Grafana を使用して TiDB をモニタリングするためのベスト プラクティス
Grafana と Prometheus をトポロジー構成に追加すると、TiDB クラスター内のさまざまなコンポーネントとマシンのメトリクスを収集して表示するために、 Grafana + Prometheus モニタリング プラットフォーム TiUPを使用して TiDB クラスターをデプロイするセットが同時にデプロイされます。このドキュメントでは、Grafana を使用して TiDB を監視するためのベスト プラクティスについて説明します。これは、メトリクスを使用して TiDB クラスターのステータスを分析し、問題を診断できるようにすることを目的としています。
監視アーキテクチャ
プロメテウスは、多次元データ モデルと柔軟なクエリ言語を備えた時系列データベースです。 グラファナは、メトリクスを分析および視覚化するためのオープンソース監視システムです。
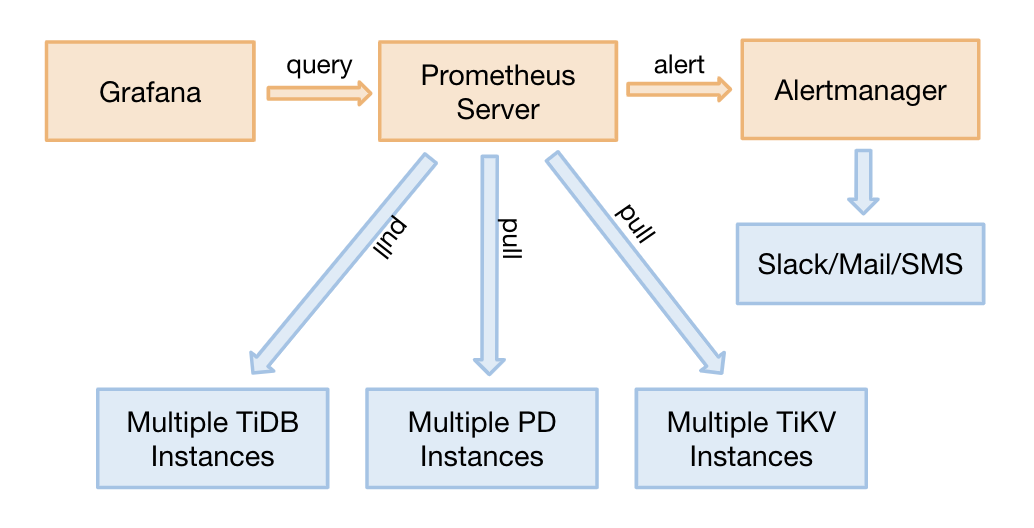
TiDB 2.1.3 以降のバージョンでは、TiDB モニタリングはプル方式をサポートしています。これは、次のような利点を持つ優れた調整です。
- Prometheus を移行する必要がある場合、TiDB クラスター全体を再起動する必要はありません。調整の前に、Prometheus を移行するには、ターゲット アドレスを更新する必要があるため、クラスター全体を再起動する必要があります。
- Grafana + Prometheus 監視プラットフォーム (可用性は高くありません) の 2 つの別々のセットをデプロイして、監視が単一ポイントになるのを防ぐことができます。
- 単一障害点となる可能性のある Pushgateway は削除されます。
モニタリングデータのソースと表示
TiDB の 3 つのコア コンポーネント (TiDBサーバー、TiKVサーバー、および PDサーバー) は、HTTP インターフェイスを通じてメトリクスを取得します。これらのメトリックはプログラム コードから収集され、ポートは次のとおりです。
| 成分 | ポート |
|---|---|
| TiDBサーバー | 10080 |
| TiKVサーバー | 20181 |
| PDサーバー | 2379 |
次のコマンドを実行して、HTTP インターフェイス経由で SQL ステートメントの QPS を確認します。 TiDBサーバーを例に挙げます。
curl http://__tidb_ip__:10080/metrics |grep tidb_executor_statement_total
# Check the real-time QPS of different types of SQL statements. The numbers below are the cumulative values of counter type (scientific notation).
