TiDB Cloudの高可用性
TiDB Cloudは、高可用性とデータ耐久性をデフォルトで維持するための堅牢なメカニズムを備えており、単一障害点を回避し、障害発生時でも継続的なサービスを保証します。実績のあるTiDBオープンソース製品をベースとしたフルマネージドサービスとして、TiDBのコアとなる高可用性(HA)機能を継承し、クラウドネイティブな機能を追加することで強化されています。
注記:
- この文書は、 TiDB Cloud Starter とTiDB Cloud Essential 。
- TiDB Cloud Dedicated の高可用性については、 TiDB Cloud専用における高可用性参照してください。
概要
TiDBは、 Raftコンセンサスアルゴリズムを用いて、高い可用性とデータの耐久性を確保します。このアルゴリズムは、複数のノード間でデータの変更を一貫して複製するため、ノード障害やネットワーク分断が発生した場合でも、TiDBは読み取りおよび書き込みリクエストを処理できます。このアプローチにより、高いデータ耐久性とフォールトトレランスが両立します。
TiDB Cloud は、さまざまな運用要件を満たすために、ゾーン高可用性とリージョン高可用性によってこれらの機能を拡張します。
注記:
- TiDB Cloud Starter クラスターの場合、ゾーン高可用性のみが有効になっており、構成できません。
- AWS 東京 (ap-northeast-1) リージョンまたは Alibaba Cloud の任意のリージョンでホストされているTiDB Cloud Essential クラスターでは、リージョン高可用性がデフォルトで有効になっています。クラスター作成時に必要に応じてゾーン高可用性に変更できます。他のリージョンでホストされているTiDB Cloud Essential クラスターでは、ゾーン高可用性のみが有効になっており、設定変更はできません。
ゾーン高可用性:このオプションでは、すべてのノードを単一のアベイラビリティゾーンに配置することで、ネットワークレイテンシーを削減します。ゾーン間のアプリケーションレベルの冗長性を必要とせずに高可用性を確保できるため、単一ゾーン内での低レイテンシーを優先するアプリケーションに適しています。詳細については、 ゾーン高可用性アーキテクチャ参照してください。
