BR Federation Architecture and Processes
BR Federation is a system designed to back up and restore TiDB clusters deployed across multiple Kubernetes using EBS snapshots.
Normally, TiDB Operator can only access the Kubernetes cluster where it is deployed. This means a TiDB Operator can only back up TiKV volumes' snapshots within its own Kubernetes cluster. However, to perform EBS snapshot backup and restore across multiple Kubernetes clusters, a coordinator role is required. This is where the BR Federation comes in.
This document outlines the architecture of the BR Federation and the processes involved in backup and restoration.
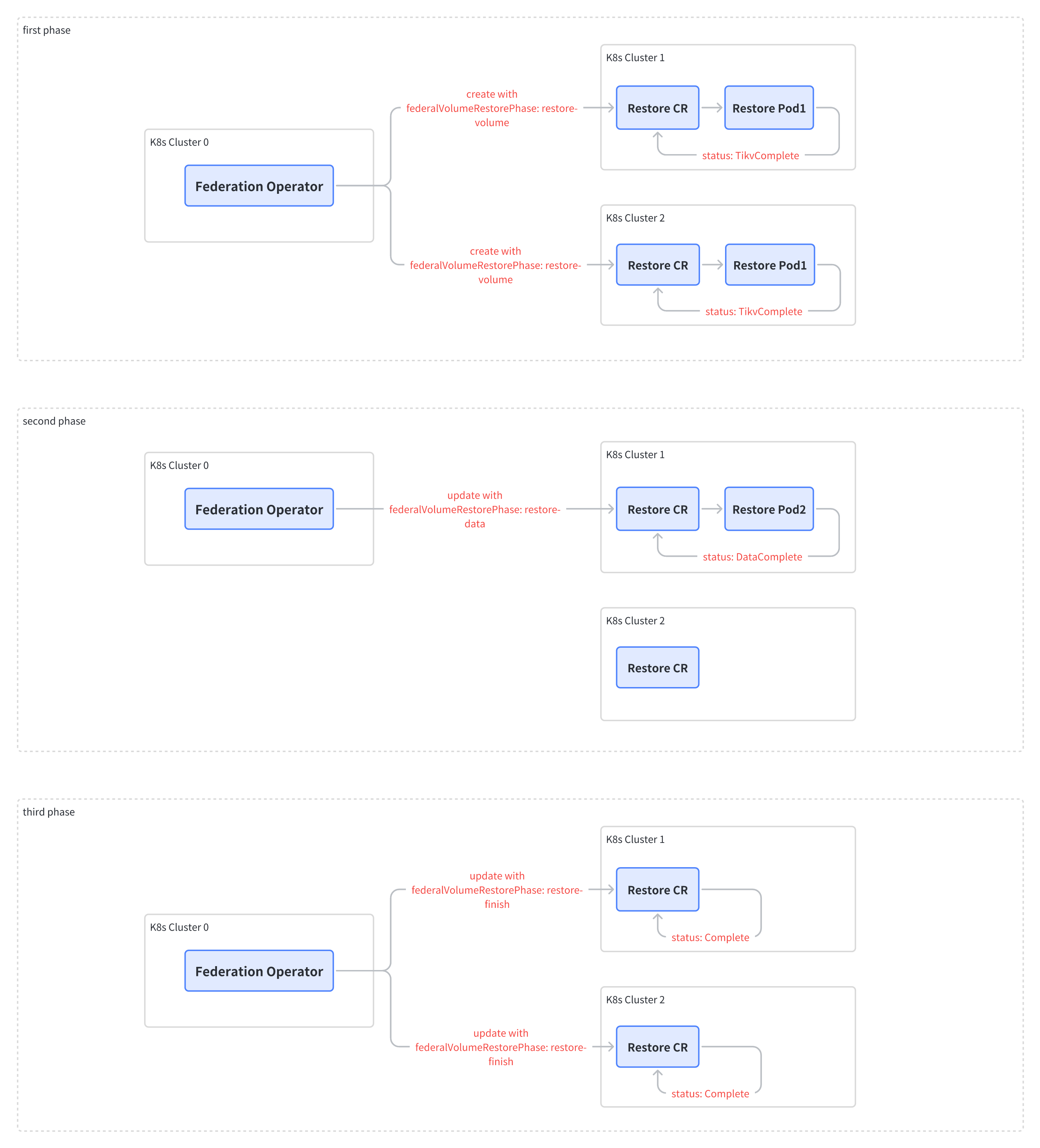
BR Federation architecture
BR Federation operates as the control plane, interacting with the data plane, which includes each Kubernetes cluster where TiDB components are deployed. The interaction is facilitated through the Kubernetes API Server.
