1 つのリージョンでの複数のアベイラビリティーゾーンの展開
分散 SQL データベースとして、TiDB は従来のリレーショナル データベースの最良の機能と NoSQL データベースのスケーラビリティを組み合わせており、アベイラビリティ ゾーン (AZ) 全体での可用性が高くなります。このドキュメントでは、1 つのリージョンでの複数の AZ のデプロイについて紹介します。
このドキュメントの「リージョン」という用語は地理的エリアを指しますが、大文字の「リージョン」は TiKV のデータstorageの基本単位を指します。 「AZ」はリージョン内の孤立した場所を指し、各リージョンには複数の AZ があります。このドキュメントで説明されているソリューションは、複数のデータ センターが 1 つの都市にあるシナリオにも当てはまります。
Raftプロトコル
Raftは分散型コンセンサス アルゴリズムです。このアルゴリズムを使用すると、TiDB クラスターのコンポーネント間で PD と TiKV の両方がデータの災害復旧を実現します。これは次のメカニズムを通じて実装されます。
- Raftメンバーの重要な役割は、ログのレプリケーションを実行し、ステート マシンとして機能することです。 Raftメンバー間では、ログを複製することによってデータ レプリケーションが実装されます。 Raftメンバーはさまざまな条件で自分の状態を変更し、サービスを提供するリーダーを選出します。
- Raftは多数決プロトコルに従う投票システムです。 Raftグループでは、メンバーが過半数の票を獲得すると、そのメンバーがリーダーに変わります。言い換えれば、ノードの大部分がRaftグループに残っている場合、サービスを提供するリーダーを選出できます。
Raft の信頼性を活用するには、実際の展開シナリオで次の条件を満たす必要があります。
- 1 台のサーバーに障害が発生した場合に備えて、少なくとも 3 台のサーバーを使用してください。
- 1 つのラックに障害が発生した場合に備えて、少なくとも 3 つのラックを使用してください。
- 1 つの AZ に障害が発生した場合に備えて、少なくとも 3 つの AZ を使用してください。
- 1 つのリージョンでデータ安全性の問題が発生した場合に備えて、TiDB を少なくとも 3 つのリージョンにデプロイ。
ネイティブRaftプロトコルは、偶数のレプリカを適切にサポートしていません。リージョン間のネットワークレイテンシーの影響を考慮すると、同じリージョンに 3 つの AZ を配置することが、可用性が高く耐災害性の高いRaft導入に最も適したソリューションである可能性があります。
1 つのリージョンに 3 つの AZ を展開
TiDB クラスターは、同じリージョン内の 3 つの AZ にデプロイできます。このソリューションでは、クラスター内のRaftプロトコルを使用して 3 つの AZ にわたるデータ レプリケーションが実装されます。これら 3 つの AZ は、読み取りおよび書き込みサービスを同時に提供できます。 1 つの AZ に障害が発生した場合でも、データの整合性は影響を受けません。