tidb_executor_statement_total{type="Delete"} 520197
tidb_executor_statement_total{type="Explain"} 1
tidb_executor_statement_total{type="Insert"} 7.20799402e+08
tidb_executor_statement_total{type="Select"} 2.64983586e+08
tidb_executor_statement_total{type="Set"} 2.399075e+06
tidb_executor_statement_total{type="Show"} 500531
tidb_executor_statement_total{type="Use"} 466016
上記のデータは Prometheus に保存され、Grafana 上で表示されます。次の図に示すように、パネルを右クリックし、 [編集]ボタンをクリックします (または直接Eキーを押します)。
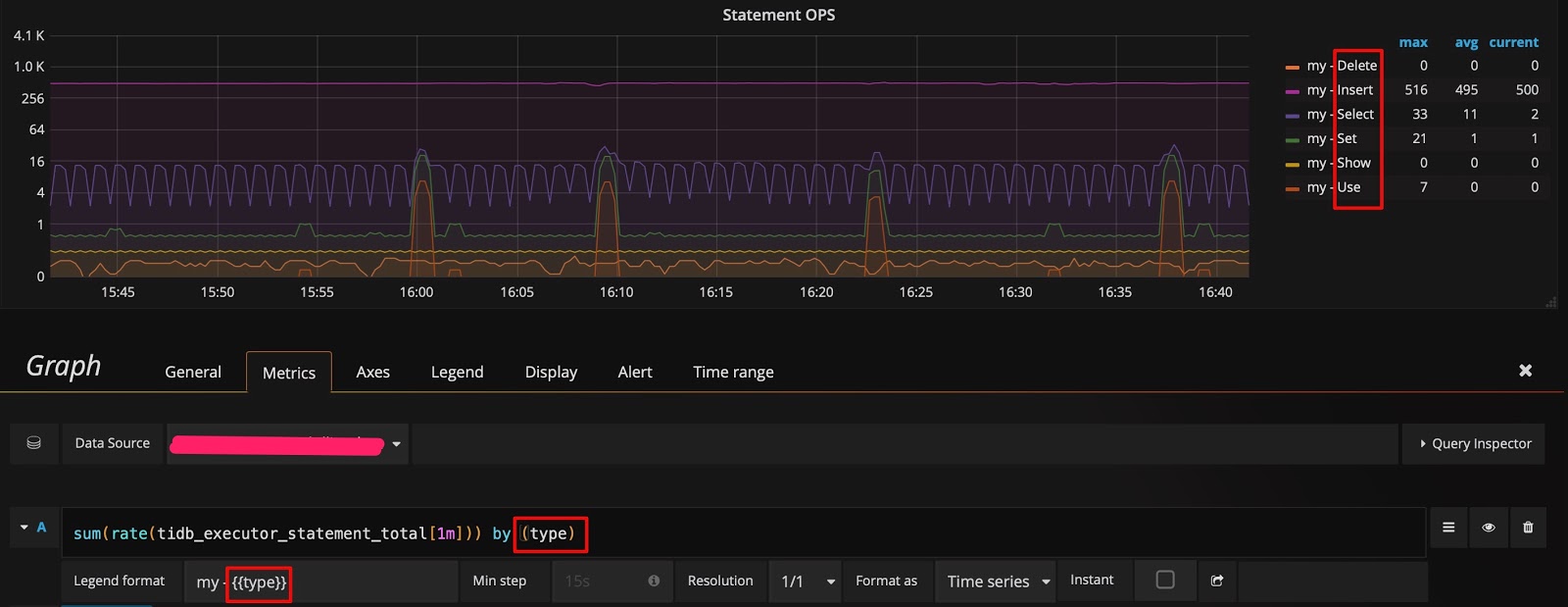
[編集]ボタンをクリックすると、[メトリック] タブにtidb_executor_statement_totalメトリック名を持つクエリ式が表示されます。パネル上の一部の項目の意味は次のとおりです。
