TiCDC の概要
ティCDCは、TiDB から増分データを複製するために使用されるツールです。具体的には、TiCDC は TiKV 変更ログを取得し、キャプチャしたデータをソートし、行ベースの増分データを下流のデータベースにエクスポートします。
使用シナリオ
TiCDC には、次のような複数の使用シナリオがあります。
- 複数の TiDB クラスターに高可用性と災害復旧ソリューションを提供します。TiCDC は、災害発生時にプライマリ クラスターとセカンダリ クラスター間の最終的なデータ整合性を保証します。
- リアルタイムのデータ変更を同種システムに複製します。これにより、監視、キャッシュ、グローバル インデックス作成、データ分析、異種データベース間のプライマリ/セカンダリ レプリケーションなど、さまざまなシナリオのデータ ソースが提供されます。
主な特徴
主な機能
TiCDC には次の主要な機能があります。
- 2 番目レベルの RPO と 1 分レベルの RTO を使用して、TiDB クラスター間で増分データをレプリケートします。
- TiDB クラスター間の双方向レプリケーションにより、TiCDC を使用したマルチアクティブ TiDB ソリューションの作成が可能になります。
- TiDB クラスターから MySQL データベースまたはその他の MySQL 互換データベースに低レイテンシーで増分データを複製します。
- TiDB クラスターから Kafka クラスターに増分データを複製します。推奨されるデータ形式には運河-JSONとアブロが含まれます。
- TiDB クラスターから Amazon S3、GCS、Azure Blob Storage、NFS などのstorageサービスに増分データを複製します。
- データベース、テーブル、DML、および DDL をフィルタリングする機能を使用してテーブルを複製します。
- 単一障害点のない高可用性、TiCDC ノードの動的な追加と削除をサポートします。
- オープンAPIを介したクラスタ管理(タスク ステータスの照会、タスク構成の動的な変更、タスクの作成または削除など)。
複製順序
すべての DDL または DML ステートメントについて、TiCDC はそれらを少なくとも 1 回出力します。
TiKV または TiCDC クラスターで障害が発生すると、TiCDC は同じ DDL/DML ステートメントを繰り返し送信することがあります。重複した DDL/DML ステートメントの場合:
- MySQL シンクは、DDL ステートメントを繰り返し実行できます。
TRUNCATE TABLEのように下流で繰り返し実行できる DDL ステートメントの場合、ステートメントは正常に実行されます。CREATE TABLEのように繰り返し実行できない DDL ステートメントの場合、実行は失敗し、TiCDC はエラーを無視してレプリケーション プロセスを続行します。 - Kafka シンクは、データ分散のためのさまざまな戦略を提供します。
- テーブル、主キー、またはタイムスタンプに基づいて、データを異なる Kafka パーティションに分散できます。これにより、行の更新されたデータが順番に同じパーティションに送信されるようになります。
- これらのすべての分散戦略は、すべてのトピックとパーティションに
Resolved TSメッセージを定期的に送信します。これは、Resolved TSより前のすべてのメッセージがトピックとパーティションにすでに送信されていることを示します。Kafka コンシューマーは、Resolved TSを使用して受信したメッセージを並べ替えることができます。 - Kafka シンクは重複したメッセージを送信することがありますが、これらの重複したメッセージは
Resolved Tsの制約に影響しません。たとえば、変更フィードが一時停止されて再開された場合、Kafka シンクはmsg1、msg2、msg3、msg2、およびmsg3順に送信する可能性があります。Kafka コンシューマーからの重複メッセージをフィルター処理できます。
- MySQL シンクは、DDL ステートメントを繰り返し実行できます。
レプリケーションの一貫性
MySQLシンク
TiCDC は、REDO ログを有効にして、データ レプリケーションの最終的な一貫性を保証します。
TiCDC は、単一行の更新の順序がアップストリームと一貫していることを保証します。
TiCDC では、ダウンストリーム トランザクションがアップストリーム トランザクションと同じ順序で実行されることは保証されません。
注記:
v6.2 以降では、シンク URI パラメータ
transaction-atomicityを使用して、単一テーブル トランザクションを分割するかどうかを制御できます。単一テーブル トランザクションを分割すると、大規模なトランザクションを複製する際のレイテンシーとメモリ消費を大幅に削減できます。
TiCDCアーキテクチャ
TiCDC は TiDB の増分データ レプリケーション ツールであり、PD の etcd を通じて高可用性を実現します。レプリケーション プロセスは次の手順で構成されます。
- 複数の TiCDC プロセスが TiKV ノードからデータの変更を取得します。
- TiCDC はデータの変更をソートしてマージします。
- TiCDC は、複数のレプリケーション タスク (変更フィード) を通じて、データの変更を複数の下流システムに複製します。
TiCDC のアーキテクチャは次の図に示されています。
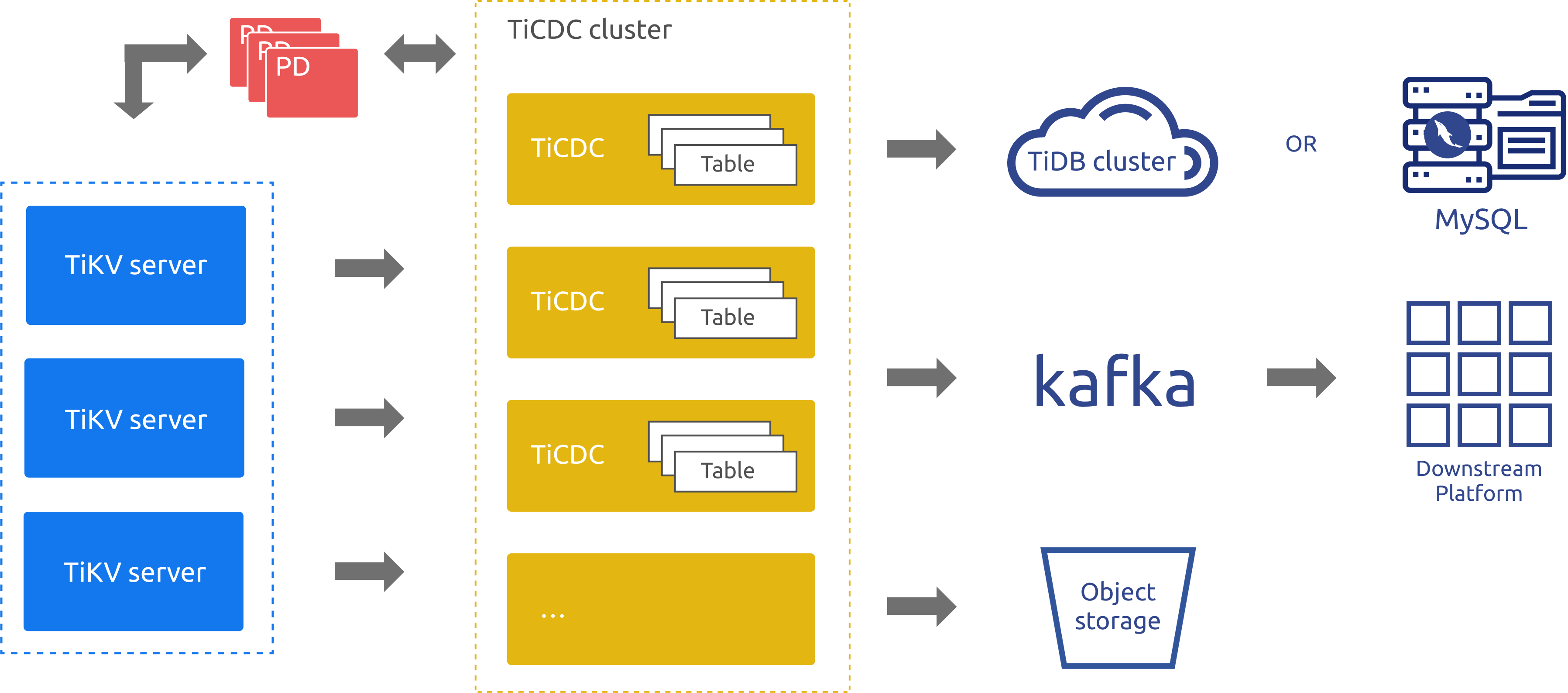
アーキテクチャ図のコンポーネントは次のように説明されます。
- TiKV サーバー: TiDB クラスター内の TiKV ノード。データの変更が発生すると、TiKV ノードは変更内容を変更ログ (KV 変更ログ) として TiCDC ノードに送信します。TiCDC ノードは変更ログが連続していないことを検出すると、TiKV ノードに変更ログを提供するよう積極的に要求します。
- TiCDC: TiCDC プロセスが実行される TiCDC ノード。各ノードは TiCDC プロセスを実行します。各プロセスは、TiKV ノード内の 1 つ以上のテーブルからデータの変更を取得し、シンクコンポーネントを通じてダウンストリーム システムにその変更を複製します。
- PD: TiDB クラスターのスケジューリング モジュール。このモジュールはクラスター データのスケジューリングを担当し、通常は 3 つの PD ノードで構成されます。PD は etcd クラスターを通じて高可用性を提供します。etcd クラスターでは、TiCDC はノードのステータス情報や変更フィード構成などのメタデータを保存します。
アーキテクチャ図に示されているように、TiCDC は TiDB、MySQL、Kafka、およびstorageサービスへのデータの複製をサポートしています。
ベストプラクティス
TiCDC を使用して 2 つの TiDB クラスター間でデータをレプリケートする場合、2 つのクラスター間のネットワークレイテンシーが 100 ミリ秒を超えると、次のようになります。
- v6.5.2 より前のバージョンの TiCDC の場合、ダウンストリーム TiDB クラスターが配置されているリージョン (IDC) に TiCDC をデプロイすることをお勧めします。
- TiCDC v6.5.2 から導入された一連の改善により、アップストリーム TiDB クラスターが配置されているリージョン (IDC) に TiCDC をデプロイすることが推奨されます。
TiCDC は、少なくとも 1 つの有効なインデックスを持つテーブルのみを複製します。有効なインデックスは次のように定義されます。
- 主キー(
PRIMARY KEY)は有効なインデックスです。 - ユニークインデックス(
UNIQUE INDEX)は、インデックスのすべての列が明示的に非NULL値として定義され(NOT NULL)、インデックスに仮想生成列(VIRTUAL GENERATED COLUMNS)がない場合に有効です。
- 主キー(
TiCDC を災害復旧に使用する場合、最終的な一貫性を確保するには、 再実行ログ設定し、上流で災害が発生したときに、REDO ログが書き込まれるstorageシステムが正常に読み取れるようにする必要があります。
処理データの変更の実装
このセクションでは主に、TiCDC が上流の DML 操作によって生成されたデータ変更を処理する方法について説明します。
アップストリーム DDL 操作によって生成されたデータ変更については、TiCDC は完全な DDL SQL ステートメントを取得し、ダウンストリームのシンクの種類に基づいて対応する形式に変換し、ダウンストリームに送信します。このセクションではこれについては詳しく説明しません。
注記:
TiCDC がデータ変更を処理するロジックは、後続のバージョンで調整される可能性があります。