リージョン高可用性(ベータ版) : このオプションでは、ノードを複数のアベイラビリティゾーンに分散することで、インフラストラクチャの分離と冗長性を最大限に高めます。最高レベルの可用性を提供しますが、ゾーン間でアプリケーションレベルの冗長性を確保する必要があります。ゾーン内のインフラストラクチャ障害に対する最大限の可用性保護が必要な場合は、このオプションを選択することをお勧めします。ただし、レイテンシーが増加し、ゾーン間のデータ転送料金が発生する可能性があることに注意してください。この機能は、3つ以上のアベイラビリティゾーンを持つリージョンで利用可能であり、クラスター作成時にのみ有効にできます。詳細については、 地域高可用性アーキテクチャ参照してください。
ゾーン高可用性アーキテクチャ
デフォルトのゾーン高可用性でクラスターを作成すると、ゲートウェイ、TiDB、TiKV、 TiFlash のコンピューティング/書き込みノードを含むすべてのコンポーネントが同じアベイラビリティゾーンで実行されます。これらのコンポーネントをデータプレーンに配置することで、仮想マシンプールによるインフラストラクチャの冗長性が確保され、コロケーションによるフェイルオーバー時間とネットワークレイテンシーが最小限に抑えられます。
次の図は、AWS 上のゾーン高可用性のアーキテクチャを示しています。
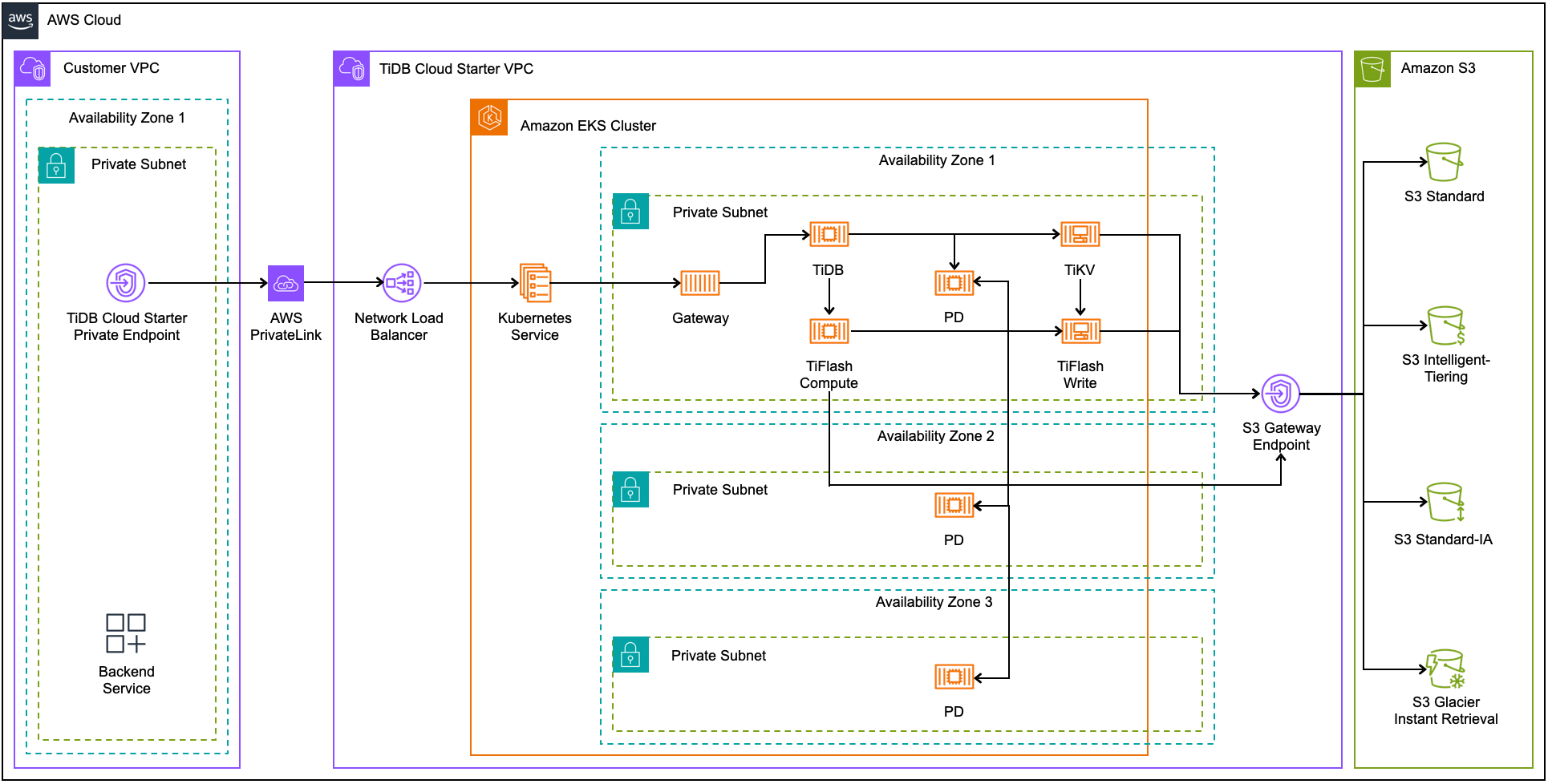
ゾーン高可用性アーキテクチャの場合:
- 配置Driver(PD) は複数の可用性ゾーンにデプロイされ、ゾーン間でデータを冗長的に複製することで高可用性を確保します。
- データは、ローカル アベイラビリティ ゾーン内の TiKV サーバーとTiFlash書き込みノード間で複製されます。
- TiDB サーバーとTiFlashコンピューティング ノードは、ストレージ レベルのレプリケーションによって保護されている TiKV およびTiFlash書き込みノードに対して読み取りと書き込みを行います。
フェイルオーバープロセス
TiDB Cloudは、アプリケーションの透過的なフェイルオーバープロセスを保証します。フェイルオーバー中は次のようになります。
障害が発生したレプリカを置き換えるために新しいレプリカが作成されます。
storageサービスを提供するサーバーは、Amazon S3 上の永続データからローカル キャッシュを復元し (クラウド プロバイダーによって異なります)、システムをレプリカとの整合性のある状態に復元します。