rate[1m]: 1分間の成長率。カウンタ型のデータのみ使用可能です。sum: 値の合計。by type: 合計されたデータは、元のメトリック値のタイプごとにグループ化されます。Legend format: メトリック名の形式。Resolution: ステップ幅のデフォルトは 15 秒です。解像度とは、複数のピクセルに対して 1 つのデータ ポイントを生成するかどうかを意味します。
[メトリック]タブのクエリ式は次のとおりです。
Prometheus は多くのクエリ式と関数をサポートしています。詳細については、 プロメテウス公式サイトを参照してください。
グラファナのヒント
このセクションでは、Grafana を効率的に使用して TiDB のメトリクスを監視および分析するための 7 つのヒントを紹介します。
ヒント 1: すべてのディメンションを確認し、クエリ式を編集する
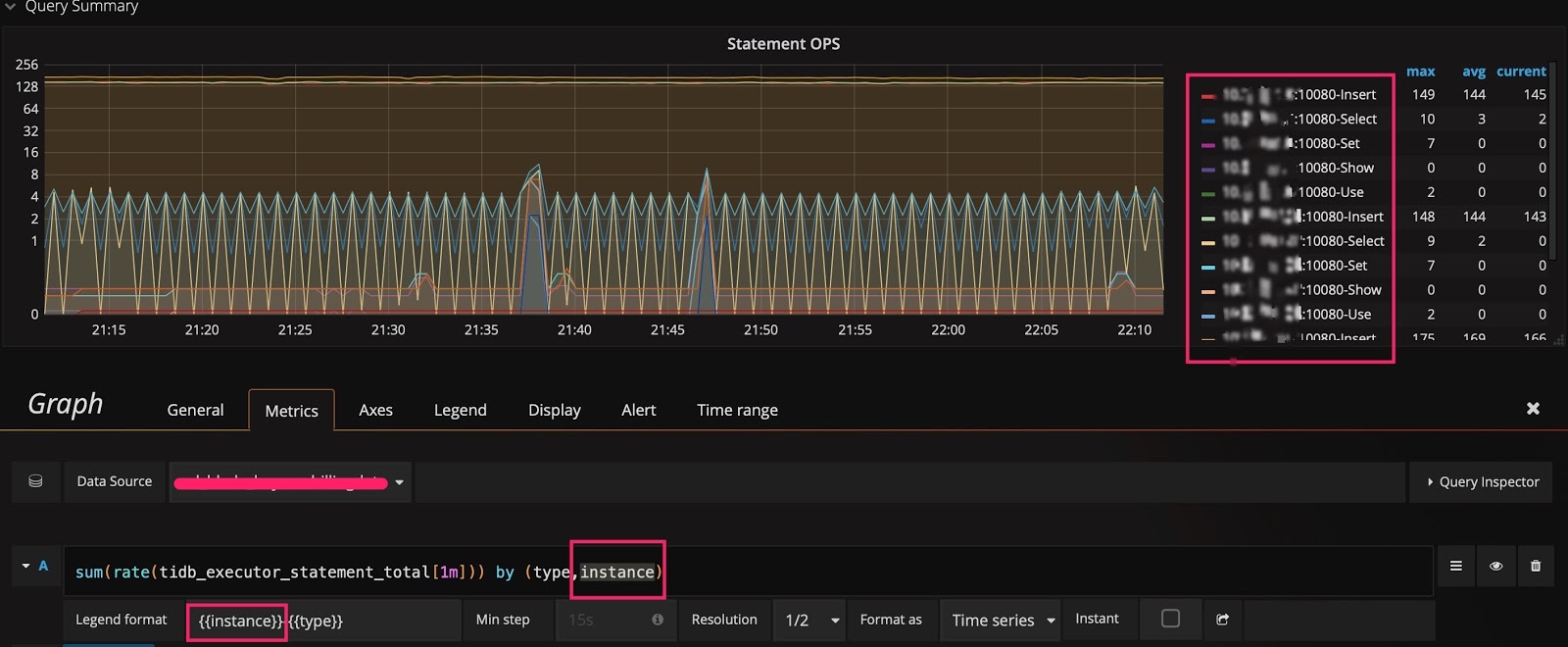
モニタリングデータのソースと表示セクションで示した例では、データはタイプごとにグループ化されています。他のディメンションでグループ化して、どのディメンションが使用可能であるかをすぐに確認できるかどうかを知りたい場合は、次の方法を使用できます。クエリ式ではメトリクス名のみを保持し、計算は行わず、 Legend formatフィールドを空白のままにします。