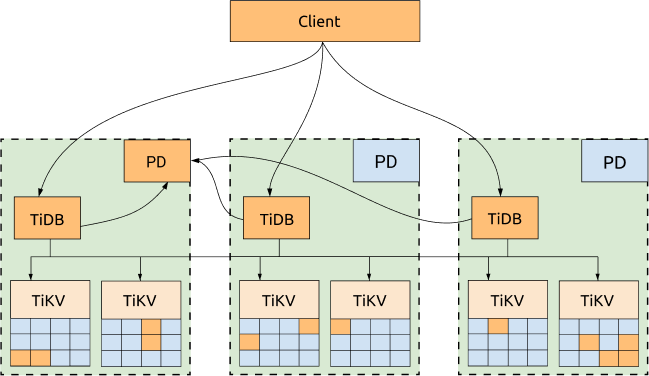
シンプルなアーキテクチャ
TiDB、TiKV、PD は 3 つの AZ に分散されており、最も高い可用性を備えた最も一般的な展開です。
利点:
- すべてのレプリカは 3 つの AZ に分散され、高可用性と災害復旧機能を備えています。
- 1 つの AZ がダウンしても (RPO = 0)、データは失われません。
- 1 つの AZ がダウンした場合でも、他の 2 つの AZ は自動的にリーダー選出を開始し、一定期間内 (ほとんどの場合 20 秒以内) にサービスを自動的に再開します。詳細については、次の図を参照してください。
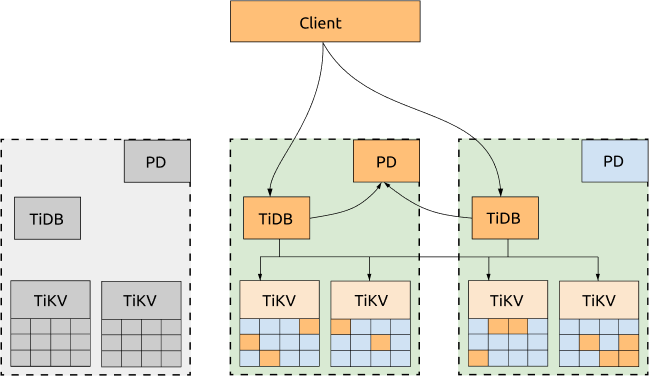
短所:
パフォーマンスはネットワークレイテンシーの影響を受ける可能性があります。
- 書き込みの場合、すべてのデータを少なくとも 2 つの AZ にレプリケートする必要があります。 TiDB は書き込みに 2 フェーズ コミットを使用するため、書き込みレイテンシーは2 つの AZ 間のネットワークのレイテンシーの少なくとも 2 倍になります。
- リーダーが読み取りリクエストを送信する TiDB ノードと同じ AZ にない場合、読み取りパフォーマンスはネットワークレイテンシーの影響も受けます。
- 各 TiDB トランザクションは、PD リーダーから TimeStamp Oracle (TSO) を取得する必要があります。したがって、TiDB リーダーと PD リーダーが同じ AZ にない場合、書き込みリクエストを伴う各トランザクションは TSO を 2 回取得する必要があるため、トランザクションのパフォーマンスもネットワークレイテンシーの影響を受けます。
最適化されたアーキテクチャ
3 つの AZ のすべてがアプリケーションにサービスを提供する必要がない場合は、すべてのリクエストを 1 つの AZ にディスパッチし、TiKVリージョンリーダーと PD リーダーを同じ AZ に移行するようにスケジュール ポリシーを構成できます。このようにして、TSO の取得も TiKV リージョンの読み取りも、AZ 間のネットワークレイテンシーの影響を受けません。この AZ がダウンしている場合、PD リーダーと TiKVリージョンリーダーは他の生き残っている AZ で自動的に選出されるため、要求をまだ生きている AZ に切り替えるだけで済みます。
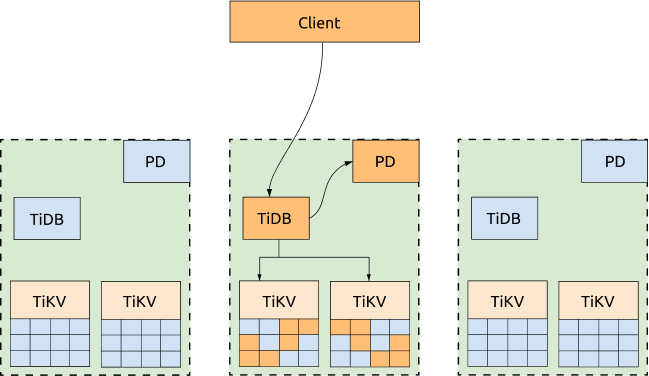
利点:
クラスターの読み取りパフォーマンスと TSO を取得する機能が向上しました。スケジューリングポリシーの設定テンプレートは次のとおりです。
-- Evicts all leaders of other AZs to the AZ that provides services to the application.
config set label-property reject-leader LabelName labelValue
-- Migrates PD leaders and sets priority.