BR Federation coordinates Backup and Restore Custom Resources (CRs) in the data plane to accomplish backup and restoration across multiple Kubernetes clusters.
Backup process
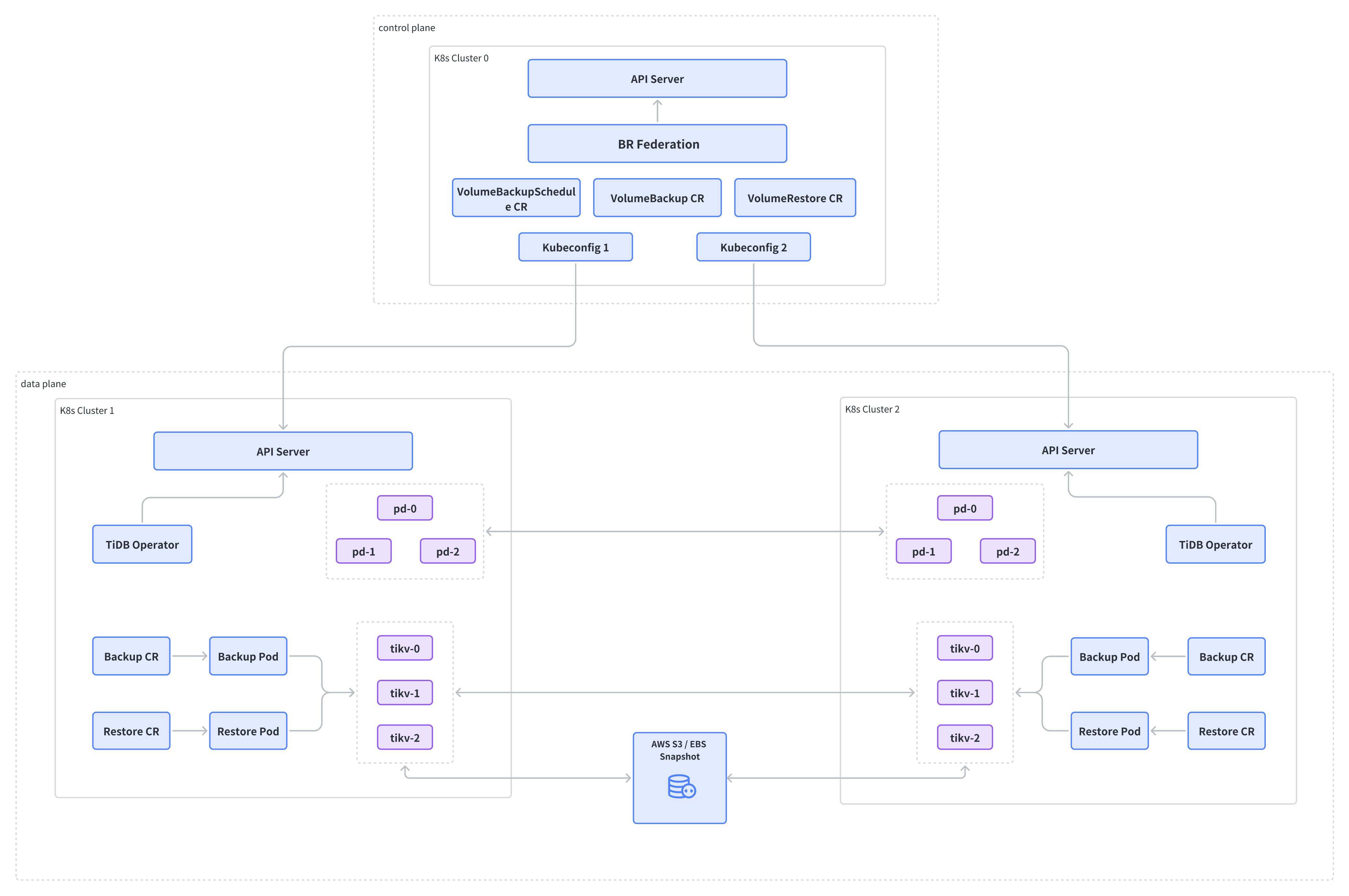
Backup process in data plane
The backup process in the data plane consists of three phases:
Phase One: TiDB Operator schedules a backup pod to request PD to pause region scheduling and Garbage Collection (GC). As each TiKV instance might take snapshots at different times, pausing scheduling and GC can avoid data inconsistencies between TiKV instances during snapshot taking. Since the TiDB components are interconnected across multiple Kubernetes clusters, executing this operation in one Kubernetes cluster affects the entire TiDB cluster.
