DM での継続的なデータ検証
このドキュメントでは、DM での継続的データ検証の使用方法、その動作原理、およびその制限事項について説明します。
ユーザーシナリオ
アップストリーム データベースからダウンストリーム データベースにデータを段階的に移行するプロセスでは、データ フローによってデータの破損やデータ損失が発生する可能性が低いです。クレジット業界や証券業界など、データの一貫性が必要なシナリオでは、移行の完了後に完全なデータ検証を実行してデータの一貫性を確保できます。
ただし、増分移行シナリオでは、アップストリームとダウンストリームは継続的にデータを書き込みます。データはアップストリームとダウンストリームで常に変化するため、テーブル内のすべてのデータに対して完全なデータ検証 (たとえば、 同期差分インスペクターを使用) を実行することは困難です。
増分移行シナリオでは、DM の継続的なデータ検証機能を使用できます。この機能により、データが継続的にダウンストリームに書き込まれる増分移行中のデータの整合性と一貫性が保証されます。
継続的なデータ検証を有効にする
次のいずれかの方法を使用して、継続的なデータ検証を有効にできます。
- タスク設定ファイルで有効にします。
- dmctl を使用して有効にします。
方法 1: タスク構成ファイルで有効にする
継続的なデータ検証を有効にするには、次の構成項目をタスク構成ファイルに追加します。
# Add the following configuration items to the upstream database that needs to be validated:
mysql-instances:
- source-id: "mysql1"
block-allow-list: "bw-rule-1"
validator-config-name: "global"
validators:
global:
mode: full # "fast" is also allowed. "none" is the default mode, which means no validation is performed.
worker-count: 4 # The number of validation workers in the background. The default value is 4.
row-error-delay: 30m # If a row cannot pass the validation within the specified time, it will be marked as an error row. The default value is 30m, which means 30 minutes.
設定項目については次のように説明します。
mode: 検証モード。可能な値はnone、full、およびfastです。none: デフォルト値。検証が実行されないことを意味します。full: 変更された行とダウンストリーム データベースで取得された行を比較します。fast: 変更された行がダウンストリーム データベースに存在するかどうかのみをチェックします。
worker-count: バックグラウンドでの検証ワーカーの数。各ワーカーは goroutine です。row-error-delay: 指定された時間内に行が検証に合格できない場合、その行はエラー行としてマークされます。デフォルト値は 30 分です。
完全な構成については、 DM 拡張タスクコンフィグレーションファイルを参照してください。
方法 2: dmctl を使用して有効にする
継続的なデータ検証を有効にするには、次のコマンドdmctl validation startを実行します。
Usage:
dmctl validation start [--all-task] [task-name] [flags]
Flags:
--all-task whether applied to all tasks
-h, --help help for start
--mode string specify the mode of validation: full (default), fast; this flag will be ignored if the validation task has been ever enabled but currently paused (default "full")
--start-time string specify the start time of binlog for validation, e.g. '2021-10-21 00:01:00' or 2021-10-21T00:01:00
--mode: 検証モードを指定します。可能な値はfastとfullです。--start-time: 検証の開始時間を指定します。フォーマットは2021-10-21 00:01:00または2021-10-21T00:01:00に従います。task: 継続的検証を有効にするタスクの名前を指定します。--all-task使用すると、すべてのタスクの検証を有効にできます。
例えば:
dmctl --master-addr=127.0.0.1:8261 validation start --start-time 2021-10-21T00:01:00 --mode full my_dm_task
継続的なデータ検証を使用する
継続的なデータ検証を使用する場合、dmctl を使用して検証のステータスを表示し、エラー行を処理できます。 「エラー行」とは、上流データベースと下流データベース間で不整合が見つかった行を指します。
検証ステータスをビュー
次のいずれかの方法を使用して検証ステータスを表示できます。
方法 1: dmctl query-status <task-name>コマンドを実行します。継続的なデータ検証が有効になっている場合、検証結果は各サブタスクのvalidationフィールドに表示されます。出力例:
"subTaskStatus": [
{
"name": "test",
"stage": "Running",
"unit": "Sync",
"result": null,
"unresolvedDDLLockID": "",
"sync": {
...
},
"validation": {
"task": "test", // Task name
"source": "mysql-01", // Source id
"mode": "full", // Validation mode
"stage": "Running", // Current stage. "Running" or "Stopped".