このようにして、元のメトリクスが表示されます。たとえば、次の図は、3 つの次元 ( instance 、 job 、およびtype ) があることを示しています。
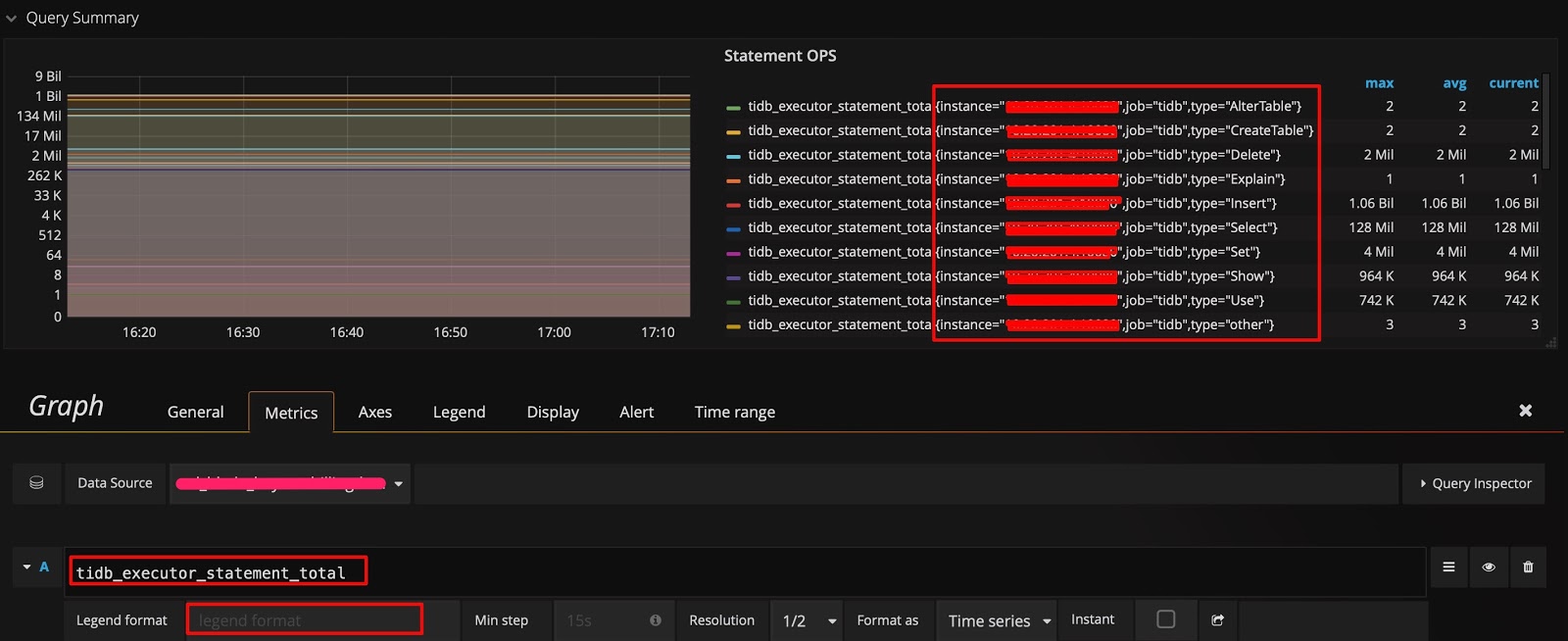
次に、 type後にinstanceディメンションを追加し、 Legend formatフィールドに{{instance}}を追加することで、クエリ式を変更できます。このようにして、各 TiDBサーバーで実行されるさまざまなタイプの SQL ステートメントの QPS を確認できます。
ヒント 2: Y 軸のスケールを切り替える
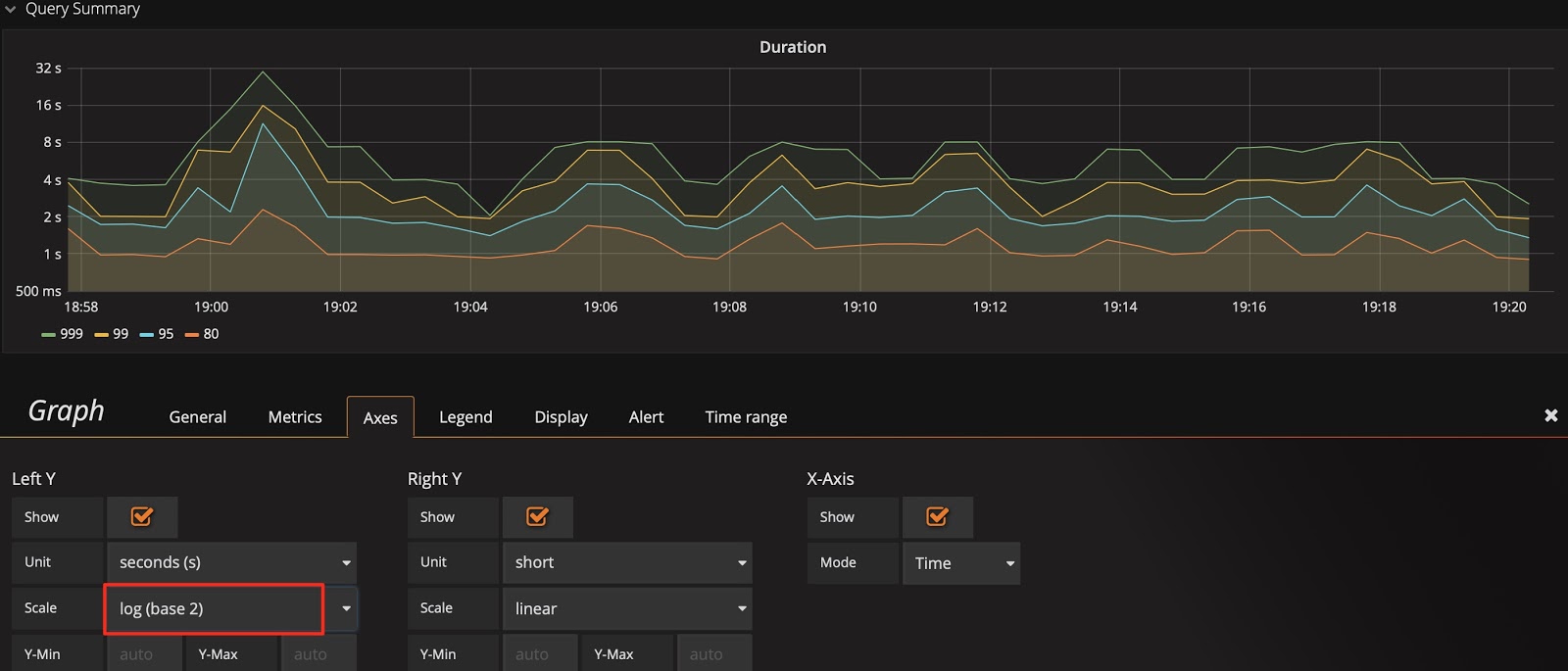
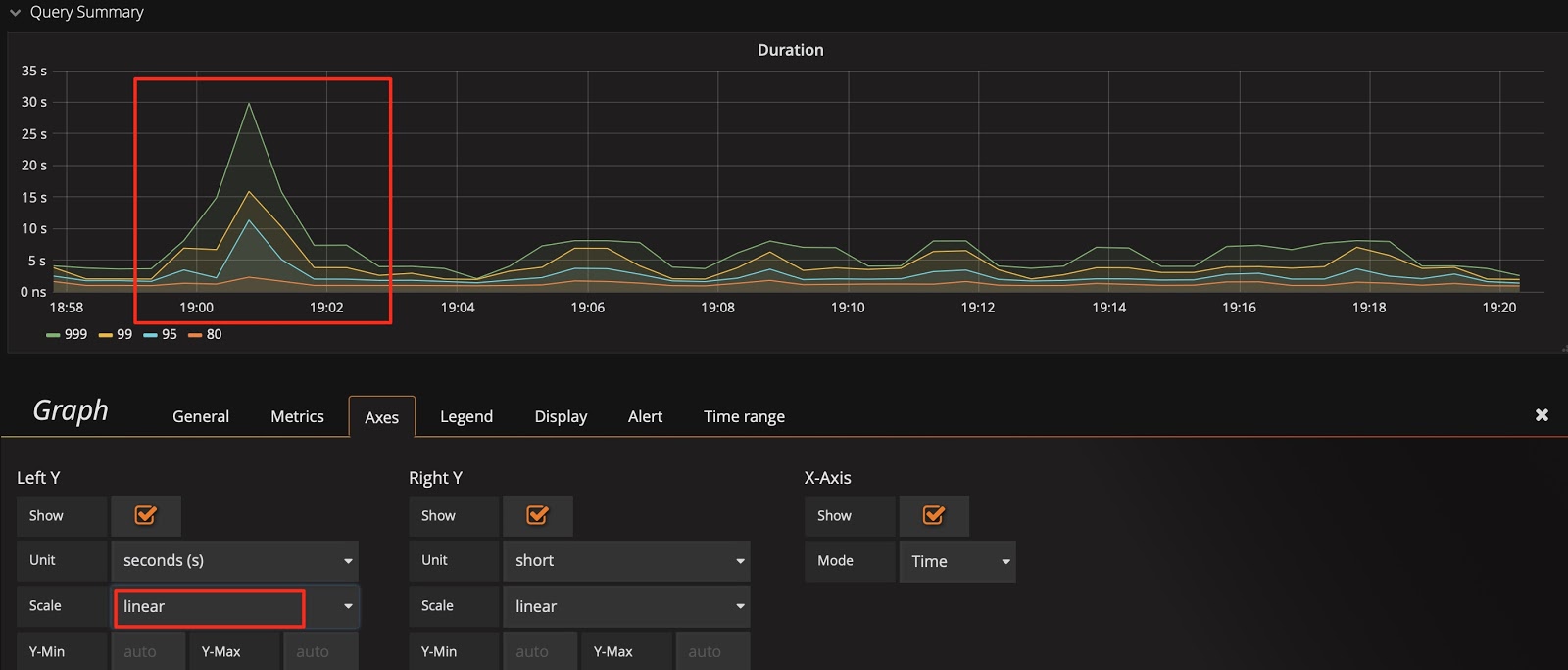
クエリ継続時間を例にとると、Y 軸はデフォルトで 2 進対数スケール (log 2 n) になり、表示のギャップが狭まります。変化を増幅するには、線形スケールに切り替えることができます。次の 2 つの図を比較すると、表示の違いに簡単に気づき、SQL ステートメントの実行が遅い時間を特定できます。
もちろん、線形スケールはすべての状況に適しているわけではありません。たとえば、1 か月間にわたるパフォーマンスの傾向を観察する場合、線形スケールのノイズが存在し、観察が困難になる可能性があります。
