key-threshold).
Recommended configurations for table-level task splitting
After switching to the new TiCDC architecture, do not reuse the table-splitting configurations from the classic architecture. In most scenarios, use the default configuration of the new architecture. Make incremental adjustments based on the default values only in special scenarios where replication performance bottlenecks or scheduling imbalance occur.
In table split mode, pay attention to the following settings:
scheduler.region-threshold: the default value is10000. When the number of Regions in a table exceeds this threshold, TiCDC splits the table. For tables with relatively few Regions but high overall write throughput, you can reduce this value appropriately. This parameter must be greater than or equal toscheduler.region-count-per-span. Otherwise, tasks might be rescheduled repeatedly, which increases replication latency.scheduler.region-count-per-span: the default value is100. During changefeed initialization, tables that meet the split conditions are split according to this parameter. After splitting, each split sub-table contains at mostregion-count-per-spanregions.scheduler.write-key-threshold: the default value is0(disabled). When the sink write throughput of a table exceeds this threshold, TiCDC triggers table splitting. In most cases, keep this parameter to0.
Compatibility
Except as described in the following special cases, the TiCDC new architecture is fully compatible with the classic architecture.
DDL progress tracking table
In the TiCDC classic architecture, DDL replication operations are strictly serial, thus the replication progress can be tracked only using the changefeed's CheckpointTs. In the new architecture, however, TiCDC replicates DDL changes for different tables in parallel whenever possible to improve DDL replication efficiency. To accurately record the DDL replication progress of each table in a downstream MySQL-compatible database, the TiCDC new architecture creates a table named tidb_cdc.ddl_ts_v1 in the downstream database, specifically storing the DDL replication progress information of the changefeed.
Changes in DDL replication behavior
The classic TiCDC architecture does not support DDLs that swap table names (for example,
RENAME TABLE a TO c, b TO a, c TO b;). The new architecture supports such DDLs.The new architecture unifies and simplifies the filtering rules for
RENAMEDDLs.In the classic architecture, the filtering logic is as follows:
- Single-table renaming: a DDL statement is replicated only if the old table name matches the filter rule.
- Multi-table renaming: a DDL statement is replicated only if both old and new table names match the filter rules.
In the new architecture, for both single-table and multi-table renaming, a DDL statement is replicated as long as old table names in the statement match the filter rules.
Take the following filter rule as an example:
[filter] rules = ['test.t*']- In the classic architecture: for single-table renaming, such as
RENAME TABLE test.t1 TO ignore.t1, the old table nametest.t1matches the rule, so it will be replicated. For a multi-table renaming, such asRENAME TABLE test.t1 TO ignore.t1, test.t2 TO test.t22;, because the new table nameignore.t1does not match the rule, it will not be replicated. - In the new TiCDC architecture: because the old table names in both
RENAME TABLE test.t1 TO ignore.t1andRENAME TABLE test.t1 TO ignore.t1, test.t2 TO test.t22;match the rules, both DDL statements will be replicated.
- In the classic architecture: for single-table renaming, such as
Limitations
The new TiCDC architecture incorporates all functionalities of the classic architecture. However, some features have not yet been fully tested. To ensure system stability, it is NOT recommended to use the following features in core production environments:
In addition, the new TiCDC architecture currently does not support splitting large transactions into multiple batches for downstream replication. As a result, there is still a risk of OOM when processing extremely large transactions. Make sure to evaluate and mitigate this risk appropriately before using the new architecture.
Upgrade guide
TiCDC in the new architecture can only be deployed in TiDB clusters of v7.5.0 or later versions. Before deployment, make sure your TiDB cluster meets this requirement.
You can deploy TiCDC nodes in the new architecture using TiUP or TiDB Operator.
Deploy a new TiDB cluster with TiCDC nodes in the new architecture
When deploying a new TiDB cluster of v8.5.4 or later using TiUP, you can also deploy TiCDC nodes in the new architecture at the same time. To do so, you only need to add the TiCDC-related section and set newarch: true in the configuration file that TiUP uses to start the TiDB cluster. The following is an example:
cdc_servers:
- host: 10.0.1.20
config:
newarch: true
- host: 10.0.1.21
config:
newarch: true
For more TiCDC deployment information, see Deploy a new TiDB cluster that includes TiCDC using TiUP.
When deploying a new TiDB cluster of v8.5.4 or later using TiDB Operator, you can also deploy TiCDC nodes in the new architecture at the same time. To do so, you only need to add the TiCDC-related section and set newarch = true in the cluster configuration file. The following is an example:
spec:
ticdc:
baseImage: pingcap/ticdc
version: v8.5.4
replicas: 3
config:
newarch = true
For more TiCDC deployment information, see Fresh TiCDC deployment.