"validatorBinlog": "(mysql-bin.000001, 5989)", // The binlog position of the validation
"validatorBinlogGtid": "1642618e-cf65-11ec-9e3d-0242ac110002:1-30", // The GTID position of the validation
"cutoverBinlogPos": "", // The specified binlog position for cutover
"cutoverBinlogGTID": "1642618e-cf65-11ec-9e3d-0242ac110002:1-30", // The specified GTID position for cutover
"result": null, // When the validation is abnormal, show the error message
"processedRowsStatus": "insert/update/delete: 0/0/0", // Statistics of the processed binlog rows.
"pendingRowsStatus": "insert/update/delete: 0/0/0", // Statistics of the binlog rows that are not validated yet or that fail to be validated but are not marked as "error rows"
"errorRowsStatus": "new/ignored/resolved: 0/0/0" // Statistics of the error rows. The three statuses are explained in the next section.
}
}
]
方法 2: dmctl validation status <taskname>コマンドを実行します。
dmctl validation status [--table-stage stage] <task-name> [flags]
Flags:
-h, --help help for status
--table-stage string filter validation tables by stage: running/stopped
前述のコマンドでは、 --table-stage使用して検証中のテーブルをフィルターしたり、検証を停止したりできます。出力例:
{
"result": true,
"msg": "",
"validators": [
{
"task": "test",
"source": "mysql-01",
"mode": "full",
"stage": "Running",
"validatorBinlog": "(mysql-bin.000001, 6571)",
"validatorBinlogGtid": "",
"cutoverBinlogPos": "(mysql-bin.000001, 6571)",
"cutoverBinlogGTID": "",
"result": null,
"processedRowsStatus": "insert/update/delete: 2/0/0",
"pendingRowsStatus": "insert/update/delete: 0/0/0",
"errorRowsStatus": "new/ignored/resolved: 0/0/0"
}
],
"tableStatuses": [
{
"source": "mysql-01", // Source id
"srcTable": "`db`.`test1`", // Source table name
"dstTable": "`db`.`test1`", // Target table name
"stage": "Running", // Validation status
"message": "" // Error message
}
]
}
エラーの種類やエラー時間など、エラー行の詳細を表示する場合は、 dmctl validation show-errorコマンドを実行します。
Usage:
dmctl validation show-error [--error error-state] <task-name> [flags]
Flags:
--error string filtering type of error: all, ignored, or unprocessed (default "unprocessed")