Y 軸はデフォルトで 2 進対数スケールを使用します。
Y 軸を線形スケールに切り替えます。
ヒント:
ヒント 2 とヒント 1 を組み合わせると、
SELECTステートメントとUPDATEステートメントが遅いかどうかをすぐに分析するのに役立つsql_typeディメンションを見つけることができます。遅い SQL ステートメントを使用してインスタンスを見つけることもできます。
ヒント 3: Y 軸のベースラインを変更して変化を増幅する
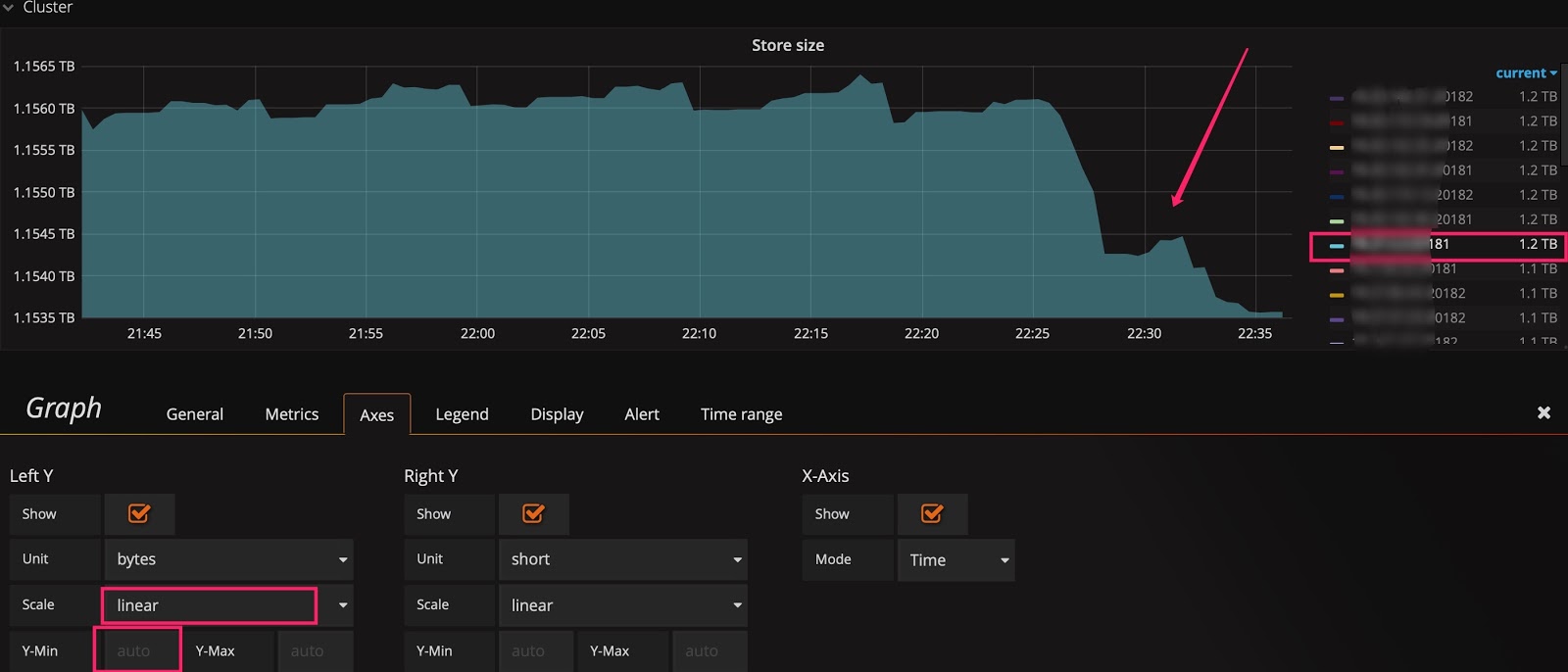
線形スケールに切り替えた後も傾向を確認できない場合があります。たとえば、次の図では、クラスターをスケーリングした後のStore sizeのリアルタイムの変化を観察したいと考えていますが、ベースラインが大きいため、小さな変化は表示されません。この状況では、Y 軸のベースラインを0からautoに変更して、上部を拡大できます。下の 2 つの図を確認すると、データ移行が開始されていることがわかります。
ベースラインのデフォルトは0です。
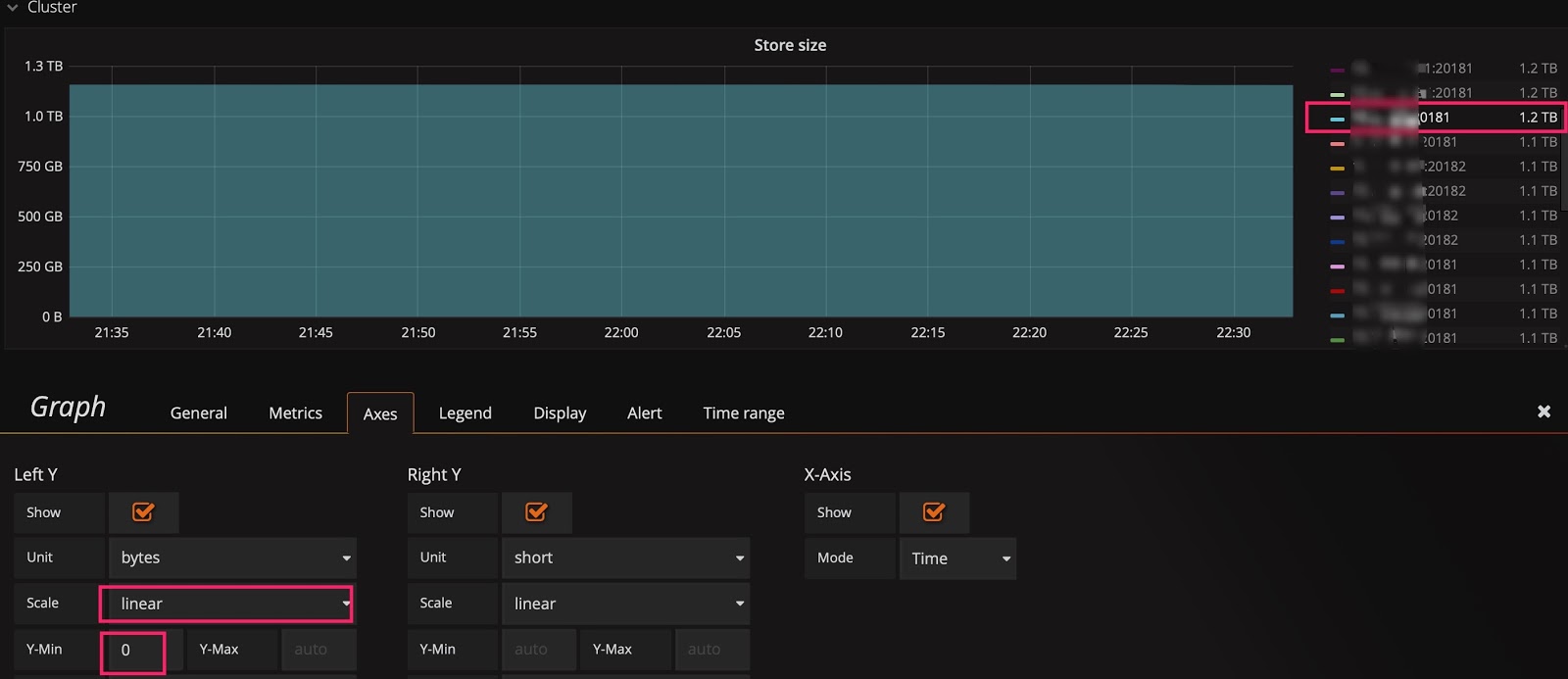
ベースラインをautoに変更します。