Phase Two: TiDB Operator collects meta information such as
TidbClusterCR and EBS volumes, and then schedules another backup pod to request AWS API to create EBS snapshots. This phase must be executed in each Kubernetes cluster.Phase Three: After EBS snapshots are completed, TiDB Operator deletes the first backup pod to resume region scheduling and GC for the TiDB cluster. This operation is required only in the Kubernetes cluster where Phase One was executed.
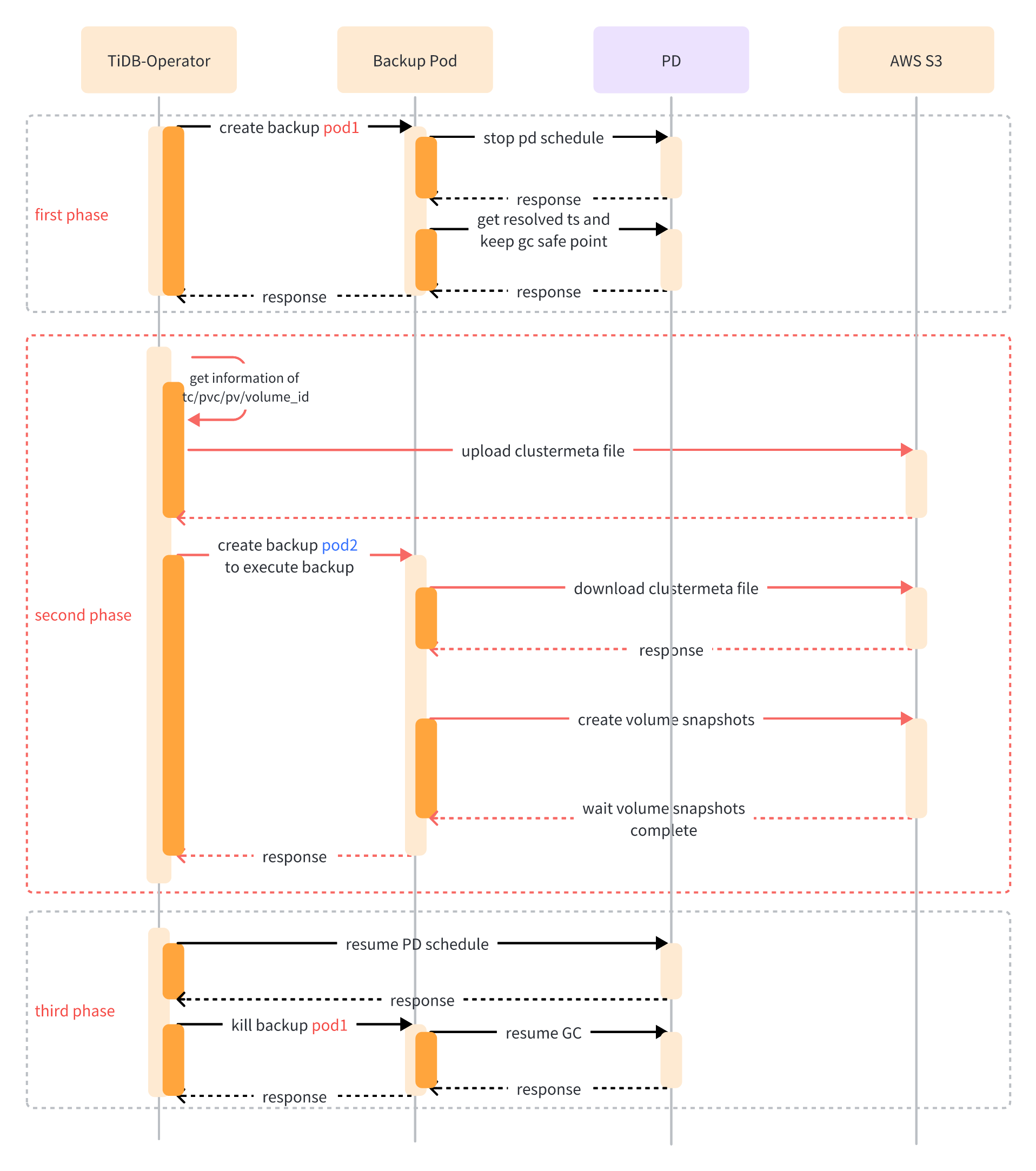
Backup orchestration process