-h, --help help for show-error
出力例:
{
"result": true,
"msg": "",
"error": [
{
"id": "1", // Error row id, which will be used in processing error rows
"source": "mysql-replica-01", // Source id
"srcTable": "`validator_basic`.`test`", // Source table of the error row
"srcData": "[0, 0]", // Data of the error row in the source table
"dstTable": "`validator_basic`.`test`", // Target table of the error row
"dstData": "[]", // Data of the error row in the target table
"errorType": "Expected rows not exist", // Error type
"status": "NewErr", // Error status
"time": "2022-07-04 13:33:02", // Discovery time of the error row
"message": "" // Additional information
}
]
}
エラー行の処理
継続的なデータ検証によってエラー行が返された後は、エラー行を手動で処理する必要があります。
継続的なデータ検証でエラー行が見つかった場合、検証はすぐには停止しません。代わりに、処理できるエラー行が記録されます。エラー行が処理される前のデフォルトのステータスはunprocessedです。ダウンストリームでエラー行を手動で修正した場合、検証では修正されたデータの最新ステータスが自動的に取得されません。エラー行は引き続きerrorフィールドに記録されます。
検証ステータスにエラー行を表示したくない場合、またはエラー行を解決済みとしてマークしたい場合は、 validation show-errorコマンドを使用してエラー行 ID を見つけ、その後、指定されたエラー ID で処理できます。
dmctl は、次の 3 つのエラー処理コマンドを提供します。
clear-error: エラー行をクリアします。show-errorコマンドではエラー行が表示されなくなりました。Usage: dmctl validation clear-error <task-name> <error-id|--all> [flags] Flags: --all all errors -h, --help help for clear-errorignore-error: エラー行を無視します。このエラー行は「無視」としてマークされます。Usage: dmctl validation ignore-error <task-name> <error-id|--all> [flags] Flags: --all all errors -h, --help help for ignore-errorresolve-error: エラー行は手動で処理され、「解決済み」としてマークされます。Usage: dmctl validation resolve-error <task-name> <error-id|--all> [flags] Flags: --all all errors -h, --help help for resolve-error
継続的なデータ検証を停止する
継続的なデータ検証を停止するには、次のコマンドvalidation stopを実行します。
Usage:
dmctl validation stop [--all-task] [task-name] [flags]
Flags:
--all-task whether applied to all tasks
-h, --help help for stop
詳しい使い方はdmctl validation startを参照してください。
継続的なデータ検証のためのカットオーバー ポイントを設定する
アプリケーションを別のデータベースに切り替える前に、データの整合性を確保するために、データが特定の位置にレプリケートされた直後に継続的なデータ検証を実行する必要がある場合があります。これを実現するには、この特定の位置を継続的な検証のカットオーバー ポイントとして設定できます。