storageレイヤーでは、永続化されたデータは高い耐久性を確保するために定期的にAmazon S3にプッシュされます。さらに、即時更新は複数のTiKVサーバーに複製されるだけでなく、各サーバーのEBSにも保存され、さらにデータが複製されることで耐久性が向上します。TiDBは、数ミリ秒単位でバックオフと再試行を行うことで問題を自動的に解決し、クライアントアプリケーションにとってシームレスなフェイルオーバープロセスを実現します。
ゲートウェイ層とコンピューティング層はステートレスであるため、フェイルオーバーは即座に別の場所で再起動することを意味します。アプリケーションは接続の再試行ロジックを実装する必要があります。ゾーン構成は高可用性を実現しますが、ゾーン全体の障害には対応できません。ゾーンが利用できなくなった場合、ゾーンとそれに依存するサービスが復旧するまでダウンタイムが発生します。
地域高可用性アーキテクチャ
リージョン高可用性を備えたクラスターを作成すると、PDやTiKVなどの重要なOLTP(オンライントランザクション処理)ワークロードコンポーネントが複数のアベイラビリティゾーンに展開され、冗長レプリケーションが確保され、可用性が最大化されます。通常運用中は、ゲートウェイ、TiDB、 TiFlashのコンピューティング/書き込みノードなどのコンポーネントは、プライマリアベイラビリティゾーンでホストされます。データプレーン内のこれらのコンポーネントは、仮想マシンプールを通じてインフラストラクチャの冗長性を提供し、コロケーションによるフェイルオーバー時間とネットワークレイテンシーを最小限に抑えます。
注記:
地域的な高可用性は現在ベータ版です。
次の図は、AWS 上のリージョン高可用性のアーキテクチャを示しています。
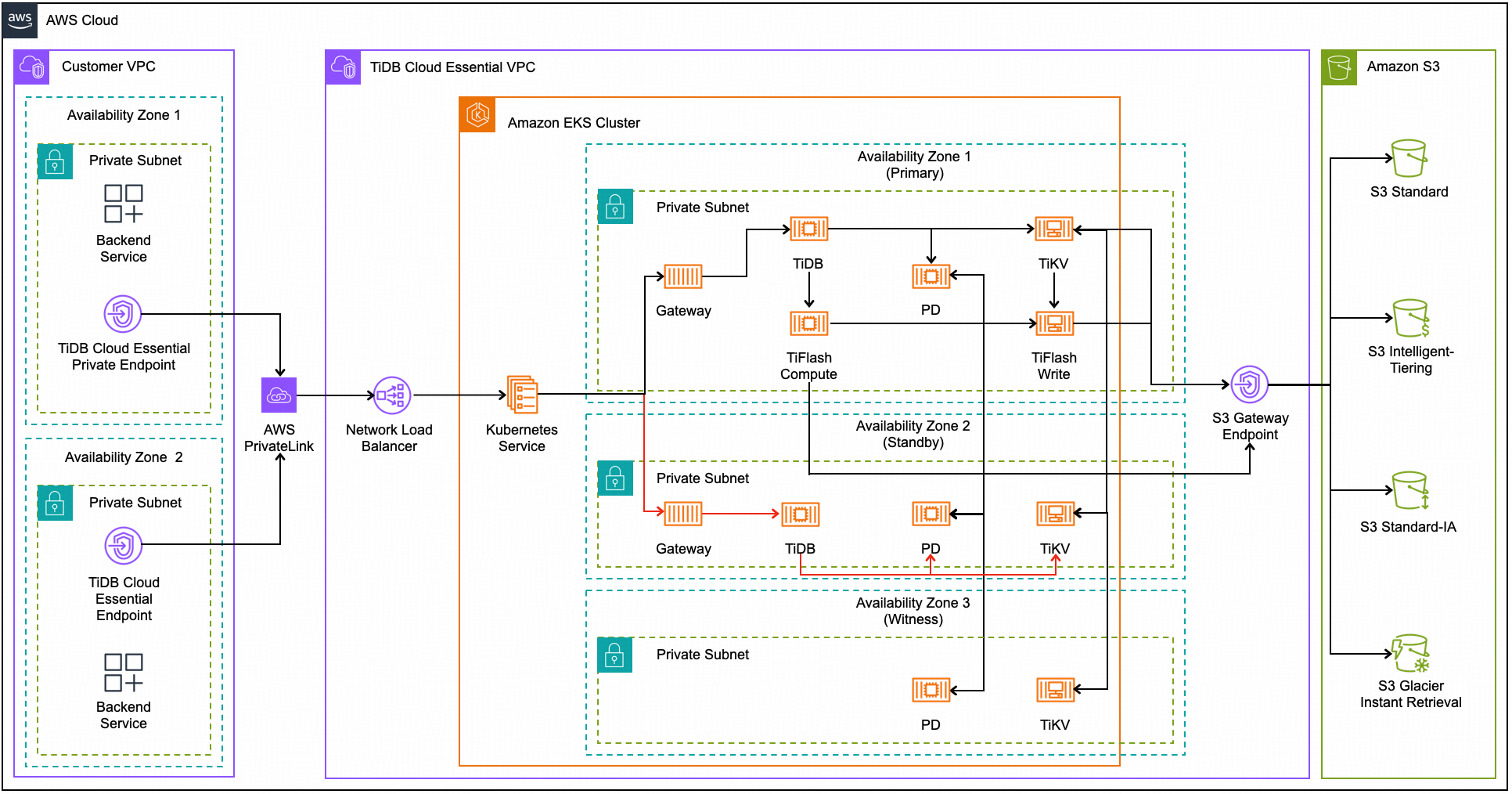
地域高可用性アーキテクチャの場合:
- 配置Driver(PD) と TiKV は複数の可用性ゾーンに展開され、データは常にゾーン間で冗長的に複製され、最高レベルの可用性が確保されます。
- データは、プライマリ アベイラビリティ ゾーン内のTiFlash書き込みノード間で複製されます。
- TiDB サーバーとTiFlashコンピューティング ノードは、ストレージ レベルのレプリケーションによって保護されているこれらの TiKV およびTiFlash書き込みノードに対して読み取りと書き込みを行います。
フェイルオーバープロセス