The orchestration process of Backup from the control plane to the data plane is as follows:
Restore process
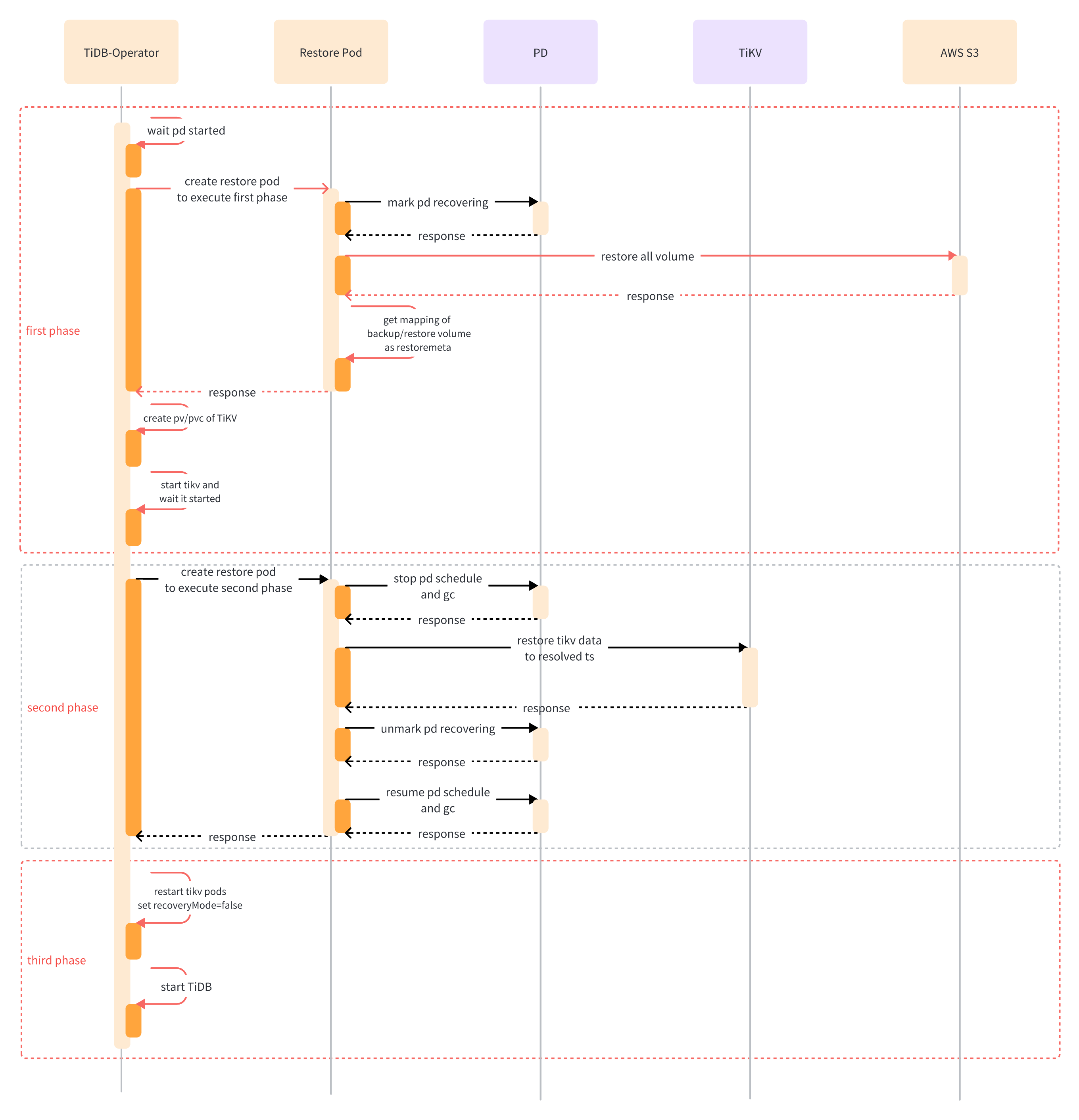
Restore process in data plane
The restore process in the data plane consists of three phases:
Phase One: TiDB Operator schedules a restore pod to request the AWS API to restore the EBS volumes using EBS snapshots based on the backup information. The volumes are then mounted onto the TiKV nodes, and TiKV instances are started in recovery mode. This phase must be executed in each Kubernetes cluster.