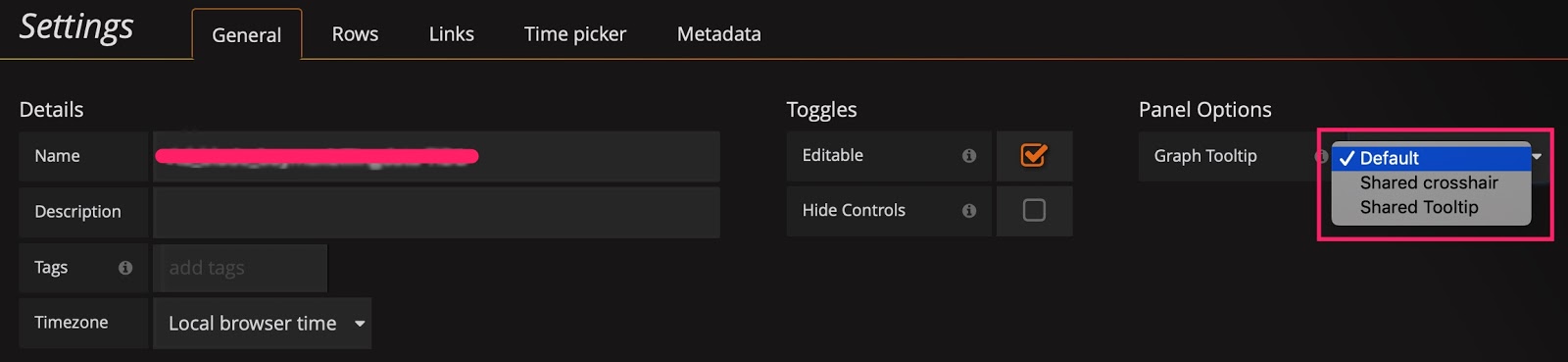
ヒント 4: 共有十字線またはツールチップを使用する
[設定]パネルには、デフォルトでDefaultに設定されている[グラフ ツールチップ]パネル オプションがあります。
次の図に示すように、共有十字線と共有ツールチップをそれぞれ使用して効果をテストできます。すると、スケールが連動して表示されるので、問題を診断する際に2つの指標の相関関係を確認するのに便利です。
グラフィック プレゼンテーション ツールを[共有十字線]に設定します。

グラフィカル プレゼンテーション ツールを[共有ツールチップ]に設定します。

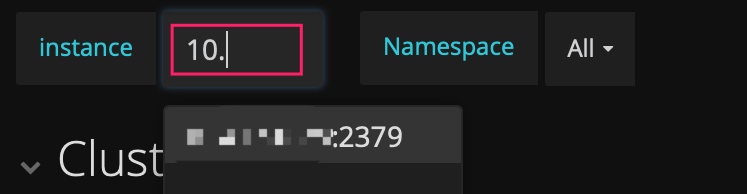
ヒント 5: IP address:port number入力して履歴のメトリクスを確認する
PD のダッシュボードには、現在のリーダーの指標のみが表示されます。履歴内の PD リーダーのステータスを確認したいが、そのリーダーがinstanceフィールドのドロップダウン リストに存在していない場合は、手動でIP address:2379入力してリーダーのデータを確認できます。
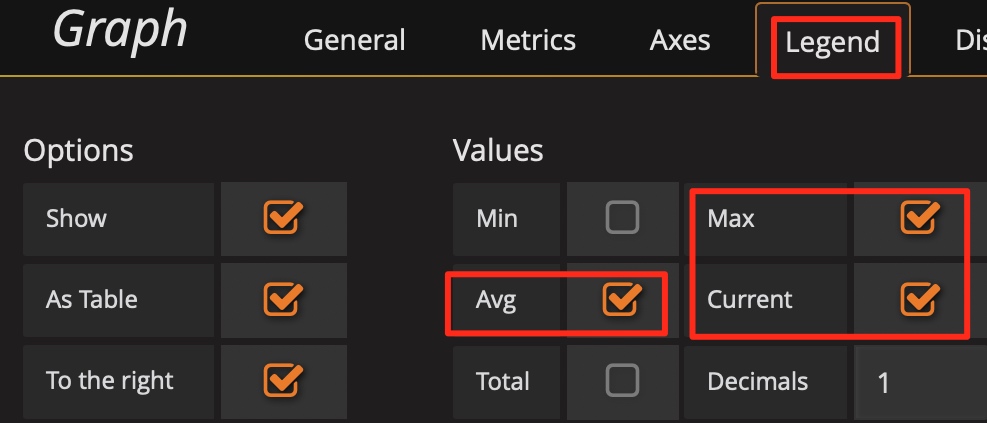
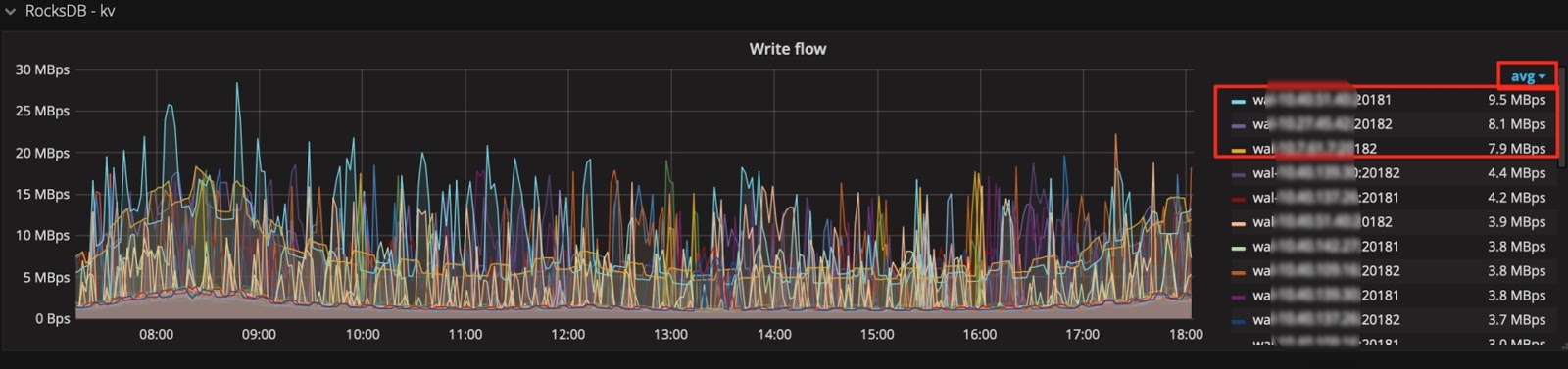