継続的なデータ検証のカットオーバー ポイントを設定するには、 validation updateコマンドを使用します。
Usage:
dmctl validation update <task-name> [flags]
Flags:
--cutover-binlog-gtid string specify the cutover binlog gtid for validation, only valid when source config's gtid is enabled, e.g. '1642618e-cf65-11ec-9e3d-0242ac110002:1-30'
--cutover-binlog-pos string specify the cutover binlog name for validation, should include binlog name and pos in brackets, e.g. '(mysql-bin.000001, 5989)'
-h, --help help for update
--cutover-binlog-gtid: 検証のためのカットオーバー位置を1642618e-cf65-11ec-9e3d-0242ac110002:1-30の形式で指定します。 GTID がアップストリーム クラスターで有効になっている場合にのみ有効です。--cutover-binlog-pos: 検証のためのカットオーバー位置を(mysql-bin.000001, 5989)の形式で指定します。task-name: 継続的なデータ検証のタスクの名前。このパラメータは必須です。
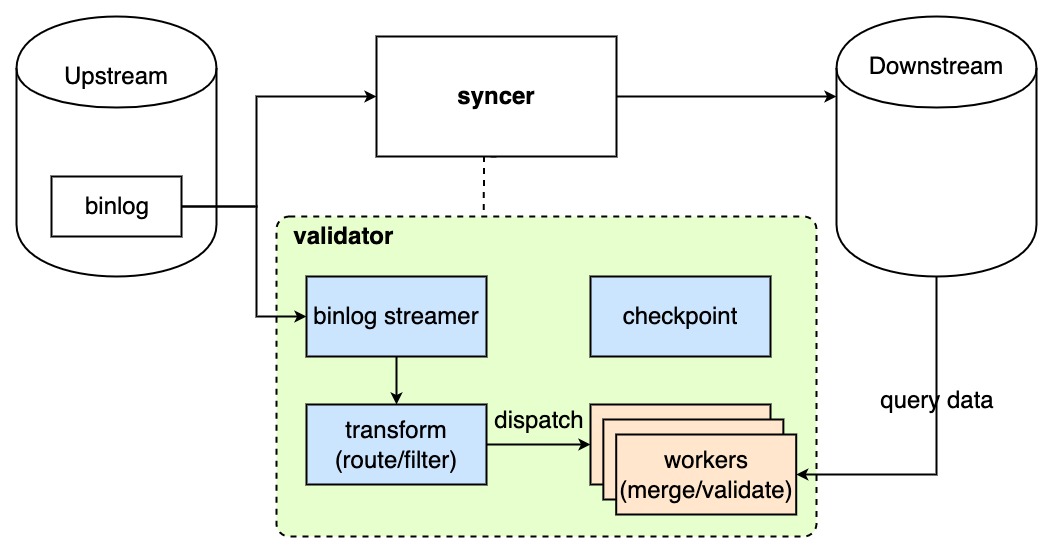
実装
DM における継続的なデータ検証 (バリデーター) のアーキテクチャは次のとおりです。
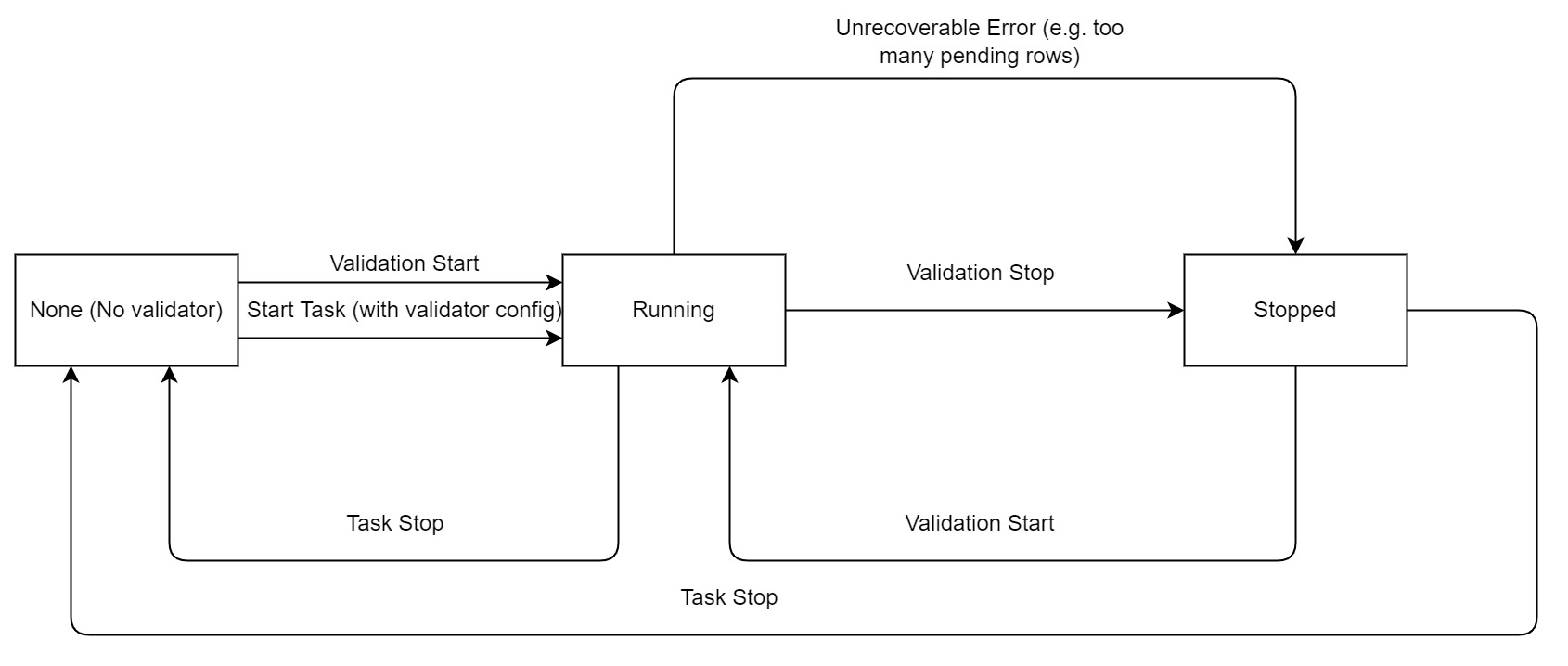
継続的なデータ検証のライフサイクルは次のとおりです。
継続的なデータ検証の詳細な実装は次のとおりです。
- バリデーターはアップストリームからbinlogイベントをプルし、変更された行を取得します。
- バリデーターは、シンサーによって段階的に移行されたイベントのみをチェックします。イベントがシンサーによって処理されていない場合、バリデーターは一時停止し、シンサーの処理が完了するまで待ちます。
- イベントがシンサーによって処理された場合、バリデーターは次のステップに進みます。
- バリデーターはbinlogイベントを解析し、ブロックおよび許可リスト、テーブル フィルター、およびテーブル ルーティングに基づいて行をフィルターで除外します。その後、バリデーターは変更された行をバックグラウンドで実行される検証ワーカーに送信します。
- 検証ワーカーは、同じテーブルと同じ主キーに影響を与える変更された行をマージして、「期限切れ」データの検証を回避します。変更された行はメモリにキャッシュされます。
- 検証ワーカーが一定数の変更された行を蓄積するか、一定の時間が経過すると、検証ワーカーは主キーを使用してダウンストリーム データベースにクエリを実行して現在のデータを取得し、それを変更された行と比較します。
- 検証ワーカーはデータ検証を実行します。検証モードが
fullの場合、検証ワーカーは変更された行のデータをダウンストリーム データベースのデータと比較します。検証モードがfastの場合、検証ワーカーは変更された行の存在のみをチェックします。- 変更された行が検証に合格すると、変更された行はメモリから削除されます。
- 変更された行が検証に失敗した場合、バリデーターはすぐにエラーを報告せず、一定の時間待機してから行を再度検証します。
- 変更された行が (ユーザーが指定した) 指定時間内に検証に合格できない場合、バリデーターはその行をエラー行としてマークし、ダウンストリームのメタ データベースに書き込みます。移行タスクをクエリすると、エラー行の情報を表示できます。詳細は検証ステータスをビュー 、 エラー行の処理を参照してください。
制限事項
- 検証されるソーステーブルには、主キーまたは null でない一意のキーが必要です。
- DM がアップストリーム データベースから DDL を移行する場合、次の制限が適用されます。
- DDL では、主キーを変更したり、列の順序を変更したり、既存の列を削除したりしてはなりません。
- テーブルを削除してはなりません。
- 式を使用してイベントをフィルタリングするタスクはサポートされません。
- 浮動小数点数の精度は TiDB と MySQL で異なります。 10^-6 より小さい差は等しいとみなされます。
- 次のデータ型はサポートされていません。
- JSON
- バイナリデータ