自然災害、構成変更、ソフトウェアの問題、ハードウェア障害などによりプライマリゾーンに障害が発生した場合、ゲートウェイやTiDBなどの重要なOLTPワークロードコンポーネントがスタンバイアベイラビリティゾーンで自動的に起動されます。トラフィックはスタンバイゾーンに自動的にリダイレクトされ、迅速な復旧とビジネス継続性を確保します。
TiDB Cloud は、次のアクションを実行することで、プライマリ ゾーンの障害発生時にサービスの中断を最小限に抑え、ビジネスの継続性を確保します。
- スタンバイ可用性ゾーンに Gateway と TiDB の新しいレプリカを自動的に作成します。
- エラスティック ロード バランサーを使用して、スタンバイ アベイラビリティ ゾーン内のアクティブなゲートウェイ レプリカを検出し、障害が発生したプライマリ ゾーンからの OLTP トラフィックをリダイレクトします。
TiKVレプリケーションによる高可用性に加え、TiKVインスタンスは、各データレプリカを異なるアベイラビリティゾーンに配置するようにデプロイおよび構成されています。2つのアベイラビリティゾーンが正常に動作している限り、システムは継続的に利用可能です。高い耐久性を確保するため、S3への定期的なデータバックアップによりデータの永続性が確保されています。2つのゾーンに障害が発生した場合でも、S3に保存されているデータへのアクセスと復旧は可能です。
アプリケーションはプライマリゾーン以外のゾーンで発生した障害の影響を受けず、そのようなイベントを認識することもありません。プライマリゾーンで障害が発生した場合、ワークロードを処理するために、ゲートウェイとTiDBがスタンバイ・アベイラビリティ・ゾーンで起動されます。アプリケーションには、新規リクエストをスタンバイ・アベイラビリティ・ゾーンのアクティブサーバーにリダイレクトする再試行ロジックを実装してください。
自動バックアップと耐久性
データベースのバックアップは、事業継続性と災害復旧に不可欠であり、データの破損や誤削除からデータを保護するのに役立ちます。バックアップがあれば、データベースを保有期間内の特定の時点に復元できるため、データ損失とダウンタイムを最小限に抑えることができます。
TiDB Cloud は、継続的なデータ保護を保証する強力な自動バックアップ メカニズムを提供します。
- 毎日の完全バックアップ: データベースの完全なバックアップが 1 日に 1 回作成され、データベース全体の状態がキャプチャされます。
- 継続的なトランザクション ログのバックアップ:トランザクションログは約 5 分ごとに継続的にバックアップされますが、正確な頻度はデータベースのアクティビティによって異なります。