Deploy TiCDC nodes in the new architecture in an existing TiDB cluster
To deploy TiCDC nodes in the new architecture using TiUP, take the following steps:
If your TiDB cluster does not have TiCDC nodes yet, refer to Scale out a TiCDC cluster to add new TiCDC nodes in the cluster. Otherwise, skip this step.
If your TiDB cluster version is earlier than v8.5.4, you need to manually download the TiCDC binary package of the new architecture, and then patch the downloaded file to your TiDB cluster. Otherwise, skip this step.
The download link follows this format:
https://tiup-mirrors.pingcap.com/cdc-${version}-${os}-${arch}.tar.gz, where${version}is the TiCDC version (see TiCDC releases for the new architecture for available versions),${os}is your operating system, and${arch}is the platform the component runs on (amd64orarm64).For example, to download the binary package of TiCDC v8.5.4-release.1 for Linux (x86-64), run the following command:
wget https://tiup-mirrors.pingcap.com/cdc-v8.5.4-release.1-linux-amd64.tar.gzIf your TiDB cluster has running changefeeds, refer to Pause a replication task to pause all replication tasks of the changefeeds.
# The default server port of TiCDC is 8300. cdc cli changefeed pause --server=http://<ticdc-host>:8300 --changefeed-id <changefeed-name>Patch the downloaded TiCDC binary file to your TiDB cluster using the
tiup cluster patchcommand:tiup cluster patch <cluster-name> ./cdc-v8.5.4-release.1-linux-amd64.tar.gz -R cdc --overwriteUpdate the TiCDC configuration using the
tiup cluster edit-configcommand to enable the new architecture:tiup cluster edit-config <cluster-name>server_configs: cdc: newarch: trueRefer to Resume replication task to resume all replication tasks:
# The default server port of TiCDC is 8300. cdc cli changefeed resume --server=http://<ticdc-host>:8300 --changefeed-id <changefeed-name>
To deploy TiCDC nodes in the new architecture in an existing TiDB cluster using TiDB Operator, take the following steps:
If your TiDB cluster does not include a TiCDC component, refer to Add TiCDC to an existing TiDB cluster to add new TiCDC nodes. When doing so, specify the TiCDC image version as the new architecture version in the cluster configuration file. For available versions, see TiCDC releases for the new architecture.
For example:
spec: ticdc: baseImage: pingcap/ticdc version: v8.5.4-release.1 replicas: 3 config: newarch = trueIf your TiDB cluster already includes a TiCDC component, take the following steps:
If your TiDB cluster has running changefeeds, pause all replication tasks of the changefeeds:
kubectl exec -it ${pod_name} -n ${namespace} -- sh# The default server port of TiCDC deployed via TiDB Operator is 8301. /cdc cli changefeed pause --server=http://127.0.0.1:8301 --changefeed-id <changefeed-name>Update the TiCDC image version in the cluster configuration file to the new architecture version:
kubectl edit tc ${cluster_name} -n ${namespace}spec: ticdc: baseImage: pingcap/ticdc version: v8.5.4-release.1 replicas: 3kubectl apply -f ${cluster_name} -n ${namespace}Resume all replication tasks of the changefeeds:
kubectl exec -it ${pod_name} -n ${namespace} -- sh# The default server port of TiCDC deployed via TiDB Operator is 8301. /cdc cli changefeed resume --server=http://127.0.0.1:8301 --changefeed-id <changefeed-name>
Use the new architecture
After deploying the TiCDC nodes with the new architecture, you can continue using the same commands as in the classic architecture. There is no need to learn new commands or modify the commands used in the classic architecture.
For example, to create a replication task for a new TiCDC node in the new architecture, run the following command:
cdc cli changefeed create --server=http://127.0.0.1:8300 --sink-uri="mysql://root:123456@127.0.0.1:3306/" --changefeed-id="simple-replication-task"
To query details about a specific replication task, run the following command:
cdc cli changefeed query -s --server=http://127.0.0.1:8300 --changefeed-id=simple-replication-task
For more command usage methods and details, see Manage Changefeeds.
Monitoring
The monitoring dashboard for TiCDC in the new architecture is TiCDC-New-Arch. For TiDB clusters of v8.5.4 and later versions, this monitoring dashboard is integrated into Grafana during cluster deployment or upgrade, so no manual operation is required. If your cluster version is earlier than v8.5.4, you need to manually import the TiCDC monitoring metrics file to enable monitoring.
For importing steps and detailed descriptions of each monitoring metric, see Metrics for TiCDC in the new architecture.