MySQL binlog は、上流で実行されたすべての DML SQL ステートメントを直接記録します。MySQL とは異なり、TiCDC は上流 TiKV 内の各リージョンRaftログのリアルタイム情報をリッスンし、各トランザクションの前後のデータの差分に基づいて、複数の SQL ステートメントに対応するデータ変更情報を生成します。TiCDC は、出力変更イベントが上流 TiDB の変更と同等であることを保証するだけで、上流 TiDB のデータ変更の原因となった SQL ステートメントを正確に復元できることは保証しません。
データ変更情報には、データ変更の種類と変更前後のデータ値が含まれます。トランザクション前後のデータの違いにより、次の 3 種類のイベントが発生する可能性があります。
DELETEイベント: 変更前のデータを含むDELETE種類のデータ変更メッセージに対応します。INSERTイベント: 変更後のデータが含まれるPUT種類のデータ変更メッセージに対応します。UPDATEイベント: 変更前と変更後の両方のデータが含まれるPUT種類のデータ変更メッセージに対応します。
TiCDC は、データ変更情報に基づいて、さまざまなダウンストリーム タイプに適した形式でデータを生成し、ダウンストリームに送信します。たとえば、Canal-JSON や Avro などの形式でデータを生成し、Kafka に書き込んだり、データを SQL 文に変換してダウンストリームの MySQL や TiDB に送信したりします。
現在、TiCDC が対応するプロトコルのデータ変更情報を適応させる場合、特定のUPDATEイベントについては、それらを 1 つのDELETEイベントと 1 つのINSERTイベントに分割することがあります。詳細については、 MySQLシンクのUPDATEイベントを分割するおよび非MySQLシンクの主キーまたは一意キーのUPDATEイベントを分割するを参照してください。
ダウンストリームが MySQL または TiDB の場合、TiCDC はダウンストリームに書き込まれる SQL 文がアップストリームで実行された SQL 文とまったく同じであることを保証できません。これは、TiCDC がアップストリームで実行された元の DML 文を直接取得するのではなく、データの変更情報に基づいて SQL 文を生成するためです。ただし、TiCDC は最終結果の一貫性を保証します。
たとえば、アップストリームでは次の SQL ステートメントが実行されます。
Create Table t1 (A int Primary Key, B int);
BEGIN;
Insert Into t1 values(1,2);
Insert Into t1 values(2,2);
Insert Into t1 values(3,3);
Commit;
Update t1 set b = 4 where b = 2;
TiCDC は、データ変更情報に基づいて次の 2 つの SQL ステートメントを生成し、ダウンストリームに書き込みます。
INSERT INTO `test.t1` (`A`,`B`) VALUES (1,2),(2,2),(3,3);
UPDATE `test`.`t1`
SET `A` = CASE
WHEN `A` = 1 THEN 1
WHEN `A` = 2 THEN 2
END, `B` = CASE
WHEN `A` = 1 THEN 4
WHEN `A` = 2 THEN 4
END
WHERE `A` = 1 OR `A` = 2;
サポートされていないシナリオ
現在、次のシナリオはサポートされていません。
- RawKV のみを使用する TiKV クラスター。
- TiDB の
CREATE SEQUENCEDDL操作とSEQUENCE機能上流の TiDB がSEQUENCEを使用する場合、TiCDC は上流で実行されたSEQUENCEDDL 操作/関数を無視します。ただし、SEQUENCE関数を使用する DML 操作は正しく複製できます。 - 現在、TiCDC によって複製されているテーブルおよびデータベースに対してBRデータ復旧およびTiDB Lightning物理インポートインポートを実行することはサポートされていません。詳細については、 TiCDC を使用したレプリケーションが、上流からTiDB LightningとBRを使用してデータを復元した後に停止したり、停止したりする理由を参照してください。
TiCDC は、アップストリームでの大規模なトランザクションを伴うシナリオを部分的にのみサポートしています。詳細については、 TiCDCFAQを参照してください。そこでは、TiCDC が大規模なトランザクションの複製をサポートしているかどうか、および関連するリスクについての詳細が説明されています。