ヒント 6: Avg関数を使用する
通常、デフォルトでは凡例で使用できる関数はMaxとCurrentのみです。メトリクスが大きく変動する場合は、 Avg関数などの他の集計関数を凡例に追加して、一定期間の全体的な傾向を確認できます。
Avg関数などの要約関数を追加します。
次に、全体的な傾向を確認します。
ヒント 7: Prometheus の API を使用してクエリ式の結果を取得する
Grafana は Prometheus の API を通じてデータを取得します。この API を使用して情報を取得することもできます。さらに、次のような用途もあります。
- クラスタのサイズやステータスなどの情報を自動的に取得します。
- 式に若干の変更を加えて、1 日あたりの QPS の合計量、1 日あたりの QPS のピーク値、1 日あたりの応答時間のカウントなど、レポートの情報を提供します。
- 重要な指標について定期的な健全性検査を実行します。
Prometheus の API は次のようになります。
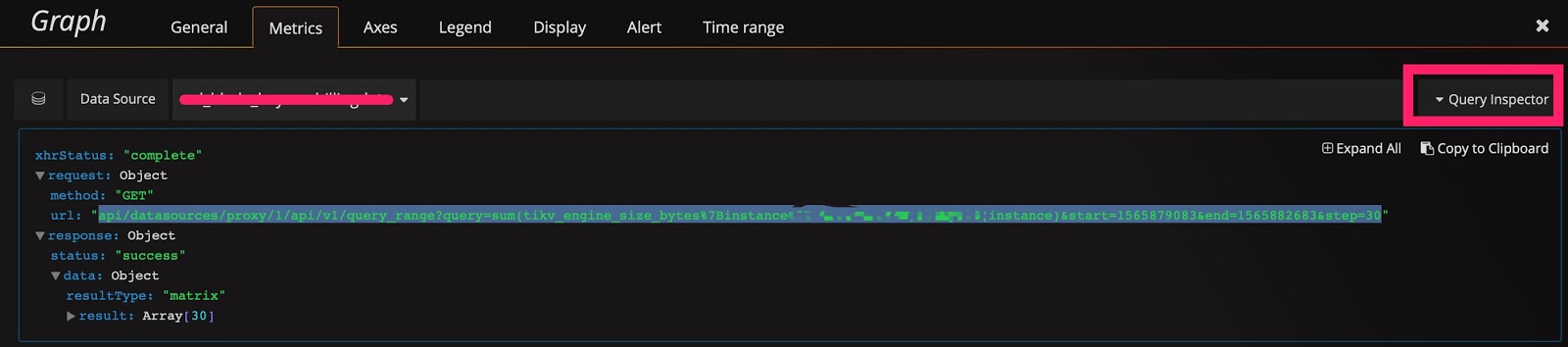
curl -u user:pass 'http://__grafana_ip__:3000/api/datasources/proxy/1/api/v1/query_range?query=sum(tikv_engine_size_bytes%7Binstancexxxxxxxxx20181%22%7D)%20by%20(instance)&start=1565879269&end=1565882869&step=30' |python -m json.tool
{
"data": {
"result": [
{
"metric": {
"instance": "xxxxxxxxxx:20181"
},
"values": [
[
1565879269,
"1006046235280"
],
[
1565879299,
"1006057877794"
],
[
1565879329,
"1006021550039"
],
[
1565879359,
"1006021550039"
],
[
1565882869,
"1006132630123"
]
]
}
],
"resultType": "matrix"
},
"status": "success"
}
まとめ
Grafana + Prometheus 監視プラットフォームは非常に強力なツールです。これをうまく活用すると効率が向上し、TiDB クラスターのステータスの分析にかかる時間を大幅に節約できます。さらに重要なのは、問題の診断に役立つことです。このツールは、特に大量のデータがある場合に、TiDB クラスターの運用と保守に非常に役立ちます。