これらの自動バックアップにより、データベースをフルバックアップから復元することも、フルバックアップと継続的なトランザクションログを組み合わせることで特定の時点から復元することもできます。この柔軟性により、インシデント発生直前の正確な時点にデータベースを復旧できます。
注記:
スナップショットベースおよびポイントインタイムリカバリ (PITR) の継続的なバックアップを含む自動バックアップは、リージョンレベルの高い耐久性を提供する Amazon S3 で実行されます。
障害発生時のセッションへの影響
障害発生時、障害が発生したサーバー上で実行中のトランザクションが中断される可能性があります。フェイルオーバーはアプリケーションに対して透過的ですが、アクティブなトランザクション中に回復可能な障害を処理するためのロジックを実装する必要があります。様々な障害シナリオは、以下のように処理されます。
- TiDBの障害:TiDBインスタンスに障害が発生した場合、 TiDB Cloudはトラフィックをゲートウェイ経由で自動的に再ルーティングするため、クライアント接続は影響を受けません。障害が発生したTiDBインスタンス上のトランザクションは中断される可能性がありますが、コミット済みのデータは保持され、新しいトランザクションは利用可能な別のTiDBインスタンスによって処理されます。
- ゲートウェイ障害:ゲートウェイに障害が発生すると、クライアント接続が中断されます。しかし、 TiDB Cloudゲートウェイはステートレスであり、新しいゾーンまたはサーバーで即座に再起動できます。トラフィックは自動的に新しいゲートウェイにリダイレクトされるため、ダウンタイムは最小限に抑えられます。
回復可能な障害に対処するために、アプリケーションに再試行ロジックを実装することをお勧めします。実装の詳細については、ドライバーまたはORMのドキュメント(例: JDBC )を参照してください。
RTOとRPO
ビジネス継続計画を作成するときは、次の 2 つの主要な指標を考慮してください。
- 回復時間目標 (RTO): 中断イベントが発生した後にアプリケーションが完全に回復するまでにかかる最大許容時間。
- リカバリポイント目標 (RPO): 予期しない中断イベントからのリカバリ中にアプリケーションが許容できる最近のデータ更新の損失の最大許容時間間隔。
次の表は、各高可用性オプションの RTO と RPO を比較したものです。