member leader transfer pdName1
member leader_priority pdName1 5
member leader_priority pdName2 4
member leader_priority pdName3 3
ノート:
TiDB v5.2 以降、
label-property構成はデフォルトではサポートされません。レプリカ ポリシーを設定するには、 配置ルールを使用します。
短所:
- 書き込みシナリオは、依然として AZ 間のネットワークレイテンシーの影響を受けます。これは、 Raft が多数派プロトコルに従っており、書き込まれたすべてのデータを少なくとも 2 つの AZ にレプリケートする必要があるためです。
- サービスを提供する TiDBサーバーは1 つの AZ 内にのみ存在します。
- すべてのアプリケーション トラフィックは 1 つの AZ によって処理され、パフォーマンスはその AZ のネットワーク帯域幅の圧力によって制限されます。
- TSO を取得する機能と読み取りパフォーマンスは、アプリケーション トラフィックを処理する AZ で PDサーバーと TiKVサーバーが稼働しているかどうかに影響されます。これらのサーバーがダウンしても、アプリケーションは依然としてクロスセンター ネットワークのレイテンシーの影響を受けます。
導入例
このセクションでは、トポロジの例を示し、TiKV ラベルと TiKV ラベルの計画について紹介します。
トポロジの例
次の例では、3 つの AZ (AZ1、AZ2、および AZ3) が 1 つのリージョンに配置されていると想定しています。各 AZ には 2 セットのラックがあり、各ラックには 3 台のサーバーがあります。この例では、ハイブリッド デプロイメント、または複数のインスタンスが 1 台のマシンにデプロイされるシナリオは無視されています。 1 つのリージョン内の 3 つの AZ での TiDB クラスター (3 つのレプリカ) のデプロイは次のとおりです。
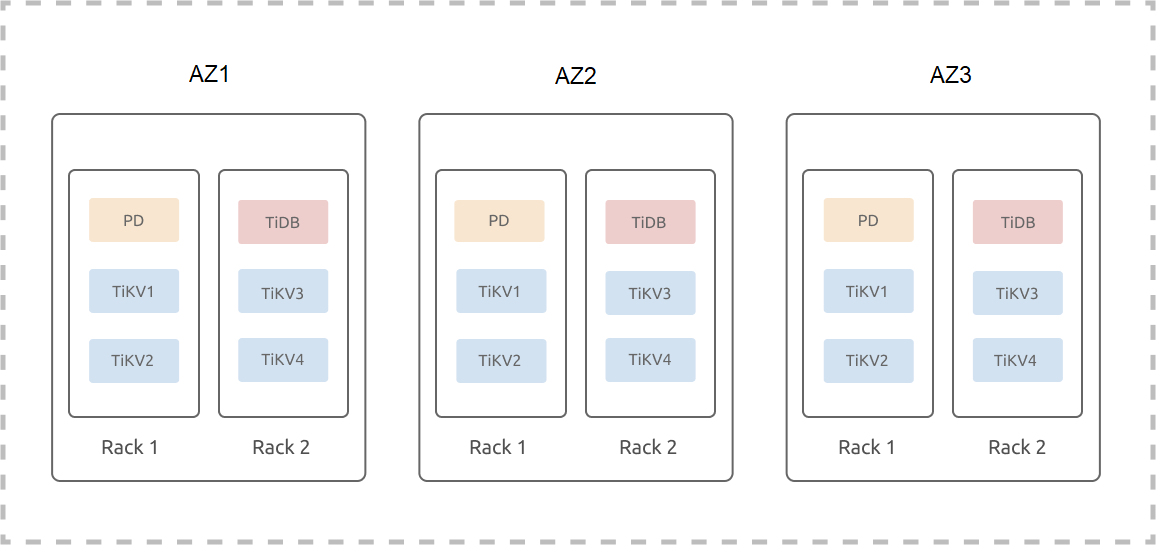
TiKV ラベル
TiKV は、データが領域に分割され、各リージョンのサイズがデフォルトで 96 MB である Multi-Raft システムです。各リージョンの 3 つのレプリカがRaftグループを形成します。 3 つのレプリカからなる TiDB クラスターの場合、リージョンレプリカの数は TiKV インスタンスの数に依存しないため、リージョンの 3 つのレプリカは 3 つの TiKV インスタンスにのみスケジュールされます。これは、クラスターが N 個の TiKV インスタンスを持つようにスケールアウトされた場合でも、依然として 3 つのレプリカからなるクラスターであることを意味します。
3 つのレプリカからなるRaftグループは 1 つのレプリカ障害のみを許容するため、クラスターが N 個の TiKV インスタンスを持つようにスケールアウトされた場合でも、このクラスターは依然として 1 つのレプリカ障害のみを許容します。 2 つの TiKV インスタンスに障害が発生すると、一部のリージョンでレプリカが失われ、このクラスター内のデータが完全でなくなる可能性があります。これらのリージョンからのデータにアクセスする SQL リクエストは失敗します。 N 個の TiKV インスタンス間で 2 つの同時障害が発生する確率は、3 つの TiKV インスタンス間で 2 つの同時障害が発生する確率よりもはるかに高くなります。これは、Multi-Raft システムがスケールアウトされる TiKV インスタンスが増えるほど、システムの可用性が低下することを意味します。
前述の制限のため、TiKV の位置情報の記述にはlabelが使用されます。ラベル情報は、展開またはローリング アップグレード操作によって TiKV 起動構成ファイルに更新されます。起動した TiKV は最新のレーベル情報を PD に報告します。ユーザーが登録したラベル名 (ラベル メタデータ) と TiKV トポロジに基づいて、PD はリージョンレプリカを最適にスケジュールし、システムの可用性を向上させます。
TiKVラベルプランニング例
システムの可用性と災害復旧を向上させるには、既存の物理リソースと災害復旧機能に応じて TiKV ラベルを設計および計画する必要があります。計画されたトポロジに従ってクラスター初期化構成ファイルを編集する必要もあります。
server_configs:
pd:
replication.location-labels: ["zone","az","rack","host"]
tikv_servers:
- host: 10.63.10.30
config:
server.labels: { zone: "z1", az: "az1", rack: "r1", host: "30" }
- host: 10.63.10.31
config:
server.labels: { zone: "z1", az: "az1", rack: "r1", host: "31" }
- host: 10.63.10.32
config:
server.labels: { zone: "z1", az: "az1", rack: "r2", host: "32" }
- host: 10.63.10.33
config:
server.labels: { zone: "z1", az: "az1", rack: "r2", host: "33" }
- host: 10.63.10.34
config:
server.labels: { zone: "z2", az: "az2", rack: "r1", host: "34" }
- host: 10.63.10.35
config:
server.labels: { zone: "z2", az: "az2", rack: "r1", host: "35" }
- host: 10.63.10.36
config:
server.labels: { zone: "z2", az: "az2", rack: "r2", host: "36" }
- host: 10.63.10.37
config:
server.labels: { zone: "z2", az: "az2", rack: "r2", host: "37" }
- host: 10.63.10.38
config:
server.labels: { zone: "z3", az: "az3", rack: "r1", host: "38" }
- host: 10.63.10.39
config:
server.labels: { zone: "z3", az: "az3", rack: "r1", host: "39" }
- host: 10.63.10.40
config:
server.labels: { zone: "z3", az: "az3", rack: "r2", host: "40" }
- host: 10.63.10.41
config:
server.labels: { zone: "z3", az: "az3", rack: "r2", host: "41" }
前述の例では、 zoneはレプリカ (サンプル クラスター内の 3 つのレプリカ) の分離を制御する論理アベイラビリティ ゾーンレイヤーです。
将来のAZのスケールアウトを考慮して、3層のラベル構造( az 、 rack 、 host )をそのまま採用しません。 AZ2 、 AZ3 、およびAZ4をスケールアウトすると仮定すると、対応するアベイラビリティ ゾーン内の AZ をスケールアウトし、対応する AZ 内のラックをスケールアウトするだけで済みます。
この 3 層ラベル構造を直接採用した場合、AZ をスケールアウトした後、新しいラベルを適用し、TiKV 内のデータの再バランスが必要になる場合があります。
高可用性と災害復旧の分析
1 つのリージョンに複数の AZ を展開すると、1 つの AZ に障害が発生した場合でも、手動介入なしでクラスターが自動的にサービスを回復できることが保証されます。データの一貫性も保証されます。スケジュール ポリシーはパフォーマンスを最適化するために使用されますが、障害が発生した場合、これらのポリシーはパフォーマンスよりも可用性を優先することに注意してください。