Phase Two: TiDB Operator schedules another restore pod to restore all raft logs and KV data in TiKV instances to a consistent state, and then instructs TiKV instances to exit recovery mode. As TiKV instances are interconnected across multiple Kubernetes clusters, this operation can restore all TiKV data and only needs to be executed in one Kubernetes cluster.
Phase Three: TiDB Operator restarts all TiKV instances to run in normal mode, and start TiDB finally. This phase must be executed in each Kubernetes cluster.
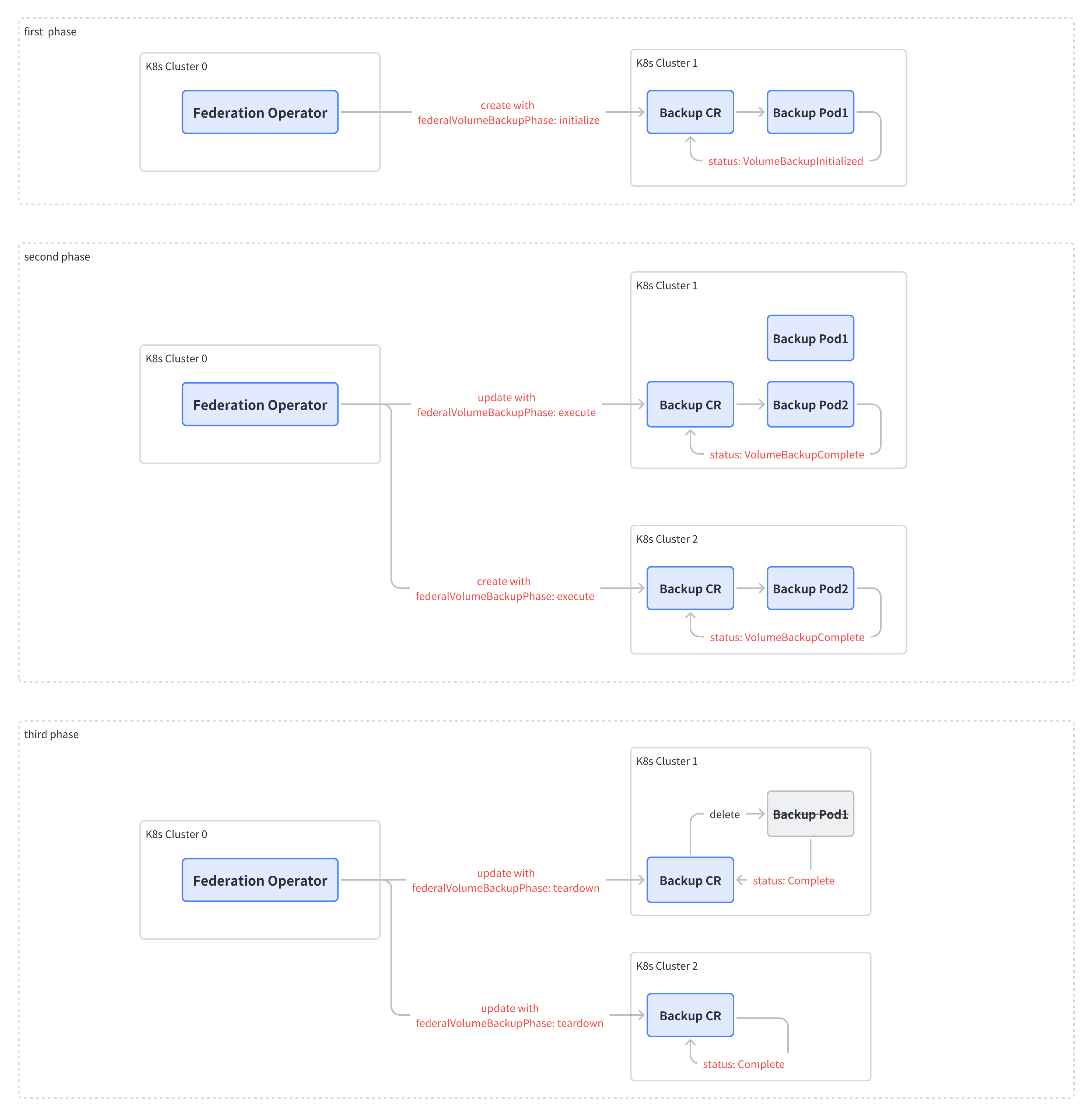
Restore orchestration process
The orchestration process of Restore from the control plane to the data plane is as follows: